Python基础语法——模块与类库
1.模块
模块是由一组类,函数与变量组成的,这些类等都存在文本文件中。.py是Python程序代码文件的扩展名,模块可能是使用C或是Python写成的,模块文件的扩展名可能是.py或。pyc.在Python目录下的lib文件夹中。
(1)Python中的模块
有过C语言编程经验的朋友都知道在C语言中如果要引用sqrt函数,必须用语句#include 引入math.h这个头文件,否则是无法正常进行调用的。
那么在Python中,如果要引用一些其他的函数,该怎么处理呢?
在Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个模块,下面就来了解一下Python中的模块。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
(2)import
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。
形如:
处于该模块的名称空间内。
import module1,mudule2...
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。
在调用math模块中的函数时,必须这样引用:
模块名.函数名
-
想一想:
为什么必须加上模块名调用呢?
-
答:
因为可能存在这样一种情况:在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以如果像上述这样引入模块的时候,调用函数必须加上模块名
import math
#这样会报错
print sqrt(2)
#这样才能正确输出结果
print math.sqrt(2)
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
from 模块名 import 函数名1,函数名2....
不仅可以引入函数,还可以引入一些全局变量、类等
-
注意:
-
通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
-
如果想一次性引入math中所有的东西,还可以通过from math import *来实现
-
(3)from 模块名 import 函数名
用此方法引用该模块的函数时,此函数处于全域名空间内,而不是在该模块的名称空间内。
Python的 from语句让你从模块中导入一个指定的部分到当前命名空间中。
语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块fib的fibonacci函数,使用如下语句:
from fib import fibonacci
from 隔壁班 import 李明():把隔壁班的李明拿过来了。
注意
- 不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个引入
(4)from … import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
注意
- 这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
(5)定位模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录
- 当前目录下定义的文件不能和标准模块重名,如果出现重名问题,在导入标准模块时就会把这些定义的文件当成模板来加载,通常会引发错误。
2.模块制作
(1)定义自己的模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
test.py
def add(a,b):
return a+b
(2)调用自己定义的模块
那么在其他文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入
main.py
import test
result = test.add(11,22)
print(result)
(3)测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
test.py
def add(a,b):
return a+b
# 用来进行测试
ret = add(12,22)
print('int test.py file,,,,12+22=%d'%ret)
如果此时,在其他py文件中引入了此文件的话测试的那段代码也会执行
main.py
import test
result = test.add(11,22)
print(result)
运行现象:
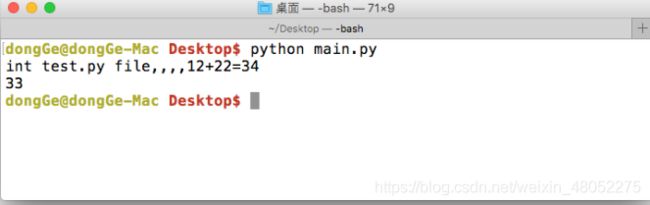
至此,可发现test.py中的测试代码,应该是单独执行test.py文件时才应该执行的,不应该是在其他的文件中引用而执行
为了解决这个问题,python在执行一个文件时有个变量__name__。
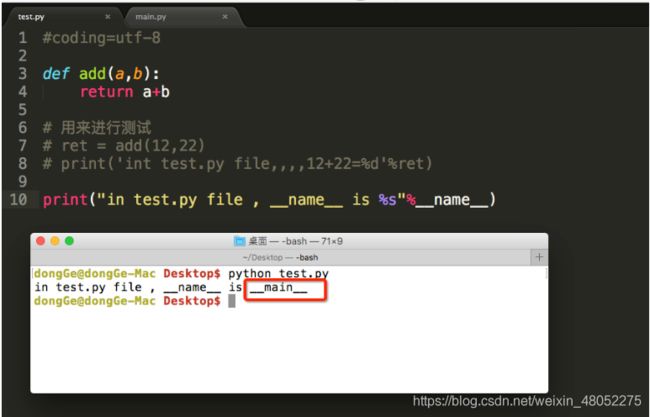
直接运行此文件
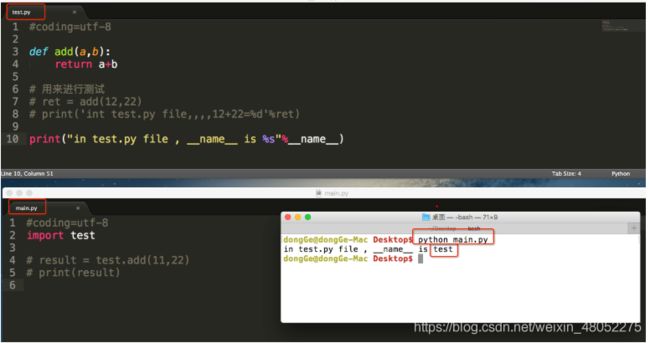
在其他文件中import此文件
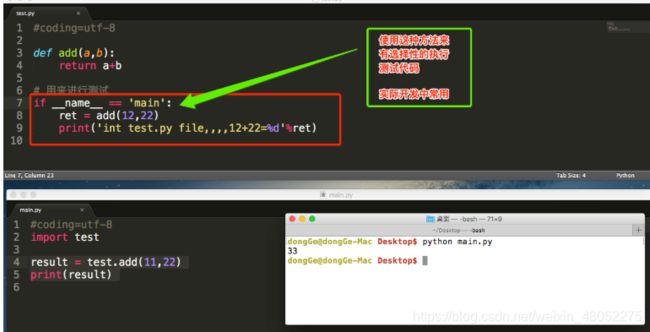
总结:
- 可以根据
__name__变量的结果能够判断出,是直接执行的python脚本还是被引入执行的,从而能够有选择性的执行测试代码 - test.py文件是被当成程序执行的该__name__属性的值是“__main__”
- test.py文件是被别的文件导入的该__name__属性的值是“__test__(被导入的模块名)”
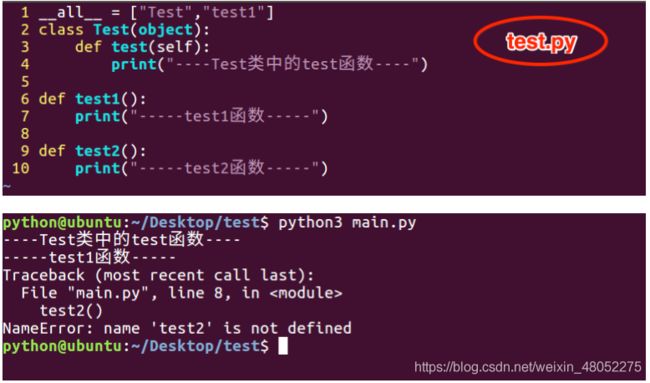
3.模块中的__all__
__all__=["Test","test1"] Test:为类名,test1为方法名。
- 防止别人使用 from sendmsg import * 引用模块时 将所有方法全部
- 既只有中括号中存在的才可以被调用
(1) 没有__all__
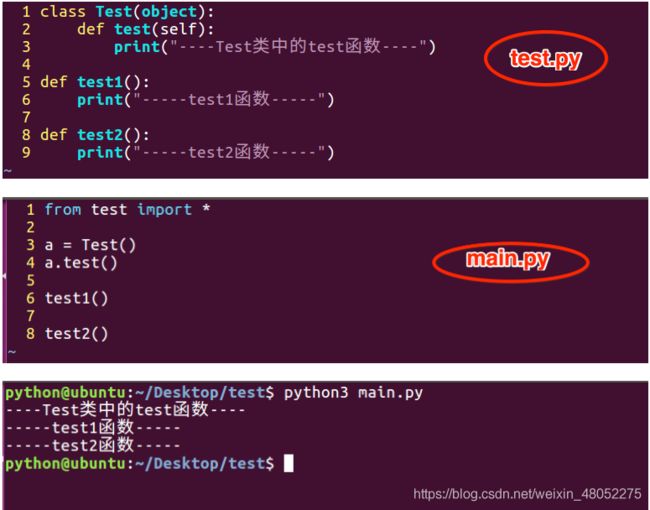
(2)模块中有__all__
3.什么是类库
类库是由一组相同文件夹的模块组成的,类库的名称必须是sys.path所列的文件夹的子文件夹。每一个类库的文件夹中必须至少有一个__init__.py文件。类库可以包含子类库,自类库的文件夹中也必须有一个__init__.py文件。
import 类库.模块
import 子类库1,子类库2,.....
4.模块和类库的基本操作
(1)修改模块名:
import 模块 as 新名称
或
from 模块 import 函数 as 新名称
(2)模块的内置方法
以下都__builtin__模块的内置方法,可以讲这些方法应用在模块或类库中。
m.__dict__:显示模块字典。
m.__doc__:显示模块的文件字符串。
m.__name__:显示模块的名称。
m.__file__显示模块的完整路径
del 模块名 删除模块
6.模块打包
如果想使用一个存放在其他目录的Python程序,或者是其他系统的Python程序,就可以将这些程序制作成有个安装包,然后安装到本地,安装的位置可以选择sys.path文件中的任意一个目录。这样用户就可以在任何想要使用该程序的地方,直接使用import导入了。
7.运行期服务组模块(常见)
(1)sys模块用与存取与Python解释器有关联的系统参数,包括变量和参数。
(2)types 模块包含Python内置类型的名称。用户可以使用Python解释器的type(obj)内置函数,得到obj对象的内置类型。
(3)operator 模块包含所有Python标准运算符相应的函数,是使用C写成的。
a+b等于operator.add(a,b)或operator.__add__(a,b)
a-b等于operator.sub(a,b)或operator.__sub__(a,b)
a+b等于operator.mul(a,b)或operator.__mul__(a,b)
a/b等于operator.truediv(a,b)或operator.__add__(a,b)
(4)traceback模块支持输出与捕捉追踪栈,在输出时,可以检验调用函数的堆栈来调试。
(5)lincache模块:让用户可以随机存取文本文件的任意一,linecache模块使用高效缓存来操作文件。
(6)pickle模块:pickle模块可以处理Python对象的序列化。所谓对象的序列化,就是将对象转换为位串流,如此就可以将对象存储在文件或数据库中,也可以通过网络来传输,
(7)keyword模块:测试一个子符串是否属于Python关键字
(8)数据压缩模块:
8.字符处理模块
(1)string模块:提供一般的字符串操作函数与常数
(2)re模块用来使用普洱类型的正则表达运算
(3)struct模块将Python的数据与二进制数据结构进行转换,转换后的二进制数据可以应用在c语言及网络传输协议内。