3、基于物品的协同过滤算法
一.背景及优点
随着网站的用户数目越来越大,计算用户兴趣相似度矩阵越来越困难,其运算时间复杂度和空间时间复杂度的增长和用户数的增长近似于平方关系。其次,基于用户的协同过滤算法很难对推荐结果作出解释。
因此产生了基于物品的协同过滤算法(ItemCF)。ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。 ItemCF可以利用用户的行为给推荐结果提供推荐解释
二.算法详解
2.1 ItemCF主要分为两步
- 计算物品之间的相似度
根据物品的相似度和用户的历史行为给用户生成推荐列表
我们可以通过以下公式定义物品的相似度
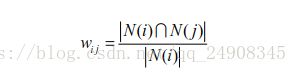
以上,其中
N(i)表示喜欢物品i的用户数,而分子N(i)∩N(j)表示喜欢物品i同时喜欢物品j的用户数
因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j
然后,这里有一个问题,就是如果物品j很热门,那么喜欢物品i的用户很多都喜欢物品j那么W就会区域1.所有我们使用以下公式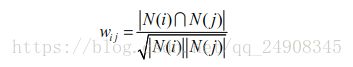
以上,在分母中加上
N(j)对相似度进行惩罚,即越热门,这个物品被使用的人越多,那么分母就会变大。从而可以挖掘长尾信息。
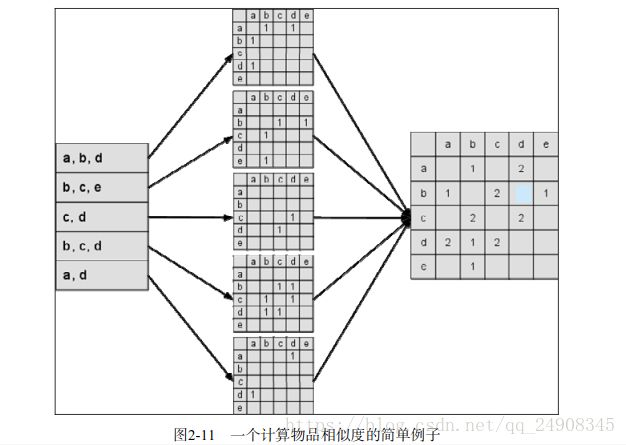
其中C[i][j]表示的是同时喜欢物品i 和物品j的用户数 如果物品相似度求出来了,就可以根据以下公式计算用户u对于一个物品j的兴趣度
![]()
其中N(u)是用户喜欢的物品的集合,S(j,k)是和物品j最相似的K个物品的集合,w 表示是物品j,i的相似度,r表示的是用户u对物品i的兴趣(对于隐反馈数据集,如果用户u对物品i有过行为,即可令r=1)
该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
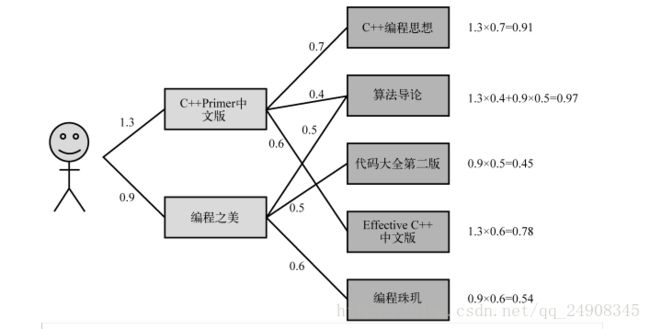
2.2 下图是一个基于物品推荐的例子:
- 用户喜欢 C++和编程之美两本书,权重分别为 1.3和0.9
- 和C++相似的书有 C++编程思想,算法导论,EffectiveC++ 相似度分别为 0.7,0.4,0.6
- 和编程之美相似的书有算法导论,代码大全,编程珠玑 相似度分别为 0.5,0.5,0.6
那么计算用户对算法导论的兴趣度为=》1.3*0.4+0.9*0.5=0.97
对C++编程思想兴趣度为=》1.3*0.7=0.91
最后按照兴趣度降序排序,从高到低进行推荐。
2.3 用户活跃度对物品相似度的影响
每个用户的兴趣列表都对物品的相似度产生了贡献。但是不是每个用户对物品的相似度产生的贡献都相同的。
假如一个书商买了几十万本书,那么他的这一行为就不能增加物品相似度。
IUF算法,即用户活跃度对数的倒数的参数,活跃用户对物品相似度的贡献应该小于不活跃用户。他提出应该增加IUF参数来修正物品相似度的计算公式
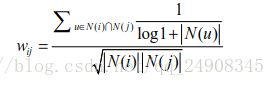
2.4 物品相似度的归一化
Karypis在研究中发现如果将Ite’mCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w’
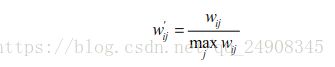
归一化能够有效地提高覆盖率和降低流行度
三: UserCF和ItemCF的区别

就新闻网站来说,用户的兴趣不是特别细化,绝大多数用户都喜欢看热门的新闻。即使是个性化,也是比较粗粒度的,比如有些用户喜欢体育新闻,有些喜欢社会新闻,而特别细粒度的个性话一般是不存在的。比方说,很少有用户只看某个话题的新闻,主要是因为这个话题不可能保证每天都有新的消息,而这个用户每天都是要看新闻的。
因此个性化新闻推荐更加强调抓住新闻热点,热门程度和时效性是关键
从技术方面来考虑。作为一个物品,新闻的更新非常快,每时每刻都有新内容出现,而ItemCF需要维护一张物品相关度的表,如果物品,新闻的更新非常的快,每时每刻都有新的新闻产生,而ItemCF需要维护一张物品相关度的表,如果物品更新很快,那么这张表需要很快的更新,技术上很难实现。而UserCF对于新用户也需要更新相似度表,但在新闻网站中,物品的更新速度远远快于新用户的加入速度。
四:python 代码实现
#-*- coding: utf-8 -*-
'''
Created on 2015-06-22
@author: Lockvictor
'''
import sys
import random
import math
import os
from operator import itemgetter
from collections import defaultdict
random.seed(0)
'''
users.dat 数据集
用户id 用户性别 用户年龄 用户职业 用户所在地邮编
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
movies.dat 数据集
电影id 电影名称 电影类型
250::Heavyweights (1994)::Children's|Comedy
251::Hunted, The (1995)::Action
252::I.Q. (1994)::Comedy|Romance
ratings.dat 数据集
用户id 电影id 用户评分 时间戳
157::3519::4::1034355415
157::2571::5::977247494
157::300::3::977248224
'''
'''基于物品协同过滤算法'''
class ItemBasedCF(object):
''' TopN recommendation - Item Based Collaborative Filtering '''
def __init__(self):
self.trainset = {} # 存储训练集
self.testset = {} # 存储测试集
self.n_sim_movie = 20 # 定义相似电影数20
self.n_rec_movie = 10 # 定义推荐电影数10
self.movie_sim_mat = {} # 存储电影相似矩阵
self.movie_popular = {}
self.movie_count = 0
print('Similar movie number = %d' % self.n_sim_movie, file=sys.stderr)
print('Recommended movie number = %d' %
self.n_rec_movie, file=sys.stderr)
@staticmethod
def loadfile(filename):
''' 只读的方式打开文件 '''
fp = open(filename, 'r')
# enumerate()为枚举,i为行号从0开始,line为值
for i, line in enumerate(fp):
# yield 迭代去下一个值,类似next()
# line.strip()用于去除字符串头尾指定的字符。
yield line.strip('\r\n')
if i % 100000 == 0:
print ('loading %s(%s)' % (filename, i), file=sys.stderr)
fp.close()
print ('load %s succ' % filename, file=sys.stderr)
def generate_dataset(self, filename, pivot=0.7):
''' 加载数据并且将数据划分为训练集和测试集'''
trainset_len = 0
testset_len = 0
for line in self.loadfile(filename):
user, movie, rating, _ = line.split('::')
# 按照pivot=0.7 比例划分
if random.random() < pivot:
'''训练集 数据为 {userid,{moveiesid,rating。。。。}}'''
self.trainset.setdefault(user, {})
self.trainset[user][movie] = int(rating)
trainset_len += 1
else:
'''测试集 数据为 {userid,{moveiesid,rating....}}'''
self.testset.setdefault(user, {})
self.testset[user][movie] = int(rating)
testset_len += 1
print ('划分数据集成功', file=sys.stderr)
print ('训练集 = %s' % trainset_len, file=sys.stderr)
print ('测试集 = %s' % testset_len, file=sys.stderr)
def calc_movie_sim(self):
''' 记录电影被观看过的次数,从而反映出电影的流行度'''
print('counting movies number and popularity...', file=sys.stderr)
# 计算电影的流行度 实质是一个电影被多少用户操作过(即看过,并有评分) 以下数据虚构
'''{'914': 23, '3408': 12, '2355': 4, '1197': 12, '2804': 31, '594': 12 .....}'''
for user, movies in self.trainset.items():
for movie in movies:
# count item popularity
if movie not in self.movie_popular:
# 如果电影第一次出现 则置为0 假如到字典中。
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
print('count movies number and popularity succ', file=sys.stderr)
# 计算总共被看过的电影数
self.movie_count = len(self.movie_popular)
print('total movie number = %d' % self.movie_count, file=sys.stderr)
# 根据用户使用习惯 构建物品相似度
itemsim_mat = self.movie_sim_mat
print('building co-rated users matrix...', file=sys.stderr)
'''以下为数据格式,通过for循环依次遍历训练集,找到两个电影之间,如果被一个人同时看过,则累加一'''
#{'914': defaultdict( , {'3408': 1, '2355': 1 , '1197': 1, '2804': 1, '594': 1, '919': 1})}
for user, movies in self.trainset.items():
for m1 in movies:
itemsim_mat.setdefault(m1, defaultdict(int))
for m2 in movies:
if m1 == m2:
continue
itemsim_mat[m1][m2] += 1
print('build co-rated users matrix succ', file=sys.stderr)
# calculate similarity matrix
print('calculating movie similarity matrix...', file=sys.stderr)
simfactor_count = 0
PRINT_STEP = 2000000
# 计算用户相似度矩阵
# 先取得特定用户
for m1, related_movies in itemsim_mat.items():
for m2, count in related_movies.items():
# 以下公式为 两个a,b电影共同被喜欢的用户数/ 根号下(喜欢电影a的用户数 乘 喜欢电影 b的用户数)
itemsim_mat[m1][m2] = count / math.sqrt(
self.movie_popular[m1] * self.movie_popular[m2])
simfactor_count += 1
if simfactor_count % PRINT_STEP == 0:
print('calculating movie similarity factor(%d)' %
simfactor_count, file=sys.stderr)
print('calculate movie similarity matrix(similarity factor) succ',
file=sys.stderr)
print('Total similarity factor number = %d' %
simfactor_count, file=sys.stderr)
'''找到K个相似电影 并推荐N个电影'''
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
watched_movies = self.trainset[user]
for movie, rating in watched_movies.items():
# 对于用户看过的每个电影 都找出其相似度最高的前K个电影
for related_movie, similarity_factor in sorted(self.movie_sim_mat[movie].items(),
key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
# 假如评分权重,
rank[related_movie] += similarity_factor * rating
# 返回综合评分最高的N个电影
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 计算准确率,召回率,覆盖率,流行度
def evaluate(self):
''' print evaluation result: precision, recall, coverage and popularity '''
print('Evaluation start...', file=sys.stderr)
N = self.n_rec_movie
# varables for precision and recall
hit = 0
rec_count = 0
test_count = 0
# varables for coverage
all_rec_movies = set()
# varables for popularity
popular_sum = 0
for i, user in enumerate(self.trainset):
if i % 500 == 0:
print ('recommended for %d users' % i, file=sys.stderr)
test_movies = self.testset.get(user, {})
rec_movies = self.recommend(user)
for movie, _ in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
popular_sum += math.log(1 + self.movie_popular[movie])
rec_count += N
test_count += len(test_movies)
# 准确率 = 推荐中的电影/总推荐的电影
precision = hit / (1.0 * rec_count)
# 召回率 = 推荐中的电影/测试集中所有电影数目
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
popularity = popular_sum / (1.0 * rec_count)
print ('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f' %
(precision, recall, coverage, popularity), file=sys.stderr)
if __name__ == '__main__':
ratingfile = os.path.join('ml-1m', 'ratings.dat')
itemcf = ItemBasedCF()
itemcf.generate_dataset(ratingfile)
itemcf.calc_movie_sim()
print(itemcf.recommend('1'))
#itemcf.evaluate()
代码多谢 大神提供代码
https://github.com/Lockvictor/MovieLens-RecSys
以下是我添加了数据集和注解后的代码
https://github.com/guoyiguang/Recommend
