小样本学习综述Generalizing from a Few Examples-A Survey on Few-Shot
这是我的第一篇写在CSDN上的博客,日后有空的话会持续更新一些关于小样本学习和弱监督半监督医学图像相关的论文笔记和代码。。。估计也没啥人看,就当给自己看。
话不多说,先贴上论文链接https://arxiv.org/abs/1904.05046,小样本学习是一个非常有前景的方向,这篇综述也在持续更新中,非常值得一读。
摘要
机器学习在数据密集型应用中非常成功,但当数据集很小时,它常常受到阻碍。为了解决这一问题,近年来提出了小样本学习(FSL)。利用先验知识,FSL可以快速地泛化到只包含少量有监督信息的样本的新任务中。在这篇论文中,我们进行了一个彻底的调研,以充分了解FSL。从FSL的正式定义出发,我们将FSL与几个相关的机器学习问题区分开来。然后指出了FSL的核心问题是经验风险最小化是不可靠的。
基于先验知识如何处理这一核心问题,从三个角度对FSL方法进行了分类:
(i)数据,它使用先验知识来增加监督经验
(ii)利用先验知识缩小假设空间大小的模型
(iii)算法,利用先验知识在给定的假设空间中改变对最佳假设的搜索。有了这种分类法,我们就可以回顾和讨论每个类别的优缺点。在FSL问题的设置、技术、应用和理论方面也提出了有前景的方向,为未来的研究提供了见解
概述
FSL的意义
(1):让机器表现得更像人
(2):从稀有样本中学习(例如药物毒性,稀有病例等)
(3):减少数据收集工作和计算成本
FSL与其他学习方法的区别和联系
弱监督学习(Weakly supervised learning):根据定义,不完全监督的弱监督学习只包括分类和回归,而FSL也包括强化学习问题。此外,不完全监督的弱监督学习主要使用未标记数据作为E中的附加信息,而FSL利用了各种先验知识,如预先训练的模型、来自其他领域或模式的监督数据,并不限制使用未标记数据。因此,只有当先验知识为无标记数据且任务为分类或回归时,FSL才成为弱监督学习问题。
不平衡学习(Imbalanced learning):此方法通常需要利用所有的不平衡样本来进行训练,而FSL只需要利用少量样本做训练和测试,其它的样本则作为先验知识。
迁移学习(Transfer learning):迁移学习方法在FSL中被广泛使用,该方法将先验知识从源任务转移到few-shot任务。
元学习(Meta-learning):通过提供的数据集和meta-learner在多个任务中提取的元知识提高了目标(新的)任务的最终表现,通俗地来说就是获得了可以应用在目标任务上的共性知识(从多种任务中学习得到)。元学习是一种学习学习能力的方法,这种方法在FSL任务中有着非常好的应用。
说白了FSL可以是各种形式的学习,监督,半监督,强化学习,迁移学习等等,本质上的定义取决于可用的数据,只不过现在对于小样本学习来说,最具价值的当属元学习。
一些数学符号的意义
考虑一个学习任务 T T T,FSL处理一个数据集 D = { D t r a i n , D t e s t } D=\left\{ D_{train},D_{test} \right\} D={ Dtrain,Dtest},训练集表示为 D train = { ( x i , y i ) } i = 1 I D_{\text {train }}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{I} Dtrain ={ (xi,yi)}i=1I, I I I表示一个较小的值(也就是小样本),测试集表示为 D t e s t = { x t e s t } D_{test}=\left\{ x^{test} \right\} Dtest={ xtest} 。 p ( x , y ) p(x,y) p(x,y) 表示输入 x x x和输出 y y y的ground-truth联合概率分布, h ^ \hat{h} h^ 表示从 x x x到 y y y的最优假设(optimal hypothesis)。FSL的学习目标就寻找一个 h ^ \hat{h} h^可以很好地拟合 D t r a i n D_{train} Dtrain和 D t e s t D_{test} Dtest,为了逼近 h ^ \hat{h} h^,FSL模型决定了一个假设 h ( ⋅ ; θ ) h\left( \cdot ;\theta \right) h(⋅;θ)的假设空间 H \mathcal{H} H, θ \theta θ表示 h h h所使用的所有参数。FSL算法的目的就是在假设空间 H \mathcal{H} H中寻找最优参数 θ \theta θ,得到最优参数模型 h ∗ ∈ H h^*\in \mathcal{H} h∗∈H。FSL算法的性能通过损失函数 ℓ ( y ^ , y ) \ell \left( \hat{y},y \right) ℓ(y^,y)表示,其中 y ^ = h ( x ; θ ) \hat{y}=h(x;\theta) y^=h(x;θ)表示预测值。
核心问题
在训练模型中,我们是通过训练集来拟合真实分布,我们训练出来的分布和真实分布往往不一样,这中间的差值称为期望风险(期望损失),表达式如下:
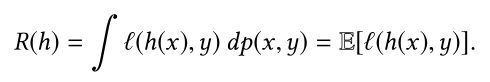
从理论上来说,对于一个模型而言,我们最希望的就是期望风险最小化,但是在实际上 p ( x , y ) p(x,y) p(x,y)是未知的(我们想要学习的就是这个分布,那么现在当然还不知道)。因而在估算风险(损失)的时候通常使用经验风险(损失)来替代期望风险(损失)。经验风险表示在训练集上预测的结果和真实结果的差异:
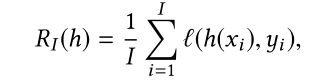
定义如下表示:
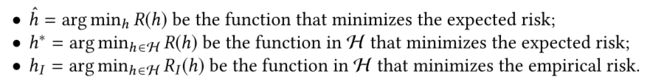
h ^ \hat{h} h^表示最小期望风险, h ∗ h^* h∗表示在假设空间 H \mathcal{H} H中的最小期望风险, h I h_{I} hI表示在假设空间 H \mathcal{H} H中最小经验风险。
PS:关于经验风险和期望风险如果不清楚可以参考https://blog.csdn.net/liyajuan521/article/details/44565269
总损失可以表示为如下式子:
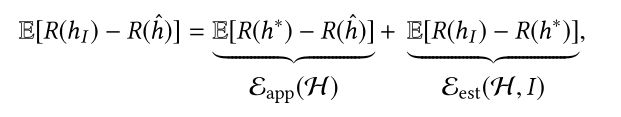
也就是说总误差可以由两部分组成,一是 h ∗ h^* h∗到 h ^ \hat{h} h^的近似误差,这部分表示的是假设空间 H \mathcal{H} H中最优假设和真实假设的误差,这一项其实由你所选择的模型和参数的初始化分布决定的,通俗来说就是欠拟合;二是 h I h_{I} hI到 h ∗ h^* h∗的估计误差,这部分就是我们训练得到的假设和 H \mathcal{H} H中最优假设的误差,我们训练得到的假设也是从假设空间H中选择的,但有时候会陷入局部最优,或者提供的训练数据分布有偏差,导致无法到全局最优。
PS:关于近似误差和估计误差的解释https://www.zhihu.com/question/60793482/answer/248437399
不可靠的经验风险最小化:
通常来说,我们可以通过扩大样本量来减小估计误差,但对FSL来说这么做显然是不行的,对少量的样本进行训练所导致的过拟合其实就是不可靠的经验风险最小化。
结合下面这张图可以很好地理解上述内容:
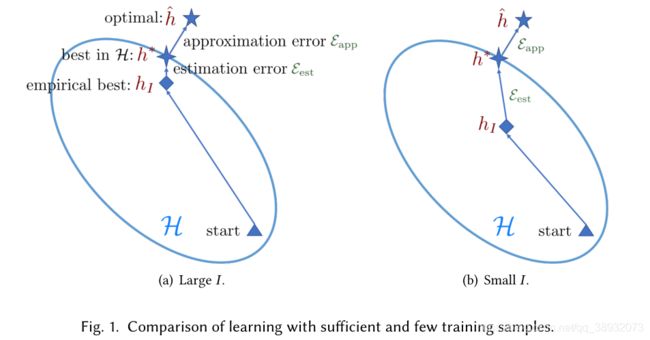
说白了,对于FSL任务而言,我们主要要解决的就是估计误差过大的问题。
如何解决FSL任务
先验知识:
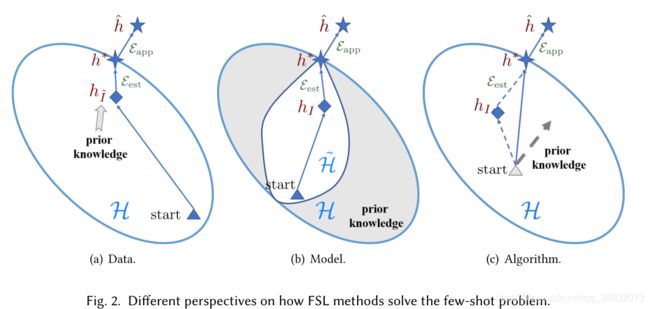
(1).从数据层面考虑,可以通过数据扩充的方面来增加样本量,从而使得一般的学习算法可以适用于FSL任务。
(2).从模型层面考虑,使用先验知识来约束假设空间 H \mathcal{H} H,如上图所示通过某些方法把那些不太可能到达最优假设的部分剔除。
(3).从算法层面考虑,例如优化初始化方法,优化搜索策略等,对于后者而言,对策略优化时通常考虑到先验知识所带来的帮助。
下面这张表很好地展示了可以从哪些方面解决FSL任务:
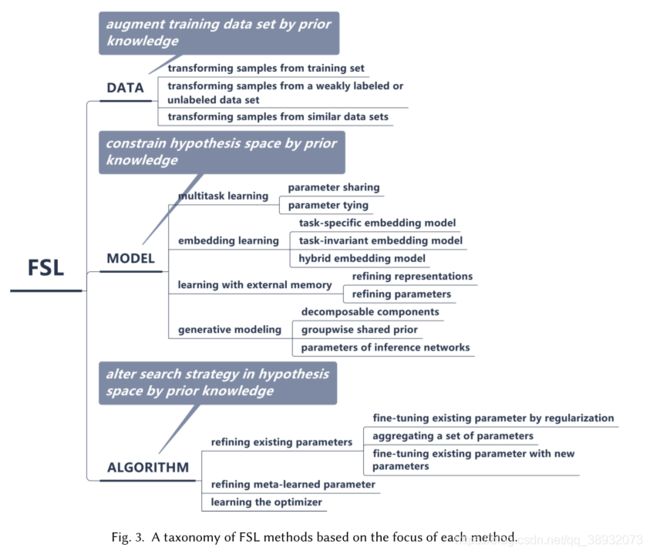
基于数据
利用手工的方法对图像进行裁剪,旋转等操作可以在一定程度上扩充数据,但这种方法严重依赖于专业知识,且通常只能针对特定数据集,难以迁移。
下表展示了一些较常用的数据扩充方法:
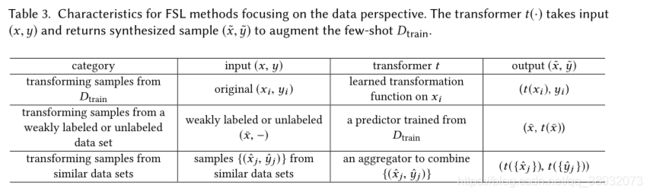
第一种是从数据集中变换数据来达到扩充数据的目的,可以利用一些传统的机器学习方法,例如构造一个函数将不同类别之间的变化性施加到原始样本中从而增加样本数量。
第二种是充分利用弱标签或无标签数据,这两类数据相对比较容易获取,同时可以通过构造预测器通过对完全监督标签数据进行学习来给这两类弱或无标签数据打上更为完善且易于学习的标签,再将这些数据加入原始数据集。
第三种是利用与目标数据集相似的但更为庞大数据集进行数据生成,例如可以利用生成对抗网络(GAN)来进行数据生成,实际上GAN在数据生成方面有着巨大价值。
总的来说,数据扩充是一种相对易于理解且直截了当的方法,但数据扩充所得到的数据集通常只能针对特定的任务,而且大多数扩充方法只在图像领域有着较好效果,而对于文本、音频等包含语法和结构的信息进行扩充到目前为止还是比较困难的。
基于模型
通过先验知识来对假设空间进行约束,使经验风险最小化更加可靠并降低过拟合风险,下面是基于模型的常用FSL方法:
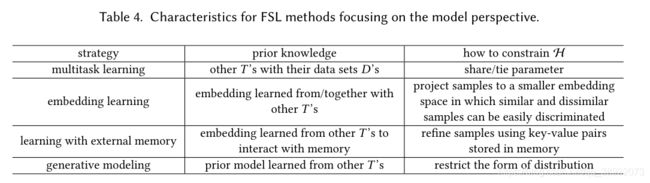
多任务学习(Multitask Learning)
简单来说就是提供了很多个相关的任务和它们的对应数据集,这些数据集可以有很少样本也可以有很多样本。这些任务是共同学习的,因此可以利用别的任务参数(模型)来对目标参数(模型)进行约束,也就是约束了假设空间。这种方法主要分为参数共享和参数绑定两类。
参数共享:顾名思义在多个任务之间共享参数,当然并不是完全共享的,例如两个任务网络共享用于获取通用或者说表层信息的的前几层,而学习不同的最终层来处理不同的输出。
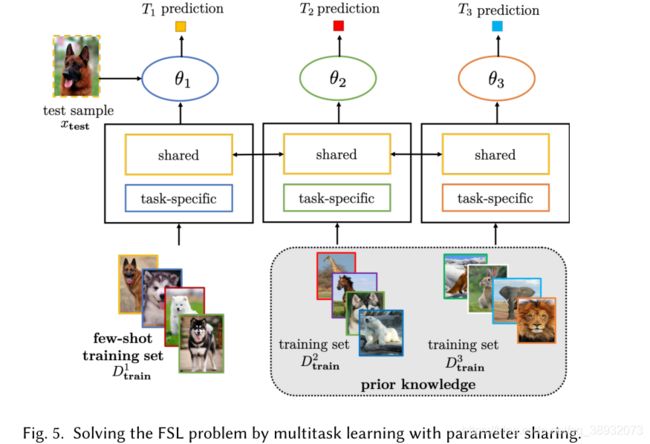
参数绑定:这是一种让参数变得相似的策略,最流行的方法是对不同任务的参数进行正则化,例如对任务中成对的参数进行惩罚,其实就是让不同任务的假设空间相似,从而在解决较易任务的时候同时解决了较难任务,也就是FSL。
嵌入学习(Embedding learning)
嵌入学习其实就是通过构建一个函数将所有样本转换到一个低维空间 Z \mathcal{Z} Z中,使得相似的样本更为接近,而不相似的样本则更加容易区分,这样一来在这个低维空间中便可以构建一个受约束的更小的假设空间。
嵌入学习中几个关键组成:将测试样本嵌入到 Z \mathcal{Z} Z中的函数 f ( ⋅ ) f(\cdot) f(⋅);将训练样本嵌入到 Z \mathcal{Z} Z中的函数 f ( ⋅ ) f(\cdot) f(⋅);用于衡量 f f f和 g g g在 Z \mathcal{Z} Z中相似度的函数 s ( ⋅ , ⋅ ) s(\cdot,\cdot) s(⋅,⋅)
嵌入学习根据不同的任务可分为task-specific,task-invariant和hybrid 三种。
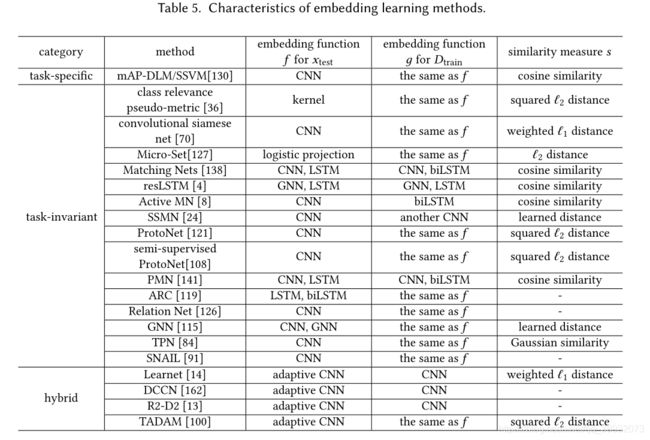
Task-specific是在任务自身的训练集上训练的,通过构造同类样本相同,不同类样本不同的样本对作为数据集,这样数据集会有一个极大的扩充,以提高最终模型的复杂度。
Task-invariant通过在不同输出的大规模数据集上学习通用的嵌入函数,然后直接用于当前任务而无需重新训练。
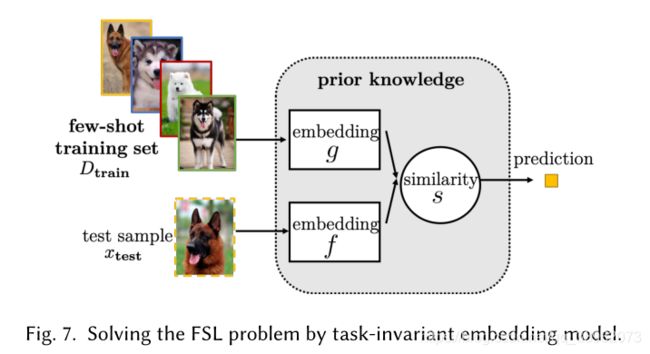
最近,更复杂的Task-invariant模型通过元学习的方法得到,例如匹配网络(Matching Nets),原型网络(Prototypical Networks)等。
尽管Task-invariant方法可以应用于新任务,且计算成本较低,但它们不利用当前任务的特定知识。Hybrid Embedding Models利用 D t r a i n D_{train} Dtrain中task-specific信息,从先验知识中学习到通用的 task-invariant 嵌入模型。
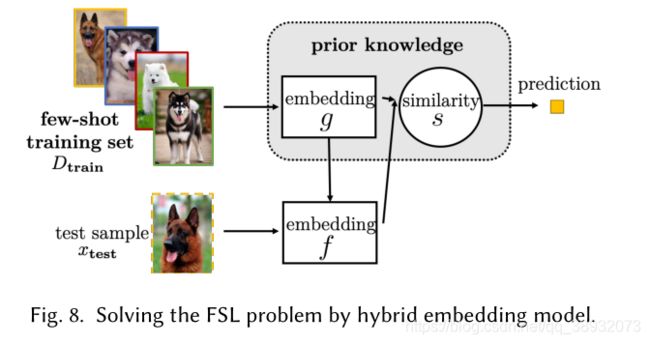
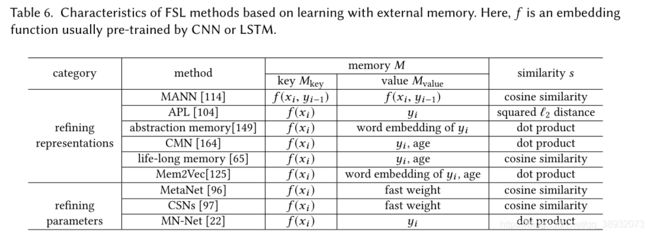
外部记忆学习(Learning with External Memory)
该方法通过从 D t r a i n D_{train} Dtrain中提取知识并将其存储在外部记忆中,每一个新的测试样本 x t e s t x_{test} xtest用从memory中提取的内容的加权平均值来表示。这限制了 x t e s t x_{test} xtest只能用memory中的内容来表示,从而减小了假设空间。
 可以注意到,这里同样使用了一个嵌入函数 f f f,然而不同与前面提到的嵌入学习, f ( x t e s t ) f(x_{test}) f(xtest)并不是直接用来表示 x t e s t x_{test} xtest,而只是用于在memory中查询最相似的节点。
可以注意到,这里同样使用了一个嵌入函数 f f f,然而不同与前面提到的嵌入学习, f ( x t e s t ) f(x_{test}) f(xtest)并不是直接用来表示 x t e s t x_{test} xtest,而只是用于在memory中查询最相似的节点。
这部分看上去简单但又好像有些东西很模糊。。。以后搞懂了再具体分析
生成模型(Generative Modeling)
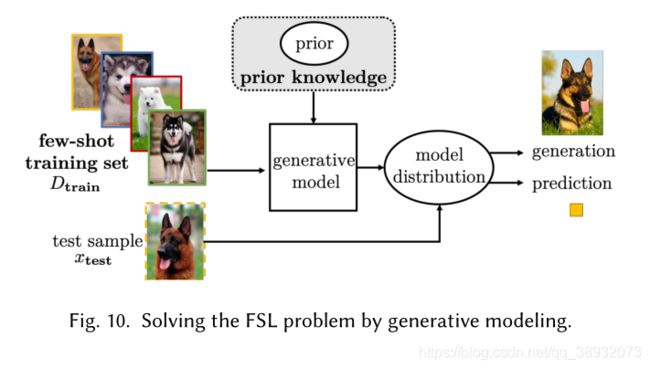
说白了就是从其他大规模的数据集中学习先验知识或者在生成模型中可以称之为的“潜变量”,也就是得到了一组先验分布,通过这个先验分布来约束后验分布以起到限制假设空间大小的作用。根据潜变量所指代的内容,生成模型方法可以分为Decomposable Components,Groupwise Shared Prior和Parameters of Inference Networks。
Decomposable Components:尽管在FSL问题中具有监督信息的样本很少,但它们可能与其他任务中的样本共享一些较小的可分解组件。例如,只使用提供的几张人脸照片就可以识别一个人。虽然相似的面孔可能很难找到,但有相似眼睛、鼻子或嘴巴的照片很容易找到。有了大量的样本,这些可分解组件的模型就很容易学习了。然后,只需找到这些可分解组件的正确组合,并决定该组合属于哪个目标类。
Groupwise Shared Prior:通常,相似的任务有相似的先验概率,这可以在FSL中使用。例如,考虑“橙色猫”、“豹”和“孟加拉虎”的三类分类。这三个物种很相似,但孟加拉虎濒临灭绝,而橙色猫科动物和豹子数量众多。因此,你可以从“橙色猫”和“豹子”中学到先验概率,并将其作为few-shot类“孟加拉虎”的先验知识。
Parameters of Inference Networks:要找到最佳的 θ θ θ,就必须最大化后验分布:
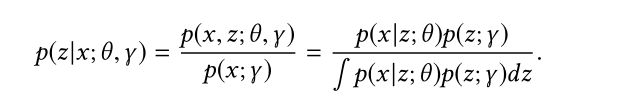
可以看到解决第三个式子的分母部分积分是比较困难的,这里主要使使用了“变分推断”来解决这一问题,这部分的知识实际上比较复杂,属于变分自编码和生成对抗的核心思想,文中并未介绍地很清楚,有兴趣的可以自行查阅相关资料。
方法总结
当存在一个包含各种类足够样本的大规模数据集时,可以使用嵌入学习方法。这些方法将样本映射到一个良好的嵌入空间,在该空间中可以很好地分离来自不同类别的样本,因此需要一个较小的 H \mathcal{H} H。然而,当few-shot任务与其他任务没有紧密联系时,它们可能就不能很好地工作。此外,更多的探索如何混合任务的不变信息和特定任务的信息是有帮助的。
当一个memory network可用时,通过在内存上训练一个简单的模型(例如分类器),可以很容易地将其用于FSL。通过精心设计的更新规则,可以有选择地保护内存slots。这种策略的缺点是它会导致额外的空间和计算成本,这些成本会随着内存大小的增加而增加。
最后,当想要完成FSL之外的生成和重构等任务时,可以使用生成模型,它们从其它数据集中学习先验概率以缩减假设空间大小。学习到的生成模型还可以用于生成样本以进行数据增强。然而,生成式建模方法推理成本高,而且比确定性模型更难推导。
基于算法
在样本充足的情况下,我们通常会使用基于SGD的方法来更新参数,但是在FSL任务中,样本数量很少,这种方法不再有效,导致不可靠的经验风险最小化。根据先验知识对搜索策略的影响,可将本节的方法分为三组:

改进现有参数( Refining Existing Parameters)
这种方法从其他相关任务的预训练网络中学习到一个较好的初始化参数,这么做是假设了我们能够从大规模的数据中提取到一般信息,将这些信息应用到FSL任务中,便只需要较少的迭代次数来更新最终参数。
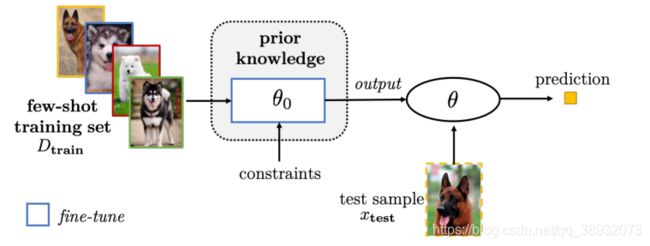
通过正则化对现有参数进行微调
这里说的其实就是预训练+微调的方法,但是这种方法对于小样本学习而言很容易导致过拟合,所以可以采用一些深度学习中常用的trick来避免过拟合,如早停法,选择性更新参数或只更新关联参数。
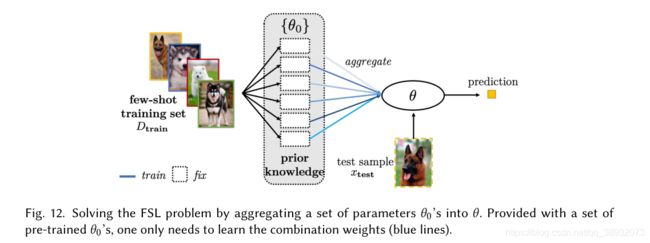
参数聚合
我们有许多从相关任务中学习到的模型。例如,在人脸识别方面,我们可能已经有了眼睛、鼻子和耳朵的识别模型。因此,可以将这些模型参数聚合为合适的模型,然后由 D t r a i n D_{train} Dtrain直接使用或进一步调整优化。
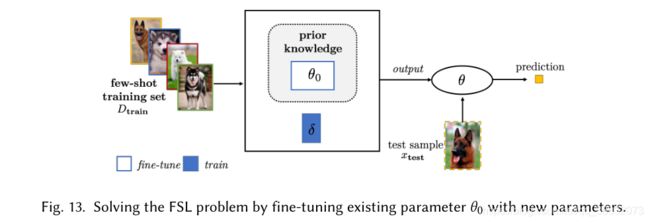
用新参数微调现有参数
仅仅使用预训练模型的参数对于FSL任务而言可能并不足够,因此可以考虑在预训练参数的基础上再加入额外的参数来学习 D t r a i n D_{train} Dtrain的特定知识。
改进Meta-Learned参数

注: Φ \varPhi Φ表示task-specific parameter
这里主要考虑的是MAML方法,元学习中最重要的优化方法之一。该方法的设想是训练一组初始化参数,通过在初始参数的基础上进行一或多步的梯度调整,来达到仅用少量数据就能快速适应新task的目的。为了达到这一目的,训练模型需要最大化新task的loss function的参数敏感度(maximizing the sensitivity of the loss functions of new tasks with respect to the parameters),当敏感度提高时,极小的参数(参数量)变化也可以对模型带来较大的改进。
MAML 专注于提升模型整体的学习能力,而不是解决某个具体问题的能力,因此,它的训练数据是以 task 为基本单位的,每个 task 都有自己独立的损失函数。训练时,不停地在不同的 task 上切换,从而达到初始化网络参数的目的,最终得到的模型,面对新的 task 时可以学习得更快。
具体实施步骤可移步至原始论文:MAML:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
当然MAML仍然存在一些问题,可以考虑从以下方面改进:
(1)合并特定任务信息。MAML为所有任务提供相同的初始化。但是,这忽略了特定于任务的信息,并且仅在任务集非常相似时才适用。
(2)利用元学习的不确定性进行建模。只学习几个例子不可避免地导致模型具有更高的不确定性。因此,学习到的模型可能无法对新任务进行高可信度的预测。测量这种不确定性的能力为主动学习和进一步的数据收集提供了提示。
(3)改进refine程序。只是通过少量梯度下降步骤就进行细化可能不可靠,可考虑正则化以修正下降方向,例如利用回归网络(Regression Network)。
学习优化器(Learning the Optimizer)
在上一节中,使用了元学习方法来初始化参数,而本节则是使用元学习方法来学习一个优化策略,也就是所谓的学习如何学习(learn to learn)。
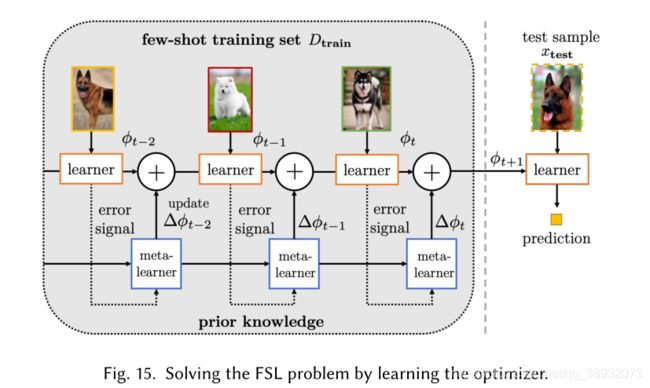
在这里可以直接输出参数更新部分 Δ θ \varDelta \theta Δθ,这样就不需要调整步长 α \alpha α或寻找搜索方向,因为学习算法会自动做到这一点。Fig.15中使用了一个RNN来更新参数,这里一方面更新了learner的参数,同时也更新了meta-learner的参数。
下面这个式子表示了更新的过程:
θ t + 1 = θ t + g t ( ∇ f ( θ t ) , ϕ ) \theta _{t+1}=\theta _t\,\,+g_t\left( \nabla f\left( \theta _t \right) ,\phi \right) θt+1=θt+gt(∇f(θt),ϕ)
g t g_{t} gt指的就是通过元学习器训练出来的优化方法。
方法总结
改进现有的参数有效减小的假设空间大小,同时降低了计算开销,但由于初始化参数终归是从别的与目标任务不同的任务中得到的,无可避免地导致了一定的精度损失。
元学习的方法是一种新兴的教会机器如何学习的方法,然而,一些重要的问题,如如何跨不同粒度(如动物的粗粒度分类与狗的细粒度分类)或不同数据源(如图像与文本)进行元学习仍是问题。从这个角度来看,元学习和多任务学习是相似的,所以如何避免负迁移也是一个值得关注的问题。
未来的工作
问题
目前的FSL方法通常使用来自单一模态(图像,文本或视频)的先验知识。实际任务中,有可能你这个模态的样本很少,但另一个模态下的样本却很充足。例如灭绝的动物,也许这种动物只有很少的视觉样本,但它可能存在大量的文本样本。因此多模态下考虑FSL任务是很有价值的,事实上,在ZSL(zero-shot learning)中,这是一种很常用的方法,现在已经有不少研究者在考虑将ZSL方法迁移到FSL中,在未来,一个有希望的方向就是考虑使用多模态信息来设计FSL方法。
技术
基于元学习的FSL方法特别有趣。元学习通过跨任务学习,可以以很小的推理代价快速适应新任务。但是目前的元学习通常考虑从相关联的任务中提取信息,实际上,很多任务是否关联是完全未知或难以决定的(代价高昂)。此外,目前的FSL方法往往考虑静态和固定的任务。然而,在流媒体应用中,任务是动态的,新的任务不断地到达。一个重要的问题是如何避免在动态设置中的灾难性遗忘,这意味着旧任务的信息不应该被遗忘。
不同的FSL方法各有优缺点,在所有的设置中都没有绝对的赢家。此外,假设空间和搜索策略通常都依赖于人的设计。自动化机器学习(AutoML)通过构建任务感知的机器学习模型,在许多应用中取得了最先进的水平。另一个方向是将自动化特征工程、模型选择和神经结构搜索的自动化方法扩展到FSL。这样就可以获得更好的算法设计,AutoML以一种经济、高效和有效的方式学习这些方法。