声明:本系列博客为原创,最先发表在拉勾教育,其中一部分为免费阅读部分。被读者各种搬运至各大网站。所有其他的来源均为抄袭。
《2021年最新版大数据面试题全面开启更新》
一、说好的流批一体呢?
1、现状
Flink并没有安全支持所谓的“流批一体”,即编写一套代码,可以同时支持流式计算和批量计算的场景。目前版本1.10依然采用DataSet和DataStream两套API来适配不同的应用场景。
2、DataSet和DataStream的区别和联系
Flink诞生支持的设计哲学就是:用同一个引擎支持多种形式的计算,包括批处理、流处理和机器学习。尤其在流式计算方面,Flink实现了计算引擎级别的流批一体。对于普通开发者而言,如果要使用原生的Flink,直接的感受还是要编写两套代码。
整体架构如下:

在Flink源码中,可以在flink-java这个模块中找到所有关于DataSet的核心类,DataStream的核心类则在flink-streaming-java这个模块中。


打开DataSet和DataStream两个类,二者支持的API都非常丰富且十分类似,比如常用的map、fliter、join等常见的transformation函数。
对于DataSet而言,Source部分来源于文件、表或者Java集合;而DataStream的Source来源于一般都是消息中间件比如Kafka等。
由于Flink DataSet和DataStream API的高度相似,并且Flink在实时计算领域中的应用更为广泛,下面主要讲解DataStream API 的使用。
二、DataStream
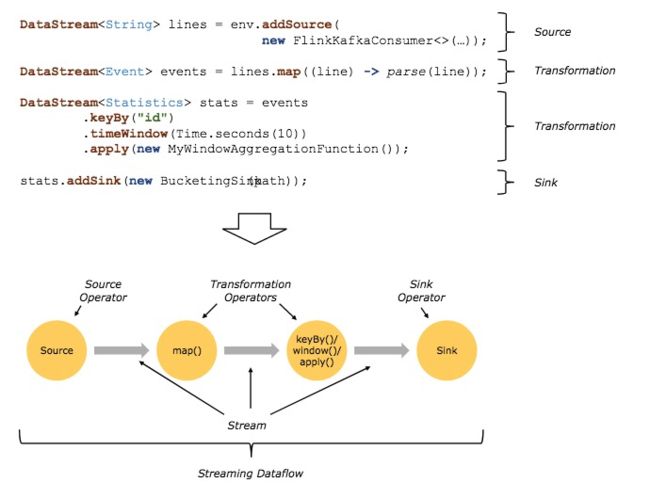
Flink的基础构建模块就是流(Streams)和转换(Transformations),每一个数据流起始于一个或多个Source,并终止于一个或多个Sink,类似有向无环图(DAG)。
1、自定义实时数据源
利用Flink提供的自定义Source的功能来实现一个自定义的实时数据源,具体如下:
public class MyStreamingSource implements SourceFunction {
private boolean isRunning = true;
/**
* 重写run方法产生一个源源不断的数据发送源
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext- ctx) throws Exception {
while(isRunning){
Item item = generateItem();
ctx.collect(item);
//每秒产生一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
//随机产生一条商品数据
private Item generateItem(){
int i = new Random().nextInt(100);
Item item = new Item();
item.setName("name" + i);
item.setId(i);
return item;
}
class Item{
private String name;
private Integer id;
Item() {
}
public String getName() {
return name;
}
void setName(String name) {
this.name = name;
}
private Integer getId() {
return id;
}
void setId(Integer id) {
this.id = id;
}
@Override
public String toString() {
return "Item{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
}
class StreamingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource text =
//注意:并行度设置为1,我们会在后面的课程中详细讲解并行度
env.addSource(new MyStreamingSource()).setParallelism(1);
DataStream item = text.map(
(MapFunction) value -> value);
//打印结果
item.print().setParallelism(1);
String jobName = "user defined streaming source";
env.execute(jobName);
}
}
在自定义Source中,实现了Flink的SourceFunction接口,同时实现了其实的run方法,在run方法中每隔一秒随机发送一个自定义的Item。我们查看运行结果:

从控制台中看到,数据不断输出。
2、Map
Map接受一个元素作为输入,并且根据开发者自定义的逻辑处理后输出。
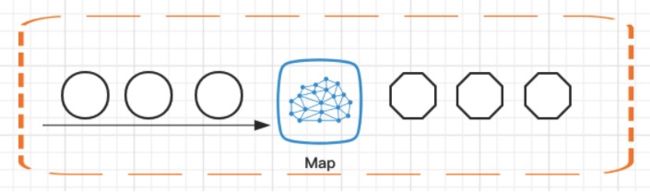
Map算子是最常用的算子之一。从源DataStream到目标DataStream的转换过程中,返回的是SingleOutputStreamOpeartor。我们也可以在重写的Map函数中使用lamba表达式。
SingleOutputStreamOperator