在本系列的上一篇《Netty 内存管理: PooledByteBufAllocator & PoolArena 代码探险》中,我们最终通过设置合适的 JVM 启动参数 —— DirectMemorySize最小应设置为chunkSize(16M)的6倍:
-XX:MaxDirectMemorySize=96M
-Dio.netty.allocator.type=pooled
这样 API网关 xharbor 启动后,得以使用 netty 的最佳内存管理策略:池化的堆外直接内存(Pooled DirectByteBuf)。古语云:知己知彼 百战不殆。在享受高效内存管理机制的大餐前,我们得先来看看,能否做到对内存的使用做到知根知底,也就是回答上篇文章留下的两个问题:
如何才能及时无误的查看 xharbor 中是否存在泄漏?
netty 中有什么的便利的设施供我们使用吗?
Netty 中内置的池化内存管理指标
代码是检验一切的标准。让我们再回到 netty 那优美而深邃的代码中去探险吧...... 只是因为在人群中多看了你一眼...... PoolArena 的定义,就有了大发现,原来 PoolArena 实现了一个名为 PoolArenaMetric 的接口,让我们把 PoolArenaMetric 的定义拿出来晒晒吧:
public interface PoolArenaMetric {
/** 返回所有通过该 arena 完成的内存分配动作数量,包括所有尺寸(tiny/small/normal/huge)
* Return the number of allocations done via the arena. This includes all sizes.
*/
long numAllocations();
/** 返回通过该 arena 完成的 tiny 尺寸的内存分配动作数量
* Return the number of tiny allocations done via the arena.
*/
long numTinyAllocations();
/** 返回通过该 arena 完成的 small 尺寸的内存分配动作数量
* Return the number of small allocations done via the arena.
*/
long numSmallAllocations();
/** 返回通过该 arena 完成的 normal 尺寸的内存分配动作数量
* Return the number of normal allocations done via the arena.
*/
long numNormalAllocations();
/** 返回通过该 arena 完成的 huge 尺寸的内存分配动作数量
* Return the number of huge allocations done via the arena.
*/
long numHugeAllocations();
/** 返回所有通过该 arena 完成的内存释放动作数量,包括所有尺寸(tiny/small/normal/huge)
* Return the number of deallocations done via the arena. This includes all sizes.
*/
long numDeallocations();
/** 返回通过该 arena 完成的 tiny 尺寸的内存释放动作数量
* Return the number of tiny deallocations done via the arena.
*/
long numTinyDeallocations();
/** 返回通过该 arena 完成的 small 尺寸的内存释放动作数量
* Return the number of small deallocations done via the arena.
*/
long numSmallDeallocations();
/** 返回通过该 arena 完成的 normal 尺寸的内存释放动作数量
* Return the number of normal deallocations done via the arena.
*/
long numNormalDeallocations();
/** 返回通过该 arena 完成的 huge 尺寸的内存释放动作数量
* Return the number of huge deallocations done via the arena.
*/
long numHugeDeallocations();
/** 返回该 arena 当前所有尺寸的活跃分配数量(已经分配但尚未释放)
* Return the number of currently active allocations.
*/
long numActiveAllocations();
/** 返回该 arena 当前 tiny 尺寸的活跃分配数量
* Return the number of currently active tiny allocations.
*/
long numActiveTinyAllocations();
/** 返回该 arena 当前 small 尺寸的活跃分配数量
* Return the number of currently active small allocations.
*/
long numActiveSmallAllocations();
/** 返回该 arena 当前 normal 尺寸的活跃分配数量
* Return the number of currently active normal allocations.
*/
long numActiveNormalAllocations();
/** 返回该 arena 当前 huge 尺寸的活跃分配数量
* Return the number of currently active huge allocations.
*/
long numActiveHugeAllocations();
/** 当前从操作系统申请的有效内存总数量
* Return the number of active bytes that are currently allocated by the arena.
*/
long numActiveBytes();
/** 返回持有该 arena 作为缓存的线程个数
* Returns the number of thread caches backed by this arena.
*/
int numThreadCaches();
/** tiny类型页面个数
* Returns the number of tiny sub-pages for the arena.
*/
int numTinySubpages();
/** small类型页面个数
* Returns the number of small sub-pages for the arena.
*/
int numSmallSubpages();
/** chunk个数
* Returns the number of chunk lists for the arena.
*/
int numChunkLists();
/** 返回所有 tiny 页面的链表
* Returns an unmodifiable {@link List} which holds {@link PoolSubpageMetric}s for tiny sub-pages.
*/
List tinySubpages();
/** 返回所有 small 页面的链表
* Returns an unmodifiable {@link List} which holds {@link PoolSubpageMetric}s for small sub-pages.
*/
List smallSubpages();
/** 返回所有chunk的链表
* Returns an unmodifiable {@link List} which holds {@link PoolChunkListMetric}s.
*/
List chunkLists();
}
上述接口方法重排了顺序,并根据内部实现进行中文翻译
原来在 PoolArena 中存在着巨大的宝库,它已经内置了详细的内存管理指标。我们暂时先把注意力集中到前面这15个内存分配/释放/活跃的指标上来,怀着激动的心情,我们再次分三组列出这些 可爱的探针:
# numXXXAllocations
numAllocations: 已完成的内存分配动作数量,包括所有尺寸(tiny/small/normal/huge)
numTinyAllocations: 已完成的 tiny 尺寸的内存分配动作数量
numSmallAllocations: 已完成的 small 尺寸的内存分配动作数量
numNormalAllocations: 已完成的 normal 尺寸的内存分配动作数量
numHugeAllocations: 已完成的 huge 尺寸的内存分配动作数量
# numXXXDeallocations
numDeallocations: 已完成的内存释放动作数量,包括所有尺寸(tiny/small/normal/huge)
numTinyDeallocations: 已完成的 tiny 尺寸的内存释放动作数量
numSmallDeallocations: 已完成的 small 尺寸的内存释放动作数量
numNormalDeallocations: 已完成的 normal 尺寸的内存释放动作数量
numHugeDeallocations: 已完成的 huge 尺寸的内存释放动作数量
# numActiveXXXAllocations
numActiveAllocations: 当前所有尺寸的活跃分配数量(已经分配但尚未释放)
numActiveTinyAllocations: 当前 tiny 尺寸的活跃分配数量
numActiveSmallAllocations: 当前 small 尺寸的活跃分配数量
numActiveNormalAllocations: 当前 normal 尺寸的活跃分配数量
numActiveHugeAllocations: 当前 huge 尺寸的活跃分配数量
如果上面中文翻译的意思理解无误的话,我们来推测下这三组15个指标的特性:
- numXXXAllocations 和 numXXXDeallocations 均为只增指标,随着分配和释放行为的进行而增加,数值不断增加
- 如果没有内存泄漏,经过一段时间,系统的业务都处理完毕且没有新的业务产生,numXXXAllocations 应该和名称对应的 numXXXDeallocations 数值严格相等
- numActiveXXXAllocations 是当前时刻,对应的 numXXXAllocations 与 numXXXDeallocations 的差值
备注:关于 PoolArena 的四种内存分配尺寸,请参见 Netty内存池原理分析,此处不再赘述原因,只列出这四种内存分配类型的对应尺寸范围(bytes):
| 内存分配类型 | 最小字节数(含) | 最大字节数(含) |
|---|---|---|
| tiny | 1 | 511 |
| small | 512 | 8191(pageSize-1) |
| normal | 8192(pageSize) | 16777216(chunkSize) |
| huge | 16777217(chunkSize+1) | 无上限 |
展现 Netty 的内存管理指标
有了这些探针,接下来该把它们都拉出来干活了。Java系统中,如果说到展现 JVM 内信息,首推 JMX。
备注:JMX在Java编程语言中定义了应用程序以及网络管理和监控的体系结构、设计模式、应用程序接口以及服务。通常使用JMX来监控系统的运行状态或管理系统的某些方面。
Netty 中没有将这些指标导出为MBean,那么该程序员上了。在 xharbor 的依赖库 jocean-http 中,我添加了一个 POJO 类:PooledAllocatorStats 来达到这一目的,并通过 Spring 将其导出为 MBean: pooledstats,摘录部分代码如下:
public class PooledAllocatorStats {
public Map getMetrics() {
final PooledByteBufAllocator allocator = PooledByteBufAllocator.DEFAULT;
final Map metrics = new HashMap<>();
{
int idx = 0;
for (PoolArenaMetric poolArenaMetric : allocator.directArenas()) {
metrics.put("1_DirectArena[" + idx++ + "]",
metricsOfPoolArena(poolArenaMetric));
}
}
{
int idx = 0;
for (PoolArenaMetric poolArenaMetric : allocator.heapArenas()) {
metrics.put("2_HeapArena[" + idx++ + "]",
metricsOfPoolArena(poolArenaMetric));
}
}
return metrics;
}
private static Map metricsOfPoolArena(
final PoolArenaMetric poolArenaMetric) {
final Map metrics = new HashMap<>();
metrics.put("2_0_numAllocations",
poolArenaMetric.numAllocations());
metrics.put("2_1_numTinyAllocations",
poolArenaMetric.numTinyAllocations());
......
}
PooledAllocatorStats.java代码片段
Spring配置文件片段
简言之,其实现思路是获取 PooledByteBufAllocator 的全局实例 DEFAULT, 将heap类型和direct类型的 PoolArena 各项指标通过Map方式输出。
如何连接并展现 JVM 上的JMX,有多种成熟的实现:从 JDK 自带的 JConsole、Java Mission Control 到大型的商业工具。而我们的生产系统解决方案是在后端系统中整合 Jolokia 将 JMX 暴露为 REST API,并通过一个集中式的WEB服务:xbeacon 进行访问和展现。
关于 xbeacon 和 Jolokia 的整合将是另一个故事,将单开系列进行介绍,敬请期待......
PoolArena 分配之谜
有了趁手的工具,把这一切组装起来,上测试环境跑跑。在运行了一段时间,怀着忐忑的心情,打开 xbeacon 的MBean展示界面,定睛一看:
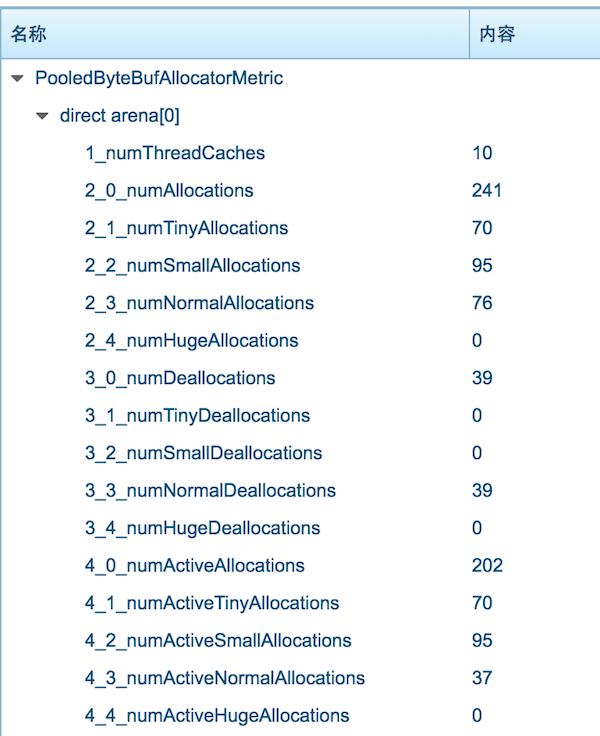
当时的界面截图如上, WTF!,为啥是这样的,有一路跟着开动脑筋的读者也应该明白了吧?竟然还有 202 个活跃分配存在,居然一个 tiny 和 small 类型的内存释放 都没有,normal 类型的内存分配倒是有对应的释放,但也才一半左右的分配释放掉了。有机灵的读者或许会提示: 是不是业务没有全部完成啊? BUT,通过另外的业务指标,我确认以及肯定,当前的API网关转发业务已经全部完成,而且没有的新的业务导入( 阿里云的 SLB 中已经将这个 xharbor 实例的服务器移除了
BTW,我们在重度使用阿里云,不过这是另外一个话题了)。
难道 xharbor 的代码中对于 ByteBuf 的使用一直有泄漏?并且漏的 一塌糊涂,tiny 漏,small 漏,连大于 8K 的 normal 都源源不断的在漏?基于现网环境已经很少出现 ByteBuf LEAK 提示了:
netty 应用的生产系统如果不断出现这样的提示:
ERROR |-i.n.u.ResourceLeakDetector:171 - LEAK: ByteBuf.release() was not called before it's garbage-collected. See http://netty.io/wiki/reference-counted-objects.html for more information.
稍有责任心的程序员都会战战惶惶 汗出如浆的......
抑制住内心的惶恐和急于翻查代码的冲动,再一次从 netty 的代码中寻找线索。终于接连从这几处地方找到提示:
tiny cache 分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
small cache 分配
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
normal cache 分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
而上述代码片段中的 cache 其实就是上一篇中已经看到的线程局部缓存,让我们再来回顾一下:
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena directArena = cache.directArena;
ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
if (PlatformDependent.hasUnsafe()) {
buf = UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
}
return toLeakAwareBuffer(buf);
}
在 Netty 主要贡献者:Norman Maurer 的一篇slide"Why Netty"我们也找到了线程局部缓存的说明:
- ThreadLocal caches for lock-free allocation
- PooledByteBufAllocator - without caches
- PooledByteBufAllocator - caches to the rescue!
好吧,假定上述的释放和分配的巨大差距是由于线程局部缓存造成的,摆在我们面前的有两个解决方法:
- 将所有线程中的有效局部缓存也纳入统计
- 完全禁用线程局部缓存这一机制
机智如我们程序员,会选择哪种方式嘞?对我相信绝大部分读者此时会像我一样...... 选择...... 禁用线程局部缓存(统计所有线程中局部缓存,引入的复杂性太高,性价比完全不合适么,再说,搞清楚了不存在泄漏,还可以再次打开线程局部缓存呀)
OK,再次上路。从 PooledByteBufAllocator 中找到如何禁用线程局部缓存的设置,参见相关代码如下:
DEFAULT_TINY_CACHE_SIZE =
SystemPropertyUtil.getInt(
"io.netty.allocator.tinyCacheSize", 512);
DEFAULT_SMALL_CACHE_SIZE =
SystemPropertyUtil.getInt(
"io.netty.allocator.smallCacheSize", 256);
DEFAULT_NORMAL_CACHE_SIZE =
SystemPropertyUtil.getInt(
"io.netty.allocator.normalCacheSize", 64);
将这三个属性都设置为0,即可禁用对应的线程局部缓存,因此连同上一篇的启动参数在内,此时我们将 xharbor 的 JVM 启动参数扩展为如下这5项:
-XX:MaxDirectMemorySize=96M
-Dio.netty.allocator.type=pooled
-Dio.netty.allocator.tinyCacheSize=0
-Dio.netty.allocator.smallCacheSize=0
-Dio.netty.allocator.normalCacheSize=0
加完上述的启动参数,再次将 xharbor 点火... 启动... 导入业务... 一段时间后... 关闭业务导入... 查看 xbeacon 上的指标:
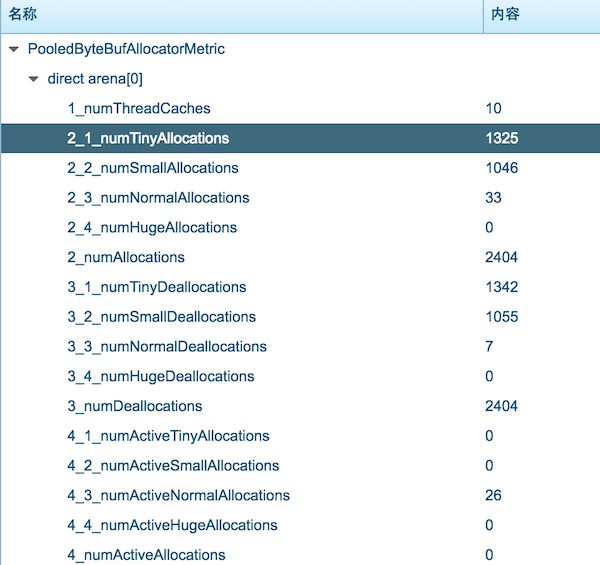
一个直观的感受是在大致相同的业务压力下,禁用线程布局缓存后,内存的分配多了好几倍,所以,缓存的确极大的减少了实际内存分配行为。另外,不错哦,numAllocations 和 numDeallocations 总算相同了,均为 2404。但隐隐总觉得哪里还有些...不对?!

如上图,我们用颜色把不太对劲的地方标注出来。似乎还有问题啊?
小结
本篇中,我们通过代码探险找到了 Netty 中内置的内存分配指标:** PoolArenaMetric**,并基于JMX将其可视的展现出来。接下来从指标的异常,找到了第一个坑:线程局部缓存,为了消除这一影响,我们将上一篇总结的 xharbor 启动参数从2个扩充为5个:
-XX:MaxDirectMemorySize=96M
-Dio.netty.allocator.type=pooled
-Dio.netty.allocator.tinyCacheSize=0
-Dio.netty.allocator.smallCacheSize=0
-Dio.netty.allocator.normalCacheSize=0
这下内存管理指标看起来已经合理多了,但其中还是夹带着些许小误差:
**为啥 **
(tiny deallocation - tiny allocation)
+ (small deallocation - small allocation)
== (normal allocation - normal deallocation)
让我们把问题留到本系列的下一篇吧!
本系列:
- Netty 内存管理: PooledByteBufAllocator & PoolArena 代码探险
- Netty 内存管理探险: PoolArena 统计之BUG和解决
参考:
- Netty内存池原理分析
- 对JasonEvans发表的内存分配器jemalloc论文翻译
- 百度百科:JMX
- Why Netty (by Norman Maurer at Netflix)