安装scrapy:
pip3 install -i https://pypi.douban.com/simple/ scrapy
创建scrapy项目:
>>>scrapy startproject ArticleCrawler(工程名)
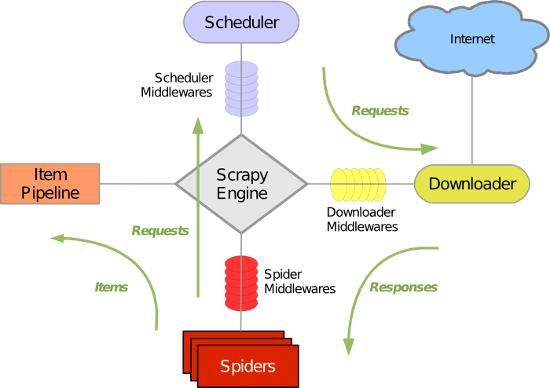
用编译器打开项目,可以看到项目结构和配置文件如下图所示:
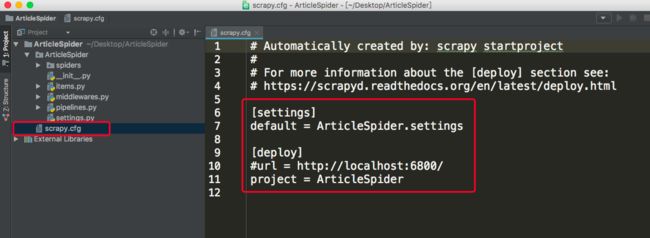
其中,setting.py是项目的配置文件,pipelines.py是管理数据存储的,items.py类似django中的form,文件夹中的spiders中用于存放爬虫脚本。注意打开settings.py设置是否遵循robots协议。

创建爬虫脚本:
打开项目根目录下,运行以下命令来创建一个爬虫脚本:
>>>scrapy genspider jobbole(爬虫名) blog.jobble.com(目标网站地址)

然后会发现spiders文件夹下出现来一个新的jobbole.py爬虫脚本。其中start_urls中存放的就是所有需要爬取的URL.
创建调试脚本:
在项目根目录下创建一个用于调试的脚本main.py,这个脚本用于模拟在命令行执行命令。然后在文件中输入以下内容:
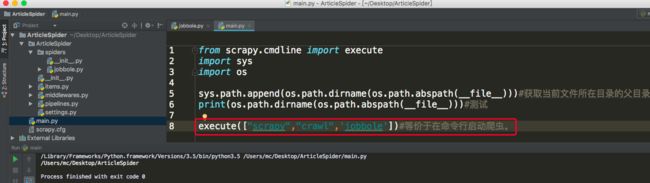
运行以上脚本等价于在项目根目录下打开命令行运行以下命令:
>>>scrapy crawl jobbole(爬虫名,即对应的爬虫脚本下name = []中的名字)
如果在windows 下报错"ImportError: No module named 'win32api'",则需要先输入以下命令安装一个依赖包:
>>>pip3 install pypiwin32
编写爬虫脚本:
编写爬虫需要用到一些Xpath相关的语法知识,如果不了解Xpath语法的可以参考这篇文章【点我】。
打开项目spider目录下的jobbole脚本,注意其中response 参数是自带 xpath方法的。

Scrapy的shell模式:
打开终端执行以下命令:
>>>scrapy shell URL
在此模式下可以调试分析页面

之后执行以下语句可以得到title元素中data的内容
>>>title.extract()
如果访问URL时需要添加headers可以写如下代码:
>>>scrapy shell -s USER_AGENT="" URL
scrapy也可以通过css选择器来使用
>>>title = response.css('.entry-header')
css里的::text 等价于xpath里的text()

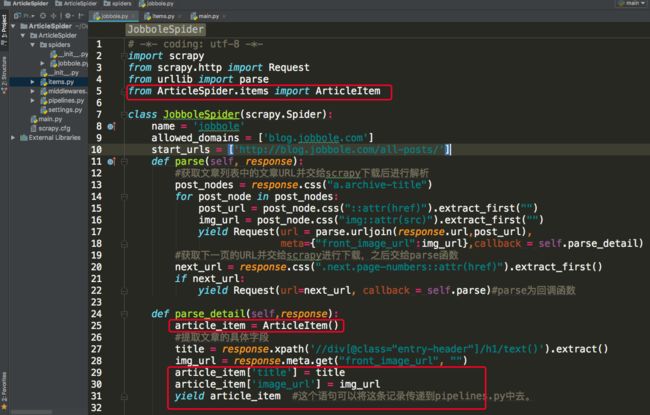
编写spider脚本获取列表文章:
打开spiders文件夹下的脚本文件,引入Request类,这个类的作用是通过一个回调函数调参数将爬虫获取的URL传入另一个函数中。

Request()中还有一个参数meta={},用于传递其它数据到回调函数

这样就可以在对应到回调函数parse_detail里获取meta里到数据了,
img_url = response.meta.get("front_image_url","")
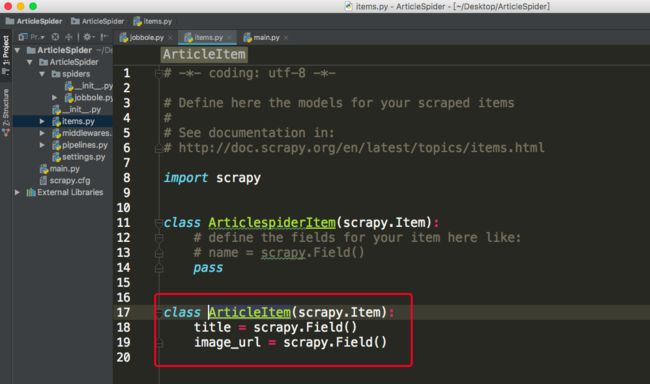
配置items文件:
打开items.py文件, 将所有需要获取的字段定义到一个class中,如下图:
回到脚本文件中,将定义的items引入文件,并创建一个items实例,将对应的数据填充进去,然后通过yield传递到pipelines.py中进行下一步操作。
配置pipelines.py文件:
先打开settings.py文件激活相应的语句。
如果要自动下载图片,可以添加几行,程序便会在 ittems中找到“front_image_url”字段.注意,这里的"front_image_url"是items对象的一个字段。

再添加下面几行,则可以设置图片存放路径

运行前,通过pip install pillow安装一下PIL库.
settings.py中设置这两句用于过滤小图片

重写pipeline:
可以将上面的类重写到pipelines.py文件中,如下:

在 settings.py中用重写到类替换调原本的类:

再一次添加pipeline中的内容:

将数据保存到本地JSON文件或者Mysql当中:
写入JSON文件
在pipeline中再写一个管道用于将数据存放到json中,代码如下:

然后在settings.py中进行相应的配置

另外,我们也可以利用scrapy自带的类来进行json文件的导出:

然后在settings.py文件中做相同的配置
写入Mysql
先在Mysql中根据数据结构建立相应的数据表,然后在pipelines.py中写入对应的pipeline配置,并在settings.py中配置好。

Mysql优化方案---连接池:
为了让Mysql的执行的任务变成异步任务,这里引入一个连接池组件
在 settings.py中配置好mysql的信息


Item loader机制的使用:
在spider脚本中引入item loader

