真-浅谈CPU设计及其运行机制
一、前言
最近看了不少关于CPU设计的一些开源项目和文章,看了之后感觉作者真的太厉害了,反观自己实在太菜了!不过正经来说,这些项目看多了自然就会对CPU的设计和运行有一个更清晰的理解!
在平时的课程和竞赛中会经常接触到SOC设计:比如上学期超大规模集成电路设计这门课的一个大作业使用到了ARM cortex-m0核;这学期参加的集创赛用到了ARM cortex-m1核;由于之前学习过RISC-V的一些知识,所以最近也熟悉了一下tinyriscv和蜂鸟E203这两个使用RISC-V来设计CPU的开源项目。
所以,下面就简单写一下自己对CPU设计和运行的一些理解,不会涉及到细节,因为具体的细节我也不咋能说上来(或者以后再慢慢说),仅仅是对其做一个整体上的思路整理。我在平时学习的时候一直都喜欢先对一个东西有一个比较清晰的整体理解,否则在之后的具体学习中会觉得非常迷,不利于后面高效的学习!!!
二、关于CPU设计
下面就以tinyriscv为例,简单的啰嗦几句,下图是tinyriscv soc的整体框架:
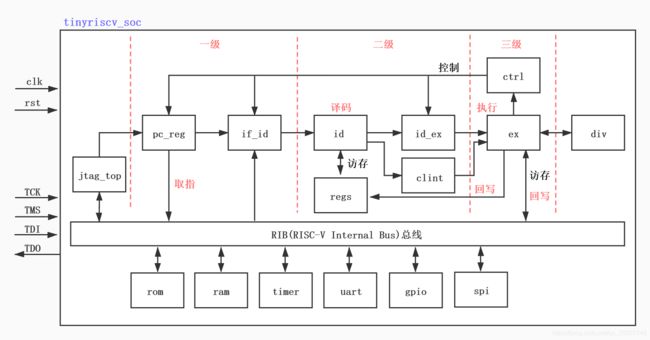
1、CPU核
CPU核是整个CPU最核心的部分,它主要负责处理指令。
我们都知道,CPU在处理一条指令的时候,一般包括以下几个步骤:取指、译码、执行、访存、写回,而且一般采用流水线设计。tinyriscv将访存和写回操作放到了执行这一步,所以只有三级,采用了三级流水线。
在处理指令时,比如译码阶段,我们就需要根据自己所使用的的指令集架构来对指令进行解析以保证正确获取指令想要完成的操作。比如一条加法指令,我们就需要正确解析出它要进行的操作是加法,还要解析出运算中的立即数,如果需要访存或者读寄存器来获得操作数,那么还要解析出数据地址是多少等等。只有按照所使用的的指令集架构来解析,才能保证后面的执行能够进行正确的操作。关于指令集架构你可能使用的是RISC-V,也可能是使用的ARM等等。
CPU核里还会有很多的reg,包括指令计数器(pc_reg)和一些通用reg,这些通用寄存器可以存放一些比如计算操作涉及到的操作数,也可以存放一些状态等等。
2、总线
设想一下一个没有总线的SOC,处理器核与外设之间的连接是怎样的。可能会如下图所示:
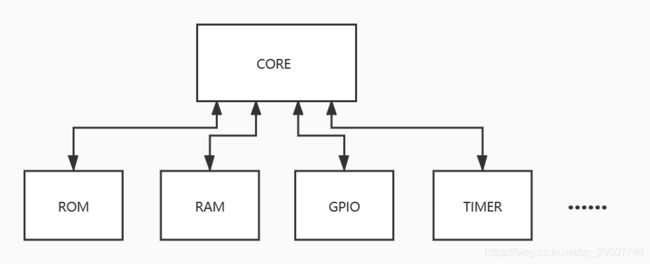
可见,处理器核core直接与每个外设进行交互。假设一个外设有一条地址总线和一条数据总线,总共有N个外设,那么处理器核就有N条地址总线和N条数据总线,而且每增加一个外设就要修改(改动还不小)core的代码。有了总线之后,处理器核只需要一条地址总线和一条数据总线,大大简化了处理器核与外设之间的连接。
目前已经有不少成熟、标准的总线,比如AMBA、wishbone、AXI等。设计CPU时大可以直接使用其中某一种,以节省开发时间。
当从一条指令中解析到需要读写ROM、RAM或者其他挂在总线上的外设时,CPU核就会发出读写地址以及读写数据。总线模块可以根据读写地址的某几位来判断需要操作哪一个外设,又会根据另外几位判断需要读写外设中的哪一个寄存器。这些外设和总线都有连接,但是总线模块可以屏蔽掉其他的外设,只选通和某一个外设的连接(包括与该外设的输入与输出的连接)。
3、外设
外设其实在我看来是一个比较重要的模块,因为大多时候我们不会自己去设计CPU核,更多的是往CPU核上挂载自己设计的功能模块以满足项目需求。所以我们就需要弄清楚这些外设是怎么挂载到总线上的,通常我们需要在代码中观察!!!
上面也说了,我们对外设进行操作,其实就是操作的其中的寄存器,这很重要。 这些寄存器可以简单的理解为是用来配置这些外设的,一般这些外设都不止一个寄存器,不同的寄存器功能不一样,它们对应着不同的偏移地址,而每个外设又有自己的基地址(有时不同的外设还挂在不同的总线上,所以又会有总线基地址)。所以通过基地址+偏移地址我们就可以唯一的确定某个具体外设的具体寄存器,然后就可以对其进行读写操作以完成一些任务。
下面就举个简单的例子—tinyriscv中SPI模块的代码:
// spi控制寄存器
// addr: 0x00
// [0]: 1: enable, 0: disable
// [1]: CPOL
// [2]: CPHA
// [3]: select slave, 1: select, 0: deselect
// [15:8]: clk div
reg[31:0] spi_ctrl;
// spi数据寄存器
// addr: 0x04
// [7:0] cmd or inout data
reg[31:0] spi_data;
// spi状态寄存器
// addr: 0x08
// [0]: 1: busy, 0: idle
reg[31:0] spi_status;
当我们需要进行SPI通信时,我们就可以设置以上几个寄存器来配置SPI模块,如上所示:我们可以设置读写spi_status寄存器以获取或者设置SPI此时的状态;我们还可以读写spi_data以获取接收到的数据或者设置将要发送出去的数据。至于为什么能够发送数据,又为什么能够接收数据,这就是由SPI模块中的verilog代码实现的,它就和我们平时使用FPGA进行SPI通信时写的代码差不多(我说的是使用状态机实现SPI协议的核心代码其实是差不多的,当然这是两个不同的应用场景,你还需要根据实际情况组织自己的代码),按照SPI协议完成数据的传输即可。
可以看出,底层写好verilog代码之后,我们在上层写应用程序的时候就只需要操作寄存器和发出一些必要的如启动接收或者发送的控制信号即可,它为我们屏蔽了复杂的协议实现过程,大大简化了应用开发!!!下面就刚好接着简单说一下关于CPU运行的一些东西!!!
三、关于CPU运行
CPU的运行其实可以简单的理解为,我们使用C/C++等高级语言编写好了应用程序,然后通过编译器将应用程序按照CPU对应的指令集架构转换成机器码,也就是一条一条的指令。假如我们的指令存储到了ROM中,那么CPU就可以读取这些指令,然后对每条指令进行解析、执行以完成我们在应用程序中想要实现的功能。
如果应用程序不牵扯到外设,比如通信模块,那么CPU核最多也就通过总线读取ROM中的指令,读写RAM和内部通用寄存器。如果牵扯到外设,那么还会读写外设中的寄存器!!!
那我们在写应用程序的时候是怎么和这些外设模块联系起来的呢?
其实如果你做过嵌入式开发,比如大家非常熟知的stm32,那么你一定知道那些使用起来非常方便的封装好的外设驱动函数,内部其实就是在进行各种寄存器操作,也就是对指定地址进行读写操作。而且在系统的头文件中,肯定会事先定义好总线的基地址、各个外设相对总线的偏移地址以及各个外设内部的寄存器相对于外设的偏移地址(当然还会有其他比如中断向量表等,这里就不说了),如下面两张图所示:
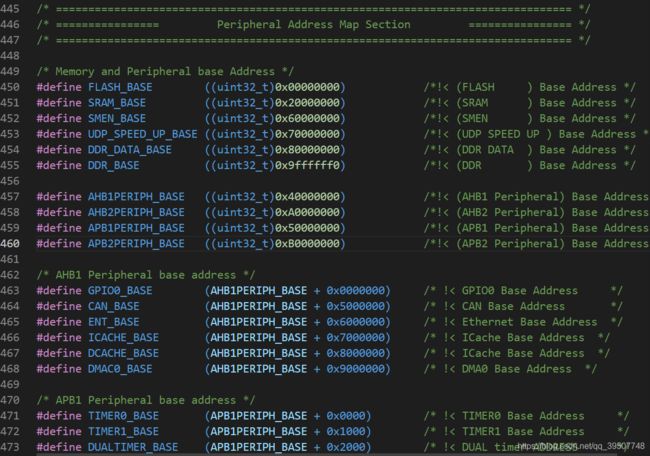
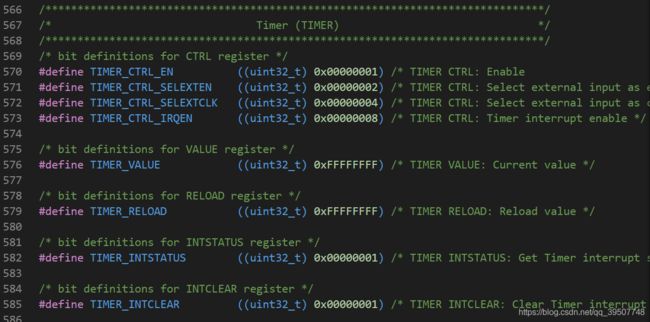
有了这些定义,我们就可以在应用程序中对指定地址处进行读写操作,其实到这里你就已经知道我们怎么操作指定地址处的模块了。
但是为什么能呢?那是因为我们在应用程序中对该地址进行读写,编译器就会根据指令集架构编译出对该地址进行读写的指令。
(以下是个人理解)比如编译器通过应用程序获取地址、操作类型以及操作数,然后在生成的指令中,把地址、操作类型以及操作数放入32位或者64位的指令中(至于放到哪些位,怎么放,那就和你使用的指令集架构有关了)。至于更加具体的细节,其实都是编译器的工作,我不太了解,感兴趣的小伙伴可以去了解一下!!!
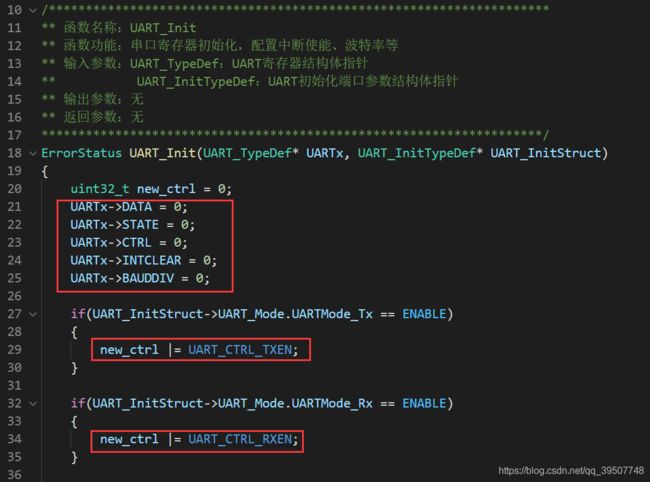
下图就是在uart驱动函数中,对uart外设进行初始化的函数,可以看到里面其实就是在利用事先定义好的地址信息,对指定地址处的寄存器进行各种操作以完成uart的初始化!!!
四、小结
以上叙述无论是对实际流片的硬核CPU还是跑在FPGA上的软核CPU都是适用的!!!
啰嗦了很多,肯定有些地方说的不是太对,如果有还希望指出来!!!本篇文章只是试图帮助读者从整体上弄清楚CPU的设计,以及明白我们写的应用程序是如何最终被CPU执行的!!!溜了,溜了!!!
参考:从零开始写RISC-V处理器