【TensorFlow2.x开发—基础】 模型保存、加载、使用
前言
本文主要介绍在TensorFlow2 中使用Keras API保存整个模型,以及如果使用保存好的模型。保存整个模型时,有两种格式可以实现,分别是SaveModel和HDF5;在TF2.x中默认使用SavedModel格式。
文章分为简约版、实践版、代码版,首先从简约版认识基本流程、要点、代码等;再到实践版查看每一步的代码调试结果;最后通过代码版,可以自己尝试实践。
简约版
一、HDF5格式
HDF5标准提供了一种基本保存模型格式,也是常见的模型xxx.h5;通过HDF5格式会保存整个模型的权值值、模型的架构、模型的训练配置、优化器及状态等。
使用model.save() 保存,使用tf.keras.models.loda_model加载模型;
首先安装一下相关的依赖库,执行如下命令即可:
pip install pyyaml h5py
1.1)保存模型
# 创建并训练一个新的模型实例
model = create_model()
model.fit(train_images, train_labels, epochs = 5)
# 以HDF5 格式保存模型,保存后是xxx.h5的文件
model.save("my_model.h5")
1.2)加载使用模型
加载模型:
# 重新创建完成相同的模型,包括权值和优化程序等
new_model = tf.keras.models.load_model("my_model.h5")
# 查看模型的结构
new_model.summary()检查其准确率(accuracy):
loss, acc = new_model.evaluate(test_images, test_labels, verbose = 2)
print("评估保存好的模型 准确率:{:5.2f}%".format(100 * acc))
二、SavedMode格式
SavedModel格式是序列化模型的一种方法,是一个包含Protobuf二进制文件和Tensorflow检查点(checkpoint)的目录;
SavedModel格式也是使用model.save() 保存模型,使用tf.keras.models.loda_model加载模型;这种方式于Tensorflow Serving兼容。
2.1)保存模型
创建并训练一个新的模型实例,然后把训练好模型保存在saved_model 目录下,保存模型的名称为:my_model
# 创建并训练一个新的模型实例。
model = create_model()
model.fit(train_images, train_labels, epochs = 5)
# 以SavedModel格式保存整个模型
model.save("saved_model/my_model")
SavedModel 格式是一个包含 protobuf 二进制文件和 Tensorflow 检查点(checkpoint)的目录。检查保存的模型目录:
# 首先查看 保存模型的目录saved_model下有那些文件
ls saved_model
# 查看我们刚才保存的模型my_model
ls saved_model/my_model能看到一个assets文件夹,saved_model.pd,和变量文件夹。
2.2)加载使用模型
加载保存好的模型:
new_model = tf.keras.models.load_model("saved_model/my_model")
# 看到模型的结构
new_model.summary()
使用模型:
# 评估模型
loss, acc = new_model.evaluate(test_images, test_labels, verbose = 2)
print("评估保存好的模型 准确率:{:5.2f}%".format(100 * acc))
实践版
一、HDF5格式
HDF5标准提供了一种基本保存模型格式,也是常见的模型xxx.h5;通过HDF5格式会保存整个模型的权值值、模型的架构、模型的训练配置、优化器及状态等。
首先安装一下相关的依赖库,执行如下命令即可:
pip install pyyaml h5py
1.1)保存模型

1.2)加载使用模型
加载模型:

检查其准确率(accuracy):

二、SavedMode格式
SavedModel格式是序列化模型的一种方法,是一个包含Protobuf二进制文件和Tensorflow检查点(checkpoint)的目录;
其使用model.save() 保存,使用tf.keras.models.loda_model加载模型;这种方式于Tensorflow Serving兼容。
2.1)保存模型
创建并训练一个新的模型实例,然后把训练好模型保存在saved_model 目录下,保存模型的名称为:my_model
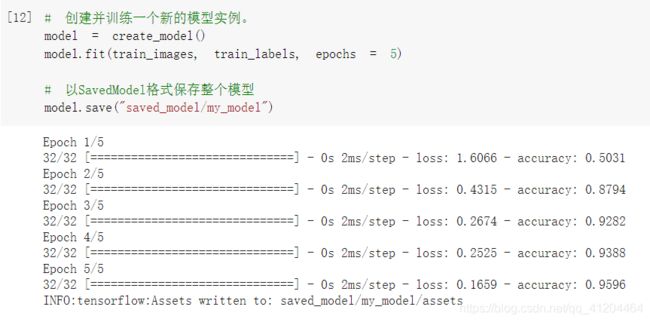
SavedModel 格式是一个包含 protobuf 二进制文件和 Tensorflow 检查点(checkpoint)的目录。检查保存的模型目录:

能看到一个assets文件夹,saved_model.pd,和变量文件夹。
2.2)加载使用模型
加载保存好的模型:
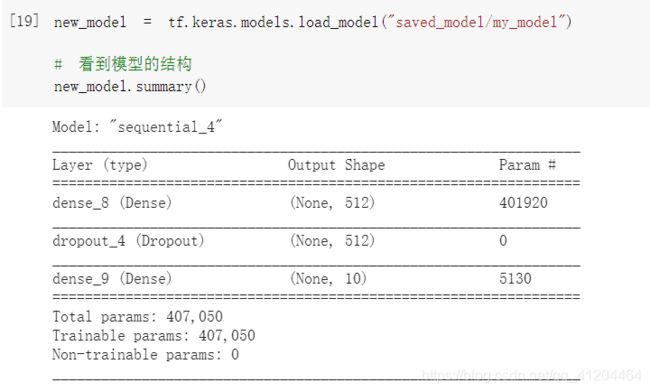
使用模型:

代码版
HDF5格式:
# 导入Tensorflow和依赖项
import os
import tensorflow as tf
from tensorflow import keras
# 获取示例数据集,使用 MNIST 数据集,主要使用使用前1000个示例
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_labels = train_labels[:1000]
test_labels = test_labels[:1000]
train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0
test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0
# 定义模型,首先构建一个简单的序列(sequential)模型
# 定义一个简单的序列模型
def create_model():
model = tf.keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
# 创建并训练一个新的模型实例
model = create_model()
model.fit(train_images, train_labels, epochs = 5)
# 以HDF5 格式保存模型,保存后是xxx.h5的文件
model.save("my_model.h5")
# 重新创建完成相同的模型,包括权值和优化程序等
new_model = tf.keras.models.load_model("my_model.h5")
# 查看模型的结构
new_model.summary()
loss, acc = new_model.evaluate(test_images, test_labels, verbose = 2)
print("评估保存好的模型 准确率:{:5.2f}%".format(100 * acc))
SavedMode格式:
# 导入Tensorflow和依赖项
import os
import tensorflow as tf
from tensorflow import keras
# 获取示例数据集,使用 MNIST 数据集,主要使用使用前1000个示例
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_labels = train_labels[:1000]
test_labels = test_labels[:1000]
train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0
test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0
# 定义模型,首先构建一个简单的序列(sequential)模型
# 定义一个简单的序列模型
def create_model():
model = tf.keras.models.Sequential([
keras.layers.Dense(512, activation='relu', input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
# 创建并训练一个新的模型实例。
model = create_model()
model.fit(train_images, train_labels, epochs = 5)
# 以SavedModel格式保存整个模型
model.save("saved_model/my_model")
new_model = tf.keras.models.load_model("saved_model/my_model")
# 看到模型的结构
new_model.summary()
# 评估模型
loss, acc = new_model.evaluate(test_images, test_labels, verbose = 2)
print("评估保存好的模型 准确率:{:5.2f}%".format(100 * acc))
print(new_model.predict(test_images).shape)
小结
保存整个模型时,有两种方式实现,分别是SaveModel和HDF5;两种都是使用model.save() 保存模块,使用tf.keras.models.loda_model加载模型;
HDF5格式 保存模型后,生成xxx.h5,比较常用。
SavedModel格式 保存模型后,是一个包含Protobuf二进制文件和Tensorflow检查点(checkpoint)的目录;
加油加油~~ 欢迎交流呀