mapreduce 概述
问题 : 什么是MapReduce ?
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统(hadoop --> HDFS(数据的存储) YRAN(YARN --> 提供container(内存,cpu jvm) --> map task reduce task))上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
问题 : MapReduce的主要组成部分?
org.apache.hadoop.mapreduce.Mapper
org.apache.hadoop.mapreduce.Reducer


问题 : MapReduce用它来干嘛?
mapreduce的主要目的
化大为小 , 分而治之。
hadoop : 多服务器多进程多线程 (5G以上) --> java编程的进阶版 固定步骤 map reduce job main
java : 但服务器但进程多线程(小数据 2G)
 举例说明:
举例说明: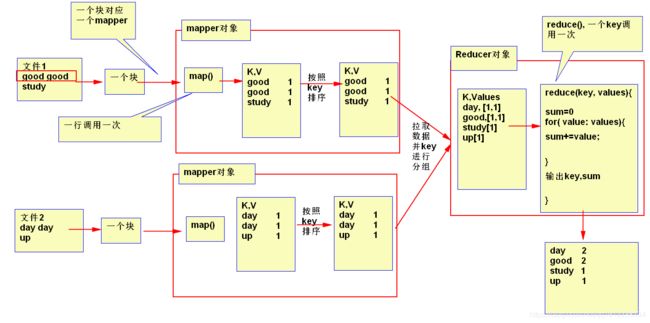
问题 : mapper和reducer阶段分别解决什么样的问题?
mapper阶段解决的问题,就是把输入变成Key,Value结果,用于reducer的输入。
mapper内部是局部有序
reducer 解决的问题的就是按分组进行汇总
全局有序(一定是建立在一个reduce的基础上) --> partition功能 --> 一个reduce 一个key 的 所有数据
小结 : MapReduce 计算架构提供的主要功能包括以下几点。
1)任务调度
提交的一个计算作业(Job)将被划分为很多个计算任务(Tasks)。 一个数据块就要跑一个map 然后如果你感觉 reduce特别慢 可以增加reduce的数量
任务调度功能主要负责为这些划分后的计算任务分配和调度计算结点(Map 结点或 Reduce 结点),同时负责监控这些结点的执行状态,以及 Map 结点执行的同步控制,也负责进行一些计算性能优化处理。
例如,对最慢的计算任务采用多备份执行,选最快完成者作为结果。
2)数据/程序互定位
为了减少数据通信量,一个基本原则是 本地化数据处理 ,即一个计算结点尽可能处理其本地磁盘上分布存储的数据,这实现了代码向数据的迁移。
当无法进行这种本地化数据处理时,再寻找其他可用结点并将数据从网络上传送给该结点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻找可用结点以减少通信延迟。
3)出错处理
在以低端商用服务器构成的大规模 MapReduce 计算集群中,结点硬件(主机、兹盘、内存等)出错和软件有缺陷是常态。因此,MapReduce 架构需要能检测并隔离出错结点,并调度分配新的结点接管出错结点的计算任务。
appMaster --> container --> 任务 --> appMaseter --> ApplicationsManager --> appMaster --> 重新跑
4)分布式数据存储与文件管理
海量数据处理需要一个良好的分布数据存储和文件管理系统作为支撑,该系统能够把海量数据分布存储在各个结点的本地磁盘上,但保持整个数据在逻辑上成为一个完整的数据文件。
为了提供数据存储容错机制,该系统还要提供数据块的多备份存储管理能力。(HDFS作为MapReduce的输入与输出来源 MapReduce计算方式 --> HDFS的文件存储特点来进行设计)
5)Combiner 和 Partitioner
为了减少数据通信开销,中间结果数据进入 Reduce 结点前需要进行合并(Combine)处理,即把具有同样主键的数据合并到一起避免重复传送。
一个 Reduce 结点所处理的数据可能会来自多个 Map 结点,因此,Map 结点输出的中间结果需使用一定的策略进行适当的划分(Partition)处理,保证相关数据发送到同一个 Reduce 结点上。
wordcount 源码解析 :(MapReduce的helloworld级别的案例实现)
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
// map阶段
public static class TokenizerMapper
extends Mapper{
// 定义计数器1
private final static IntWritable one = new IntWritable(1);
// 定义key
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// 行数据拆分 tokenizer 使用默认的分隔符集 " \t\n\r\f",即:空白字符、制表符、换行符、回车符和换页符。分隔符字符本身不作为标记。
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
// 设置key
word.set(itr.nextToken());
// 将key与计数器组成新key-value
context.write(word, one);
}
}
}
// reduce 阶段
public static class IntSumReducer
extends Reducer {
// 定义输出的数量值
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
// 为每一个key叠加值
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// 将结果最后输出
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 设置配置参数
Configuration conf = new Configuration();
// 判断一下执行的时候是否有足够的参数 执行的时候需要设置输入与输出目录 所以数量要>2
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
// 设置开启一个新的job
Job job = Job.getInstance(conf, "word count");
// 打包成jar的类
job.setJarByClass(WordCount.class);
// 设置map reduce combine 类
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
// 设置输出数据的key-val类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置不同的输入路径(支持多输入路径)
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// 设置输出路径,需要注意,不管有多少个输入路径,最后一个一定要是输出路径
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
// 等待这个job完成根据返回结果进行操作
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
问题 : MapReduce的处理流程是怎么样的?
MapReduce 的实际处理过程可以分解为 Input(输入)、Map(处理)、Sort(排序)、Combine(局部聚合)、Partition(分区)、Reduce(全局聚合)、Output(输出) 等阶段
阶段1 : Input(输入)
问题 : map 任务的输入文件是怎么分割的?
MapReduce 通过 org.apache.hadoop.mapreduce.InputSplit 类提供数据切片方法(抽象类)
split 默认一个 block(数据块) 对应一个 split(数据分片)
源码验证 :
在 org.apache.hadoop.mapreduce.lib.input.FileInputFormat 这个类中有一个神奇的参数 :
private static final double SPLIT_SLOP = 1.1; // 10% slop
Map数的计算是以文件为单位的,针对每一个文件做一个循环:
1. 文件大小/splitsize>1.1,创建一个split,这个split的大小=splitsize,文件剩余大小=文件大小-splitsize
2. 文件剩余大小/splitsize<1.1,剩余的部分作为一个split。
这样做的好处就是可以稍微减少一下Map 的数量,是不是很皮?
切好片之后我们就需要读取数据内容了,现在我们读取的文件基本都是文本内容,以后会有各种各样类型的内容,此处我们以文本内容来介绍是如何进行数据格式化的 :
1) 首先定位到文本格式化类 org.apache.hadoop.mapreduce.lib.input.TextInputFormat
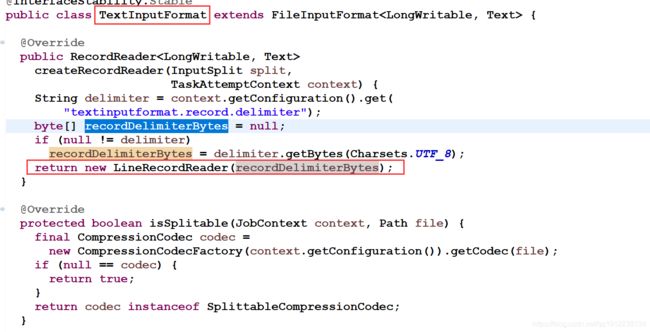
此处简单理解 LineRecordReader 可以根据自定义分隔符进行设置,如果没有就按默认分隔符设置
继续观察 org.apache.hadoop.mapreduce.lib.input.LineRecordReader
 注意 LineRecordReader 的 nextKeyValue() 方法 我们的map函数就是用它来读取文本中的一行数据的
注意 LineRecordReader 的 nextKeyValue() 方法 我们的map函数就是用它来读取文本中的一行数据的
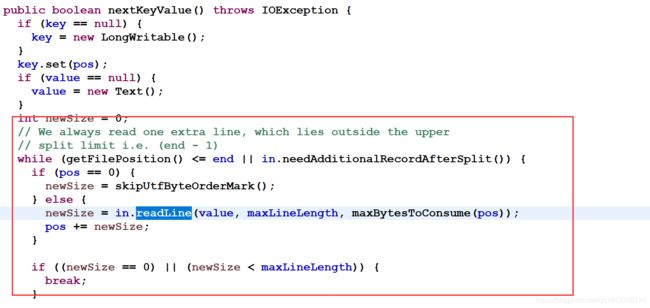 此处需要注意一个细节 : MapReduce在读取一行数据的时候不是说你这一行数据有多少就读取多少,是根据长度进行操作的,如果长度操作了限定的长度(默认是Integer.max_val)的话就会截取屌
此处需要注意一个细节 : MapReduce在读取一行数据的时候不是说你这一行数据有多少就读取多少,是根据长度进行操作的,如果长度操作了限定的长度(默认是Integer.max_val)的话就会截取屌
这也是说为什么要记录数据偏移量(LongWritable)的原因了!
此处需要再注意一个细节就是此处是用了 in.readLine的方式读取了数据, in? in是什么对象呢?通过源码我们往上找就能发现这个对象
![]()
这个是我们真正用于读取数据的对象,它是继承自LineReader类所以我们进入父类看一下readLine()方法

我们进入默认分隔符方法看一看
由于此方法过于凶残,所以我们暂时就不再往下看了;到此完成一行数据的读取工作!
数据分片小练习 :
观察下图并分析 如果执行MapReduce任务的话 下面这个目录中的数据会执行多少个map任务?
解题过程 :
1) 发现单个文件有多大 然后再数一下有多少个文件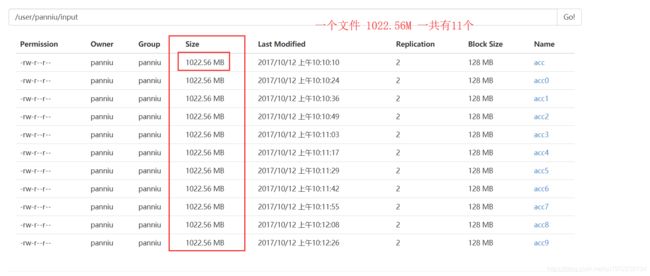
2) 观察一个文件分了多少个数据块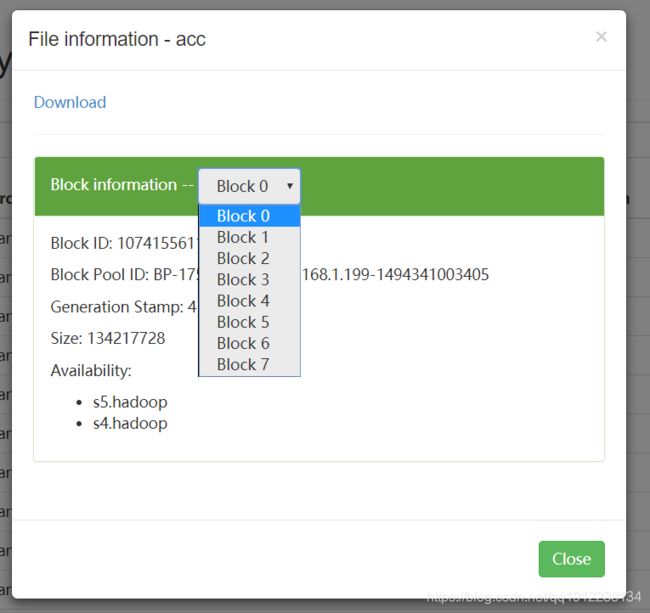
安装正常来说 一个数据块(数据块的真实大小要是在一个数据块的10% 以上)就是一个数据分片,那么现在有8个数据块 所以一个文件就会产生8个map
一个文件产生8个map 所以 11个文件就有 88个map 那么有多少个reduce呢? 注意 reduce的数量是自己设置的 根咱的map无关
执行命令验证结果
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/panniu/input /user/suniu/output/op1111
小结 :
在 MapReduce 的整个处理过程中,不同的 Map 任务之间不会进行任何通信,不同的 Reduce 任务之间也不会发生任何信息交换。
用户不能够显式地从一个结点向另一个结点发送消息,所有的信息交换都是通过 MapReduce 框架实现的。
MapReduce 计算模型实现数据处理时,应用程序开发者只需要负责 Map 函数和 Reduce 函数的实现。
MapReduce 计算模型之所以得到如此广泛的应用就是因为应用开发者不需要处理分布式和并行编程中的各种复杂问题。
如分布式存储、分布式通信、任务调度、容错处理、负载均衡、数据可靠等,这些问题都由 Hadoop MapReduce 框架负责处理,应用开发者只需要负责完成 Map 函数与 Reduce 函数的实现。
阶段2 : Map(处理)、Sort(排序)、Combine(局部聚合)
wordcount中map阶段做了什么
1)将文件拆分成多个分片。
该实例把文件拆分成两个分片,每个分片包含两行内容。在该作业中,有两个执行 Map 任务的结点和一个执行 Reduce 任务的结点。每个分片分配给一个 Map 结点,并将文件按行分割形成
2)将分割好的
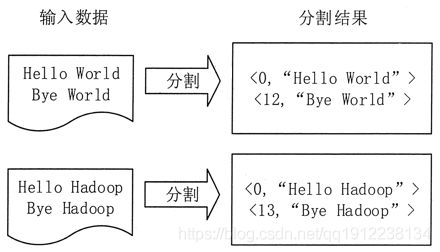
图 1 分割过程
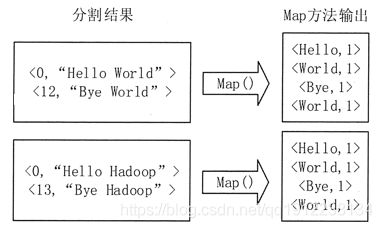
图 2 执行Map函数
3)在实际应用中,每个输入分片在经过 Map 函数分解以后都会生成大量类似 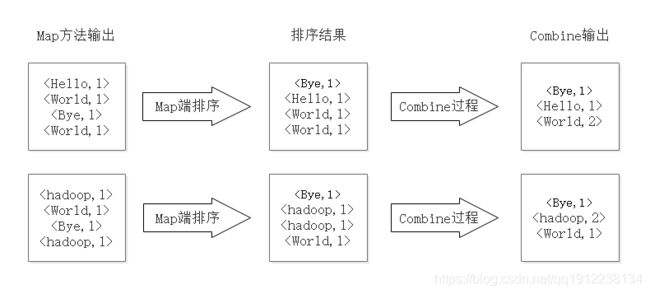
图 3 Map端排序及Combine过程
阶段3 : Partition(分区)、Reduce(全局聚合)、Output(输出)
wordcount中reduce阶段做了什么
4)Reduce 先对从 Map 端接收的数据进行排序,再交由用户自定义的 Reduce 方法进行处理,得到新的
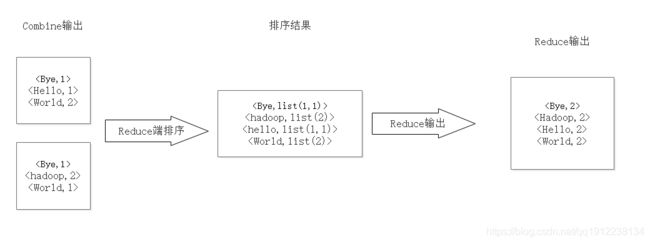
图 4 Reduce 端排序及输出结果
小结 : Hadoop MapReduce 作业执行流程
整个 Hadoop MapReduce 的作业执行流程如图 1 所示,共分为 10 步。

1. 提交作业客户端向 JobTracker 提交作业。首先,用户需要将所有应该配置的参数根据需求配置好。作业提交之后,就会进入自动化执行。在这个过程中,用户只能监控程序的执行情况和强制中断作业,但是不能对作业的执行过程进行任何干预。提交作业的基本过程如下。
1)客户端通过 Runjob() 方法启动作业提交过程。
2)客户端通过 JobTracker 的 getNewJobId() 请求一个新的作业 ID。
3)客户端检查作业的输出说明,计算作业的输入分片等,如果有问题,就抛出异常,如果正常,就将运行作业所需的资源(如作业 Jar 文件,配置文件,计算所得的输入分片等)复制到一个以作业 ID 命名的目录中。
4)通过调用 JobTracker 的 submitjob() 方法告知作业准备执行。
2. 初始化作业JobTracker 在 JobTracker 端开始初始化工作,包括在其内存里建立一系列数据结构,来记录这个 Job 的运行情况。
1)JobTracker 接收到对其 submitJob() 方法的调用后,就会把这个调用放入一个内部队列中,交由作业调度器进行调度。初始化主要是创建一个表示正在运行作业的对象,以便跟踪任务的状态和进程。
2)为了创建任务运行列表,作业调度器首先从 HDFS 中获取 JobClient 已计算好的输入分片信息,然后为每个分片创建一个 MapTask,并且创建 ReduceTask。
3. 分配任务JobTracker 会向 HDFS 的 NameNode 询问有关数据在哪些文件里面,这些文件分别散落在哪些结点里面。JobTracker 需要按照“就近运行”原则分配任务。TaskTracker 定期通过“心跳”与 JobTracker 进行通信,主要是告知 JobTracker 自身是否还存活,以及是否已经准备好运行新的任务等。
JobTracker 接收到心跳信息后,如果有待分配的任务,就会为 TaskTracker 分配一个任务,并将分配信息封装在心跳通信的返回值中返回给 TaskTracker。
对于 Map 任务,JobTracker 通常会选取一个距离其输入分片最近的 TaskTracker,对于 Reduce 任务,JobTracker 则无法考虑数据的本地化。
4.执行任务
1)TaskTracker 分配到一个任务后,通过 HDFS 把作业的 Jar 文件复制到 TaskTracker 所在的文件系统,同时,TaskTracker 将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。TaskTracker 为任务新建一个本地工作目录,并把 Jar 文件中的内容解压到这个文件夹中。
2)TaskTracker 启动一个新的 JVM 来运行每个任务(包括 Map 任务和 Reduce 任务),这样,JobClient 的 MapReduce 就不会影响 TaskTracker 守护进程。任务的子进程每隔几秒便告知父进程它的进度,直到任务完成。
5. 进程和状态的更新一个作业和它的每个任务都有一个状态信息,包括作业或任务的运行状态,Map 任务和 Reduce 任务的进度,计数器值,状态消息或描述。任务在运行时,对其进度保持追踪。这些消息通过一定的时间间隔由 ChildJVM 向 TaskTracker 汇聚,然后再向 JobTracker 汇聚。JobTracker 将产生一个表明所有运行作业及其任务状态的全局视图,用户可以通过 Web UI 进行查看。JobClient 通过每秒查询 JobTracker 来获得最新状态,并且输出到控制台上。6. 作业的完成当 JobTracker 接收到的这次作业的最后一个任务已经完成时,它会将 Job 的状态改为“successful”。当 JobClient 获取到作业的状态时,就知道该作业已经成功完成,然后 JobClient 打印信息告知用户作业已成功结束,最后从 Runjob() 方法返回。