华为诺亚方舟提出BANet,双向视觉注意力机制用于单目相机深度估计
关注公众号“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

这篇文章的作者是华为加拿大诺亚方舟实验室,是一篇将双向注意力机制用于弹幕深度估计的工作。主要的创新点在视觉注意力机制的基础上引入了前向和后向注意力模块,这些模块可以有效地整合局部和全局信息,以此来消除歧义。这篇文章又扩展了视觉注意力机制的应用范围,值得学习。
论文地址:https://arxiv.org/abs/2009.00743
在本文中,提出了双向注意力网络(BANet),这是一种用于单目相机深度估计的端到端框架,它解决了在卷积神经网络中整合局部信息和全局信息的局限性。该机制的结构源于神经机器翻译的强大概念基础,并提出了一种类似于循环神经网络的动态特性的轻量级的自适应计算控制机制。引入了双向注意模块,这些模块利用前馈特征图并结合了全局上下文来过滤模糊性。大量实验揭示了双向注意力模型在前馈基线和其他先进方法上表现出的高度能力,可用于在两个具有挑战性的数据集KITTI和DIODE上进行单目深度估计。我们表明,我们提出的方法在性能上优于或至少与最先进的单眼深度估计方法相当,但具有较少的内存和计算复杂性。
简介
深度估计的最新方法(例如《Deepordinal regression network for monocular depth estimation》、《High quality monocular depth estimationvia transfer learning》、《From big to small:Multi-scale local planar guidance for monocular depth estimation》)都是建立在全卷积网络(FCN)的基础上,以端到端的方式从单个图像估计连续深度图。受FCN成功的启发,有关单目相机深度估计( Monocular Depth Estimation,MDE)的最新工作已显示出通过对FCN结构进行更高容量的架构增强而得到的改进。
经典的计算机视觉方法采用多视图立体几何相关算法进行深度估计。随着近来基于深度学习的方法将MDE公式化为密集的,像素级的连续回归问题。当前,最先进的单目深度估计MDE模型由以下模块构成:基于预训练的卷积神经骨干网络与上采样和跳跃连接模块,全局上下文模块和用于有序回归的对数离散化模块,用于上采样与局部平面假设的系数学习器模块。所有这些设计的选择都直接或间接地受制于骨干架构中的空间下采样操作,这一点在像素级任务中已经有所体现。
由于MDE是一个单plane估计(即单通道输出)问题,基于此,本文的方法加入了深度到空间( depth-to-space,D2S)变换的思想,作为解码阶段下采样操作的补救措施。然而,直接对最终特征图进行 D2S 变换可能会因为缺乏可靠估计所需的场景全局上下文而受到影响。因此,本文的方法还在D2S变换后的单通道特征图上为每个阶段的骨干模型注入全局上下文信息。 此外,还通过双向注意模块(图2所示)有效地收集了骨干模型所有阶段的信息。对于MDE方法中出现的突出问题,本文提出了一种新颖而有效的从单幅图像中估计连续深度图的方法(见图1)——双向注意网络(Bidirectional Attention Network,BANet)。虽然本文的架构比SOTA包含了更多的连接,但由于大部分的交互作用是在D2S变换的单通道特征上计算的,因此计算复杂度和参数数量都低于最近的其他模型方法。
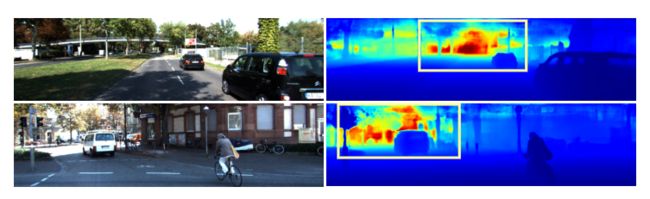
图1:在KITTI 验证集上进行BANet预测的示例。BANet通过生成每个阶段的注意力权重并减少网络内的歧义来改善总体深度估计
本文的主要贡献:
1、本文是将双向注意力机制的概念用于单目相机深度估计任务的第一项工作。本文方法可以与任何现有CNN合并。
2、进一步引入了前向和后向注意力模块,这些模块有效地整合了局部信息和全局信息以消除歧义。
3、在两个不同的MDE数据集上进行了广泛的实验结果。实验证明了本文提出的方法在效率和性能上的有效性。同时本文提出的机制的各种变体可以与最近的SOTA网络结构相媲美。
本文方法:SNE-RoadSeg
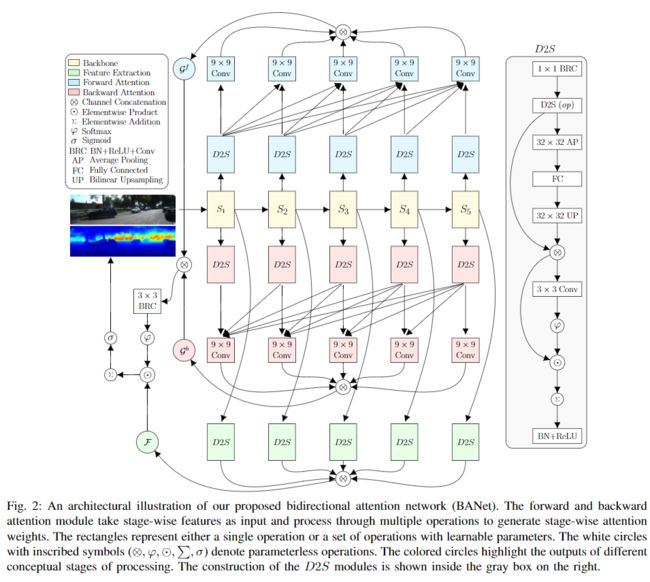
1、Bidirectional Attention Network
在本文提出的方法中的双向注意力的方法是由神经机器翻译(NMT)领域首先引进的。尽管最近有工作(例如SENet、CBAM等)在CNN中利用通道方向和空间注意力来完成各种计算机视觉任务,但尚未广泛探索以向前和向后方式应用注意力以实现双向RNN的性质的想法。
本文提出的方法的总体架构如图2所示。与NMT术语相似,BANet中的阶段性前馈特征(S1,S2,...,S5)类似于原始句子中单独的单词。同时,双向RNN会逐字地对源句进行动态处理,从而固有地生成前向和后向隐藏状态。由于CNN在输入图像上具有静态性质,因此本文的方法引入了两个不同的注意力模块,分别表示为前向和后向注意力子模块。双向注意力模块将阶段性特征图作为输入,以通过合并全局上下文来过滤模糊性。
2、Bidirectional Attention Modules
由于MDE的任务是一个单平面估计问题(即输出包含单通道),作者用一个1×1卷积将各stage特征图(si其中i= 1,2,...,5)调整到所需的空间分辨率,然后进行高效且无参数的深度到空间(depth-to-space,D2S)操作。网络的前向和后向注意力操作可以表示化为:
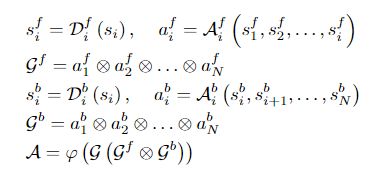
其中,上标f和b分别表示与向前和向后注意力有关的操作,下标i表示主干特征图的关联stage。表示前向注意力的9x9卷积可以访问到第i个stage的特征,并且从第i个stage开始接受表示后向注意力的9x9卷积的特征表示;因此,模拟了双向RNN的前向和后向注意力机制。接下来,将所有前向和后向注意图在通道上进行级联,并通过一个3×3卷积和softmax(φ)函数进行处理,以生成每层像素级别的注意权重A(见图3)。使用D2S模块从阶段性特征图Si计算特征表示fi的过程可以表示为:
![]()
然后,使用Hadamard点乘(element-wise)和 pixel-wise 求和操作,从并联的特征F和注意力特征图A中计算出非线性预测值。最后,用σ函数生成归一化预测值。这些操作可以表示为:
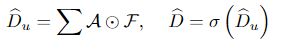

3、Global Context Aggregation
在D2S模块中,可以通过应用比较大的卷积核进行平均池化,然后进行全连接层和双线性上采样操作,将全局上下文结合起来。这套操作将像素级、局部(查询query)信息与图像级、全局(关键key)信息相结合,从整个图像中提取更好的单目线索。D2S模块中全局上下文的这种聚合有助于解决更薄的物体在更有挑战性的情况下(即非常明亮或黑暗的背景)的模糊性(见图4和5)。此外,还提供了所提出的架构的几个备选实现的细节,如下:
BANet-Full:这是架构的完整实现,如图2所示。
BANet-Vanilla:仅包含主干,后跟1×1卷积,单个D2S操作和Sigmoid,以生成最终深度预测。这与用于单目3D检测的RefinedMPL网络中用于深度预测的模型非常相似。
BANet-Forward:此设置中缺少BANet的后向注意模块。
BANet-backward:BANet的Forward模块不在此处。
BANet-Markov:这是遵循马尔可夫假设的,即每个时间步长(或阶段)的特征仅取决于前一步(向前注意)或后继(后向注意)的特征。因此,除了图2中9×9卷积的紧接的前(向前)和后(后)进入边以外,所有其他边都是在此构造中已停用。
BANet-Local:这用一个9×9卷积代替了全局上下文聚合部分。
另外,还通过简单地一次将不同的阶段特征和相似的后处理串联在一起,进行了无时间依赖性结构的实验。但是,这种幼稚的实现方式比上面提到的提出的依赖时间的实现方式差很多。因此,从进一步的实验分析中排除了这种直接的部署。
实验与结果
数据集:KITTI and DIODE
评价指标:在MDE文献中,准确度(越高越好)和误差(越低越好)这两个指标被用来衡量不同的方法。然而,不同的数据集所使用的度量指标之间缺乏一致性。在这项工作中,采用了一套统一的指标,跨越所有不同数据集的子集用于实验。 对于误差度量,主要遵循KITTI leadearboard中的度量方法(SILog、SqRel、AbsRel、MAE、RMSE、iRMSE)。另外,由于传统的准确度指标是一个区间内相对预测的阈值测量,作者对准确度指标进行了修改,以达到更严格的测量目的。具体扩展了这套指标,将更多的阈值置于同一区间内的低端和现有的最低阈值之间(式4)。
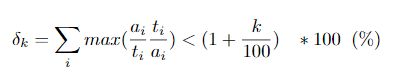
k的取值为:{5,10,15,25,56,95}。如此严格的指标扩展为自动驾驶应用提供了更好的见解,其中深度估算的高精度至关重要。
1、定量对比分析
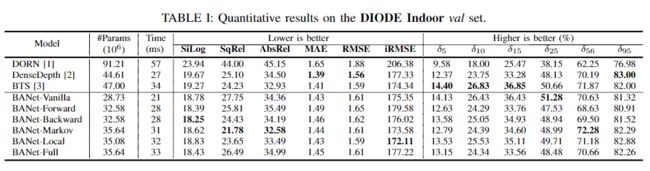


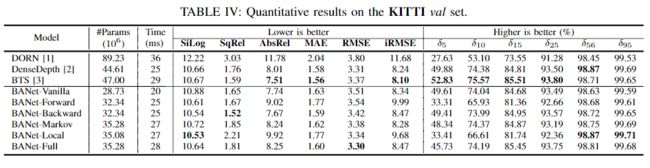
表I,II,III和IV列出了我们的BANet变体与SOTA架构的比较结果。注意,由于离散化或有序水平提供的粒度影响,DONN的性能特别差。为此超参数设置较高的值可能会提高其精度。但是,增加此数量会导致训练期间的内存消耗呈指数增长;因此很难在大型数据集(如KITTI和DIODE)上进行训练。总体而言,BANet变体在特定的BTS中表现更好或接近于现有的SOTA。值得注意的是,最重的BANet变量(BANet-Full)中的参数数量比BTS少25%。
2、定性分析
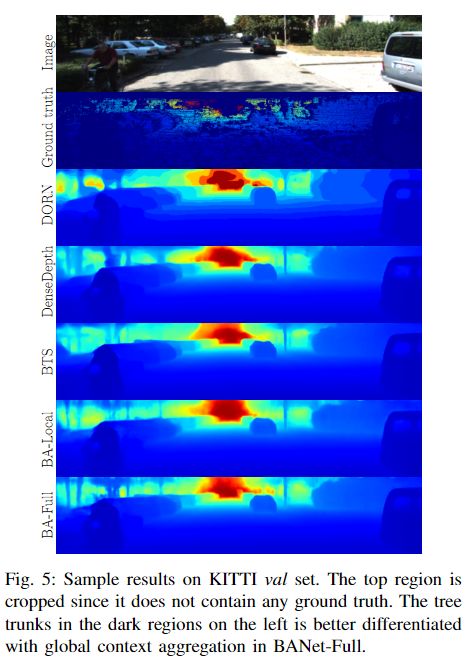
图4和5显示了不同SOTA方法的定性比较。DORN预测图清楚地表明了其预测的半离散性。对于图4中的室内和室外图像,BTS和DenseDepth的高强度区域都围绕左图像右下方的窗框和右图像中的树干。BANet变体在这些性能较差的脆弱区域表现得更好。尤其是,BANet-Full的全局上下文聚合比其局部副本有了更好地区分性能。图5展示了类似的情况,但是这次是在黑暗的环境中。从这些可视化来看,很明显全局上下文聚合对于解决由不利照明引起的潜在歧义。

更多细节可参考论文原文。