摘要
本文提出了一种基于深度循环网络架构的图片描述生成架构, 在COCO数据集上取得SOTA的水平.

1. 介绍
自动生成图像文本描述是非常有意义的同时也是十分具有挑战性的, 除了视觉理解以外还要有语言模型的加入. 以前的方法把这个问题当成两个子问题分开处理, 正相反我们提出了一个联合模型, 使得在给定图片的条件下生成某个单词序列的概率$ p(S|I)$最大,$I$是输入图像,$S = \lbrace S_1, S_2, ... \rbrace$ 是产生的单词序列. 这篇文章受到当时最新机器翻译技术的启发, 使用一个编码器RNN将源语言文本$S$编码为富含语义信息的向量, 然后再使用一个解码器RNN将该向量作为初始隐含层并生成目标语言文本$T$, 训练最大化$p(T|S)$. 该文章使用CNN来代替RNN编码器来提取表示图像特征, 使用RNN解码器. 主要贡献有: a. 提出了基于神经网络的端到端系统; b. 使用最先进的视觉和语言模型, 扩充了可利用的额外资源; c. 大大超过了以前方法的性能.
2. 相关工作
早些时候研究人员独立使用视觉模型来识别图像物体与关系, 使用语言模型生成文本, 通常基于复杂的人工设计系统如模板等, 这些方法生成的文本很呆板. 后来为了解决这样的问题, 又有人将图片和文本映射到相同的向量空间, 通过寻找距离图像向量最近的文本向量来生成语句. 即使最新的神经网络方法也没有解决无法描述未曾出现物体的问题.
3. 模型
受到机器翻译的启发, 文章提出最大化给定图片生成正确描述的概率:
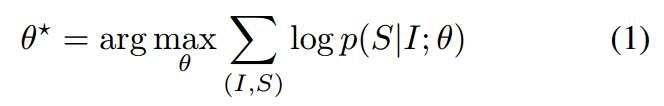
其中, $\theta$是模型参数, $I$是图片, $S$是正确的生成语句. 通常对数部分可以写作:
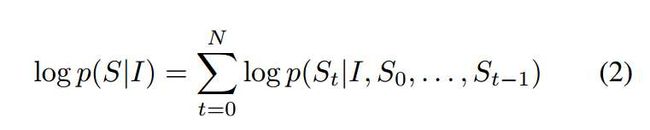
可以使用RNN对这个概率进行建模, 将单词使用隐含层特征$h_t$表示, $h_t = f(h_{t-1}, x_{t-1})$, 为了提高性能,使用ILSVRC 2014比赛的最佳CNN模型和LSTM-RNN.
3.1. 基于LSTM的文本生成器
为了避免RNN的梯度爆炸与弥散问题, 使用LSTM进行解码.
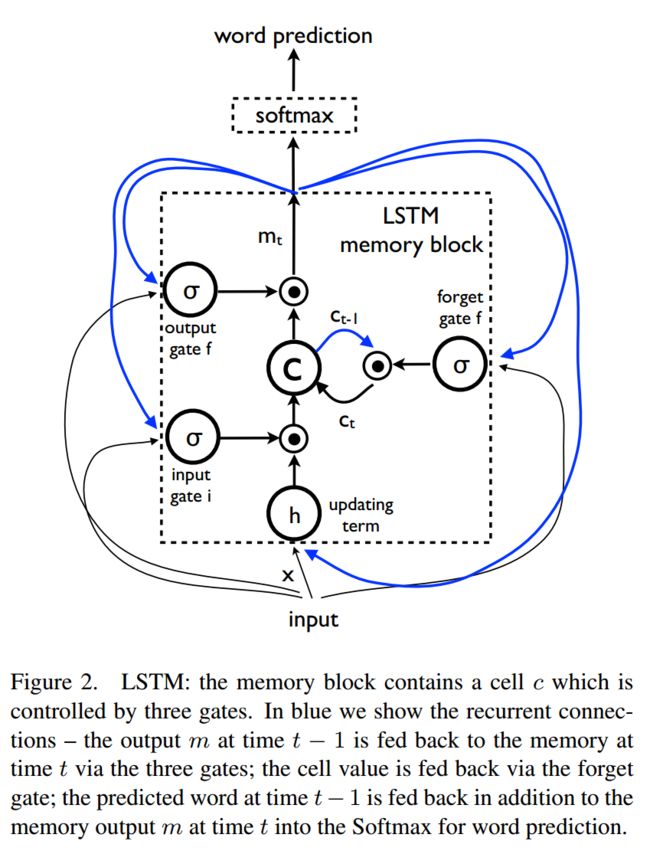
LSTM的定义及跟新规则如下:
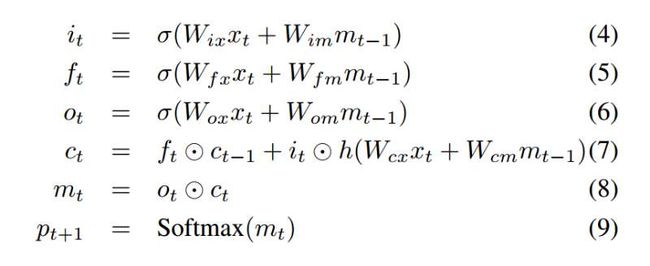
训练过程
将LSTM展开如下图所示:

其中:
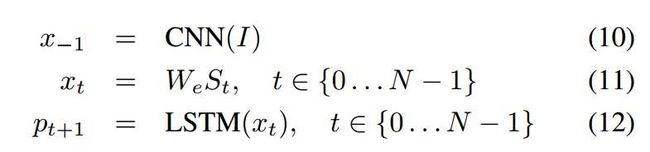
文章中使用独热编码向量$S_t$表示每个单词, 用特殊的$S_0$和$S_N$表示句子的开始和终止, 图片与词语分别使用CNN和词嵌入被映射到同一个空间. 经过实验验证, 图片只在$t = -1$的时候喂进网络一次的效果比每个时间都喂进图片效果好.
Loss函数如下公式:
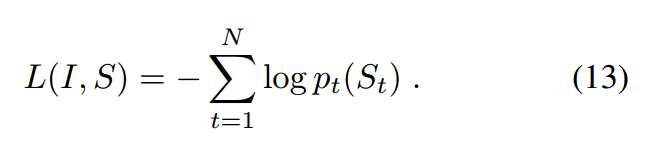
推理过程
NIC推理的方法有两种, 一种是通常的Sampling方法, 即每次只选择概率最大的值生成单词; 另一种是BeamSearch, 每次单词生成时选择概率最大的K个值进行组合(详细课件Seq2Seq中的BeamSearch).
4. 实验
4.1. 评价标准
除了自动化标准外(BLEU, METEOR, CIDER), 本文还使用了人工评价的方式, 对每个句子在1-4之间打分. 同时, 在调参时还使用Perplexity进行参数选择. 最后还可以将图像描述问题转换为描述排名问题,这样就可以利用排序评价标准比如 reacall@k, 但是还是应该更加关注于生成评价方法.
4.2. 数据集
图像描述数据集的统计数据如下:

4.3. 结果
4.3.1. 训练细节
由于图像描述数据集数据不够充分. 为了防止过拟合, NIC使用ImageNet等上的预训练模型来初始化CNN参数. 同时也使用大规模新闻语料库对语言模型参数$W_e$初始化, 但是并无明显效果, 所以最后为了简单没有使用新闻语料库初始化. 最后, 使用了一些模型方面的防过拟合方法, 如Dropout和模型融合以及修改网络模型尺寸等. 所有的参数使用固定学习率的SGD(无动量Momentum)进行优化; 使用512维向量作为词嵌入(Embedding)向量以及LSTM向量的尺寸.
4.3.2. 图像描述生成结果
MSCOCO数据集上的BLEU-1, BLEU-4, METEOR, CIDER模型对比评分如下, 其中人工方法的评分是对5句人工描述计算BELU分数再取平均.

4.3.3. 迁移学习, 数据尺寸及标签质量
Flickr8k和Flickr30k这两个数据集很相似. 且Flick30k训练数据大约是Flickr8k的4倍大小, 所以从30k训练迁移到8k的结果提高了4个BELU点; 但是从MSCOCO(5倍于Flickr30k)迁移到Flickr时, 由于数据相差很远, 所以最终降低了10点. 其他数据集间的迁移情况也类似.
4.3.4. 描述生成多样性讨论
为了研究生成的图像描述是否具有多样性和创新性, 文章使用BeamSearch的方法选出N个得分最高的语句, 其中每张图最好的15个句子的平均BLEU与人类的得分相近, 并且这15个句子中很多是未曾出现在训练数据中的, 因此具有很好的多样性.一些测试集上的BeamSearch方法生成语句如下所示:

4.3.5. 结果排名
给定图片对描述排名及给定描述对图片进行排序都取得了很好的结果,如图所示:

4.3.6. 人工评价
人工评价结果如下图所示, 可见NIC模型优于参考系统但是差于Grond Truth, 这的同时也表明BLEU并不是一个很好的系统.

人工评价的一些例子如下:
4.3.7. 嵌入分析
使用词嵌入作为LSTM解码器的输入, 可以学习到语言中相似的语义信息, 也有利于CNN提取相似的语义特征, 一些最邻近单词的例子如下:

5. 结论
基于CNN和RNN的NIC模型多个数据集及多种评价标准下都展现了强大的生成性能和鲁棒性. 显然, 相关数据集的发展对NIC类似方法的提高也会有很大的帮助. 更进一步, 使用无监督数据集进行相关研究也是很有趣的.