找份钱多活少离家近的工作

前途无忧 | MySQL | 百度地图API | HBuider | 智慧城市
今年想换份工作,然后搜索了一下想转的方向,智慧城市相关的。从结果来看职位类型玲琅满目,然而职位跟我契合的并不多,慢慢找吧,先了解了解职业职位、薪酬、公司、地理分布再说。

需求分析
主要任务: 上篇 简单的实现了网上抓取数据存进数据库中的表,新篇想在以前写过的文章 建筑英才网职位信息统计 稍加更改升级。职位信息可以大致的反映薪酬跟任职要求,但是对于通勤距离的比较可能就没那么直观。
本篇本来还包括活少的环节,本来是想对岗位职责的描述做统计,具体的词云工具我还需要部分时间学习才能实现。暂时就通过薪资跟地理信息来反映下!
步骤
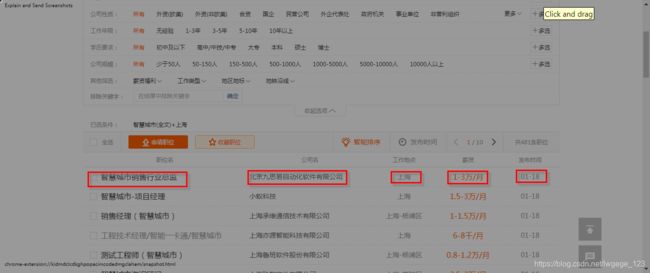
第一步:职位信息提取
首先选用前途无忧网站搜索职位,关键词是智慧城市+上海两关键词。具体的步骤是将数据用框架Scrapy爬虫将信息存进数据库中的表。具体的方法参考: 西刺网代理IP存进数据库 。
网页代码解析: 10页结果存储(部分有问题,页面分批存入)
代码示例(Scrapy部分代码spider)
import scrapy
from search51job.items import Search51JobItem
class SearchjobSpider(scrapy.Spider):
name = 'searchjob'
allowed_domains = ['search.com']
start_urls = ['https://search.51job.com/']
def start_requests(self):
reqs=[]
for i in range(1,11):
req=scrapy.Request("https://search.51job.com/list/020000,000000,0000,00,9,99,智慧城市,2,%s.html?"%i)
reqs.append(req)
return reqs
def parse(self, response):
items = []
positions = response.xpath('//div[@class="el"]/p/span/a/text()').extract()
hrefs = response.xpath('//div[@class="el"]/p/span/a/@href').extract()
companys = response.xpath('//*[@id="resultList"]/div[@class="el"]/span[@class="t2"]/a/text()').extract()
adresses = response.xpath('//*[@id="resultList"]/div[@class="el"]/span[@class="t3"]/text()').extract()
salarys = response.xpath('//*[@id="resultList"]/div[@class="el"]/span[@class="t4"]/text()').extract()
pubdates = response.xpath('//*[@id="resultList"]/div[@class="el"]/span[@class="t5"]/text()').extract()
n=len(companys)
for i in range (0,n):
pre_item = Search51JobItem()
pre_item['position']=positions[i].split()[0]
pre_item['href'] = hrefs[i]
pre_item['company'] = companys[i]
pre_item['adress'] = adresses[i]
pre_item['salary'] = salarys[i]
pre_item['pubdate'] = pubdates[i]
items.append(pre_item)
return items
数据库中的表导出:将表导出成Excel表格(sql语言不是很熟)

第二步:位置信息抓取
位置信息抓取前,要对数据进行清洗(有的岗位有地址,却没有提供百度地图地理位置)岗位招聘网址分析如下:

带地图
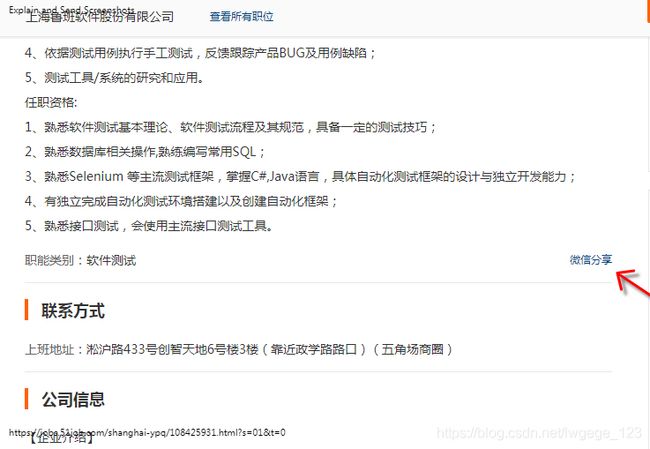
无地图
代码示例(展示的是单个岗位的地址跟经纬度提取)
import requests
from bs4 import BeautifulSoup
import re
import json
url = 'https://jobs.51job.com/shanghai-ypq/108425931.html?s=01&t=0'
wb_data=requests.get(url)
soup=BeautifulSoup(wb_data.content,'lxml')
# address= soup.select(".fp")[2].get_text().split()
# print(address)
# class里的值有空格
map = soup.find_all('a',class_= ["icon_b", "i_map"])
# map = soup.find_all("a.icon_b.i_map")
a=map[2]
# print(a)
pattern=re.compile('.*onclick="showMapIframe\(\'(.*?)\'.*')
b=re.findall(pattern,str(a)) #匹配出公司与职位的信息
final_url=b[0]
wb_data1=requests.get(final_url)
soup1=BeautifulSoup(wb_data1.content,'lxml')
sc=soup1.select('input')[2]
# print(sc)
pattern1=re.compile('.*lat="(.*?)".*')
pattern2=re.compile('.*lng="(.*?)".*')
pattern3=re.compile('.*value="(.*?)".*')
lat=re.findall(pattern1,str(sc))
lng=re.findall(pattern2,str(sc))
address=re.findall(pattern3,str(sc))
print(lat)
print(lng)
print(address)
Excel中重复公司的删除:具体参考
< https://jingyan.baidu.com/article/46650658756e10f549e5f8a7.html>
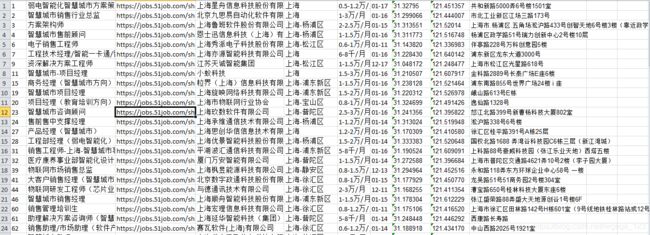
第三步:百度地图实现
H5插入百度地图,这个网上有教程,能生成源代码:
< https://blog.csdn.net/m0_38061194/article/details/79578506>
标注点先标注好居住的地方,公司的位置用数组的方式复制进生成的百度地图就可以,数组生成如下。
代码示例(pycharm写代码生成字典列表)
#function:读excel文件中的数据
import xlrd
import json
#打开一个workbook
workbook = xlrd.open_workbook('searchjob2.xls')
#定位到sheet1
worksheet1 = workbook.sheet_by_name(u'Sheet1')
# 获取第一列数据
order_num = worksheet1.col_values(0)
# 公司名字
titles = worksheet1.col_values(3)
# 纬度信息
lats = worksheet1.col_values(7)
# 经度信息
lngs = worksheet1.col_values(8)
# 地址信息
addresses = worksheet1.col_values(9)
home = "{title:\"我的住址\",content:\"租住的地方\",point:\"121.455217|31.262702\",isOpen:0,icon:{w:21,h:21,l:0,t:0,x:6,lb:5}}"
for i in range (0,len(titles)):
title = titles[i].replace('\'','')
# print(title)
lat = lats[i].replace('\'','')
lng = lngs[i].replace('\'','')
address = addresses[i].replace('\'','')
num = str(order_num[i])
content = title+address
# print(content)
dict = home.replace('我的住址',num).replace('租住的地方',content).replace('121.455217',lng).replace('31.262702',lat)
print(dict+',')
代码运行结果

HBuider里百度地图源代码数据
代码示例(存成记事本也可以,用浏览器打开)
百度地图API自定义地图
显示结果
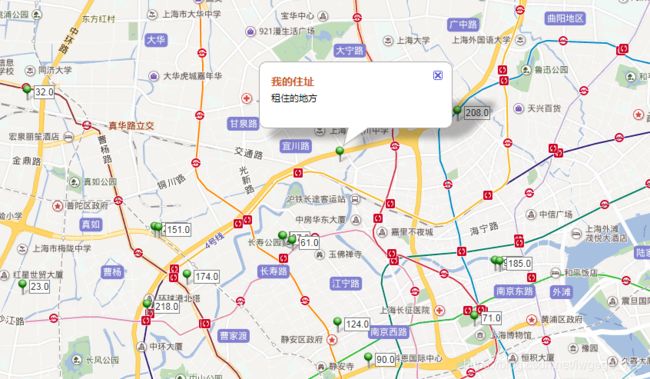

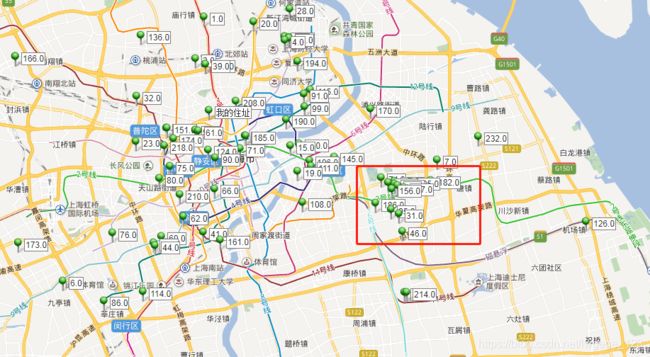
如果标公司名的可能是覆盖住了位置,所以把公司对应的序号标注上来,具体公司名标注进内容,从图可以看出张江高科这块的公司很多。
总结
如果要深入的话,知道地理坐标,可计算家与各公司的位置;百度地图可以采集从家到各公司的交通方式所需的时间。
扫描关注公众号有同名文章:
