爬虫实战6:爬取英雄联盟官网五个位置的综合排行榜保存到excel
申明:资料来源于网络及书本,通过理解、实践、整理成学习笔记。
文章目录
- 英雄联盟官网
- 获取一个位置的综合排行榜所有数据(上单为例)
- 获取所有位置的综合排行榜所有数据
英雄联盟官网
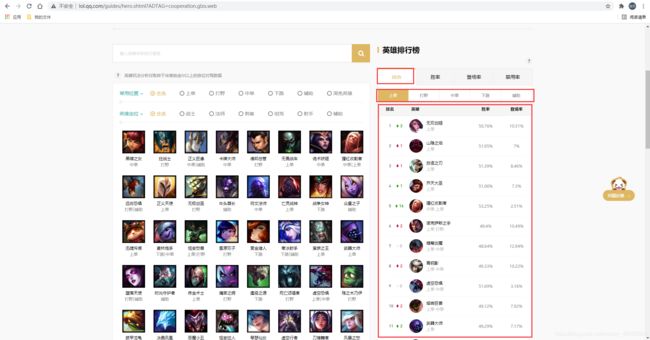
获取一个位置的综合排行榜所有数据(上单为例)
以上单排行榜为例:
- 1、使用谷歌的无头浏览器访问该网页
url = 'http://lol.qq.com/guides/hero.shtml?ADTAG=cooperation.glzx.web' # 创建一个参数对象,用来控制chrome以无界面的方式打开 options = Options() # 后面的两个是固定写法 必须这么写 options.add_argument('--headless') options.add_argument('--disable-gpu') # 创建浏览器对象 driver = webdriver.Chrome(options=options) driver.get(url) - 2、获取上单的所有数据进行数据处理
# 获取上单英雄的所有数据 driver.find_element(By.XPATH, '//a[@data-types="top"]').click() element = driver.find_element(By.ID, 'rankTable') data = element.text.split('\n') data.pop(0) - 3、创建一个excel表格并写入第一行数据
# 新建一个工作簿 wb = Workbook() ws1 = wb.active # 更改sheet名称 ws1.title = '上单英雄' # excel表单第一行 first_line = ('排名', '排名波动', '英雄', '位置', '胜率', '登场率') for i in range(len(first_line)): ws1.cell(1, i + 1, first_line[i]) - 4、处理空值,网页信息中的英雄排名波动有部分英雄是没有值的,这会影响到我们后面批量处理获得的数据,所以我们可以按照索引添加数据0
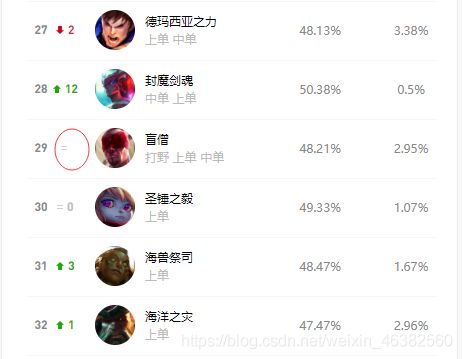
创建一个列表,将有空值的索引添加进去,并在该位置插入数据0# 排名波动空值 employ = [28, 43] for i in range(46): if i in employ: data.insert(i * 5 + 1, '0') - 5、将所有获得的数据分别保存至变量
# 将获取的数据进行处理并保存 rank = data[i * 5] rank_float = data[i * 5 + 1] hero = data[i * 5 + 2] location = data[i * 5 + 3] win_rate = data[i * 5 + 4].split(' ')[0] appearance_rate = data[i * 5 + 4].split(' ')[1] - 6、将所有数据保存到excel表,并保存到本地
# 将数据写入excel表格 ws1.cell(i + 2, 1, rank) ws1.cell(i + 2, 2, rank_float) ws1.cell(i + 2, 3, hero) ws1.cell(i + 2, 4, location) ws1.cell(i + 2, 5, win_rate) ws1.cell(i + 2, 6, appearance_rate) # 保存excel表 wb_name = '英雄联盟上单英雄总和排行榜数据.xlsx' wb.save(wb_name) - 7、完整代码如下
from openpyxl import Workbook from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By url = 'http://lol.qq.com/guides/hero.shtml?ADTAG=cooperation.glzx.web' # 创建一个参数对象,用来控制chrome以无界面的方式打开 options = Options() # 后面的两个是固定写法 必须这么写 options.add_argument('--headless') options.add_argument('--disable-gpu') # 创建浏览器对象 driver = webdriver.Chrome(options=options) driver.get(url) driver.implicitly_wait(10) # 新建一个工作簿 wb = Workbook() ws1 = wb.active ws1.title = '上单英雄' # excel表单第一行 first_line = ('排名', '排名波动', '英雄', '位置', '胜率', '登场率') for i in range(len(first_line)): ws1.cell(1, i + 1, first_line[i]) # 获取上单英雄的所有数据 driver.find_element(By.XPATH, '//a[@data-types="top"]').click() element = driver.find_element(By.ID, 'rankTable') data = element.text.split('\n') data.pop(0) # 排名波动空值 employ = [28, 43] for i in range(46): if i in employ: data.insert(i * 5 + 1, '0') # 将获取的数据进行处理并保存 rank = data[i * 5] rank_float = data[i * 5 + 1] hero = data[i * 5 + 2] location = data[i * 5 + 3] win_rate = data[i * 5 + 4].split(' ')[0] appearance_rate = data[i * 5 + 4].split(' ')[1] # 将数据写入excel表格 ws1.cell(i + 2, 1, rank) ws1.cell(i + 2, 2, rank_float) ws1.cell(i + 2, 3, hero) ws1.cell(i + 2, 4, location) ws1.cell(i + 2, 5, win_rate) ws1.cell(i + 2, 6, appearance_rate) # 保存excel表 wb_name = '英雄联盟上单英雄总和排行榜数据.xlsx' wb.save(wb_name) print(rank, rank_float, hero, location, win_rate, appearance_rate) - 8、运行结果
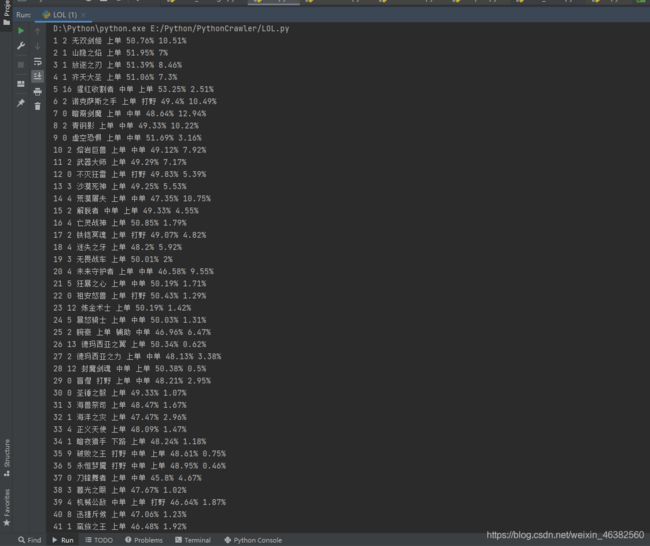

获取所有位置的综合排行榜所有数据
由于需要获取所有位置的数据,如果依次获取,会导致代码量很大,可以使用for循环加上if判断获取
完整代码如下:
from openpyxl import Workbook
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
class LOL:
def get_hero_info(self):
# LOL官网url
url = 'http://lol.qq.com/guides/hero.shtml?ADTAG=cooperation.glzx.web'
# 创建一个参数对象,用来控制chrome以无界面的方式打开
options = Options()
# 后面的两个是固定写法 必须这么写
options.add_argument('--headless')
options.add_argument('--disable-gpu')
# 创建浏览器对象
driver = webdriver.Chrome(options=options)
driver.get(url)
driver.implicitly_wait(10)
# 新建一个工作簿
wb = Workbook()
for j in range(5):
# 获取上单英雄时所要变更的变量
if j == 0:
self.ws = wb.active
self.ws.title = '上单英雄'
driver.find_element(By.XPATH, '//a[@data-types="top"]').click()
self.element = driver.find_element(By.ID, 'rankTable')
# 页面中上单英雄排行波动为空值的索引
self.employ = [28, 43]
# 上单英雄排行总个数
self.num = 46
# 获取打野英雄时所要变更的变量
elif j == 1:
# 创建第2个sheet表单并命名
self.ws = wb.create_sheet('打野英雄', index=1)
# 切换到打野英雄排行榜
driver.find_element(By.XPATH, '//a[@data-types="jungle"]').click()
self.element = driver.find_element(By.ID, 'rankTable')
# 页面中打野英雄排行波动为空值的索引
self.employ = [1, 5, 20, 29, 35]
# 打野英雄排行总个数
self.num = 40
# 获取中单英雄时所要变更的变量
elif j == 2:
# 创建第3个sheet表单并命名
self.ws = wb.create_sheet('中单英雄', index=2)
# 切换到中单英雄排行榜
driver.find_element(By.XPATH, '//a[@data-types="mid"]').click()
self.element = driver.find_element(By.ID, 'rankTable')
# 页面中中单英雄排行波动为空值的索引
self.employ = [24, 59]
# 中单英雄排行总个数
self.num = 60
# 获取下路英雄时所要变更的变量
elif j == 3:
# 创建第4个sheet表单并命名
self.ws = wb.create_sheet('下路英雄', index=3)
# 切换到下路英雄排行榜
driver.find_element(By.XPATH, '//a[@data-types="bottom"]').click()
self.element = driver.find_element(By.ID, 'rankTable')
# 页面中下路英雄排行波动为空值的索引
self.employ = [12]
# 下路英雄排行总个数
self.num = 21
# 获取辅助英雄时所要变更的变量
elif j == 4:
# 创建第5个sheet表单并命名
self.ws = wb.create_sheet('辅助英雄', index=4)
# 切换到辅助英雄排行榜
driver.find_element(By.XPATH, '//a[@data-types="support"]').click()
self.element = driver.find_element(By.ID, 'rankTable')
# 页面中辅助英雄排行波动为空值的索引
self.employ = []
# 辅助英雄排行总个数
self.num = 37
# 处理数据
data = self.element.text.split('\n')
data.pop(0)
# excel表单第一行
first_line = ('排名', '排名波动', '英雄', '位置', '胜率', '登场率')
for i in range(len(first_line)):
self.ws.cell(1, i + 1, first_line[i])
time.sleep(1)
# 排名波动空值
for i in range(self.num):
if i in self.employ:
data.insert(i * 5 + 1, '0')
# 将获取的数据进行处理并保存
rank = data[i * 5]
rank_float = data[i * 5 + 1]
hero = data[i * 5 + 2]
location = data[i * 5 + 3]
win_rate = data[i * 5 + 4].split(' ')[0]
appearance_rate = data[i * 5 + 4].split(' ')[1]
# 将数据写入excel表格
self.ws.cell(i + 2, 1, rank)
self.ws.cell(i + 2, 2, rank_float)
self.ws.cell(i + 2, 3, hero)
self.ws.cell(i + 2, 4, location)
self.ws.cell(i + 2, 5, win_rate)
self.ws.cell(i + 2, 6, appearance_rate)
# 保存excel表
wb_name = '英雄联盟数据.xlsx'
wb.save(wb_name)
print(rank, rank_float, hero, location, win_rate, appearance_rate)
if __name__ == '__main__':
LOL().get_hero_info()
运行结果:
- 上单英雄综合排行榜数据

- 打野英雄综合排行榜数据
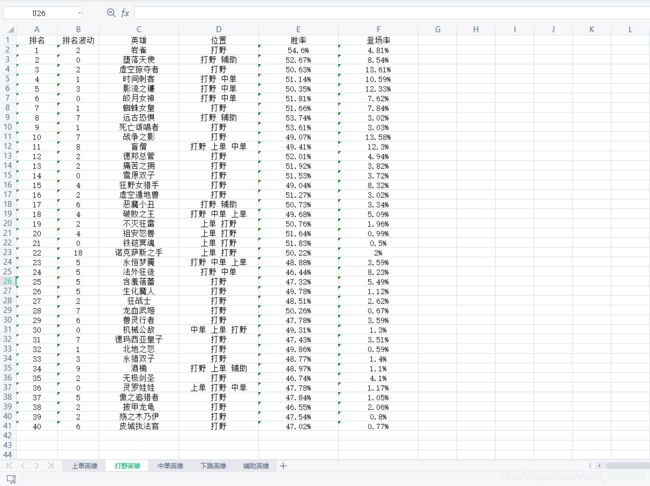
- 中单英雄综合排行榜数据

- 下路英雄综合排行榜数据

- 辅助英雄综合排行榜数据
Python爬虫实战专栏:
爬虫实战5:爬取全部穿越火线武器的图片以武器名称命名保存到本地文件
爬虫实战6:爬取英雄联盟官网五个位置的综合排行榜保存到excel
爬虫实战7:更新中—
一个坚持学习,坚持成长,坚持分享的人,即使再不聪明,也一定会成为优秀的人!
如果看完觉得有所收获的话,记得一键三连哦,谢谢大家!