前端面试超全整理2(vue和react)
16、React 和 Vue 两大框架之间的相爱相杀
React 和 Vue 应该是国内当下最火热的前端框架,当然 Angular 也是一个不错的框架,但是这个产品国内使用的人很少再加上我对 Angular 也不怎么熟悉,所以框架的章节中不会涉及到 Angular 的内容。
这一章节,我们将会来学习以下几个内容
- MVVM 是什么
- Virtual DOM 是什么
- 前端路由是如何跳转的
- React 和 Vue 之间的区别
MVC和MVVM 、MVP
涉及面试题:什么是 MVVM?比之 MVC 有什么区别?
首先先申明一点,不管是 React 还是 Vue,它们都不是 MVVM 框架,只是有借鉴 MVVM 的思路。文中拿 Vue 举例也是为了更好地理解 MVVM 的概念。
MVC,MVP,MVVM是三种常见的前端架构模式,通过分离关注点来改进代码组织方式。MVC模式是MVP,MVVM模式的基础,这两种模式更像是MVC模式的优化改良版,他们三个的MV即Model,view都是相同的,不同的是MV之间的桥梁连接部分。
一、MVC
视图(View):用户界面,只负责渲染 HTML
控制器(Controller):业务逻辑,负责调度 model 和 view
模型(Model):数据保存,只负责存储数据、请求数据、更新数据
MVC允许在不改变视图情况下改变视图对用户输入的响应方式,用户对View操作交给Controller处理在Controller中响应View的事件调用Model的接口对数据进行操作,一旦Model发生变化便通知相关视图View进行更新。
接受用户指令时,MVC 可以分成两种方式。一种是通过 View 接受输入,传递给 Controller。另一种是直接通过controller接受指令。此处只画了第一种情况。

但是 MVC 有一个巨大的缺陷就是控制器承担的责任太大了,随着项目愈加复杂,控制器中的代码会越来越臃肿,导致出现不利于维护的情况。
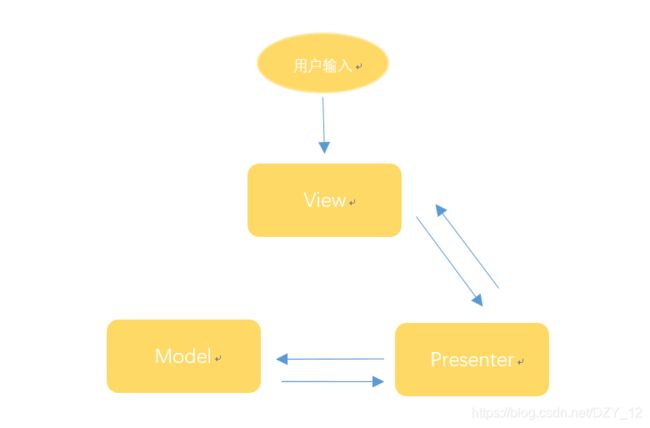
二、MVP
MVP 模式将 Controller 改名为 Presenter,同时改变了通信方向。
与MVC最大的区别就是View和Model层完全解耦,不在有依赖关系,而是通过Presenter做桥梁,用于操作view层发出的事件传递到presenter层中,presenter层去操作model层,并且将数据返回给view层,整个过程中view层和model层完全没有联系。
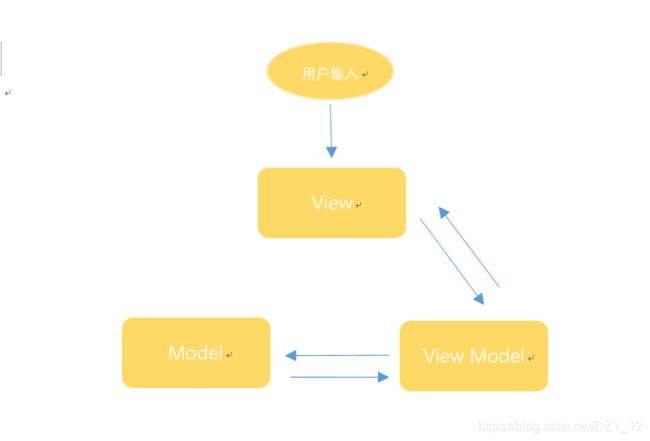
三、MVVM
MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。唯一的区别是,它采用双向绑定(data-binding),View的变动,自动反映在 ViewModel,反之亦然。
这里我们拿典型的MVVM模式的代表,Vue,来举例:
<div id="app-5">
<p>{
{
message }}</p>
<button v-on:click="reverseMessage">逆转消息</button>
</div>
var app5 = new Vue({
el: '#app-5',
data: {
message: 'Hello Vue.js!'
},
methods: {
reverseMessage: function () {
this.message = this.message.split('').reverse().join('')
}
}
})
这里的html部分相当于View层,可以看到这里的View通过通过模板语法来声明式的将数据渲染进DOM元素,当ViewModel对Model进行更新时,通过数据绑定更新到View。
Vue实例中的data相当于Model层,而ViewModel层的核心是Vue中的双向数据绑定,即Model变化时VIew可以实时更新,View变化也能让Model发生变化。
整体看来,MVVM比MVC精简很多,不仅简化了业务与界面的依赖,还解决了数据频繁更新的问题,不用再用选择器操作DOM元素。因为在MVVM中,View不知道Model的存在,Model和ViewModel也观察不到View,这种低耦合模式提高代码的可重用性。
除了以上三个部分,其实在 MVVM 中还引入了一个隐式的 Binder 层,实现了 View 和 ViewModel 的绑定。这个隐式的 Binder 层就是 Vue 通过解析模板中的插值和指令从而实现 View 与 ViewModel 的绑定。
对于 MVVM 来说,其实最重要的并不是通过双向绑定或者其他的方式将 View 与 ViewModel 绑定起来,而是通过 ViewModel 将视图中的状态和用户的行为分离出一个抽象,这才是 MVVM 的精髓。很简单,就是用户看到的视图
- Model 同样很简单,一般就是本地数据和数据库中的数据
基本上,我们写的产品就是通过接口从数据库中读取数据,然后将数据经过处理展现到用户看到的视图上。当然我们还可以从视图上读取用户的输入,然后又将用户的输入通过接口写入到数据库中。但是,如何将数据展示到视图上,然后又如何将用户的输入写入到数据中,不同的人就产生了不同的看法,从此出现了很多种架构设计。
传统的 MVC 架构适用大型项目Model(业务模型)(放业务数据;存储视图模型) view(用户界面css html) controller(控制器)(处理用户交互)
通常是使用控制器更新模型,视图从模型中获取数据去渲染。当用户有输入时,会通过控制器去更新模型,并且通知视图进行更新。

但是 MVC 有一个巨大的缺陷就是控制器承担的责任太大了,随着项目愈加复杂,控制器中的代码会越来越臃肿,导致出现不利于维护的情况。
在 MVVM 架构中,引入了 ViewModel 的概念。ViewModel 只关心数据和业务的处理,不关心 View 如何处理数据,在这种情况下,View 和 Model 都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个 ViewModel 中,让多个 View 复用这个 ViewModel。
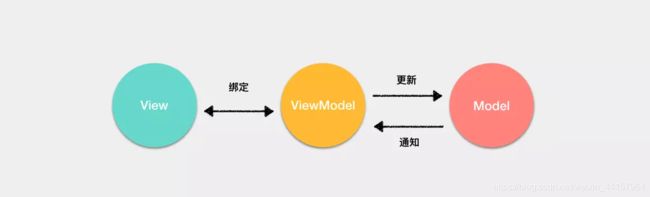
以 Vue 框架来举例,ViewModel 就是组件的实例。View 就是模板,Model 的话在引入 Vuex 的情况下是完全可以和组件分离的。
除了以上三个部分,其实在 MVVM 中还引入了一个隐式的 Binder 层,实现了 View 和 ViewModel 的绑定。
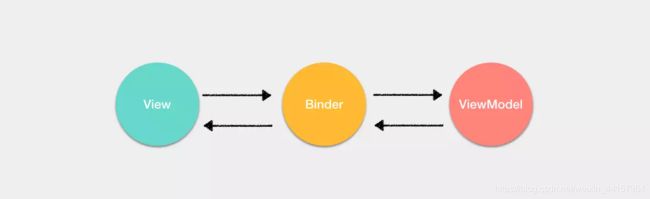
同样以 Vue 框架来举例,这个隐式的 Binder 层就是 Vue 通过解析模板中的插值和指令从而实现 View 与 ViewModel 的绑定。
对于 MVVM 来说,其实最重要的并不是通过双向绑定或者其他的方式将 View 与 ViewModel 绑定起来,而是通过 ViewModel 将视图中的状态和用户的行为分离出一个抽象,这才是 MVVM 的精髓。
Virtual DOM
涉及面试题:什么是 Virtual DOM?为什么 Virtual DOM 比原生 DOM 快?
想必大家都听过操作 DOM 性能很差,但是这其中的原因是什么呢?
因为 DOM 是属于渲染引擎中的东西,而 JS 又是 JS 引擎中的东西。当我们通过 JS 操作 DOM 的时候,其实这个操作涉及到了两个线程之间的通信,那么势必会带来一些性能上的损耗。操作 DOM 次数一多,也就等同于一直在进行线程之间的通信,并且操作 DOM 可能还会带来重绘、回流的情况,所以也就导致了性能上的问题。那么既然 DOM 可以通过 JS 对象来模拟,反之也可以通过 JS 对象来渲染出对应的 DOM。当然了,通过 JS 来模拟 DOM 并且渲染对应的 DOM 只是第一步,难点在于如何判断新旧两个 JS 对象的最小差异并且实现局部更新 DOM。
首先 DOM 是一个多叉树的结构,如果需要完整的对比两颗树的差异,那么需要的时间复杂度会是 O(n ^ 3),这个复杂度肯定是不能接受的。于是 React 团队优化了算法,实现了 O(n) 的复杂度来对比差异。 实现 O(n) 复杂度的关键就是只对比同层的节点,而不是跨层对比,这也是考虑到在实际业务中很少会去跨层的移动 DOM 元素。 所以判断差异的算法就分为了两步
-
首先从上至下,从左往右遍历对象,也就是树的深度遍历,这一步中会给每个节点添加索引,便于最后渲染差异
-
一旦节点有子元素,就去判断子元素是否有不同
-
当我们判断出以上的差异后,就可以把这些差异记录下来。当对比完两棵树以后,就可以通过差异去局部更新 DOM,实现性能的最优化。
-
当然了 Virtual DOM 提高性能是其中一个优势,其实最大的优势还是在于:
- 将 Virtual DOM 作为一个兼容层,让我们还能对接非 Web 端的系统,实现跨端开发。
- 同样的,通过 Virtual DOM 我们可以渲染到其他的平台,比如实现 SSR、同构渲染等等。
- 实现组件的高度抽象化
路由原理
涉及面试题:前端路由原理?两种实现方式有什么区别?
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新页面。目前前端使用的路由就只有两种实现方式
- Hash 模式
- History 模式
路由原理:本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新
路由需要实现三个功能:
①浏览器地址变化,切换页面;
②点击浏览器【后退】、【前进】按钮,网页内容跟随变化;
③刷新浏览器,网页加载当前路由对应内容
- hash 模式
点击跳转或者浏览器历史跳转当#后面的哈希值发生变化时,不会向服务器请求数据,可以通过hashchange事件来监听到 URL 的变化,从而进行跳转页面
手动刷新不会触发hashchange事件,可以采用load事件监听解析URL
匹配相应的路由规则,跳转到相应的页面,然后通过DOM替换更改页面内容
this.mode==='hash"
location.hash=path
history.pushState({
path},"","?"+path)
- history 模式
利用history API实现url地址改变, 网页内容改变
History.back()、History.forward()、History.go() 移动到以前访问过的页面时,页面通常是从浏览器缓存之中加载,而不是重新要求服务器发送新的网页
History.pushState()
用于在历史中添加一条记录。该方法接受三个参数,依次为一个与添加的记录相关联的状态对象:state;新页面的标题title;必须与当前页面处在同一个域下的新的网址url
该方法不会触发页面刷新,只是导致 History 对象发生变化,地址栏会有反应,不会触发hashchange事件
History.replaceState()方法用来修改 History 对象的当前记录
每当同一个文档的浏览历史(即history对象)出现变化时,就会触发popstate事件。
pushState()方法或replaceState()不会触发
前进后退 history.back() history.forword() history.go()会触发
回调函数中可以获取event.state
页面第一次加载的时候,浏览器不会触发popstate事件。
两种模式对比
- Hash 模式只可以更改
#后面的内容,History 模式可以通过 API 设置任意的同源 URL - History 模式可以通过 API 添加任意类型的数据到历史记录中,Hash 模式只能更改哈希值,也就是字符串
- Hash 模式无需后端配置,并且兼容性好。History 模式在用户手动输入地址或者刷新页面的时候会发起 URL 请求,后端需要配置
index.html页面用于匹配不到静态资源的时候
Vue 和 React 之间的区别
Vue 的表单可以使用 v-model 支持双向绑定,相比于 React 来说开发上更加方便,当然了 v-model 其实就是个语法糖,本质上和 React 写表单的方式没什么区别。
改变数据方式不同,Vue 修改状态相比来说要简单许多,React 需要使用 setState 来改变状态,并且使用这个 API 也有一些坑点。并且 Vue 的底层使用了依赖追踪,页面更新渲染已经是最优的了,但是 React 还是需要用户手动去优化这方面的问题。
React 16以后,有些钩子函数会执行多次,这是因为引入 Fiber 的原因,这在后续的章节中会讲到。
React 需要使用 JSX,有一定的上手成本,并且需要一整套的工具链支持,但是完全可以通过 JS 来控制页面,更加的灵活。Vue 使用了模板语法,相比于 JSX 来说没有那么灵活,但是完全可以脱离工具链,通过直接编写 render 函数就能在浏览器中运行。
在生态上来说,两者其实没多大的差距,当然 React 的用户是远远高于 Vue 的。
在上手成本上来说,Vue 一开始的定位就是尽可能的降低前端开发的门槛,然而 React 更多的是去改变用户去接受它的概念和思想,相较于 Vue 来说上手成本略高。
小结
这一章节中我们学习了几大框架中的相似点,也对比了 React 和 Vue 之间的区别。其实我们可以发现,React 和 Vue 虽然是两个不同的框架,但是他们的底层原理都是很相似的,无非在上层堆砌了自己的概念上去。所以我们无需去对比到底哪个框架牛逼,引用尤大的一句话
说到底,就算你证明了 A 比 B 牛逼,也不意味着你或者你的项目就牛逼了… 比起争这个,不如多想想怎么让自己变得更牛逼吧。
17、Vue 常考基础知识点
这一章节我们将来学习 Vue 的一些经常考到的基础知识点。
组件的data 选项必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝,不然一个实例的data改变所有实例的date的引用都会改变
生命周期函数
Vue实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模板、挂载Dom、渲染→更新→渲染、销毁等一系列过程,我们称这是Vue的生命周期。通俗说就是Vue实例从创建到销毁的过程,就是生命周期。
每一个组件或者实例都会经历一个完整的生命周期,总共分为三个阶段:初始化、运行中、销毁。
- 实例、组件通过new Vue() 创建出来之后会初始化事件和生命周期,然后就会执行beforeCreate钩子函数,这个时候,数据还没有挂载呢,只是一个空壳,无法访问到数据和真实的dom,一般不做操作
- 挂载数据,绑定事件等等,然后执行created函数,这个时候已经可以使用到数据,也可以更改数据,在这里更改数据不会触发updated函数,在这里可以在渲染前倒数第二次更改数据的机会,不会触发其他的钩子函数,一般可以在这里做初始数据的获取
- 接下来开始找实例或者组件对应的模板,编译模板为虚拟dom放入到render函数中准备渲染,然后执行beforeMount钩子函数,在这个函数中虚拟dom已经创建完成,马上就要渲染,在这里也可以更改数据,不会触发updated,在这里可以在渲染前最后一次更改数据的机会,不会触发其他的钩子函数,一般可以在这里做初始数据的获取
- 接下来开始render,渲染出真实dom,然后执行mounted钩子函数,此时,组件已经出现在页面中,数据、真实dom都已经处理好了,事件都已经挂载好了,可以在这里操作真实dom等事情…
- 当组件或实例的数据更改之后,会立即执行beforeUpdate,然后vue的虚拟dom机制会重新构建虚拟dom与上一次的虚拟dom树利用diff算法进行对比之后重新渲染,一般不做什么事儿
- 当更新完成后,执行updated,数据已经更改完成,dom也重新render完成,可以操作更新后的虚拟dom
- 当经过某种途径调用$destroy方法后,立即执行beforeDestroy,一般在这里做一些善后工作,例如清除计时器、清除非指令绑定的事件等等
- 组件的数据绑定、监听…去掉后只剩下dom空壳,这个时候,执行destroyed,在这里做善后工作也可以
beforeCreate:此时获取不到prop和data中的数据;
created:可以获取到prop和data中的数据;
beforeMount:获取到了VDOM;
mounted:VDOM解析成了真实DOM;
beforeUpdate:在更新之前调用;
updated:在更新之后调用;
keep-alive:切换组件之后,组件放进activated,之前的组件放进deactivated;
beforeDestory:在组件销毁之前调用,可以解决内存泄露的问题,如setTimeout和setInterval造成的问题。 destory:组件销毁之后调用。
beforeCreate (使用的频率较低)
在实例创建以前
data 数据访问不到
created (使用频率高)
实例创建完
能拿到data下的数据,能修改data的数据
修改数据不会触发updated , beforeUpdate 钩子函数
取不到最终渲染完成的dom
beforeMount (在挂载之前)
编译模板已经结束
可以访问data数据
可以修改数据,修改数据不会触发updated , beforeUpdate 钩子函数
mounted (挂载)
真实的dom节点已经渲染到页面,可以操作渲染后的dom
可以访问和更改数据,会触发updated , beforeUpdate 钩子函数
beforeUpdate
修改之前会被调用
updated
修改数据之后会被调用
beforeDetroy
实例卸载之前会被调用,可以清理一些资源,防止内存泄漏
destroyed
computed: 基于现有的属性,衍生出来一个新的属性,如果数据不发生变化,会重缓存中读取
watch:观测data下数据的变化,当数据有变化时,会执行对应的函数
组件之间数据共享
总结概述
组件是 vue.js最强大的功能之一,而组件实例的作用域是相互独立的,这就意味着不同组件之间的数据无法相互引用。针对不同的使用场景,如何选择行之有效的通信方式?
1:props emit 缺点:如果组件嵌套层次多的话,数据传递比较繁琐
2:provide inject (依赖注入),缺点:不支持响应式
3:this.$root -------- this.$parent --------- this.$refs
4: eventbus 缺点:数据不支持响应式
5: vuex 缺点:数据的读取和修改需要按照流程来操作,不适合小型项目
父子通信:
父组件向子组件传递数据可以通过 props;
子组件向父组件是通过 $emit、$on事件;
provide / inject ;
还可以通过 $root、$parent、$refs属性相互访问组件实例;
兄弟通信: eventbus ;Vuex;
跨级通信: eventbus ;Vuex;provide / inject;
一、 props/ $emit
父组件A通过props的方式向子组件B传递,B to A 通过在 B 组件中 $emit, A 组件中 v-on 的方式实现。
1、父组件向子组件传值
用“v-bind”来告诉 Vue传给prop一个什么类型的值; 子组件用props获取数据;
prop 只可以从上一级组件传递到下一级组件(父子组件),即所谓的单向数据流。
而且 prop 只读,不可被修改,所有修改都会失效并警告。
缺点:如果组件嵌套层次多的话,数据传递比较繁琐。
<div id="app">
<!-- 需要用“v-bind”来告诉 Vue传给prop一个什么类型的值;
左边":"后为父组件传入的变量名;右边为子组件props接受的变量名-->
<root-temp :catalogue.keyWord="catalogue" :articles="articleList"></root-temp>
</div>
<script type="text/template" id="childTemp">
<div>
<!-- 获取一个数组 -->
<li v-for="(item, index) in articles" :key="index">{
{
item}}</li>
</ol>
</div>
</script>
<script>
//全局注册的父组件
Vue.component('root-temp', {
props: ["articles"],
//子组件
template: "#childTemp",
})
var vm = new Vue({
el: "#app",
data: {
articleList: ['红楼梦', '西游记', '三国演义',"水浒传"]
},
})
</script>
</body>
</html>
2、子组件向父组件传值(通过事件形式)
对于$emit 我觉得理解是这样的: $emit绑定一个自定义事件, 当这个语句被执行时, 就会将参数arg传递给父组件,父组件通过v-on监听并接收参数。通过一个例子,说明子组件如何向父组件传递数据。
总结:在子组件中对加减事件进行侦听,操作数据驱动显示;数据改变时,使用$emit向外发布“counterchange”事件,并将数据放在第二个参数传递;在父组件里通过@counterchange="handleChange"就可以订阅handleChange事件了;handleChange函数拿到的参数赋给实例data选项中的一个属性;就可以在父级组件之间使用。
缺点:如果组件嵌套层次多的话,数据传递比较繁琐。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="../../vue.js"></script>
</head>
<body>
<div id="app">
{
{
count}}
<gp-counter @counterchange="handleChange"></gp-counter>
</div>
<script type="text/template" id="counterTemp">
<div>
<h1>gp-counter</h1>
<div>
<button @click="decrement(1)">-</button>
<button @click="increment(1)">+</button>
</div>
</div>
</script>
<script>
Vue.component('gp-counter', {
template: "#counterTemp",
//组件的data 选项必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝,不然一个实例的data改变所有实例的date的引用都会改变,:
data() {
return {
//子组件将要向外发送的数据:给个初始值为0
count: 0
}
},
methods: {
//子组件中对加减事件进行侦听,操作数据驱动显示
increment(num) {
this.count++;
//数据改变时,使用$emit向外发布“counterchange”事件,并将数据放在第二个参数传递;
this.$emit('counterchange', this.count)
},
decrement(num) {
this.count--;
this.$emit('counterchange', this.count)
}
}
})
var vm = new Vue({
el: "#app",
data: {
count: 0
},
methods: {
handleChange(num) {
this.count = num;
}
}
})
</script>
</body>
</html>
二、provide/ inject
概念:provide/ inject 是vue2.0新增的api,简单来说就是父组件中通过provide来提供变量, 然后在子组件中通过inject来注入变量;主要解决了跨级组件间的通信问题,不过它的使用场景,主要是子组件获取上级组件的状态,跨级组件间建立了一种主动提供与依赖注入的关系。接下来就用一个例子来验证上面的描述: 假设有三个组件: A、B、C 其中 C是B的子组件,B是A的子组件
const compc = {
//利用inject实现注入变量username
inject: ['username'],
template: '“孙子”组件------{
{username}}
'
}
var vm = new Vue({
el: "#app",
data: {
username: 'apple'
},
//provide函数结合data选项配置数据
provide: function () {
return {
username: this.username
}
},
components: {
compa
}
})
!
通过对比来看这里不论子组件嵌套有多深, 只要调用了inject 那么就可以注入provide中的数据,而不局限于只能从当前父组件的props属性中回去数据;注意配置和注入的变量名要保持一致。
缺点:provide inject (依赖注入)不支持响应式
三、$root、$parent、$refs
1、$root Vue 子组件可以通过$root 属性获取vue的根实例,比如在简单的项目中将公共数据放再vue根实例上(可以理解为一个全局 store ),因此可以代替vuex实现状态管理;
2、$parent 属性可以用来从一个子组件访问父组件的实例,可以替代将数据以 prop 的方式传入子组件的方式;当变更父级组件的数据的时候,容易造成调试和理解难度增加;
3、在子组件上使用ref特性后,this.$refs 属性可以直接访问该子组件。可以代替事件$emit 和$on 的作用。使用方式是通过 ref 特性为这个子组件赋予一个 ID 引用,再通过this.$refs.testId获取指定元素。注意:$refs 只会在组件渲染完成之后生效,并且它们不是响应式的。这仅作为一个用于直接操作子组件的“逃生舱”——你应该避免在模板或计算属性中访问 $refs。
root 和parent 的区别
root 和parent 都能够实现访问父组件的属性和方法,
两者的区别在于,如果存在多级子组件,通过parent 访问得到的是它最近一级的父组件,通过root 访问得到的是根父组件。
所有子组件都可以将这个实例作为一个全局 store 来访问或使用
// 获取根组件的数据
this.$root.message
// 写入根组件的数据
this.$root.message= 2
// 访问根组件的计算属性
this.$root.selfdate
// 调用根组件的方法
this.$root.selfmethods()
$refs 访问子组件实例;通过在子组件标签定义 ref 属性,在父组件中可以使用$refs 访问子组件实例
<div id="app">
<button @click="add">通过ref访问子组件</button>
<input type="text" ref="inputDate"/>
</div>
<script>
var app = new Vue({
el: '#app',
methods: {
add:function(){
console.log("获取子组件的input.value---->",this.$refs.inputDate.value)
this.$refs.inputDate.value ="test"; //this.$refs.inputDate 减少获取dom节点的消耗
console.log("获取更改后的子组件input.value---->",this.$refs.inputDate.value)
}
}
})
</script>
四、eventBus
eventBus又称为事件总线,在vue中可以使用它来作为沟通桥梁的概念, 就像是所有组件共用相同的事件中心,可以向该中心注册发送事件或接收事件, 所以组件都可以通知其他组件。在Vue的项目中怎么使用eventBus来实现组件之间的数据通信呢?具体通过下面几个步骤
1. 实例初始化
首先需要创建一个事件总线并将其导出, 以便其他模块可以使用或者监听它.
var eventbus = new Vue();
2. 发送事件
methods: {
handleClick() {
eventbus.$emit('message', 'hello world')
}
}
3. 接收事件
const compb = {
template: 'EventBus-componentb
',
mounted() {
eventbus.$on('message', function (msg) {
console.log(msg)
})
}
}
4. 移除事件监听
如果需要移除事件的监听:
mounted() {
eventbus.$off('message', function (msg) {
console.log(msg)
})
}
**缺点:**`eventbus` 方式数据不支持响应式;当项目较大,维护起来也比较困难。
五、Vuex
1.简要介绍Vuex原理
Vuex实现了一个单向数据流,在全局拥有一个State存放数据,当组件要更改State中的数据时,必须通过Mutation进行,Mutation同时提供了订阅者模式供外部插件调用获取State数据的更新。而当所有异步操作(常见于调用后端接口异步获取更新数据)或批量的同步操作需要走action,但action也是无法直接修改State的,还是需要通过Mutation来修改State的数据。最后,根据State的变化,渲染到视图上。
2.简要介绍各模块在流程中的功能:
Vue Components:Vue组件。HTML页面上,负责接收用户操作等交互行为,执行dispatch方法触发对应action进行回应。
dispatch:操作行为触发方法,是唯一能执行action的方法。
actions:操作行为处理模块,由组件中的 $store.dispatch(‘action 名称’,data)来触发。然后由commit()来触发mutation的调用 , 间接更新 state。负责处理Vue Components接收到的所有交互行为。
commit:状态改变提交操作方法。对mutation进行提交,是唯一能执行mutation的方法。
mutations:状态改变操作方法,由actions中的 commit(‘mutation 名称’)来触发。是Vuex修改state的唯一推荐方法。该方法只能进行同步操作,且方法名只能全局唯一。
state:页面状态管理容器对象。集中存储Vue components中data对象的零散数据,全局唯一,以进行统一的状态管理。
getters:Vue Components通过该方法读取全局state对象。
浏览器适配
postcss-px-to-viewport
https://www.npmjs.com/package/postcss-px-to-viewport
https://www.postcss.parts/
移动端滚动条
better-scroll:
https://github.com/ustbhuangyi/better-scroll
虚拟DOM
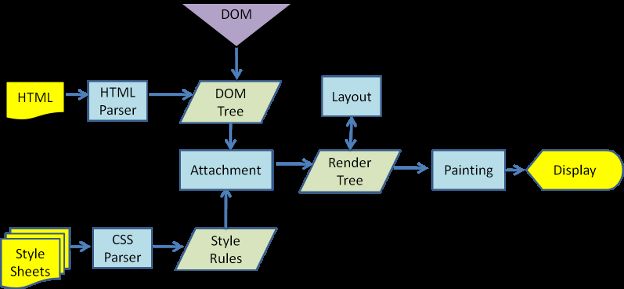
一、真实DOM和其解析流程
浏览器渲染引擎工作流程都差不多,大致分为5步,创建DOM树——创建StyleRules——创建Render树——布局Layout——绘制Painting
第一步,用HTML分析器,分析HTML元素,构建一颗DOM树(标记化和树构建)。
第二步,用CSS分析器,分析CSS文件和元素上的inline样式,生成页面的样式表。
第三步,将DOM树和样式表,关联起来,构建一颗Render树(这一过程又称为Attachment)。每个DOM节点都有attach方法,接受样式信息,返回一个render对象(又名renderer)。这些render对象最终会被构建成一颗Render树。
第四步,有了Render树,浏览器开始布局,为每个Render树上的节点确定一个在显示屏上出现的精确坐标。
第五步,Render树和节点显示坐标都有了,就调用每个节点paint方法,把它们绘制出来。
DOM树的构建是文档加载完成开始的?
构建DOM树是一个渐进过程,为达到更好用户体验,渲染引擎会尽快将内容显示在屏幕上。它不必等到整个HTML文档解析完毕之后才开始构建render树和布局。
Render树是DOM树和CSSOM树构建完毕才开始构建的吗?
这三个过程在实际进行的时候又不是完全独立,而是会有交叉。会造成一边加载,一遍解析,一遍渲染的工作现象。
CSS的解析是从右往左逆向解析的(从DOM树的下-上解析比上-下解析效率高),嵌套标签越多,解析越慢。
二、JS操作真实DOM的代价!
用我们传统的开发模式,原生JS或JQ操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程。在一次操作中,我需要更新10个DOM节点,浏览器收到第一个DOM请求后并不知道还有9次更新操作,因此会马上执行流程,最终执行10次。例如,第一次计算完,紧接着下一个DOM更新请求,这个节点的坐标值就变了,前一次计算为无用功。计算DOM节点坐标值等都是白白浪费的性能。即使计算机硬件一直在迭代更新,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户体验。
为什么需要虚拟DOM,它有什么好处?
Web界面由DOM树(树的意思是数据结构)来构建,当其中一部分发生变化时,其实就是对应某个DOM节点发生了变化。
虚拟DOM就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地一个JS对象中,最终将这个JS对象一次性attch到DOM树上,再进行后续操作,避免大量无谓的计算量。所以, 用JS对象模拟DOM节点的好处是,页面的更新可以先全部反映在JS对象(虚拟DOM)上,操作内存中的JS对象的速度显然要更快,等更新完成后,再将最终的JS对象映射成真实的DOM,交由浏览器去绘制。
组件通信
- props emit 缺点:如果组件嵌套层次多的话,数据传递比较繁琐
- provide inject (依赖注入),缺点:不支持响应式
this.$rootthis.$parent维护不方便 ,不知道在哪个组件更改的
this.$refs- eventbus 缺点:数据不支持响应式
- vuex 缺点:数据的读取和修改需要按照流程来操作,不适合小型项目
我们可以按组件之间的三种关系简单归纳一下组件之间的通信方式:
进行父子组件通信:
1、父组件向子组件传递数据可以通过 props;缺点:如果组件嵌套层次多的话,数据传递比较繁琐
2、子组件向父组件是通过 e m i t 、 emit、 emit、on事件;缺点:如果组件嵌套层次多的话,数据传递比较繁琐
3、provide / inject ;(依赖注入)
provide函数结合vue实例中data选项来配置属性数据 利用inject实现向组件中注入变量
4、还可以通过$root、$parent、$refs属性相互访问组件实例;
root 和parent 的区别
root 和parent 都能够实现访问父组件的属性和方法,两者的区别在于,如果存在多级子组件,通过parent 访问得到的是它最近一级的父组件,通过root 访问得到的是根父组件。
所有子组件都可以将这个实例作为一个全局 store 来访问或使用
// 获取根组件的数据
this.$root.message
$refs 访问子组件实例;通过在子组件标签定义 ref 属性,在父组件中可以使用$refs 访问子组件实例
兄弟组件通信: eventbus ;Vuex;
跨级组件通信: eventbus ;Vuex;provide / inject;
eventBus 又称为事件总线,在vue中可以使用它来作为沟通桥梁的概念, 就像是所有组件共用相同的事件中心,可以向该中心注册发送事件或接收事件, 所以组件都可以通知其他组件。
- 实例初始化 var eventbus = new Vue();
- 发送事件 eventbus.$emit(‘message’, ‘hello world’)
- 接受事件 eventbus.$on(‘message’, function (msg) { console.log(msg) })
Vuex
1.简要介绍Vuex原理
Vuex实现了一个单向数据流,在全局拥有一个State存放数据,当组件要更改State中的数据时,必须通过Mutation进行,Mutation同时提供了订阅者模式供外部插件调用获取State数据的更新。而当所有异步操作(常见于调用后端接口异步获取更新数据)或批量的同步操作需要走action,但action也是无法直接修改State的,还是需要通过Mutation来修改State的数据。最后,根据State的变化,渲染到视图上。
2.简要介绍各模块在流程中的功能:
Vue Components:Vue组件。HTML页面上,负责接收用户操作等交互行为,执行dispatch方法触发对应action进行回应。
dispatch:操作行为触发方法,是唯一能执行action的方法。
actions:操作行为处理模块,由组件中的 $store.dispatch(‘action 名称’,data)来触发。然后由commit()来触发mutation的调用 , 间接更新 state。负责处理Vue Components接收到的所有交互行为。
commit:状态改变提交操作方法。对mutation进行提交,是唯一能执行mutation的方法。
mutations:状态改变操作方法,由actions中的 commit(‘mutation 名称’)来触发。是Vuex修改state的唯一推荐方法。该方法只能进行同步操作,且方法名只能全局唯一。
改变状态的唯一途经就是通过mutation,这样可以让共享状态易于预测。使用commit方法触发mutation处理函数;mutation的同步特性是出于调试的目的,可以借助开发者工具生成快照方便地调试应用。
state:页面状态管理容器对象。集中存储Vue components中data对象的零散数据,全局唯一,以进行统一的状态管理。
getters:Vue Components通过该方法读取全局state对象。
插槽
自定义组件v-model的实现
父组件和子组件生命周期钩子的渲染顺序是什么
创建的时候从外到里,挂载的时候从里到外
加载渲染过程
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
子组件更新过程
父beforeUpdate->子beforeUpdate->子updated->父updated
父组件更新过程
父beforeUpdate->父updated
销毁过程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
extend 能做什么
这个 API 很少用到,作用是扩展组件生成一个构造器,通常会与 $mount 一起使用。
// 创建组件构造器
let Component = Vue.extend({
template: 'test'
})
// 挂载到 #app 上
new Component().$mount('#app')
// 除了上面的方式,还可以用来扩展已有的组件
let SuperComponent = Vue.extend(Component)
new SuperComponent({
created() {
console.log(1)
}
})
new SuperComponent().$mount('#app')
mixin 和 mixins 区别
mixin 用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的。
Vue.mixin({
beforeCreate() {
// ...逻辑
// 这种方式会影响到每个组件的 beforeCreate 钩子函数
}
})
虽然文档不建议我们在应用中直接使用 mixin,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的 ajax 或者一些工具函数等等。
mixins 应该是我们最常使用的扩展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过 mixins 混入代码,比如上拉下拉加载数据这种逻辑等等。
另外需要注意的是 mixins 混入的钩子函数会先于组件内的钩子函数执行,并且在遇到同名选项的时候也会有选择性的进行合并,具体可以阅读 文档。
自定义指令
https://cn.vuejs.org/v2/guide/custom-directive.html
渲染函数jsx
https://cn.vuejs.org/v2/guide/render-function.html
插件
通过全局方法 Vue.use() 使用插件。它需要在你调用 new Vue() 启动应用之前完成
computed 和 watch 和methods区别
computed 是计算属性,依赖其他属性计算值,并且 computed 的值有缓存,只有当计算值变化才会返回内容。
watch 监听到值的变化就会执行回调,在回调中可以进行一些逻辑操作。
所以一般来说需要依赖别的属性来动态获得值的时候可以使用 computed,对于监听到值的变化需要做一些复杂业务逻辑的情况可以使用 watch。
另外 computed 和 watch 还都支持对象的写法,这种方式知道的人并不多。
vm.$watch('obj', {
// 深度遍历
deep: true,
// 立即触发
immediate: true,
// 执行的函数
handler: function(val, oldVal) {
}
})
var vm = new Vue({
data: {
a: 1 },
computed: {
aPlus: {
// this.aPlus 时触发
get: function () {
return this.a + 1
},
// this.aPlus = 1 时触发
set: function (v) {
this.a = v - 1
}
}
}
})
用 computed 属性方法编写的逻辑运算,在调用时直接将返回时 areas 视为一个变量值就可使用,无需进行函数调用。
computed 具有缓存功能,在系统刚运行的时候调用一次。只有只有当计算结果发生变化才会被调用。比如,我们在长度框与宽度框更改值的时候每次更改 computed 都会被调用一次,很浪费资源。
用 methods 方法编写的逻辑运算,在调用时 add() 一定要加“()”,methods 里面写的多位方法,调用方法一定要有()。
methods方法页面刚加载时调用一次,以后只有被调用的时候才会被调用。我们在长度框和宽度框的值输入完以后,点击“+” methods 方法调用一次。这里很明显我们采用 methods 会更节省资源。
keep-alive 组件有什么作用
如果你需要在组件切换的时候,保存一些组件的状态防止多次渲染,就可以使用 keep-alive 组件包裹需要保存的组件。
对于 keep-alive 组件来说,它拥有两个独有的生命周期钩子函数,分别为 activated 和 deactivated 。用 keep-alive 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 deactivated 钩子函数,命中缓存渲染后会执行 actived 钩子函数。
v-show 与 v-if 区别
v-show 只是在 display: none 和 display: block 之间切换。无论初始条件是什么都会被渲染出来,后面只需要切换 CSS,DOM 还是一直保留着的。所以总的来说 v-show 在初始渲染时有更高的开销,但是切换开销很小,更适合于频繁切换的场景。
v-if 的话就得说到 Vue 底层的编译了。当属性初始为 false 时,组件就不会被渲染,直到条件为 true,并且切换条件时会触发销毁/挂载组件,所以总的来说在切换时开销更高,更适合不经常切换的场景。
并且基于 v-if 的这种惰性渲染机制,可以在必要的时候才去渲染组件,减少整个页面的初始渲染开销。
组件中 data 什么时候可以使用对象
这道题目其实更多考的是 JS 功底。
组件复用时所有组件实例都会共享 data,如果 data 是对象的话,就会造成一个组件修改 data 以后会影响到其他所有组件,所以需要将 data 写成函数,每次用到就调用一次函数获得新的数据。
当我们使用 new Vue() 的方式的时候,无论我们将 data 设置为对象还是函数都是可以的,因为 new Vue() 的方式是生成一个根组件,该组件不会复用,也就不存在共享 data 的情况了。
小结
总的来说这一章节的内容更多的偏向于 Vue 的基础,下一章节我们将来了解一些原理性方面的知识。
18、Vue 常考进阶知识点
这一章节我们将来学习 Vue 的一些经常考到的进阶知识点。这些知识点相对而言理解起来会很有难度,可能需要多次阅读才能理解。
vue整体概括
初始化 Vue 实例
设置数据劫持(Object.defineProperty)
模板编译(compile)
渲染(render function)
转化为虚拟 DOM(Object)
对比新老虚拟DOM(patch、diff)
更新视图(真实 dom)
1、传入实例参数
当我们开始写 Vue 项目时,首先初始化一个 Vue 实例,传入一个对象参数,参数中包括一下几个重要属性:
1{
2 el: '#app',
3 data: {
4 student: {
5 name: '公众号',
6 age: 20,
7 }
8 }
9 computed:{
10 ...
11 }
12 ...
13}
-
el:将渲染好的 DOM 挂载到页面中(可以传入一个 id,也可以传入一个 dom 节点)。
-
data:页面所需要的数据(对象类型,至于为什么,会在数据劫持内容说明)。
-
computed:计算属性,随着 data 中的数据变化,来更新页面关联的计算属性。
-
methods:实例所用到的方法集合。
除此之外,还有一些生命周期钩子函数等其他内容。
***2、***设置数据劫持
所谓的数据劫持,当 Vue 实例上的 data 中的数据改变时,对应的视图所用到的 data 中数据也会在页面改变。所以我们需要给 data 中的所有数据设置一个监听器,监听 data 的改变和获取,一旦数据改变,监听器会触发,通知页面,要改变数据了。
1 Object.defineProperty(obj, key, {
2 get() {
3 return value;
4 },
5 set: newValue => {
6 console.log(---------------更新视图--------------------)
7 }
8 }
数据劫持的实现就是给每一个 data绑定 Object.defineProperty()。对于 Object.defineProperty()的用法,自己详细看 MDN ,这也是 MVVM的核心实现 API,下遍很多东西都是围绕着它转。
***3、***模板编译(compile)
拿到传入 dom 对象和 data 数据了,如果将这些 data 渲染到 HTML 所对应的 { {student.age}}、v-model=“student.name” 等标签中,这个过程就是模板编译的过程,主要解析模板中的指令、class、style等等数据。
1// 把当前节点放到内存中去(因为频繁渲染造成回流和重绘)
2let fragment = this.nodefragment(this.el);
3
4// 把节点在内存中替换(编译模板,数据编译)
5this.compile(fragment);
6
7// 把内容塞回页面
8this.el.appendChild(fragment);
我们通过 el 拿到 dom 对象,然后将这个当前的 dom 节点拿到内存中去,然后将数据和 dom 节点进行替换合并,然后再把结果塞会到页面中。下面会根据代码实现,具体展开分享。
***4、***虚拟 DOM(Virtual DOM)
所谓虚拟 DOM,其实就是一个 javascript对象,说白了就是对真实 DOM 的一个描述对象,和真实 dom做一个映射。
1// 真实 DOM
2
3 HelloWord
4
5
6
7// 虚拟 DOM —— 以上的真实 DOM 被虚拟 DOM 表示如下:
8{
9 children:(1) [{…}] // 子元素
10 domElement: div // 对应的真实 dom
11 key: undefined // key 值
12 props: {} // 标签对应的属性
13 text: undefined // 文本内容
14 type: "div" // 节点类型
15 ...
16}
一旦页面数据有变化,我们不直接操作更新真实 DOM,而是更新虚拟 DOM,又因为虚拟 DOM和真实 DOM有映射关系,所有真实 DOM也被简洁更新,避免了回流和重绘造成性能上的损失。
对于虚拟 DOM,主要核心涉及到 diff算法,新老虚拟结点如何检查差异的,然后又是如何进行更新的,后边会展开一点点讲。
***5、***对比新老虚拟 DOM(patch)
patch 主要是对更新后的新节点和更新前的节点进行比对,比对的核心算法就是 diff 算法,比如新节点的属性值不同,新节点又增加了一个子元素等变化,都需要通过这个过程,将最后新的虚拟 DOM 更新到视图上,呈现最新的变化,这个过程是一个核心部分,面试也是经常问到的。
***6、***更新视图(update view)
当第一次加载 Vue 实例的时候,我们将渲染好的数据挂载到页面中。当我们已经将实例挂载到了真实 dom 上,我们更新数据时,新老节点对比完成,拿到对比的最新数据状态,然后更新到视图上去。
Vue 2.0 的数据依赖实现原理简析
以上就是在Vue实例初始化的过程中实现依赖管理的分析。大致的总结下就是:
initState的过程中,将props,computed,data等属性通过Object.defineProperty来改造其getter/setter属性,并为每一个响应式属性实例化一个observer观察者。这个observer内部dep记录了这个响应式属性的所有依赖。- 当响应式属性调用
setter函数时,通过dep.notify()方法去遍历所有的依赖,调用watcher.update()去完成数据的动态响应。
这篇文章主要从初始化的数据
首先让我们从最简单的一个实例Vue入手:
const app = new Vue({
// options 传入一个选项obj.这个obj即对于这个vue实例的初始化
})
通过查阅文档,我们可以知道这个options可以接受:
- 选项/数据
- data
- props
- propsData(方便测试使用)
- computed
- methods
- watch
- 选项 / DOM
- 选项 / 生命周期钩子
- 选项 / 资源
- 选项 / 杂项
具体未展开的内容请自行查阅相关文档,接下来让我们来看看传入的选项/数据是如何管理数据之间的相互依赖的。
const app = new Vue({
el: '#app',
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
},
data: {
msg1: 'Hello world!',
arr: {
arr1: 1
}
},
watch: {
a (newVal, oldVal) {
console.log(newVal, oldVal)
}
},
methods: {
go () {
console.log('This is simple demo')
}
}
})
我们使用Vue这个构造函数去实例化了一个vue实例app。传入了props, data, watch, methods等属性。在实例化的过程中,Vue提供的构造函数就使用我们传入的options去完成数据的依赖管理,初始化的过程只有一次,但是在你自己的程序当中,数据的依赖管理的次数不止一次。
那Vue的构造函数到底是怎么实现的呢?Vue
// 构造函数
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}
// 对Vue这个class进行mixin,即在原型上添加方法
// Vue.prototype.* = function () {}
initMixin(Vue)
stateMixin(Vue)
eventsMixin(Vue)
lifecycleMixin(Vue)
renderMixin(Vue)
当我们调用new Vue的时候,事实上就调用的Vue原型上的_init方法.
// 原型上提供_init方法,新建一个vue实例并传入options参数
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// a uid
vm._uid = uid++
let startTag, endTag
// a flag to avoid this being observed
vm._isVue = true
// merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
// 将传入的这些options选项挂载到vm.$options属性上
vm.$options = mergeOptions(
// components/filter/directive
resolveConstructorOptions(vm.constructor),
// this._init()传入的options
options || {},
vm
)
}
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm)
} else {
vm._renderProxy = vm
}
// expose real self
vm._self = vm // 自身的实例
// 接下来所有的操作都是在这个实例上添加方法
initLifecycle(vm) // lifecycle初始化
initEvents(vm) // events初始化 vm._events, 主要是提供vm实例上的$on/$emit/$off/$off等方法
initRender(vm) // 初始化渲染函数,在vm上绑定$createElement方法
callHook(vm, 'beforeCreate') // 钩子函数的执行, beforeCreate
initInjections(vm) // resolve injections before data/props
initState(vm) // Observe data添加对data的监听, 将data转化为getters/setters
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created') // 钩子函数的执行, created
// vm挂载的根元素
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}
其中在this._init()方法中调用initState(vm),完成对vm这个实例的数据的监听,也是本文所要展开说的具体内容。
export function initState (vm: Component) {
// 首先在vm上初始化一个_watchers数组,缓存这个vm上的所有watcher
vm._watchers = []
// 获取options,包括在new Vue传入的,同时还包括了Vue所继承的options
const opts = vm.$options
// 初始化props属性
if (opts.props) initProps(vm, opts.props)
// 初始化methods属性
if (opts.methods) initMethods(vm, opts.methods)
// 初始化data属性
if (opts.data) {
initData(vm)
} else {
observe(vm._data = {}, true /* asRootData */)
}
// 初始化computed属性
if (opts.computed) initComputed(vm, opts.computed)
// 初始化watch属性
if (opts.watch) initWatch(vm, opts.watch)
}
initProps
我们在实例化app的时候,在构造函数里面传入的options中有props属性:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
}
function initProps (vm: Component, propsOptions: Object) {
// propsData主要是为了方便测试使用
const propsData = vm.$options.propsData || {}
// 新建vm._props对象,可以通过app实例去访问
const props = vm._props = {}
// cache prop keys so that future props updates can iterate using Array
// instead of dynamic object key enumeration.
// 缓存的prop key
const keys = vm.$options._propKeys = []
const isRoot = !vm.$parent
// root instance props should be converted
observerState.shouldConvert = isRoot
for (const key in propsOptions) {
// this._init传入的options中的props属性
keys.push(key)
// 注意这个validateProp方法,不仅完成了prop属性类型验证的,同时将prop的值都转化为了getter/setter,并返回一个observer
const value = validateProp(key, propsOptions, propsData, vm)
// 将这个key对应的值转化为getter/setter
defineReactive(props, key, value)
// static props are already proxied on the component's prototype
// during Vue.extend(). We only need to proxy props defined at
// instantiation here.
// 如果在vm这个实例上没有key属性,那么就通过proxy转化为proxyGetter/proxySetter, 并挂载到vm实例上,可以通过app._props[key]这种形式去访问
if (!(key in vm)) {
proxy(vm, `_props`, key)
}
}
observerState.shouldConvert = true
}
接下来看下validateProp(key, propsOptions, propsData, vm)方法内部到底发生了什么。
export function validateProp (
key: string,
propOptions: Object, // $options.props属性
propsData: Object, // $options.propsData属性
vm?: Component
): any {
const prop = propOptions[key]
// 如果在propsData测试props上没有缓存的key
const absent = !hasOwn(propsData, key)
let value = propsData[key]
// 处理boolean类型的数据
// handle boolean props
if (isType(Boolean, prop.type)) {
if (absent && !hasOwn(prop, 'default')) {
value = false
} else if (!isType(String, prop.type) && (value === '' || value === hyphenate(key))) {
value = true
}
}
// check default value
if (value === undefined) {
// default属性值,是基本类型还是function
// getPropsDefaultValue见下面第一段代码
value = getPropDefaultValue(vm, prop, key)
// since the default value is a fresh copy,
// make sure to observe it.
const prevShouldConvert = observerState.shouldConvert
observerState.shouldConvert = true
// 将value的所有属性转化为getter/setter形式
// 并添加value的依赖
// observe方法的分析见下面第二段代码
observe(value)
observerState.shouldConvert = prevShouldConvert
}
if (process.env.NODE_ENV !== 'production') {
assertProp(prop, key, value, vm, absent)
}
return value
}
// 获取prop的默认值
function getPropDefaultValue (vm: ?Component, prop: PropOptions, key: string): any {
// no default, return undefined
// 如果没有default属性的话,那么就返回undefined
if (!hasOwn(prop, 'default')) {
return undefined
}
const def = prop.default
// the raw prop value was also undefined from previous render,
// return previous default value to avoid unnecessary watcher trigger
if (vm && vm.$options.propsData &&
vm.$options.propsData[key] === undefined &&
vm._props[key] !== undefined) {
return vm._props[key]
}
// call factory function for non-Function types
// a value is Function if its prototype is function even across different execution context
// 如果是function 则调用def.call(vm)
// 否则就返回default属性对应的值
return typeof def === 'function' && getType(prop.type) !== 'Function'
? def.call(vm)
: def
}
Vue提供了一个observe方法,在其内部实例化了一个Observer类,并返回Observer的实例。每一个Observer实例对应记录了props中这个的default value的所有依赖(仅限object类型),这个Observer实际上就是一个观察者,它维护了一个数组this.subs = []用以收集相关的subs(订阅者)(即这个观察者的依赖)。通过将default value转化为getter/setter形式,同时添加一个自定义__ob__属性,这个属性就对应Observer实例。
说起来有点绕,还是让我们看看我们给的demo里传入的options配置:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
}
在往上数的第二段代码里面的方法obervse(value),即对{key1: 'a', key2: {a: 'b'}}进行依赖的管理,同时将这个obj所有的属性值都转化为getter/setter形式。此外,Vue还会将props属性都代理到vm实例上,通过vm.a就可以访问到这个属性。
此外,还需要了解下在Vue中管理依赖的一个非常重要的类: Dep
export default class Dep {
constructor () {
this.id = uid++
this.subs = []
}
addSub () {...} // 添加订阅者(依赖)
removeSub () {...} // 删除订阅者(依赖)
depend () {...} // 检查当前Dep.target是否存在以及判断这个watcher已经被添加到了相应的依赖当中,如果没有则添加订阅者(依赖),如果已经被添加了那么就不做处理
notify () {...} // 通知订阅者(依赖)更新
}
在Vue的整个生命周期当中,你所定义的响应式的数据上都会绑定一个Dep实例去管理其依赖。它实际上就是观察者和订阅者联系的一个桥梁。
刚才谈到了对于依赖的管理,它的核心之一就是观察者Observer这个类:
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that has this object as root $data
constructor (value: any) {
this.value = value
// dep记录了和这个value值的相关依赖
this.dep = new Dep()
this.vmCount = 0
// value其实就是vm._data, 即在vm._data上添加__ob__属性
def(value, '__ob__', this)
// 如果是数组
if (Array.isArray(value)) {
// 首先判断是否能使用__proto__属性
const augment = hasProto
? protoAugment
: copyAugment
augment(value, arrayMethods, arrayKeys)
// 遍历数组,并将obj类型的属性改为getter/setter实现
this.observeArray(value)
} else {
// 遍历obj上的属性,将每个属性改为getter/setter实现
this.walk(value)
}
}
/**
* Walk through each property and convert them into
* getter/setters. This method should only be called when
* value type is Object.
*/
// 将每个property对应的属性都转化为getter/setters,只能是当这个value的类型为Object时
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}
/**
* Observe a list of Array items.
*/
// 监听array中的item
observeArray (items: Array) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}
walk方法里面调用defineReactive方法:通过遍历这个object的key,并将对应的value转化为getter/setter形式,通过闭包维护一个dep,在getter方法当中定义了这个key是如何进行依赖的收集,在setter方法中定义了当这个key对应的值改变后,如何完成相关依赖数据的更新。但是从源码当中,我们却发现当getter函数被调用的时候并非就一定会完成依赖的收集,其中还有一层判断,就是Dep.target是否存在。
/**
* Define a reactive property on an Object.
*/
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: Function
) {
// 每个属性新建一个dep实例,管理这个属性的依赖
const dep = new Dep()
// 或者属性描述符
const property = Object.getOwnPropertyDescriptor(obj, key)
// 如果这个属性是不可配的,即无法更改
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
// 递归去将val转化为getter/setter
// childOb将子属性也转化为Observer
let childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
// 定义getter -->> reactiveGetter
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
// 定义相应的依赖
if (Dep.target) {
// Dep.target.addDep(this)
// 即添加watch函数
// dep.depend()及调用了dep.addSub()只不过中间需要判断是否这个id的dep已经被包含在内了
dep.depend()
// childOb也添加依赖
if (childOb) {
childOb.dep.depend()
}
if (Array.isArray(value)) {
dependArray(value)
}
}
return value
},
// 定义setter -->> reactiveSetter
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
// 对得到的新值进行observe
childOb = observe(newVal)
// 相应的依赖进行更新
dep.notify()
}
})
}
在上文中提到了Dep类是链接观察者和订阅者的桥梁。同时在Dep的实现当中还有一个非常重要的属性就是Dep.target,它事实就上就是一个订阅者,只有当Dep.target(订阅者)存在的时候,调用属性的getter函数的时候才能完成依赖的收集工作。
Dep.target = null
const targetStack = []
export function pushTarget (_target: Watcher) {
if (Dep.target) targetStack.push(Dep.target)
Dep.target = _target
}
export function popTarget () {
Dep.target = targetStack.pop()
}
那么Vue是如何来实现订阅者的呢?Vue里面定义了一个类: Watcher,在Vue的整个生命周期当中,会有4类地方会实例化Watcher:
Vue实例化的过程中有watch选项Vue实例化的过程中有computed计算属性选项Vue原型上有挂载$watch方法: Vue.prototype. w a t c h , 可 以 直 接 通 过 实 例 调 用 ‘ t h i s . watch,可以直接通过实例调用`this. watch,可以直接通过实例调用‘this.watch`方法Vue生成了render函数,更新视图时
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: Object
) {
// 缓存这个实例vm
this.vm = vm
// vm实例中的_watchers中添加这个watcher
vm._watchers.push(this)
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
....
// parse expression for getter
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = function () {}
}
}
// 通过get方法去获取最新的值
// 如果lazy为true, 初始化的时候为undefined
this.value = this.lazy
? undefined
: this.get()
}
get () {...}
addDep () {...}
update () {...}
run () {...}
evaluate () {...}
run () {...}
Watcher接收的参数当中expOrFn定义了用以获取watcher的getter函数。expOrFn可以有2种类型:string或function.若为string类型,首先会通过parsePath方法去对string进行分割(仅支持.号形式的对象访问)。在除了computed选项外,其他几种实例化watcher的方式都是在实例化过程中完成求值及依赖的收集工作:this.value = this.lazy ? undefined : this.get().在Watcher的get方法中:
!!!前方高能
get () {
// pushTarget即设置当前的需要被执行的watcher
pushTarget(this)
let value
const vm = this.vm
if (this.user) {
try {
// $watch(function () {})
// 调用this.getter的时候,触发了属性的getter函数
// 在getter中进行了依赖的管理
value = this.getter.call(vm, vm)
console.log(value)
} catch (e) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
}
} else {
// 如果是新建模板函数,则会动态计算模板与data中绑定的变量,这个时候就调用了getter函数,那么就完成了dep的收集
// 调用getter函数,则同时会调用函数内部的getter的函数,进行dep收集工作
value = this.getter.call(vm, vm)
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
// 让每个属性都被作为dependencies而tracked, 这样是为了deep watching
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps()
return value
}
一进入get方法,首先进行pushTarget(this)的操作,此时Vue当中Dep.target = 当前这个watcher,接下来进行value = this.getter.call(vm, vm)操作,在这个操作中就完成了依赖的收集工作。还是拿文章一开始的demo来说,在vue实例化的时候传入了watch选项:
props: {
a: {
type: Object,
default () {
return {
key1: 'a',
key2: {
a: 'b'
}
}
}
}
},
watch: {
a (newVal, oldVal) {
console.log(newVal, oldVal)
}
},
在Vue的initState()开始执行后,首先会初始化props的属性为getter/setter函数,然后在进行initWatch初始化的时候,这个时候初始化watcher实例,并调用get()方法,设置Dep.target = 当前这个watcher实例,进而到value = this.getter.call(vm, vm)的操作。在调用this.getter.call(vm, vm)的方法中,便会访问props选项中的a属性即其getter函数。在a属性的getter函数执行过程中,因为Dep.target已经存在,那么就进入了依赖收集的过程:
if (Dep.target) {
// Dep.target.addDep(this)
// 即添加watch函数
// dep.depend()及调用了dep.addSub()只不过中间需要判断是否这个id的dep已经被包含在内了
dep.depend()
// childOb也添加依赖
if (childOb) {
childOb.dep.depend()
}
if (Array.isArray(value)) {
dependArray(value)
}
}
dep是一开始初始化的过程中,这个属性上的dep属性。调用dep.depend()函数:
depend () {
if (Dep.target) {
// Dep.target为一个watcher
Dep.target.addDep(this)
}
}
Dep.target也就刚才的那个watcher实例,这里也就相当于调用了watcher实例的addDep方法: watcher.addDep(this),并将dep观察者传入。在addDep方法中完成依赖收集:
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
这个时候依赖完成了收集,当你去修改a属性的值时,会调用a属性的setter函数,里面会执行dep.notify(),它会遍历所有的订阅者,然后调用订阅者上的update函数。
initData过程和initProps类似,具体可参见源码。
initComputed
以上就是在initProps过程中Vue是如何进行依赖收集的,initData的过程和initProps类似,下来再来看看initComputed的过程. 在computed属性初始化的过程当中,会为每个属性实例化一个watcher:
const computedWatcherOptions = { lazy: true }
function initComputed (vm: Component, computed: Object) {
// 新建_computedWatchers属性
const watchers = vm._computedWatchers = Object.create(null)
for (const key in computed) {
const userDef = computed[key]
// 如果computed为funtion,即取这个function为getter函数
// 如果computed为非function.则可以单独为这个属性定义getter/setter属性
let getter = typeof userDef === 'function' ? userDef : userDef.get
// create internal watcher for the computed property.
// lazy属性为true
// 注意这个地方传入的getter参数
// 实例化的过程当中不去完成依赖的收集工作
watchers[key] = new Watcher(vm, getter, noop, computedWatcherOptions)
// component-defined computed properties are already defined on the
// component prototype. We only need to define computed properties defined
// at instantiation here.
if (!(key in vm)) {
defineComputed(vm, key, userDef)
}
}
}
但是这个watcher在实例化的过程中,由于传入了{lazy: true}的配置选项,那么一开始是不会进行求值与依赖收集的: this.value = this.lazy ? undefined : this.get().在initComputed的过程中,Vue会将computed属性定义到vm实例上,同时将这个属性定义为getter/setter。当你访问computed属性的时候调用getter函数:
function createComputedGetter (key) {
return function computedGetter () {
const watcher = this._computedWatchers && this._computedWatchers[key]
if (watcher) {
// 是否需要重新计算
if (watcher.dirty) {
watcher.evaluate()
}
// 管理依赖
if (Dep.target) {
watcher.depend()
}
return watcher.value
}
}
}
在watcher存在的情况下,首先判断watcher.dirty属性,这个属性主要是用于判断这个computed属性是否需要重新求值,因为在上一轮的依赖收集的过程当中,观察者已经将这个watcher添加到依赖数组当中了,如果观察者发生了变化,就会dep.notify(),通知所有的watcher,而对于computed的watcher接收到变化的请求后,会将watcher.dirty = true即表明观察者发生了变化,当再次调用computed属性的getter函数的时候便会重新计算,否则还是使用之前缓存的值。
initWatch
initWatch的过程中其实就是实例化new Watcher完成观察者的依赖收集的过程,在内部的实现当中是调用了原型上的Vue.prototype.$watch方法。这个方法也适用于vm实例,即在vm实例内部调用this.$watch方法去实例化watcher,完成依赖的收集,同时监听expOrFn的变化。
总结:
以上就是在Vue实例初始化的过程中实现依赖管理的分析。大致的总结下就是:
initState的过程中,将props,computed,data等属性通过Object.defineProperty来改造其getter/setter属性,并为每一个响应式属性实例化一个observer观察者。这个observer内部dep记录了这个响应式属性的所有依赖。- 当响应式属性调用
setter函数时,通过dep.notify()方法去遍历所有的依赖,调用watcher.update()去完成数据的动态响应。
这篇文章主要从初始化的数据层面上分析了Vue是如何管理依赖来到达数据的动态响应。下一篇文章来分析下Vue中模板中的指令和响应式数据是如何关联来实现由数据驱动视图,以及数据是如何响应视图变化的。
#深入阅读Vue.js源码
diff
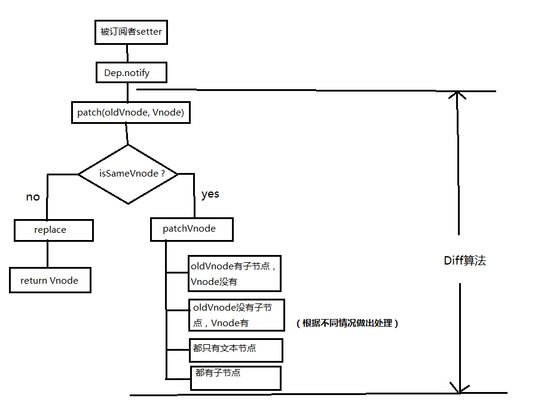
1、patch (oldVnode, vnode)
函数接收两个参数 oldVnode 和 Vnode 分别代表新的节点和之前的旧节点
如果两个节点都是一样的,那么就执行 patchVnode深入检查他们的子节点。如果两个节点不一样那就说明 Vnode 完全被改变了,就可以直接替换 oldVnode 。
1、patchVnode(oldVnode, vnode)([src/core/vdom/patch.js]
:更新真实dom节点的data属性,相当于对dom节点进行了预处理的操作
这其中的diff过程中又分了好几种情况
- 首先进行文本节点的判断,若新老dom节点文本不同,那么就会直接进行文本节点的替换;
- 在新dom节点情况下,进入子节点的
diff; - 当老子节点和新子节点都存在且不相同的情况下,调用
updateChildren对子节点进行diff; - 若老子节点不存在,新子节点存在,先清空老节点的文本节点,同时调用
addVnodes方法将新子节点添加到elm真实dom节点当中; - 若老子节点存在,新子节点不存在,则删除
elm真实节点下的老子节点; - 若老节点有文本节点,而新节点没有,就清空这个文本节点。
2、updateChildren( parentElm, oldCh, newCh) 最重要的环节:
会将新老DOM节点提取出来首先给老子节点和新子节点
分别分配一个startIndex和endIndex来作为遍历的索引,
当老子节点或者新子节点遍历完后
(遍历完的条件就是老子节点或者新子节点的startIndex >= endIndex),
就停止老子节点和新子节点的diff过程。
接下来通过实例来看下整个diff的过程(节点属性中不带key的情况):
-
首先从第一个节点开始比较,不管是老子节点还是新子节点的起始或者终止节点都不存在
sameVnode,同时节点属性中是不带key标记的,因此第一轮的diff完后,新子节点的startVnode被添加到oldStartVnode的前面,同时新节点起始索引+1;function` `sameVnode (a, b) { ``return` `( ``a.key === b.key && ``// key值 ``a.tag === b.tag && ``// 标签名 ``a.isComment === b.isComment && ``// 是否为注释节点 ``// 是否都定义了data,data包含一些具体信息,例如onclick , style ``isDef(a.data) === isDef(b.data) && ``sameInputType(a, b) ``// 当标签是的时候,type必须相同 ``) }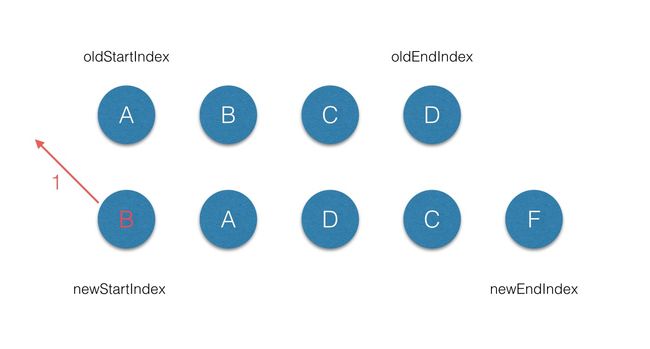
(https://user-images.githubusercontent.com/9695264/27948439-63c3fb00-632c-11e7-95ae-425fac8ffc81.jpeg)
-
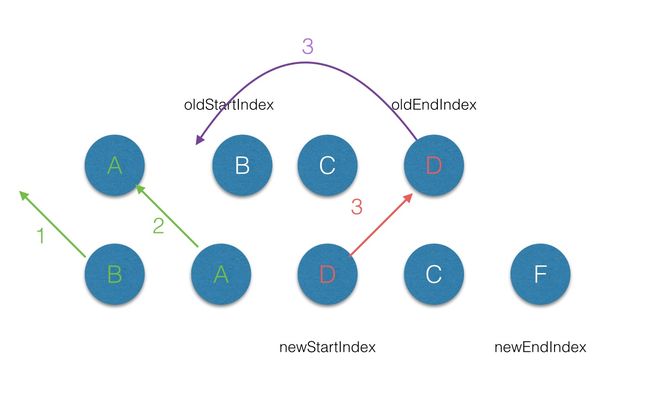
第二轮的
diff中,满足sameVnode(oldStartVnode, newStartVnode),因此对这2个
vnode进行diff,最后将
patch标记的差异反应到当前比较的老节点上同时
oldStartVnode和newStartIndex+1位

(https://user-images.githubusercontent.com/9695264/27948452-6c0acbf4-632c-11e7-85a9-d5cc9585d051.jpeg)
-
第三轮的
diff中,满足sameVnode(最后位置老节点, 当前比较位置新节点),那么首先对
oldEndVnode和newStartVnode进行diff,并对
oldEndVnode进行patch,并完成
oldEndVnode移位的操作,最后newStartIndex+1,oldStartVnode后移一位;
[
(https://user-images.githubusercontent.com/9695264/27948460-73c6d6da-632c-11e7-88f4-2887c72e740f.jpeg)
-
遍历的过程结束后,
newStartIndex > newEndIndex,说明此时老子节点存在多余的节点,那么最后就需要将这些多余的节点删除。
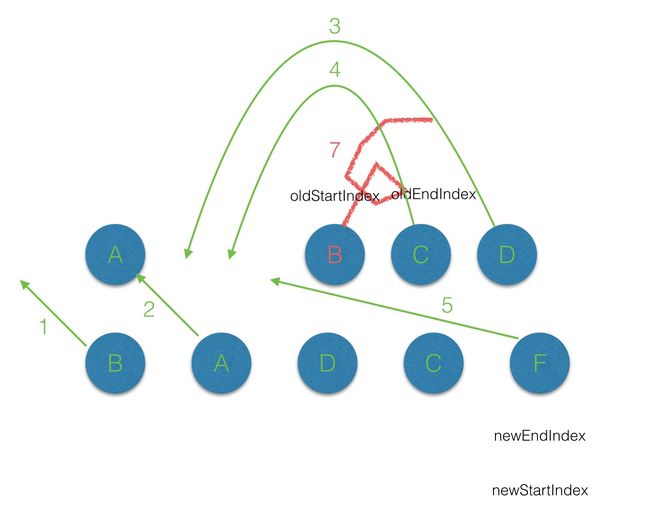
在vnode不带key的情况下,
每一轮的diff过程当中都是起始和结束节点进行比较,直到oldCh或者newCh被遍历完。
而当为vnode引入key属性后,在每一轮的diff过程中,
当起始和结束节点都没有找到sameVnode时,首先对oldCh中进行key值与索引的映射:
3、createKeyToOldIdx方法 key
用以将老子节点作为键,而对应的节点的索引作为值。然后再判断在newStartVnode的属性中是否有key,且是否在oldKeyToIndx中找到对应的节点。
-
如果不存在这个
key,那么就将这个newStartVnode作为新的节点创建且插入到原有的root的子节点前面: -
如果存在这个
key,// 将找到的key一致的oldVnode再和newStartVnode,然后再进行
diff的过程:通过以上分析,给
vdom上添加key属性后,遍历diff的过程中,当起始点,结束点的搜寻及diff出现还是无法匹配的情况下时,就会用key来作为唯一标识,来进行diff,这样就可以提高diff效率。
注意在第一轮的diff过后oldCh上的B节点被删除了,但是newCh上的B节点上elm属性保持对oldCh上B节点的elm引用。
Vue 双向绑定原理分析
当我们学习angular或者vue的时候,其双向绑定为我们开发带来了诸多便捷,今天我们就来分析一下vue双向绑定的原理。
首先我们为每个vue属性用Object.defineProperty()实现数据劫持,为每个属性分配一个订阅者集合的管理数组dep;然后在编译的时候在该属性的数组dep中添加订阅者,v-model会添加一个订阅者,{ {}}也会,v-bind也会,只要用到该属性的指令理论上都会,接着为input会添加监听事件,修改值就会为该属性赋值,触发该属性的set方法,在set方法内通知订阅者数组dep,订阅者数组循环调用各订阅者的update方法更新视图。
1.vue双向绑定原理
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。我们先来看Object.defineProperty()这个方法:
var obj = {};
Object.defineProperty(obj, 'name', {
get: function() {
console.log('我被获取了')
return val;
},
set: function (newVal) {
console.log('我被设置了')
}
})
obj.name = 'fei';//在给obj设置name属性的时候,触发了set这个方法
var val = obj.name;//在得到obj的name属性,会触发get方法
已经了解到vue是通过数据劫持的方式来做数据绑定的,其中最核心的方法便是通过Object.defineProperty()来实现对属性的劫持,那么在设置或者获取的时候我们就可以在get或者set方法里加入其他的触发函数,达到监听数据变动的目的,无疑这个方法是本文中最重要、最基础的内容之一。
2.实现最简单的双向绑定
我们知道通过Object.defineProperty()可以实现数据劫持,使得属性在赋值的时候触发set方法,
Document
当然要是这么粗暴,肯定不行,性能会出很多的问题。
3.讲解vue如何实现
先看原理图
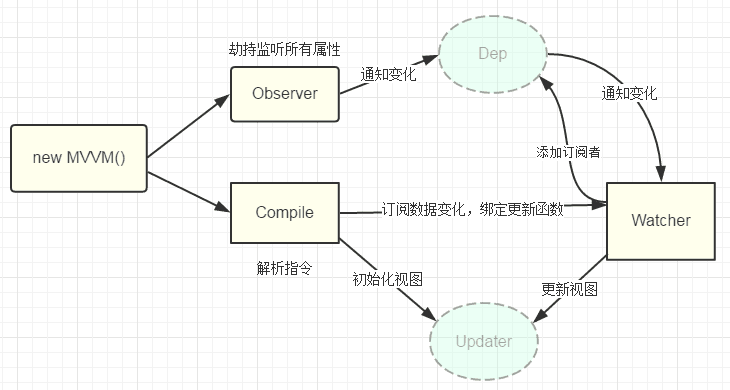
3.1 observer用来实现对每个vue中的data中定义的属性循环用Object.defineProperty()实现数据劫持,以便利用其中的setter和getter,然后通知订阅者,订阅者会触发它的update方法,对视图进行更新。
3.2 我们介绍为什么要订阅者,在vue中v-model,v-name,{ {}}等都可以对数据进行显示,也就是说假如一个属性都通过这三个指令了,那么每当这个属性改变的时候,相应的这个三个指令的html视图也必须改变,于是vue中就是每当有这样的可能用到双向绑定的指令,就在一个Dep中增加一个订阅者,其订阅者只是更新自己的指令对应的数据,也就是v-model='name’和{ {name}}有两个对应的订阅者,各自管理自己的地方。每当属性的set方法触发,就循环更新Dep中的订阅者。
4.vue代码实现
4.1 observer实现,主要是给每个vue的属性用Object.defineProperty(),代码如下:
function defineReactive (obj, key, val) {
var dep = new Dep();
Object.defineProperty(obj, key, {
get: function() {
//添加订阅者watcher到主题对象Dep
if(Dep.target) {
// JS的浏览器单线程特性,保证这个全局变量在同一时间内,只会有同一个监听器使用
dep.addSub(Dep.target);
}
return val;
},
set: function (newVal) {
if(newVal === val) return;
val = newVal;
console.log(val);
// 作为发布者发出通知
dep.notify();//通知后dep会循环调用各自的update方法更新视图
}
})
}
function observe(obj, vm) {
Object.keys(obj).forEach(function(key) {
defineReactive(vm, key, obj[key]);
})
}
4.2实现compile:
compile的目的就是解析各种指令成真正的html。
function Compile(node, vm) {
if(node) {
this.$frag = this.nodeToFragment(node, vm);
return this.$frag;
}
}
Compile.prototype = {
nodeToFragment: function(node, vm) {
var self = this;
var frag = document.createDocumentFragment();
var child;
while(child = node.firstChild) {
console.log([child])
self.compileElement(child, vm);
frag.append(child); // 将所有子节点添加到fragment中
}
return frag;
},
compileElement: function(node, vm) {
var reg = /\{\{(.*)\}\}/;
//节点类型为元素(input元素这里)
if(node.nodeType === 1) {
var attr = node.attributes;
// 解析属性
for(var i = 0; i < attr.length; i++ ) {
if(attr[i].nodeName == 'v-model') {//遍历属性节点找到v-model的属性
var name = attr[i].nodeValue; // 获取v-model绑定的属性名
node.addEventListener('input', function(e) {
// 给相应的data属性赋值,进而触发该属性的set方法
vm[name]= e.target.value;
});
new Watcher(vm, node, name, 'value');//创建新的watcher,会触发函数向对应属性的dep数组中添加订阅者,
}
};
}
//节点类型为text
if(node.nodeType === 3) {
if(reg.test(node.nodeValue)) {
var name = RegExp.$1; // 获取匹配到的字符串
name = name.trim();
new Watcher(vm, node, name, 'nodeValue');
}
}
}
}
4.3 watcher实现
function Watcher(vm, node, name, type) {
Dep.target = this;
this.name = name;
this.node = node;
this.vm = vm;
this.type = type;
this.update();
Dep.target = null;
}
Watcher.prototype = {
update: function() {
this.get();
this.node[this.type] = this.value; // 订阅者执行相应操作
},
// 获取data的属性值
get: function() {
console.log(1)
this.value = this.vm[this.name]; //触发相应属性的get
}
}
4.4 实现Dep来为每个属性添加订阅者
function Dep() {
this.subs = [];
}
Dep.prototype = {
addSub: function(sub) {
this.subs.push(sub);
},
notify: function() {
this.subs.forEach(function(sub) {
sub.update();
})
}
}
这样一来整个数据的双向绑定就完成了。
5.梳理
首先我们为每个vue属性用Object.defineProperty()实现数据劫持,为每个属性分配一个订阅者集合的管理数组dep;然后在编译的时候在该属性的数组dep中添加订阅者,v-model会添加一个订阅者,{ {}}也会,v-bind也会,只要用到该属性的指令理论上都会,接着为input会添加监听事件,修改值就会为该属性赋值,触发该属性的set方法,在set方法内通知订阅者数组dep,订阅者数组循环调用各订阅者的update方法更新视图。
编译过程
想必大家在使用 Vue 开发的过程中,基本都是使用模板的方式。那么你有过「模板是怎么在浏览器中运行的」这种疑虑嘛?
首先直接把模板丢到浏览器中肯定是不能运行的,模板只是为了方便开发者进行开发。Vue 会通过编译器将模板通过几个阶段最终编译为 render 函数,然后通过执行 render 函数生成 Virtual DOM 最终映射为真实 DOM。
接下来我们就来学习这个编译的过程,了解这个过程中大概发生了什么事情。这个过程其中又分为三个阶段,分别为:
- 将模板解析为 AST
- 优化 AST
- 将 AST 转换为
render函数
在第一个阶段中,最主要的事情还是通过各种各样的正则表达式去匹配模板中的内容,然后将内容提取出来做各种逻辑操作,接下来会生成一个最基本的 AST 对象
{
// 类型
type: 1,
// 标签
tag,
// 属性列表
attrsList: attrs,
// 属性映射
attrsMap: makeAttrsMap(attrs),
// 父节点
parent,
// 子节点
children: []
}
然后会根据这个最基本的 AST 对象中的属性,进一步扩展 AST。
当然在这一阶段中,还会进行其他的一些判断逻辑。比如说对比前后开闭标签是否一致,判断根组件是否只存在一个,判断是否符合 HTML5 Content Model 规范等等问题。
接下来就是优化 AST 的阶段。在当前版本下,Vue 进行的优化内容其实还是不多的。只是对节点进行了静态内容提取,也就是将永远不会变动的节点提取了出来,实现复用 Virtual DOM,跳过对比算法的功能。在下一个大版本中,Vue 会在优化 AST 的阶段继续发力,实现更多的优化功能,尽可能的在编译阶段压榨更多的性能,比如说提取静态的属性等等优化行为。
最后一个阶段就是通过 AST 生成 render 函数了。其实这一阶段虽然分支有很多,但是最主要的目的就是遍历整个 AST,根据不同的条件生成不同的代码罢了。
NextTick 原理分析
nextTick 可以让我们在下次 DOM 更新循环结束之后执行延迟回调,用于获得更新后的 DOM。
在 Vue 2.4 之前都是使用的 microtasks,但是 microtasks 的优先级过高,在某些情况下可能会出现比事件冒泡更快的情况,但如果都使用 macrotasks 又可能会出现渲染的性能问题。所以在新版本中,会默认使用 microtasks,但在特殊情况下会使用 macrotasks,比如 v-on。
对于实现 macrotasks ,会先判断是否能使用 setImmediate ,不能的话降级为 MessageChannel ,以上都不行的话就使用 setTimeout
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (
typeof MessageChannel !== 'undefined' &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]')
) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
以上代码很简单,就是判断能不能使用相应的 API。
小结
以上就是 Vue 的几个高频核心问题了,如果你还想了解更多的源码相关的细节,强烈推荐黄老师的 Vue 技术揭秘。
19、React 常考基础知识点
这一章节我们将来学习 React 的一些经常考到的基础知识点。
React的特点和优势
- 虚拟DOM
我们以前操作dom的方式是通过document.getElementById()的方式,这样的过程实际上是先去读取html的dom结构,将结构转换成变量,再进行操作
而reactjs定义了一套变量形式的dom模型,一切操作和换算直接在变量中,这样减少了操作真实dom,性能真实相当的高,和主流MVC框架有本质的区别,并不和dom打交道
- 组件系统
react最核心的思想是将页面中任何一个区域或者元素都可以看做一个组件 component
那么什么是组件呢?
组件指的就是同时包含了html、css、js、image元素的聚合体
使用react开发的核心就是将页面拆分成若干个组件,并且react一个组件中同时耦合了css、js、image,这种模式整个颠覆了过去的传统的方式
- 单向数据流
其实reactjs的核心内容就是数据绑定,所谓数据绑定指的是只要将一些服务端的数据和前端页面绑定好,开发者只关注实现业务就行了
- JSX 语法
在vue中,我们使用render函数来构建组件的dom结构性能较高,因为省去了查找和编译模板的过程,但是在render中利用createElement创建结构的时候代码可读性较低,较为复杂,此时可以利用jsx语法来在render中创建dom,解决这个问题,但是前提是需要使用工具来编译jsx
生命周期
在 V16 版本中引入了 Fiber 机制。这个机制一定程度上的影响了部分生命周期的调用,并且也引入了新的 2 个 API 来解决问题,关于 Fiber 的内容将会在下一章节中讲到。
在之前的版本中,如果你拥有一个很复杂的复合组件,然后改动了最上层组件的 state,那么调用栈可能会很长
调用栈过长,再加上中间进行了复杂的操作,就可能导致长时间阻塞主线程,带来不好的用户体验。Fiber 就是为了解决该问题而生。
Fiber 本质上是一个虚拟的堆栈帧,新的调度器会按照优先级自由调度这些帧,从而将之前的同步渲染改成了异步渲染,在不影响体验的情况下去分段计算更新。
对于如何区别优先级,React 有自己的一套逻辑。对于动画这种实时性很高的东西,也就是 16 ms 必须渲染一次保证不卡顿的情况下,React 会每 16 ms(以内) 暂停一下更新,返回来继续渲染动画。
对于异步渲染,现在渲染有两个阶段:reconciliation 和 commit 。前者过程是可以打断的,后者不能暂停,会一直更新界面直到完成。
Reconciliation 阶段
componentWillMountcomponentWillReceivePropsshouldComponentUpdatecomponentWillUpdate
Commit 阶段
componentDidMountcomponentDidUpdatecomponentWillUnmount
因为 Reconciliation 阶段是可以被打断的,所以 Reconciliation 阶段会执行的生命周期函数就可能会出现调用多次的情况,从而引起 Bug。由此对于 Reconciliation 阶段调用的几个函数,除了 shouldComponentUpdate 以外,其他都应该避免去使用,并且 V16 中也引入了新的 API 来解决这个问题。
getDerivedStateFromProps 用于替换 componentWillReceiveProps ,该函数会在初始化和 update 时被调用
getSnapshotBeforeUpdate 用于替换 componentWillUpdate ,该函数会在 update 后 DOM 更新前被调用,用于读取最新的 DOM 数据。
React中组件也有生命周期,也就是说也有很多钩子函数供我们使用, 组件的生命周期,我们会分为四个阶段,初始化、运行中、销毁、错误处理(16.3之后)
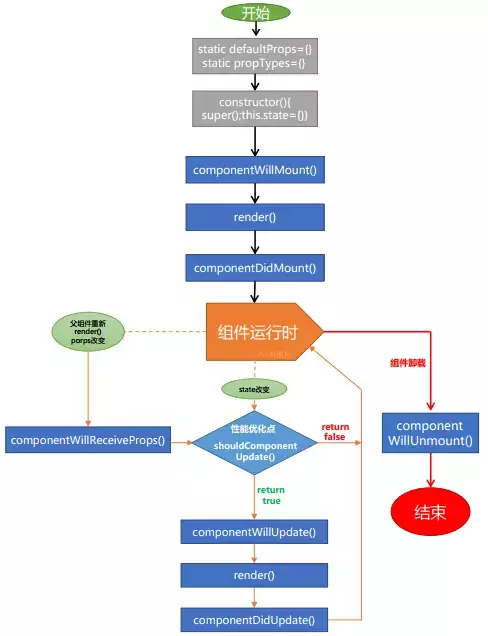
一、初始化阶段
1、设置组件的默认属性
static defaultProps = {
name: 'sls', age:23 }; //or Counter.defaltProps={name:'sls'}
2、constructor 设置组件的初始化状态
constructor() {
super();
this.state = {number: 0}
}
3、getDerivedStateFromProps()
该函数会在初始化和 update 时被调用
4、componentWillMount()
组件即将被渲染到页面之前触发,此时可以进行开启定时器、向服务器发送请求等操作
5、render()
组件渲染
6、componentDidMount()
组件已经被渲染到页面中后触发:此时页面中有了真正的DOM的元素,可以进行DOM相关的操作
二、运行中阶段
props或state的改变可能会引起组件的更新,组件重新渲染的过程中会调用以下方法:
1、componentWillReceiveProps()
组件接收到属性时触发
3、 getDerivedStateFromProps()
4、shouldComponentUpdate()
当组件接收到新属性,或者组件的状态发生改变时触发。组件首次渲染时并不会触发
shouldComponentUpdate(newProps, newState) {
if (newProps.number < 5) return true; return false }
//该钩子函数可以接收到两个参数,新的属性和状态,返回true/false来控制组件是否需要更新。
一般我们通过该函数来优化性能:
一个React项目需要更新一个小组件时,很可能需要父组件更新自己的状态。而一个父组件的重新更新会造成它旗下所有的子组件重新执行render()方法,形成新的虚拟DOM,再用diff算法对新旧虚拟DOM进行结构和属性的比较,决定组件是否需要重新渲染
无疑这样的操作会造成很多的性能浪费,所以我们开发者可以根据项目的业务逻辑,在shouldComponentUpdate()中加入条件判断,从而优化性能
例如React中的就提供了一个PureComponent的类,当我们的组件继承于它时,组件更新时就会默认先比较新旧属性和状态,从而决定组件是否更新。值得注意的是,PureComponent进行的是浅比较,所以组件状态或属性改变时,都需要返回一个新的对象或数组
5、componentWillUpdate()
组件即将被更新时触发
6、render()
7、getSnapshotBeforeUpdate()
8、componentDidUpdate()
组件被更新完成后触发。页面中产生了新的DOM的元素,可以进行DOM操作
三、销毁阶段
componentWillUnmount()
组件被销毁时触发。这里我们可以进行一些清理操作,例如清理定时器,取消Redux的订阅事件等等。
- componentWillReceiveProps() / UNSAFE_componentWillReceiveProps()
- shouldComponentUpdate()
- componentWillUpdate() / UNSAFE_componentWillUpdate()
- render()
- getSnapshotBeforeUpdate()
- componentDidUpdate()
##卸载阶段
- componentWillUnmount()
##错误处理
- componentDidCatch()
各生命周期详解
1.constructor(props)
React组件的构造函数在挂载之前被调用。在实现React.Component构造函数时,需要先在添加其他内容前,调用super(props),用来将父组件传来的props绑定到这个类中,使用this.props将会得到。
官方建议不要在constructor引入任何具有副作用和订阅功能的代码,这些应当使用componentDidMount()。
constructor中应当做些初始化的动作,如:
初始化state,
将事件处理函数绑定到类实例上,
但也不要使用setState()。
如果没有必要初始化state或绑定方法,则不需要构造constructor,
或者把这个组件换成纯函数写法。
当然也可以利用props初始化state,在之后修改state不会对props造成任何修改,但仍然建议大家提升状态到父组件中,或使用redux统一进行状态管理。
constructor(props) {
super(props);
this.state = {
isLiked: props.isLiked
};
}
2. getDerivedStateFromProps(nextProps, prevState)
getDerivedStateFromProps 是react16.3之后新增,
在组件实例化后,和接受新的props后被调用。
他必须返回一个对象来更新状态,或者返回null表示新的props不需要任何state的更新。
如果是由于父组件的props更改,所带来的重新渲染,也会触发此方法。
调用setState()不会触发getDerivedStateFromProps()。
之前这里都是使用constructor+componentWillRecieveProps完成相同的功能的
3.componentWillMount()
componentWillMount()将在React未来版本(官方说法 17.0)中被弃用。UNSAFE_componentWillMount()
在组件挂载前被调用,
在这个方法中调用setState()不会起作用,是由于他在render()前被调用。
为了避免副作用和其他的订阅,官方都建议使用componentDidMount()代替。
这个方法是用于在服务器渲染上的唯一方法。
这个方法因为是在渲染之前被调用,也是惟一一个可以直接同步修改state的地方。
4.render()
render()方法是必需的。当他被调用时,他将计算this.props和this.state,并返回以下一种类型:
- React元素。通过jsx创建,既可以是dom元素,也可以是用户自定义的组件。
- 字符串或数字。他们将会以文本节点形式渲染到dom中。
- Portals。react 16版本中提出的新的解决方案,可以使组件脱离父组件层级直接挂载在DOM树的任何位置。
- null,什么也不渲染
- 布尔值。也是什么都不渲染。
当返回null,false,ReactDOM.findDOMNode(this)将会返回null,什么都不会渲染。
render()方法必须是一个纯函数,他不应该改变state,也不能直接和浏览器进行交互,应该将事件放在其他生命周期函数中。
如果shouldComponentUpdate()返回false,render()不会被调用。
5.componentDidMount
componentDidMount在组件被装配后立即调用。初始化获得DOM节点应该进行到这里。
通常在这里进行ajax请求
如果要初始化第三方的dom库,也在这里进行初始化。只有到这里才能获取到真实的dom.
6.componentWillReceiveProps()
官方建议使用getDerivedStateFromProps函数代替componentWillReceiveProps。当组件挂载后,接收到新的props后会被调用。如果需要更新state来响应props的更改,则可以进行this.props和nextProps的比较,并在此方法中使用this.setState()。
如果父组件会让这个组件重新渲染,即使props没有改变,也会调用这个方法。
React不会在组件初始化props时调用这个方法。调用this.setState也不会触发。
7.shouldComponentUpdate(nextProps, nextState)
调用shouldComponentUpdate使React知道,组件的输出是否受state和props的影响。默认每个状态的更改都会重新渲染,大多数情况下应该保持这个默认行为。
在渲染新的props或state前,shouldComponentUpdate会被调用。默认为true。
这个方法不会在初始化时被调用,
也不会在forceUpdate()时被调用。
返回false不会阻止子组件在state更改时重新渲染。
如果shouldComponentUpdate()返回false,componentWillUpdate,render和componentDidUpdate不会被调用。
官方并不建议在
shouldComponentUpdate()中进行深度查询或使用JSON.stringify(),他效率非常低,并且损伤性能。
8.UNSAFE_componentWillUpdate(nextProps, nextState)
在渲染新的state或props时,UNSAFE_componentWillUpdate会被调用,将此作为在更新发生之前进行准备的机会。
这个方法不会在初始化时被调用。
不能在这里使用this.setState(),
也不能做会触发视图更新的操作。
如果需要更新state或props,调用getDerivedStateFromProps。
9.getSnapshotBeforeUpdate()
在react render()后的输出被渲染到DOM之前被调用。
它使您的组件能够在它们被潜在更改之前捕获当前值(如滚动位置)。
这个生命周期返回的任何值都将作为参数传递给componentDidUpdate()。
10.componentDidUpdate(prevProps, prevState, snapshot)
在更新发生后立即调用componentDidUpdate()。
此方法不用于初始渲染。
当组件更新时,将此作为一个机会来操作DOM。
只要您将当前的props与以前的props进行比较(例如,如果props没有改变,则可能不需要网络请求),这也是做网络请求的好地方。
如果组件实现getSnapshotBeforeUpdate()生命周期,则它返回的值将作为第三个“快照”参数传递给componentDidUpdate()。否则,这个参数是undefined。
11.componentWillUnmount()
在组件被卸载并销毁之前立即被调用。
在此方法中执行任何必要的清理,
例如使定时器无效,
取消网络请求或清理在componentDidMount中创建的任何监听。
12.componentDidCatch(error, info)
错误边界是React组件,可以在其子组件树中的任何位置捕获JavaScript错误,记录这些错误并显示回退UI,而不是崩溃的组件树。
错误边界在渲染期间,生命周期方法以及整个树下的构造函数中捕获错误。
如果类组件定义了此生命周期方法,则它将成错误边界。
在它中调用setState()可以让你在下面的树中捕获未处理的JavaScript错误,并显示一个后备UI。
只能使用错误边界从意外异常中恢复; 不要试图将它们用于控制流程。
错误边界只会捕获树中下面组件中的错误。错误边界本身不能捕获错误。
13.PureComponent
PureComponnet里如果接收到的新属性或者是更改后的状态和原属性、原状态相同的话,就不会去重新render了
在里面也可以使用shouldComponentUpdate,而且。
是否重新渲染以shouldComponentUpdate的返回值为最终的决定因素。
import React, { PureComponent } from 'react'
class YourComponent extends PureComponent {
……
}
setState
setState有时表现出异步,有时表现出同步
setState只在合成事件和钩子函数中是“异步”的,在原生事件和setTimeout 中都是同步的。
setState 的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。
setState 的批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout 中不会批量更新,在“异步”中如果对同一个值进行多次setState,setState的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时setState多个不同的值,在更新时会对其进行合并批量更新
setState 在 React 中是经常使用的一个 API,但是它存在一些的问题经常会导致初学者出错,核心原因就是因为这个 API 是异步的。
首先 setState 的调用并不会马上引起 state 的改变,并且如果你一次调用了多个 setState ,那么结果可能并不如你期待的一样。
handle() {
// 初始化 `count` 为 0
console.log(this.state.count) // -> 0
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
console.log(this.state.count) // -> 0
}
第一,两次的打印都为 0,因为 setState 是个异步 API,只有同步代码运行完毕才会执行。setState 异步的原因我认为在于,setState 可能会导致 DOM 的重绘,如果调用一次就马上去进行重绘,那么调用多次就会造成不必要的性能损失。设计成异步的话,就可以将多次调用放入一个队列中,在恰当的时候统一进行更新过程。
第二,虽然调用了三次 setState ,但是 count 的值还是为 1。因为多次调用会合并为一次,只有当更新结束后 state 才会改变,三次调用等同于如下代码
Object.assign(
{},
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
)w
当然你也可以通过以下方式来实现调用三次 setState 使得 count 为 3
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
}
如果你想在每次调用 setState 后获得正确的 state ,可以通过如下代码实现
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }), () => {
console.log(this.state)
})
}
通信
其实 React 中的组件通信基本和 Vue 中的一致。同样也分为以下三种情况:
- 父子组件通信
- 兄弟组件通信
- 跨多层级组件通信
- 任意组件
父子通信
父组件通过 props 传递数据给子组件,子组件通过调用父组件传来的函数传递数据给父组件,这两种方式是最常用的父子通信实现办法。
这种父子通信方式也就是典型的单向数据流,父组件通过 props 传递数据,子组件不能直接修改 props, 而是必须通过调用父组件函数的方式告知父组件修改数据。
兄弟组件通信
对于这种情况可以通过共同的父组件来管理状态和事件函数。比如说其中一个兄弟组件调用父组件传递过来的事件函数修改父组件中的状态,然后父组件将状态传递给另一个兄弟组件。
跨多层次组件通信
如果你使用 16.3 以上版本的话,对于这种情况可以使用 Context API。
// 创建 Context,可以在开始就传入值
const StateContext = React.createContext()
class Parent extends React.Component {
render () {
return (
// value 就是传入 Context 中的值
)
}
}
class Child extends React.Component {
render () {
return (
// 取出值
{context => (
name is { context }
)}
);
}
}
context.js
import React from 'react'
const {
Provider,
Consumer: MapCounsumer
} = React.createContext();
class MapProvider extends React.Component {
constructor() {
super();
this.state = {
showMap: JSON.parse(localStorage.getItem('showMap')) || false
}
}
changeStatus = () => {
this.setState((preState) => {
return {
showMap: !preState.showMap
}
}, () => {
localStorage.setItem('showMap', this.state.showMap)
})
}
render() {
return (
{
this.props.children
}
)
}
}
export {
MapProvider,
MapCounsumer
}
//index.js
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import "assets/styles/reset.css"
import { MapProvider } from './context/MapContext'
ReactDOM.render(
,
document.getElementById('root')
);
more.js
import React, { Component } from 'react'
import {Switch} from 'antd-mobile'
import {MapCounsumer} from 'context/MapContext'
export default class More extends Component {
render() {
return (
{
({showMap,changeStatus})=>{
return (
<>
地图:
)
}
}
任意组件
这种方式可以通过 Redux 或者 Event Bus 解决,另外如果你不怕麻烦的话,可以使用这种方式解决上述所有的通信情况
redux和mobx区别
Redux的流程:
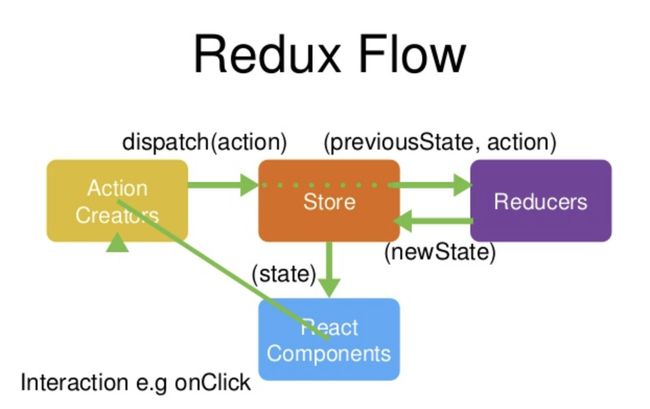
1.store通过reducer创建了初始状态;
2.view通过store.getState()将store中保存的state挂载在了自己的状态上;
3.用户产生了操作,调用了actions 的方法;
4.actions的方法被调用,创建了带有标示性信息的action;
5.actions将action通过调用store.dispatch方法发送到了reducer中;
6.reducer接收到action并根据标识信息判断之后返回了新的state;
7.store的state被reducer更改为新state的时候,store.subscribe方法里的回调函数会执行,此时就可以通知view去重新获取state;
react-redux提供两个核心的api:
- Provider: 提供store
- connect: 用于连接容器组件和展示组件
-
Provider
根据单一store原则 ,一般只会出现在整个应用程序的最顶层。
-
connect
语法格式为
connect(mapStateToProps?, mapDispatchToProps?, mergeProps?, options?)(component)一般来说只会用到前面两个,它的作用是:
- 把
store.getState()的状态转化为展示组件的props - 把
actionCreators转化为展示组件props上的方法
- 把
特别强调:
官网上的第二个参数为mapDispatchToProps, 实际上就是actionCreators
只要上层中有Provider组件并且提供了store, 那么,子孙级别的任何组件,要想使用store里的状态,都可以通过connect方法进行连接。如果只是想连接actionCreators,可以第一个参数传递为null
两者对比:
1、redux将数据保存在单一的store中,mobx将数据保存在分散的多个store中
2、redux使用 扁平的对象 保存数据,需要手动处理变化后的操作;mobx使用observable保存数据,数据变化后自动处理响应的操作
3、redux使用不可变状态,这意味着状态是只读的,不能直接去修改它,而是应该返回一个新的状态,同时使用纯函数;mobx中的状态是可变的,可以直接对其进行修改
4、mobx相对来说比较简单,mobx更多的使用面向对象的编程思维;redux会比较复杂,因为其中的函数式编程思想掌握起来不是那么容易,同时需要借助一系列的中间件来处理异步和副作用
5、mobx调试会比较困难;而redux提供能够进行时间回溯的开发工具,让调试变得更加的容易
场景辨析:
基于以上区别,我们可以简单得分析一下两者的不同使用场景.
1、mobx更适合数据不复杂的应用: mobx难以调试,很多状态无法回溯,面对复杂度高的应用时,往往力不从心.
2、redux适合有回溯需求的应用: 比如一个画板应用、一个表格应用,很多时候需要撤销、重做等操作,由于redux不可变的特性,天然支持这些操作.
3、mobx适合短平快的项目: mobx上手简单,样板代码少,可以很大程度上提高开发效率.
4、当然mobx和redux也并不一定是非此即彼的关系,你也可以在项目中用redux作为全局状态管理,用mobx作为组件局部状态管理器来用
简述 flux 思想
Flux 的最大特点,就是数据的"单向流动"。
用户访问 View
View 发出用户的 Action
Dispatcher 收到 Action,要求 Store 进行相应的更新
Store 更新后,发出一个"change"事件
View 收到"change"事件后,更新页面
shouldComponentUpdate和componentWillReciveProps
shouldComponentUpdate 这个方法用来判断是否需要调用 render 方法重新描绘 dom。因为 dom 的描绘非常消耗性能,如果我们能在 shouldComponentUpdate 方法中能够写出更优化的 dom diff 算法,可以极大的提高性能
componentWillReceiveProps在初始化render的时候不会执行,它会在Component接受到新的状态(Props)时被触发,一般用于父组件状态更新时子组件的重新渲染。React 16之后这个生命周期被废弃.
React合成事件和原生事件区别
React合成事件机制:React并不是将click事件直接绑定在dom上面,而是采用事件冒泡的形式冒泡到document上面,然后将事件内容封装交给中间层,最后将事件交给正式的函数运行和处理
Hooks的原理是什么?
代码可读性更强,原本同一块功能的代码逻辑被拆分在了不同的生命周期函数中,容易使开发者不利于维护和迭代,通过 React Hooks 可以将功能代码聚合,方便阅读维护
组件树层级变浅,在原本的代码中,我们经常使用 HOC/render props 等方式来复用组件的状态,增强功能等,无疑增加了组件树层数及渲染,而在 React Hooks 中,这些功能都可以通过强大的自定义的 Hooks 来实现
1、useState 保存组件状态
2、useEffect 处理副作用
3、useContext 减少组件层级
4、useReducer
在使用上几乎跟 Redux/React-Redux 一模一样,唯一缺少的就是无法使用 redux 提供的中间件。用法也很简单
5、useCallback 记忆函数
function App() {
const memoizedHandleClick = useCallback(() => {
console.log('Click happened')
}, []); // 空数组代表无论什么情况下该函数都不会发生改变
return Click Me ;
}
通过 useCallback 获得一个记忆后的函数。
第二个参数传入一个数组,数组中的每一项一旦值或者引用发生改变,useCallback 就会重新返回一个新的记忆函数提供给后面进行渲染。
6、useMemo 记忆组件:
只有在第二个参数数组的值发生变化时,才会触发子组件的更新。
useCallback 的功能完全可以由 useMemo 所取代,
唯一的区别是:**useCallback 不会执行第一个参数函数,而是将它返回给你,而 useMemo 会执行第一个函数并且将函数执行结果返回给你。**所以在前面的例子中,可以返回 handleClick 来达到存储函数的目的。
所以 useCallback 常用记忆事件函数,生成记忆后的事件函数并传递给子组件使用。而 useMemo 更适合经过函数计算得到一个确定的值,比如记忆组件。
7、useRef 保存引用值:
useRef 创建一个引用,不是拷贝
8、useImperativeHandle 透传 Ref
9、通过 useImperativeHandle 用于让父组件获取子组件内的DOM
10、useLayoutEffect 同步执行副作用
会在 DOM 更新之后同步执行;useLayoutEffect 会在 render,DOM 更新之后同步触发函数,会优于 useEffect 异步触发函数。
render为什么会执行两次
父组件发生变化 子组件即使props state没发生变化也会执行render 只是diff后不再渲染dom
为了解决这个问题可以通过使用PureComponent 类
PureComponent 是优化 React 应用程序最重要的方法之一。只要把继承类从 Component 换成 PureComponent ,当组件更新时,如果组件的 props 和 state 都没发生改变,render 方法就不会触发,省去 Virtual DOM 的生成和比对过程可以减少不必要的 render 操作的次数,从而提高性能,而且可以少写 shouldComponentUpdate 函数,节省了点代码。
React 受控组件和非受控组件
在React中,所谓受控组件和非受控组件,是针对表单而言的
受控组件,表单元素的修改会实时映射到状态值上,此时就可以对输入的内容进行校验
受控组件必须要在表单上使用onChange事件来绑定对应的事件
非受控组件即不受状态的控制,获取数据就是相当于操作DOM
react中如何实现命名插槽
在Vue中,假如我们需要让子组件的一部分内容,被父组件控制,而不是被子组件控制,那么我们会采用插槽的写法
在 React 里也有类似的写法,父组件写法是相同的,但子组件是采用 {this.props.children} 来实现
react中具名插槽只要使用属性传递就行
如何理解的jsx
所谓的 JSX 其实就是 JavaScript 对象,就是用 JavaScript 对象来表现一个 DOM 元素的结构。JSX就是让 JavaScript 语言能够支持这种直接在 JavaScript 代码里面编写类似 HTML 标签结构的语法,这样写起来就方便很多。编译的过程会把类似 HTML 的 JSX 结构转换成 JavaScript 的对象结构。
shouldComponentUpdate参数
shouldComponentUpdate函数是重渲染时render()函数调用前被调用的函数,它接受两个参数:nextProps和nextState,分别表示下一个props和下一个state的值。并且,当函数返回false时候,阻止接下来的render()函数的调用,阻止组件重渲染,而返回true时,组件照常重渲染。
react的render
只要组件的状态(props或者state)发生了更改,那么组件就会默认执行render函数重新进行渲染(你也可以通过重写shouldComponentUpdate手动阻止这件事的发生)。同时要注意的事情是,执行render函数并不意味着浏览器中的真实 DOM 树需要修改。浏览器中的真实 DOM 是否需要发生修改,是由 React 最后比较 Virtual Tree 决定的。 我们都知道修改浏览器中的真实 DOM 是非常耗费性能的一件事,于是 React 为我们做出了优化。但是执行render的代价仍然需要我们自己承担
注意点
在redux中,reducer是纯函数,需要返回一个全新的对象才会触发redux对state的修改,如果是在原对象上进行修改则无法触发,因为redux会先比较前后两份state的引用,相同就return
小结
总的来说这一章节的内容更多的偏向于 React 的基础,另外 React 的面试题还会经常考到 Virtual DOM 中的内容,所以这块内容大家也需要好好准备。
下一章节我们将来了解一些 React 的进阶知识内容。
20、React 常考进阶知识点
这一章节我们将来学习 React 的一些经常考到的进阶知识点,并且这章节还需要配合第十九章阅读,其中的内容经常会考到。
React码源
如今,主流的前端框架React,Vue和Angular在前端领域已成三足鼎立之势,基于前端技术栈的发展现状,大大小小的公司或多或少也会使用其中某一项或者多项技术栈,那么掌握并熟练使用其中至少一种也成为了前端人员必不可少的技能饭碗。当然,框架的部分实现细节也常成为面试中的考察要点,因此,一方面为了应付面试官的连番追问,另一方面为了提升自己的技能水平,还是有必要对框架的底层实现原理有一定的涉猎。
面试考点
看完以上内容,按道理来说以下几个可能的面试考点应该就不成问题了,或者说至少也不会遇到一个字也回答不了的尴尬局面,试试看吧:
- 在React中为何能够支持
jsx语法 - 类组件的
render方法执行后最终返回的结果是什么 - 手写代码实现一个
createElement方法 - 如何判断一个对象是不是
React Element - 如何区分类组件和函数定义组件
Component和PureComponent之间的关系- 如何区分
Component和PureComponent
1、准备阶段
在facebook的github上,目前React的最新版本为v16.12.0,我们知道在React的v16版本之后引入了新的Fiber架构,这种架构使得任务拥有了暂停和恢复机制,将一个大的更新任务拆分为一个一个执行单元,充分利用浏览器在每一帧的空闲时间执行任务,无空闲时间则延迟执行,从而避免了任务的长时间运行导致阻塞主线程同步任务的执行。为了了解这种Fiber架构,这里选择了一个比较适中的v16.10.2的版本,没有选择最新的版本是因为在最新版本中移除了一些旧的兼容处理方案,虽说这些方案只是为了兼容,但是其思想还是比较先进的,值得我们推敲学习,所以先将其保留下来,这里选择v16.10.2版本的另外一个原因是React在v16.10.0的版本中涉及到两个比较重要的优化点:

在上图中指出,在任务调度(Scheduler)阶段有两个性能的优化点,解释如下:
-
将任务队列的内部数据结构转换成最小二叉堆的形式以提升队列的性能(在最小堆中我们能够以最快的速度找到最小的那个值,因为那个值一定在堆的顶部,有效减少整个数据结构的查找时间)。
-
使用周期更短的
postMessage循环的方式而不是使用requestAnimationFrame这种与帧边界对齐的方式(这种优化方案指得是在将任务进行延迟后恢复执行的阶段,前后两种方案都是宏任务,但是宏任务也有顺序之分,postMessage的优先级比requestAnimationFrame高,这也就意味着延迟任务能够更快速地恢复并执行)。
当然现在不太理解的话没关系,后续会有单独的文章来介绍任务调度这一块内容,遇到上述两个优化点的时候会进行详细说明,在开始阅读源码之前,我们可以使用create-react-app来快速搭建一个React项目,后续的示例代码可以在此项目上进行编写:
// 项目搭建完成后React默认为最新版v16.12.0
create-react-app react-learning
// 为了保证版本一致,手动将其修改为v16.10.2
npm install --save [email protected] [email protected]
// 运行项目
npm start
执行以上步骤后,不出意外的话,浏览器中会正常显示出项目的默认界面。得益于在Reactv16.8版本之后推出的React Hooks功能,让我们在原来的无状态函数组件中也能进行状态管理,以及使用相应的生命周期钩子,甚至在新版的create-react-app脚手架中,根组件App已经由原来的类组件的写法升级为了推荐的函数定义组件的方式,但是原来的类组件的写法并没有被废弃掉,事实上我们项目中还是会大量充斥着类组件的写法,因此为了了解这种类组件的实现原理,我们暂且将App根组件的函数定义的写法回退到类组件的形式,并对其内容进行简单修改:
// src -> App.js
import React, {Component} from 'react';
function List({data}) {
return (
{
data.map(item => {
return - {item}
})
}
);
}
export default class App extends Component {
constructor(props) {
super(props);
this.state = {
data: [1, 2, 3]
};
}
render() {
return (
React learning
);
}
}
经过以上简单修改后,然后我们通过调用
// src -> index.js
ReactDOM.render(来将组件挂载到DOM容器中,最终得到App组件的DOM结构如下所示:
React learning
- 1
- 2
- 3
因此我们分析React源码的入口也将会是从ReactDOM.render方法开始一步一步分析组件渲染的整个流程,但是在此之前,我们有必要先了解几个重要的前置知识点,这几个知识点将会更好地帮助我们理解源码的函数调用栈中的参数意义和其他的一些细节。
2、前置知识
首先我们需要明确的是,在上述示例中,App组件的render方法返回的是一段HTML结构,在普通的函数中这种写法是不支持的,所以我们一般需要相应的插件来在背后支撑,在React中为了支持这种jsx语法提供了一个Babel预置工具包@babel/preset-react,其中这个preset又包含了两个比较核心的插件:
-
@babel/plugin-syntax-jsx:这个插件的作用就是为了让Babel编译器能够正确解析出jsx语法。 -
@babel/plugin-transform-react-jsx:在解析完jsx语法后,因为其本质上是一段HTML结构,因此为了让JS引擎能够正确识别,我们就需要通过该插件将jsx语法编译转换为另外一种形式。在默认情况下,会使用React.createElement来进行转换,当然我们也可以在.babelrc文件中来进行手动设置。
// .babelrc
{
"plugins": [
["@babel/plugin-transform-react-jsx", {
"pragma": "Preact.h", // default pragma is React.createElement
"pragmaFrag": "Preact.Fragment", // default is React.Fragment
"throwIfNamespace": false // defaults to true
}]
]
}
这里为了方便起见,我们可以直接使用Babel官方实验室来查看转换后的结果,对应上述示例,转换后的结果如下所示:
// 转换前
render() {
return (
React learning
);
}
// 转换后
render() {
return React.createElement("div", {
className: "content"
},
React.createElement("header", null, "React learning"),
React.createElement(List, { data: this.state.data }));
}
可以看到jsx语法最终被转换成由React.createElement方法组成的嵌套调用链,可能你之前已经了解过这个API,或者接触过一些伪代码实现,这里我们就基于源码,深入源码内部来看看其背后为我们做了哪些事情。
2.1 createElement & ReactElement
为了保证源码的一致性,也建议你将React版本和笔者保持一致,采用v16.10.2版本,可以通过facebook的github官方渠道进行获取,下载下来之后我们通过如下路径来打开我们需要查看的文件:
// react-16.10.2 -> packages -> react -> src -> React.js
在React.js文件中,我们直接跳转到第63行,可以看到React变量作为一个对象字面量,包含了很多我们所熟知的方法,包括在v16.8版本之后推出的React Hooks方法:
const React = {
Children: {
map,
forEach,
count,
toArray,
only,
},
createRef,
Component,
PureComponent,
createContext,
forwardRef,
lazy,
memo,
// 一些有用的React Hooks方法
useCallback,
useContext,
useEffect,
useImperativeHandle,
useDebugValue,
useLayoutEffect,
useMemo,
useReducer,
useRef,
useState,
Fragment: REACT_FRAGMENT_TYPE,
Profiler: REACT_PROFILER_TYPE,
StrictMode: REACT_STRICT_MODE_TYPE,
Suspense: REACT_SUSPENSE_TYPE,
unstable_SuspenseList: REACT_SUSPENSE_LIST_TYPE,
// 重点先关注这里,生产模式下使用后者
createElement: __DEV__ ? createElementWithValidation : createElement,
cloneElement: __DEV__ ? cloneElementWithValidation : cloneElement,
createFactory: __DEV__ ? createFactoryWithValidation : createFactory,
isValidElement: isValidElement,
version: ReactVersion,
unstable_withSuspenseConfig: withSuspenseConfig,
__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED: ReactSharedInternals,
这里我们暂且先关注createElement方法,在生产模式下它来自于与React.js同级别的ReactElement.js文件,我们打开该文件,并直接跳转到第312行,可以看到createElement方法的函数定义(去除了一些__DEV__环境才会执行的代码):
/**
* 该方法接收包括但不限于三个参数,与上述示例中的jsx语法经过转换之后的实参进行对应
* @param type 表示当前节点的类型,可以是原生的DOM标签字符串,也可以是函数定义组件或者其它类型
* @param config 表示当前节点的属性配置信息
* @param children 表示当前节点的子节点,可以不传,也可以传入原始的字符串文本,甚至可以传入多个子节点
* @returns 返回的是一个ReactElement对象
*/
export function createElement(type, config, children) {
let propName;
// Reserved names are extracted
// 用于存放config中的属性,但是过滤了一些内部受保护的属性名
const props = {};
// 将config中的key和ref属性使用变量进行单独保存
let key = null;
let ref = null;
let self = null;
let source = null;
// config为null表示节点没有设置任何相关属性
if (config != null) {
// 有效性判断,判断 config.ref !== undefined
if (hasValidRef(config)) {
ref = config.ref;
}
// 有效性判断,判断 config.key !== undefined
if (hasValidKey(config)) {
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source;
// Remaining properties are added to a new props object
// 用于将config中的所有属性在过滤掉内部受保护的属性名后,将剩余的属性全部拷贝到props对象中存储
// const RESERVED_PROPS = {
// key: true,
// ref: true,
// __self: true,
// __source: true,
// };
for (propName in config) {
if (
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// Children can be more than one argument, and those are transferred onto
// the newly allocated props object.
// 由于子节点的数量不限,因此从第三个参数开始,判断剩余参数的长度
// 具有多个子节点则props.children属性存储为一个数组
const childrenLength = arguments.length - 2;
if (childrenLength === 1) {
// 单节点的情况下props.children属性直接存储对应的节点
props.children = children;
} else if (childrenLength > 1) {
// 多节点的情况下则根据子节点数量创建一个数组
const childArray = Array(childrenLength);
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
props.children = childArray;
}
// Resolve default props
// 此处用于解析静态属性defaultProps
// 针对于类组件或函数定义组件的情况,可以单独设置静态属性defaultProps
// 如果有设置defaultProps,则遍历每个属性并将其赋值到props对象中(前提是该属性在props对象中对应的值为undefined)
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
props[propName] = defaultProps[propName];
}
}
}
// 最终返回一个ReactElement对象
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
经过上述分析我们可以得出,在类组件的render方法中最终返回的是由多个ReactElement对象组成的多层嵌套结构,所有的子节点信息均存放在父节点的props.children属性中。我们将源码定位到ReactElement.js的第111行,可以看到ReactElement函数的完整实现:
/**
* 为一个工厂函数,每次执行都会创建并返回一个ReactElement对象
* @param type 表示节点所对应的类型,与React.createElement方法的第一个参数保持一致
* @param key 表示节点所对应的唯一标识,一般在列表渲染中我们需要为每个节点设置key属性
* @param ref 表示对节点的引用,可以通过React.createRef()或者useRef()来创建引用
* @param self 该属性只有在开发环境才存在
* @param source 该属性只有在开发环境才存在
* @param owner 一个内部属性,指向ReactCurrentOwner.current,表示一个Fiber节点
* @param props 表示该节点的属性信息,在React.createElement中通过config,children参数和defaultProps静态属性得到
* @returns 返回一个ReactElement对象
*/
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// This tag allows us to uniquely identify this as a React Element
// 这里仅仅加了一个$$typeof属性,用于标识这是一个React Element
$$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner,
};
...
return element;
};
一个ReactElement对象的结构相对而言还是比较简单,主要是增加了一个$$typeof属性用于标识该对象是一个React Element类型。REACT_ELEMENT_TYPE在支持Symbol类型的环境中为symbol类型,否则为number类型的数值。与REACT_ELEMENT_TYPE对应的还有很多其他的类型,均存放在shared/ReactSymbols目录中,这里我们可以暂且只关心这一种,后面遇到其他类型再来细看。
2.2 Component & PureComponent
了解完ReactElement对象的结构之后,我们再回到之前的示例,通过继承React.Component我们将App组件修改为了一个类组件,我们不妨先来研究下React.Component的底层实现。React.Component的源码存放在packages/react/src/ReactBaseClasses.js文件中,我们将源码定位到第21行,可以看到Component构造函数的完整实现:
/**
* 构造函数,用于创建一个类组件的实例
* @param props 表示所拥有的属性信息
* @param context 表示所处的上下文信息
* @param updater 表示一个updater对象,这个对象非常重要,用于处理后续的更新调度任务
*/
function Component(props, context, updater) {
this.props = props;
this.context = context;
// If a component has string refs, we will assign a different object later.
// 该属性用于存储类组件实例的引用信息
// 在React中我们可以有多种方式来创建引用
// 通过字符串的方式,如:
// 通过回调函数的方式,如: this.inputRef = input;} />
// 通过React.createRef()的方式,如:this.inputRef = React.createRef(null);
// 通过useRef()的方式,如:this.inputRef = useRef(null);
this.refs = emptyObject;
// We initialize the default updater but the real one gets injected by the
// renderer.
// 当state发生变化的时候,需要updater对象去处理后续的更新调度任务
// 这部分涉及到任务调度的内容,在后续分析到任务调度阶段的时候再来细看
this.updater = updater || ReactNoopUpdateQueue;
}
// 在原型上新增了一个isReactComponent属性用于标识该实例是一个类组件的实例
// 这个地方曾经有面试官考过,问如何区分函数定义组件和类组件
// 函数定义组件是没有这个属性的,所以可以通过判断原型上是否拥有这个属性来进行区分
Component.prototype.isReactComponent = {};
/**
* 用于更新状态
* @param partialState 表示下次需要更新的状态
* @param callback 在组件更新之后需要执行的回调
*/
Component.prototype.setState = function(partialState, callback) {
...
this.updater.enqueueSetState(this, partialState, callback, 'setState');
};
/**
* 用于强制重新渲染
* @param callback 在组件重新渲染之后需要执行的回调
*/
Component.prototype.forceUpdate = function(callback) {
this.updater.enqueueForceUpdate(this, callback, 'forceUpdate');
};
上述内容中涉及到任务调度的会在后续讲解到调度阶段的时候再来细讲,现在我们知道可以通过原型上的isReactComponent属性来区分函数定义组件和类组件。事实上,在源码中就是通过这个属性来区分Class Component和Function Component的,可以找到以下方法:
// 返回true则表示类组件,否则表示函数定义组件
function shouldConstruct(Component) {
return !!(Component.prototype && Component.prototype.isReactComponent);
}
与Component构造函数对应的,还有一个PureComponent构造函数,这个我们应该还是比较熟悉的,通过浅比较判断组件前后传递的属性是否发生修改来决定是否需要重新渲染组件,在一定程度上避免组件重渲染导致的性能问题。同样的,在ReactBaseClasses.js文件中,我们来看看PureComponent的底层实现:
// 通过借用构造函数,实现典型的寄生组合式继承,避免原型污染
function ComponentDummy() {}
ComponentDummy.prototype = Component.prototype;
function PureComponent(props, context, updater) {
this.props = props;
this.context = context;
// If a component has string refs, we will assign a different object later.
this.refs = emptyObject;
this.updater = updater || ReactNoopUpdateQueue;
}
// 将PureComponent的原型指向借用构造函数的实例
const pureComponentPrototype = (PureComponent.prototype = new ComponentDummy());
// 重新设置构造函数的指向
pureComponentPrototype.constructor = PureComponent;
// Avoid an extra prototype jump for these methods.
// 将Component.prototype和PureComponent.prototype进行合并,减少原型链查找所浪费的时间(原型链越长所耗费的时间越久)
Object.assign(pureComponentPrototype, Component.prototype);
// 这里是与Component的区别之处,PureComponent的原型上拥有一个isPureReactComponent属性
pureComponentPrototype.isPureReactComponent = true;
通过以上分析,我们就可以初步得出Component和PureComponent之间的差异,可以通过判断原型上是否拥有isPureReactComponent属性来进行区分,当然更细粒度的区分,还需要在阅读后续的源码内容之后才能见分晓。
揭秘ReactDOM.render
在上一篇文章中我们通过create-react-app脚手架快速搭建了一个简单的示例,并基于该示例讲解了在类组件中React.Component和React.PureComponent背后的实现原理。同时我们也了解到,通过使用 Babel 预置工具包@babel/preset-react可以将类组件中render方法的返回值和函数定义组件中的返回值转换成使用React.createElement方法包装而成的多层嵌套结构,并基于源码逐行分析了React.createElement方法背后的实现过程和ReactElement构造函数的成员结构,最后根据分析结果总结出了几道面试中可能会碰到或者自己以前遇到过的面试考点。上篇文章中的内容相对而言还是比较简单基础,主要是为本文以及后续的任务调度相关内容打下基础,帮助我们更好地理解源码的用意。本文就结合上篇文章的基础内容,从组件渲染的入口点ReactDOM.render方法开始,一步一步深入源码,揭秘ReactDOM.render方法背后的实现原理,如有错误,还请指出。
源码中有很多判断类似__DEV__变量的控制语句,用于区分开发环境和生产环境,笔者在阅读源码的过程中不太关心这些内容,就直接略过了,有兴趣的小伙伴儿可以自己研究研究。
render VS hydrate
本系列的源码分析是基于 Reactv16.10.2版本的,为了保证源码一致还是建议你选择相同的版本,下载该版本的地址和笔者选择该版本的具体原因可以在上一篇文章的准备阶段小节中查看,这里就不做过多讲解了。项目示例本身也比较简单,可以按照准备阶段的步骤自行使用create-react-app快速将一个简单的示例搭建起来,然后我们定位到src/index.js文件下,可以看到如下代码:
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
...
ReactDOM.render(该文件即为项目的主入口文件,App组件即为根组件,ReactDOM.render就是我们要开始分析源码的入口点。我们通过以下路径可以找到ReactDOM对象的完整代码:
packages -> react-dom -> src -> client -> ReactDOM.js
然后我们将代码定位到第632行,可以看到ReactDOM对象包含了很多我们可能使用过的方法,例如render、createPortal、findDOMNode,hydrate和unmountComponentAtNode等。本文中我们暂且只关心render方法,但为了方便对比,也可以简单看下hydrate方法:
const ReactDOM: Object = {
...
/**
* 服务端渲染
* @param element 表示一个ReactNode,可以是一个ReactElement对象
* @param container 需要将组件挂载到页面中的DOM容器
* @param callback 渲染完成后需要执行的回调函数
*/
hydrate(element: React$Node, container: DOMContainer, callback: ?Function) {
invariant(
isValidContainer(container),
'Target container is not a DOM element.',
);
...
// TODO: throw or warn if we couldn't hydrate?
// 注意第一个参数为null,第四个参数为true
return legacyRenderSubtreeIntoContainer(
null,
element,
container,
true,
callback,
);
},
/**
* 客户端渲染
* @param element 表示一个ReactElement对象
* @param container 需要将组件挂载到页面中的DOM容器
* @param callback 渲染完成后需要执行的回调函数
*/
render(
element: React$Element,
container: DOMContainer,
callback: ?Function,
) {
invariant(
isValidContainer(container),
'Target container is not a DOM element.',
);
...
// 注意第一个参数为null,第四个参数为false
return legacyRenderSubtreeIntoContainer(
null,
element,
container,
false,
callback,
);
},
...
};
发现没,render方法的第一个参数就是我们在上篇文章中讲过的ReactElement对象,所以说上篇文章的内容就是为了在这里打下基础的,便于我们对参数的理解。事实上,在源码中几乎所有方法参数中的element字段均可以传入一个ReactElement实例,这个实例就是通过 Babel 编译器在编译过程中使用React.createElement方法得到的。接下来在render方法中调用legacyRenderSubtreeIntoContainer来正式进入渲染流程,不过这里需要留意一下的是,render方法和hydrate方法在执行legacyRenderSubtreeIntoContainer时,第一个参数的值均为null,第四个参数的值恰好相反。
然后将代码定位到第570行,进入legacyRenderSubtreeIntoContainer方法的具体实现:
/**
* 开始构建FiberRoot和RootFiber,之后开始执行更新任务
* @param parentComponent 父组件,可以把它当成null值来处理
* @param children ReactDOM.render()或者ReactDOM.hydrate()中的第一个参数,可以理解为根组件
* @param container ReactDOM.render()或者ReactDOM.hydrate()中的第二个参数,组件需要挂载的DOM容器
* @param forceHydrate 表示是否融合,用于区分客户端渲染和服务端渲染,render方法传false,hydrate方法传true
* @param callback ReactDOM.render()或者ReactDOM.hydrate()中的第三个参数,组件渲染完成后需要执行的回调函数
* @returns {*}
*/
function legacyRenderSubtreeIntoContainer(
parentComponent: ?React$Component,
children: ReactNodeList,
container: DOMContainer,
forceHydrate: boolean,
callback: ?Function,
) {
...
// TODO: Without `any` type, Flow says "Property cannot be accessed on any
// member of intersection type." Whyyyyyy.
// 在第一次执行的时候,container上是肯定没有_reactRootContainer属性的
// 所以第一次执行时,root肯定为undefined
let root: _ReactSyncRoot = (container._reactRootContainer: any);
let fiberRoot;
if (!root) {
// Initial mount
// 首次挂载,进入当前流程控制中,container._reactRootContainer指向一个ReactSyncRoot实例
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(
container,
forceHydrate,
);
// root表示一个ReactSyncRoot实例,实例中有一个_internalRoot方法指向一个fiberRoot实例
fiberRoot = root._internalRoot;
// callback表示ReactDOM.render()或者ReactDOM.hydrate()中的第三个参数
// 重写callback,通过fiberRoot去找到其对应的rootFiber,然后将rootFiber的第一个child的stateNode作为callback中的this指向
// 一般情况下我们很少去写第三个参数,所以可以不必关心这里的内容
if (typeof callback === 'function') {
const originalCallback = callback;
callback = function() {
const instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
}
// Initial mount should not be batched.
// 对于首次挂载来说,更新操作不应该是批量的,所以会先执行unbatchedUpdates方法
// 该方法中会将executionContext(执行上下文)切换成LegacyUnbatchedContext(非批量上下文)
// 切换上下文之后再调用updateContainer执行更新操作
// 执行完updateContainer之后再将executionContext恢复到之前的状态
unbatchedUpdates(() => {
updateContainer(children, fiberRoot, parentComponent, callback);
});
} else {
// 不是首次挂载,即container._reactRootContainer上已经存在一个ReactSyncRoot实例
fiberRoot = root._internalRoot;
// 下面的控制语句和上面的逻辑保持一致
if (typeof callback === 'function') {
const originalCallback = callback;
callback = function() {
const instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
}
// Update
// 对于非首次挂载来说,是不需要再调用unbatchedUpdates方法的
// 即不再需要将executionContext(执行上下文)切换成LegacyUnbatchedContext(非批量上下文)
// 而是直接调用updateContainer执行更新操作
updateContainer(children, fiberRoot, parentComponent, callback);
}
return getPublicRootInstance(fiberRoot);
}
上面代码的内容稍微有些多,咋一看可能不太好理解,我们暂且可以不用着急看完整个函数内容。试想当我们第一次启动运行项目的时候,也就是第一次执行ReactDOM.render方法的时候,这时去获取container._reactRootContainer肯定是没有值的,所以我们先关心第一个if语句中的内容:
if (!root) {
// Initial mount
// 首次挂载,进入当前流程控制中,container._reactRootContainer指向一个ReactSyncRoot实例
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(
container,
forceHydrate,
);
...
}
这里通过调用legacyCreateRootFromDOMContainer方法将其返回值赋值给container._reactRootContainer,我们将代码定位到同文件下的第517行,去看看legacyCreateRootFromDOMContainer的具体实现:
/**
* 创建并返回一个ReactSyncRoot实例
* @param container ReactDOM.render()或者ReactDOM.hydrate()中的第二个参数,组件需要挂载的DOM容器
* @param forceHydrate 是否需要强制融合,render方法传false,hydrate方法传true
* @returns {ReactSyncRoot}
*/
function legacyCreateRootFromDOMContainer(
container: DOMContainer,
forceHydrate: boolean,
): _ReactSyncRoot {
// 判断是否需要融合
const shouldHydrate =
forceHydrate || shouldHydrateDueToLegacyHeuristic(container);
// First clear any existing content.
// 针对客户端渲染的情况,需要将container容器中的所有元素移除
if (!shouldHydrate) {
let warned = false;
let rootSibling;
// 循环遍历每个子节点进行删除
while ((rootSibling = container.lastChild)) {
...
container.removeChild(rootSibling);
}
}
...
// Legacy roots are not batched.
// 返回一个ReactSyncRoot实例
// 该实例具有一个_internalRoot属性指向fiberRoot
return new ReactSyncRoot(
container,
LegacyRoot,
shouldHydrate
? {
hydrate: true,
}
: undefined,
);
}
/**
* 根据nodeType和attribute判断是否需要融合
* @param container DOM容器
* @returns {boolean}
*/
function shouldHydrateDueToLegacyHeuristic(container) {
const rootElement = getReactRootElementInContainer(container);
return !!(
rootElement &&
rootElement.nodeType === ELEMENT_NODE &&
rootElement.hasAttribute(ROOT_ATTRIBUTE_NAME)
);
}
/**
* 根据container来获取DOM容器中的第一个子节点
* @param container DOM容器
* @returns {*}
*/
function getReactRootElementInContainer(container: any) {
if (!container) {
return null;
}
if (container.nodeType === DOCUMENT_NODE) {
return container.documentElement;
} else {
return container.firstChild;
}
}
其中在shouldHydrateDueToLegacyHeuristic方法中,首先根据container来获取 DOM 容器中的第一个子节点,获取该子节点的目的在于通过节点的nodeType和是否具有ROOT_ATTRIBUTE_NAME属性来区分是客户端渲染还是服务端渲染,ROOT_ATTRIBUTE_NAME位于packages/react-dom/src/shared/DOMProperty.js文件中,表示data-reactroot属性。我们知道,在服务端渲染中有别于客户端渲染的是,node服务会在后台先根据匹配到的路由生成完整的HTML字符串,然后再将HTML字符串发送到浏览器端,最终生成的HTML结构简化后如下:
在客户端渲染中是没有data-reactroot属性的,因此就可以区分出客户端渲染和服务端渲染。在 React 中的nodeType主要包含了五种,其对应的值和W3C中的nodeType标准是保持一致的,位于与DOMProperty.js同级的HTMLNodeType.js文件中:
// 代表元素节点
export const ELEMENT_NODE = 1;
// 代表文本节点
export const TEXT_NODE = 3;
// 代表注释节点
export const COMMENT_NODE = 8;
// 代表整个文档,即document
export const DOCUMENT_NODE = 9;
// 代表文档片段节点
export const DOCUMENT_FRAGMENT_NODE = 11;
经过以上分析,现在我们就可以很容易地区分出客户端渲染和服务端渲染,并且在面试中如果被问到两种渲染模式的区别,我们就可以很轻松地在源码级别上说出两者的实现差异,让面试官眼前一亮。怎么样,到目前为止,其实还是觉得挺简单的吧?
React高性能的体现:虚拟DOM
React高性能的原理:
在Web开发中我们总需要将变化的数据实时反应到UI上,这时就需要对DOM进行操作。而复杂或频繁的DOM操作通常是性能瓶颈产生的原因(如何进行高性能的复杂DOM操作通常是衡量一个前端开发人员技能的重要指标)。
React为此引入了虚拟DOM(Virtual DOM)的机制:在浏览器端用Javascript实现了一套DOM API。基于React进行开发时所有的DOM构造都是通过虚拟DOM进行,每当数据变化时,React都会重新构建整个DOM树,然后React将当前整个DOM树和上一次的DOM树进行对比,得到DOM结构的区别,然后仅仅将需要变化的部分进行实际的浏览器DOM更新。而且React能够批处理虚拟DOM的刷新,在一个事件循环(Event Loop)内的两次数据变化会被合并,例如你连续的先将节点内容从A-B,B-A,React会认为A变成B,然后又从B变成A UI不发生任何变化,而如果通过手动控制,这种逻辑通常是极其复杂的。
尽管每一次都需要构造完整的虚拟DOM树,但是因为虚拟DOM是内存数据,性能是极高的,部而对实际DOM进行操作的仅仅是Diff分,因而能达到提高性能的目的。这样,在保证性能的同时,开发者将不再需要关注某个数据的变化如何更新到一个或多个具体的DOM元素,而只需要关心在任意一个数据状态下,整个界面是如何Render的。
React Fiber
在react 16之后发布的一种react 核心算法,React Fiber是对核心算法的一次重新实现(官网说法)。之前用的是diff算法。
在之前React中,更新过程是同步的,这可能会导致性能问题。
当React决定要加载或者更新组件树时,会做很多事,比如调用各个组件的生命周期函数,计算和比对Virtual DOM,最后更新DOM树,这整个过程是同步进行的,也就是说只要一个加载或者更新过程开始,中途不会中断。因为JavaScript单线程的特点,如果组件树很大的时候,每个同步任务耗时太长,就会出现卡顿。
React Fiber的方法其实很简单——分片。把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会。
HOC 是什么?相比 mixins 有什么优点?
很多人看到高阶组件(HOC)这个概念就被吓到了,认为这东西很难,其实这东西概念真的很简单,我们先来看一个例子。
function add(a, b) {
return a + b
}
现在如果我想给这个 add 函数添加一个输出结果的功能,那么你可能会考虑我直接使用 console.log 不就实现了么。说的没错,但是如果我们想做的更加优雅并且容易复用和扩展,我们可以这样去做:
function withLog (fn) {
function wrapper(a, b) {
const result = fn(a, b)
console.log(result)
return result
}
return wrapper
}
const withLogAdd = withLog(add)
withLogAdd(1, 2)
其实这个做法在函数式编程里称之为高阶函数,大家都知道 React 的思想中是存在函数式编程的,高阶组件和高阶函数就是同一个东西。我们实现一个函数,传入一个组件,然后在函数内部再实现一个函数去扩展传入的组件,最后返回一个新的组件,这就是高阶组件的概念,作用就是为了更好的复用代码。
其实 HOC 和 Vue 中的 mixins 作用是一致的,并且在早期 React 也是使用 mixins 的方式。但是在使用 class 的方式创建组件以后,mixins 的方式就不能使用了,并且其实 mixins 也是存在一些问题的,比如:
- 隐含了一些依赖,比如我在组件中写了某个
state并且在mixin中使用了,就这存在了一个依赖关系。万一下次别人要移除它,就得去mixin中查找依赖 - 多个
mixin中可能存在相同命名的函数,同时代码组件中也不能出现相同命名的函数,否则就是重写了,其实我一直觉得命名真的是一件麻烦事。。 - 雪球效应,虽然我一个组件还是使用着同一个
mixin,但是一个mixin会被多个组件使用,可能会存在需求使得mixin修改原本的函数或者新增更多的函数,这样可能就会产生一个维护成本
HOC 解决了这些问题,并且它们达成的效果也是一致的,同时也更加的政治正确(毕竟更加函数式了)。
事件机制
React 其实自己实现了一套事件机制,首先我们考虑一下以下代码:
const Test = ({ list, handleClick }) => ({
list.map((item, index) => (
{index}
))
})
以上类似代码想必大家经常会写到,但是你是否考虑过点击事件是否绑定在了每一个标签上?事实当然不是,JSX 上写的事件并没有绑定在对应的真实 DOM 上,而是通过事件代理的方式,将所有的事件都统一绑定在了 document 上。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。
另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件(SyntheticEvent)。因此我们如果不想要事件冒泡的话,调用 event.stopPropagation 是无效的,而应该调用 event.preventDefault。
那么实现合成事件的目的是什么呢?总的来说在我看来好处有两点,分别是:
- 合成事件首先抹平了浏览器之间的兼容问题,另外这是一个跨浏览器原生事件包装器,赋予了跨浏览器开发的能力
- 对于原生浏览器事件来说,浏览器会给监听器创建一个事件对象。如果你有很多的事件监听,那么就需要分配很多的事件对象,造成高额的内存分配问题。但是对于合成事件来说,有一个事件池专门来管理它们的创建和销毁,当事件需要被使用时,就会从池子中复用对象,事件回调结束后,就会销毁事件对象上的属性,从而便于下次复用事件对象。
小结
你可能会惊讶于这一章节的内容并不多的情况,其实你如果将两章 React 以及第十九章的内容全部学习完后,基本上 React 的大部分面试问题都可以解决。
当然你可能会觉得看的还不过瘾,这不需要担心。我已经决定写一个免费专栏「React 进阶」,专门讲解有难度的问题。比如组件的设计模式、新特性、部分源码解析等等内容。当然这些内容都是需要好好打磨的,所以更新的不会很快,有兴趣的可以持续关注,都会更新链接在这一章节中。