服务器环境配置(CentOS7)
文章目录
- 虚拟机网络配置
- Java8安装配置
- Scala安装配置
- MySQL安装配置
- Redis安装配置
- Nginx安装配置
- Zookeeper安装配置
- Kafka安装配置
- ElasticSearch 安装配置
-
- ElasticSearch-Head_master安装
- IK分词器安装
- Kibana安装
- MongoDB安装
- Hadoop安装配置(单节点)
- Spark配置(单节点)
虚拟机网络配置
Xshell连接VMware虚拟机中的CentOS
Java8安装配置
下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
# 解压
tar -zxvf jdk-8u271-linux-x64.tar.gz
# 修改配置文件
vim /etc/profile
# 配置文件中添加
JAVA_HOME=/software/java/jdk1.8.0_271
JRE_HOME=/software/java/jdk1.8.0_271/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
# 使配置文件生效
source /etc/profile
# 验证
java -version
Scala安装配置
下载地址:https://downloads.lightbend.com/scala/2.12.12/scala-2.12.12.tgz
# 解压
tar -zxvf scala-2.12.12.tgz
# 修改配置文件
vim /etc/profile
# 配置文件中添加
export SCALA_HOME=/software/scala/scala-2.12.12
export PATH=$PATH:$SCALA_HOME/bin
# 使配置文件生效
source /etc/profile
# 验证
scala -version
MySQL安装配置
centos7安装mysql
CentOS7安装MySQL(完整版)
注:开始看第一篇文章,安装完MySQL后,配置看第二篇文章
Redis安装配置
参考文章:
https://blog.csdn.net/baidu_37313657/article/details/106027207
https://blog.csdn.net/zhengwei424/article/details/105901955
https://blog.csdn.net/qq_36918149/article/details/92087113
下载安装包:http://download.redis.io/releases/
#检查gcc是否安装
gcc -v
# 安装gcc ,默认安装的是4.8.5 需要升级
yum install -y gcc
# 安装scl源
yum -y install centos-release-scl
# 升级
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# scl命令启用只是临时的,退出shell或重启就会恢复原系统gcc版本
scl enable devtoolset-9 bash
# 长久使用gcc 升级版
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
# 解压同时进入目录进行编译
tar -zxvf redis-6.0.9.tar.gz
cd redis-6.0.9
make
# 安装并指定安装目录
mkdir -m 777 redis
make install PREFIX=/software/redis/redis-6.0.9/redis
# 创建etc文件夹,存放配置
mkdir -m 777 /software/redis/redis-6.0.9/redis/etc
# 拷贝配置文件过去
cp /software/redis/redis-6.0.9/redis.conf /software/redis/redis-6.0.9/redis/etc
# 修改配置文件
daemonize yes
requirepass 密码
注释 bind 127.0.0.1
protected-mode no
# 开启防火墙6379端口
firewall-cmd --permanent --add-port=6379/tcp
firewall-cmd --reload
# 启动server
cd /software/redis/redis-6.0.9/redis/bin
./redis-server ../etc/redis.conf
# 启动cli
cd /software/redis/redis-6.0.9/redis/bin
./redis-cli -a 密码
Nginx安装配置
参考文章:
https://blog.csdn.net/qq_37345604/article/details/90034424
1.安装相关库
# 安装gcc,不会安装看上面安装Redis的
yum -y install gcc
...
# pcre、pcre-devel安装
yum install -y pcre pcre-devel
# zlib安装
yum install -y zlib zlib-devel
# openssl安装
yum install -y openssl openssl-devel
2.解压
tar -zxvf nginx-1.18.0.tar.gz
3.进入
cd /software/nginx/nginx-1.18.0
4. 编译安装,依次执行下面语句
注意在执行./configure时执行下列语句,把nginx安装到指定位置,不然会默认安装到usr/local下,不便管理:
./configure --prefix=/software/nginx/nginx-1.18.0/nginx
make
make install
#注意开启防火墙的相关端口,不只是80,看自己项目开的是啥端口
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --reload
# 启动、停止nginx
cd /software/nginx/nginx-1.18.0/nginx/sbin/
./nginx
./nginx -s stop
./nginx -s quit
./nginx -s reload
Zookeeper安装配置
参考链接:Zookeeper QuickStart
1.解压文件夹
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
2.添加环境变量
vim /etc/profile
# ZooKeeper Env
export ZOOKEEPER_HOME=/software/zookeeper/apache-zookeeper-3.5.8-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
3.使环境变量生效
source /etc/profile
4.创建目录
cd /software/zookeeper/apache-zookeeper-3.5.8-bin
mkdir -m 777 data
mkdir -m 777 logs
5.修改配置
cd /software/zookeeper/apache-zookeeper-3.5.8-bin/conf
mv zoo_sample.cfg zoo.cfg
# 添加如下配置
dataDir=/software/zookeeper/apache-zookeeper-3.5.8-bin/data
dataLogDir=/software/zookeeper/apache-zookeeper-3.5.8-bin/logs
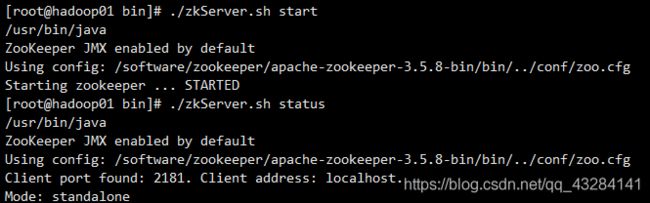
# 启动
cd /software/zookeeper/apache-zookeeper-3.5.8-bin/bin
./zkServer.sh start
# 查状态
./zkServer.sh status
# 服务启动完成后,可以使用 telnet 和 stat 命令验证服务器启动是否正常:
telnet 127.0.0.1 2181
stat
# 停止
./zkServer.sh stop
# 当stat命令报错时,在zkServer.sh中加入这个语句
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"

Kafka安装配置
参考文章:Kafka QuickStart
1. 解压文件夹
tar -zxvf kafka_2.13-2.6.0.tgz
2. 修改配置文件
vim /software/kafka/kafka_2.13-2.6.0/config/server.properties
# 修改如下配置
zookeeper.connect=49.232.218.99:2181
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://49.232.218.99:9092
# 启动
bin/kafka-server-start.sh -daemon config/server.properties
# 若启动报错,且是内存不足的问题,则:https://blog.csdn.net/weixin_40434637/article/details/101632747
# 修改kafka-server-start.sh文件
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
# 若jps没找到命令
yum install java-1.8.0-openjdk-devel.x86_64
ElasticSearch 安装配置
# 官网下载,解压到/software/elasticsearch目录下
tar -zxvf ......
# 创建data文件夹存放数据
cd /software/elasticsearch/elasticsearch-7.9.3
mkdir -m 777 data
# 添加非root用户(必须),elasticsearch不能以root用户启动
groupadd es
useradd -g es es-admin
passwd es-admin
chown -R es-admin:es /software/elasticsearch
# 若服务器内存太小,修改jvm参数
vim /software/elasticsearch/elasticsearch-7.9.3/config/jvm.options
# 改为以下,默认使1G:
-Xms256m
-Xmx256m
# 修改配置文件
vim /software/elasticsearch/elasticsearch-7.9.3/config/elasticsearch.yml
# 改为以下:
cluster.name: my-es
node.name: node-1
path.data: /software/elasticsearch/elasticsearch-7.9.3/data
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
xpack.security.transport.ssl.enabled: true
xpack.security.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: "Authorization"
# 下面可以启动:
# 切换到bin目录下:
cd /software/elasticsearch/elasticsearch-7.9.3/bin
# 切换为es-admin用户
su es-admin
./elasticsearch -d
设置密码:
./bin/elasticsearch-setup-passwords interactive
# 之后会设置一系列密码,建议都一致
# 登录==> elastic 密码
出现如下错误,见:
https://blog.csdn.net/Struggle99/article/details/102896821
![]()
sudo vim /etc/security/limits.conf
# 文件末尾加上:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
# 继续修改
sudo vim /etc/sysctl.conf
# 文件末尾加上:
vm.max_map_count=262144
# 使配置生效:
sysctl -p
ElasticSearch-Head_master安装
个人认为这个没必要装在服务端,安装个Chrome插件即可搞定
安装地址:https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm/
IK分词器安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
# 到plugins下创建一个ik文件夹
cd /software/elasticsearch/elasticsearch-7.9.3/plugins
mkdir -m 777 ik
cd ik
# 在这里解压
unzip elasticsearch-analysis-ik-7.9.3.zip
# 这里记得改用户
chown -R es-admin:es /software/elasticsearch
# 验证是否安装成功,到bin目录下执行以下,若出现ik则成功
./elasticsearch-plugin list
Kibana安装
Kibanan对于ElasticSearch来说只能一个数据展示和操作的媒介(类似Navicat),说实话挺占内存的,没有用时还是关闭吧!
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-9-3
若是下载慢(也救不了),则百度一些网盘下载吧!
# 解压到 /software/elasticsearch/kibana-7.9.3-linux-x86_64/c
cd config
vim kibana.yml
# 修改以下内容
# 配置端口
server.port: 5601
#配置Kibana的远程访问
server.host: 0.0.0.0
#配置es访问地址
elasticsearch.hosts: [“http://xxx.xxx.xxx.xxx:9200”]
#汉化界面
i18n.locale: "zh-CN"
# 开启防火墙的9200,5601端口,云服务器也注意开放安全组
# 记得切换用户 chown -R es-admin:es /software/elasticsearch
# 切换用户
su es-admin
cd bin
nohup ./kibana &
# 查看占用进程号
netstat -tunlp|grep 5601
访问:http://192.168.126.3:5601/ 进入控制台
MongoDB安装
下载:https://www.mongodb.com/try/download/community
官方文档:https://docs.mongodb.com/v4.0/reference/

# 在/software下安装
mkdir -m 777 mongodb
tar -zxvf mongodb-linux-x86_64-rhel70-4.0.22.tgz
# 编辑环境变量
vim /etc/profile
# MongoDB Env
export PATH=$PATH:/software/mongodb/mongodb-linux-x86_64-rhel70-4.0.22/bin
# 使环境变量生效
cd ~
source /etc/profile
# 创建data、log和conf目录
cd /software/mongodb/mongodb-linux-x86_64-rhel70-4.0.22
mkdir -m 777 data
mkdir -m 777 log
cd log
touch monodb.log
cd ../
mkdir -m 777 conf
cd conf
touch mongodb.conf
vim mongodb.conf
# 注意是yaml格式
net:
bindIp: 0.0.0.0
port: 27017
maxIncomingConnections: 100
security:
authorization: "enabled"
storage:
journal:
enabled: true
dbPath: "/software/mongodb/mongodb-linux-x86_64-rhel70-4.0.22/data"
engine: "wiredTiger"
wiredTiger:
engineConfig:
cacheSizeGB: 1.5
processManagement:
fork: true
systemLog:
destination: "file"
path: "/software/mongodb/mongodb-linux-x86_64-rhel70-4.0.22/log/mongodb.log"
logAppend: true
# 启动
./bin/mongod --config ./conf/mongodb.conf -- auth
# 关闭,千万别用kill,会造成数据损坏
./bin/mongod -shutdown --config ./conf/mongodb.conf
添加安全验证
# 控制台输入mongo进入MongoDB
use admin
db.createUser({
user: 'root', pwd: '123456879', roles: ['root']})
# 验证登录,返回1则成功
db.auth('root', '123456879')
# 为有关数据库添加密码
db.createUser({
user:'pcy',pwd:'123666',roles:[{
role:'readWrite',db:'recommender'}]})
Hadoop安装配置(单节点)
参考文章:
https://www.cnblogs.com/linkworld/p/10923798.html
各版本下载地址:https://archive.apache.org/dist/hadoop/common/
我这里选择3.3的版本
1.统一主机名
vim /etc/sysconfig/network
# 改为如下:
NETWORKING=yes
HOSTNAME=VM-8-6-centos
vim /etc/hosts
# 一般不需要改动
127.0.0.1 VM-8-6-centos VM-8-6-centos
127.0.0.1 localhost.localdomain localhost
127.0.0.1 localhost4.localdomain4 localhost4
vim /etc/hostname
#改为
VM-8-6-centos
2.免密登录
ssh-keygen
# 然后一路按enter键
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh 本机ip
# 发现输入yes后可以直接进行ssh连接则成功
3.配置各项配置文件
core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/software/hadoop/tempvalue>
property>
configuration>
hadoop-env.sh
export JAVA_HOME=/software/java/jdk1.8.0_271
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
hdfs-site.xml
这里要手动创建两个文件夹
/software/hadoop/dfs/name
/software/hadoop/dfs/data
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.rpc-bind-hostname>
<value>0.0.0.0value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/software/hadoop/dfs/namevalue>
property>
configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>0.0.0.0value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>${yarn.resourcemanager.hostname}:8190value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
yarn-env.sh
export JAVA_HOME=/software/java/jdk1.8.0_271
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>localhost:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>0.0.0.0:8191value>
property>
configuration>
mapred-env.sh
export JAVA_HOME=/software/java/jdk1.8.0_271
4.相关命令
# 格式化命令;执行命令前,需要将单节点(或集群)中的/data,/logs目录删除
bin/hdfs namenode -format
# 更多命令见参考文章
#
#
#
# jps 查看相关进程
NameNode对应的进程的端口对应HDFS的访问端口
ResourceManager对应的进程的端口对应Yarn的访问端口
# 查看进程对应的端口号
netstat -antlp
Spark配置(单节点)
下载地址:http://archive.apache.org/dist/spark/
我这里选择的是3.0.0版本对应Hadoop版本为3.2
#下载 解压
...
# 修改slaves配置
./conf/slaves.template ./conf/slaves
vim ./conf/slaves
# 在文件最后将本机主机名进行添加
VM-8-6-centos
# 修改spark环境配置
SPARK_MASTER_HOST=VM-8-6-centos #添加 spark master 的主机名
SPARK_MASTER_PORT=7077 #添加 spark master 的端口号
相关命令
# 启动集群
sbin/start-all.sh
# 启动后通过jps 查看名称为master的进程,根据进程拿到端口号,即可通过浏览器访问Spark的UI界面