Python 之 pandas数据处理(excel文件整合)
读取文件夹下面的所有文件
file_path=(r'D:\360极速浏览器下载\韩城服务区8月车流量\8.'+str(i)+'.xls')
Z1 = pd.read_excel(file_path)
import pandas as pd
import numpy as np
file_path=(r'D:\360极速浏览器下载\2020-3-20 服务区数据 文件\2020-3-20 服务区数据+文件\2019-12 所有数据汇总\所有收集数据汇总\2 韩城-卡口数据\韩城服务区8月车流量-原始数据\韩城服务区8月车流量\8.1.xls')
Z1 = pd.read_excel(file_path)
for i in range(2,32):
file_path=(r'D:\360极速浏览器下载\2020-3-20 服务区数据 文件\2020-3-20 服务区数据+文件\2019-12 所有数据汇总\所有收集数据汇总\2 韩城-卡口数据\韩城服务区8月车流量-原始数据\韩城服务区8月车流量\8.'+str(i)+'.xls')
print(file_path)
X = pd.read_excel(file_path)
Z1 = pd.concat([Z1,X])
print(Z1)
X = pd.read_excel(r'C:\Users\thinkpad\Desktop\服务区\韩城\韩城6月卡口.xlsx',sheet_name=1)
sheet_name=0 1 2 3 分别对应不同的sheet
concat函数
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)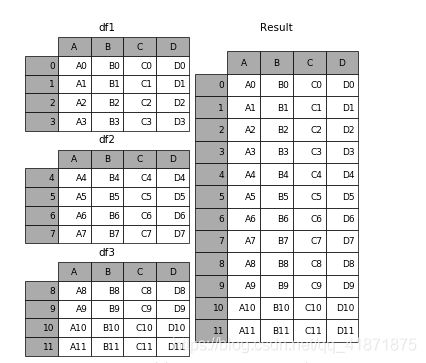
统计每个月每天每小时的车辆个数
year_sum=X.过车时间.dt.year.value_counts()
month_sum=X.过车时间.dt.month.value_counts()
day_sum=X.过车时间.dt.day.value_counts()
#print(day_sum)
print(day_sum[1])
print(type(day_sum[1]))
print(type(len(day_sum)))
num = 0
num1= 0
num1 = day_sum[1]+num1
x=X.iloc[num-day_sum[1]:num1,:]
x['hour']=x['过车时间'].dt.hour
m1=x.groupby(['hour']).count()
for i in range(1,len(day_sum)+1):
num = day_sum[i]+num
x1=X.iloc[num-day_sum[i]:num,:]
groups=x1.groupby(['hour']).count()
day_time=x1.groupby(['day']).count()
year_time=x1.groupby(['year']).count()
month_time=x1.groupby(['month']).count()
#print(groups['day'])
m1 = pd.concat([m1,groups])
print(m1['day'])
print(type(m1['day']))
print(m1)
#print(month_time)
writer1 = pd.ExcelWriter('面包车_Excel.xlsx')
m1.to_excel(writer1,'page_1',float_format='%.5f') # float_format 控制精度
writer1.save()
