Python使用requests和json一步步爬取豆瓣电影并提取自己想要的信息生成文件
经过一段时间的爬虫学习,结合自己所学的一些东西做一个小小的爬虫项目,写的不好的地方请见谅毕竟是菜鸟
目标
爬取豆瓣热门电视剧评分、名称、和连接并生成csv(可以用Excel打开)文件
准备工作
运行平台:windows10
IDE:PyCharm
requests、json库(使用pip进行安装)
第一步:分析要爬取的网页
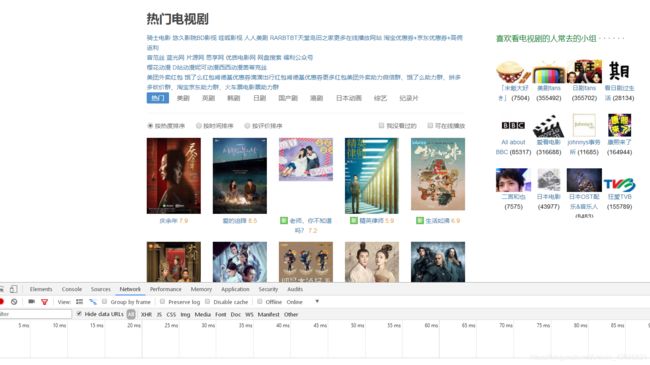
进入豆瓣热门电视剧选项按下F12点击Network刷新一下
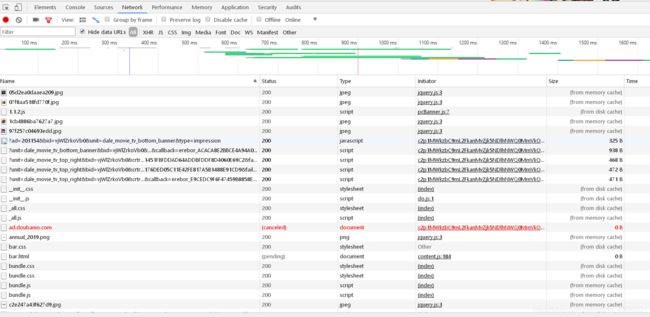
这时你会发现下面有许多东西,我也不知道是什么,这时点击Preview,然后去Name点下面的那些不知道的东西(反正信息不会在什么jpg、css、js文件里面),观察Preview里会出现我们想要的信息就是它了。(使用谷歌浏览器可以直接在Name搜寻Preview里的信息,360没有这个功能,只有一个个去找了)

就是这个然后我们点击Headers,在他的URL中找一段然后复制过去
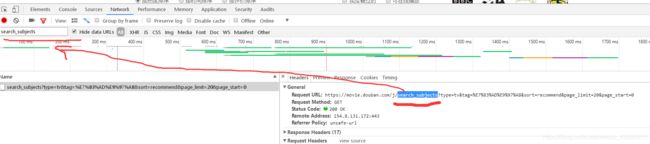
这时就会只剩下我们想要的页面了然后点击加载跟多观察变化
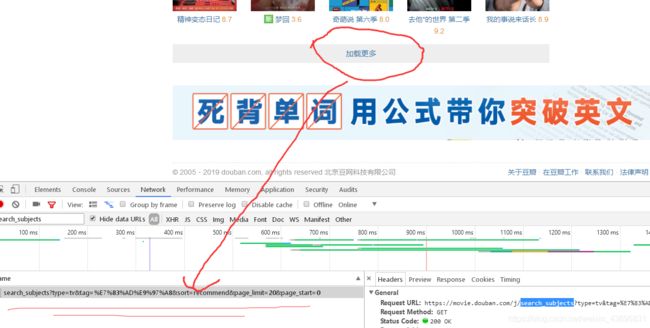
这时你会发现加载更多电视剧以后网页变的地方只有start=?这样我们可以开始写代码了!

第二步:爬取信息
我们就爬取前5页
导入库设置好url和headers信息
import json
import requests
url1="https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
header={
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) CriOS/56.0.2924.75 Mobile/14E5239e Safari/602.1"
}
注意start=后面一定是{} 不要写错了

然后通过循环来获取前5页的电视剧信息
num=0
while num<100:
url1=url.format(num)
resqonse=requests.get(url1,headers=header)
json_str=resqonse.content.decode()
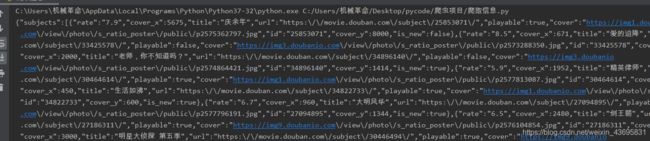
print(json_str)
num+=20
打印一下这个时候你会发现结果是json字符串就需要使用json.loads(json字符串)把json字符串转化为python类型
while num<100:
url1=url.format(num)
resqonse=requests.get(url1,headers=header)
json_str=resqonse.content.decode()
#print(json_str)
#num+=20
ret=json.loads(json_str)
print(ret)
num+=20
使用json.loads后打印一下对比结果
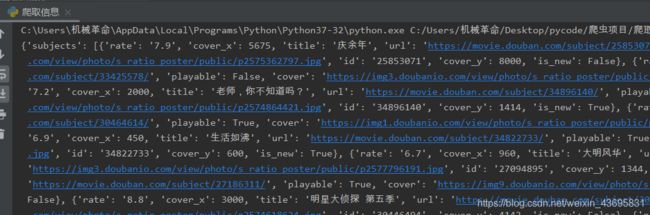
好看多了,然后继续完善代码
while num<100:
url1=url.format(num)
resqonse=requests.get(url1,headers=header)
json_str=resqonse.content.decode()
#print(json_str)
#num+=20
ret=json.loads(json_str)
print(ret)
num+=20
with open("pc1.txt","a",encoding='utf-8') as f:
f.write(json.dumps(ret,ensure_ascii=False))
ensure_ascii=False能够让中文现实为中文
json.dumps()把python转换为json字符串
然后在你的项目下就生成了一个pc1.txt的文档
点开

OK我们想要的东西全在里面了,下面对文件读取与使用正则表达式来提取我们想要的信息
先把爬取网页的所有代码放下:
import json
import requests
url="https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start={}"
header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
num=0
while num<100:
url1=url.format(num)
resqonse=requests.get(url1,headers=header)
json_str=resqonse.content.decode()
#print(json_str)
#num+=20
ret=json.loads(json_str)
print(ret)
num+=20
with open("pc1.txt","a",encoding='utf-8') as f:
f.write(json.dumps(ret,ensure_ascii=False))
第三步:提取信息
在当前py文件目录下新建一个py文件
然后用with open读取文件 "rt"是读取文件文件
使用正则表达式匹配我们想要的数据:评分、电视剧名称、连接。(正则表达式自己摸索)
然后打印出来看一下
import re
with open("pc1.txt","rt",encoding="utf-8")as f:
c= re.findall('"rate": "(.*?)"|"title": "(.*?)"|"url": "(.*?)"',f.read())
print(c)
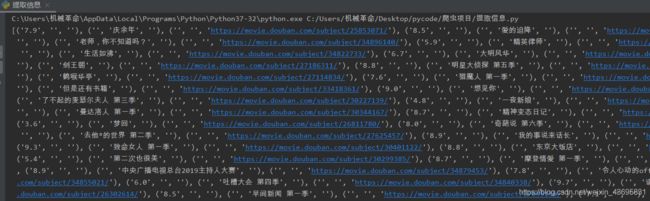
这时可以看见已经提取出了我们想要的三个信息现在需要把多余的空格去掉
with open("pc1.txt","rt",encoding="utf-8")as f:
c= re.findall('"rate": "(.*?)"|"title": "(.*?)"|"url": "(.*?)"',f.read())
list1 = []
list2 = []
list3 = []
count = 0
for i in c:
for j in i:
if j!="":
list1.append(j)
count+=1
if count==3:
list2.append(list1)
count=0
list1=[]
print(list2)
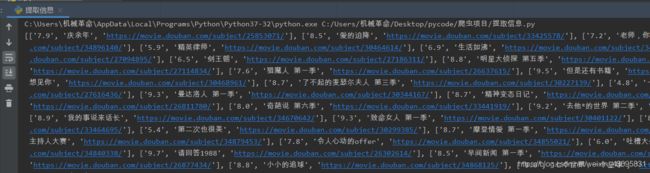
可以看见现在需要的信息成为列表中的列表元素了,但是我们要把提出来的元素存在CSV文件里面这样是不行的,还需要让列表里的列表元素变为字符串并且每个元素之间用逗号隔开,结尾要加\n实现写入一行后换行。
for i in list2:
i=",".join(i)
i=i+"\n"
list3.append(i)
print(list3)
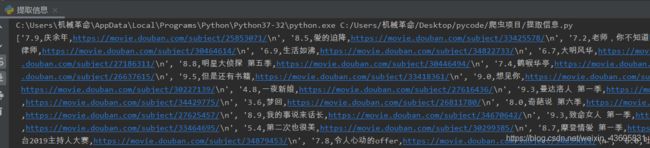
最后将列表里的字符串取出来,写入csv文件里面。
with open("pc1.csv",'wt')as f:
f.write("评分,电视剧名称,链接\n")
for k in list3:
f.write(k)
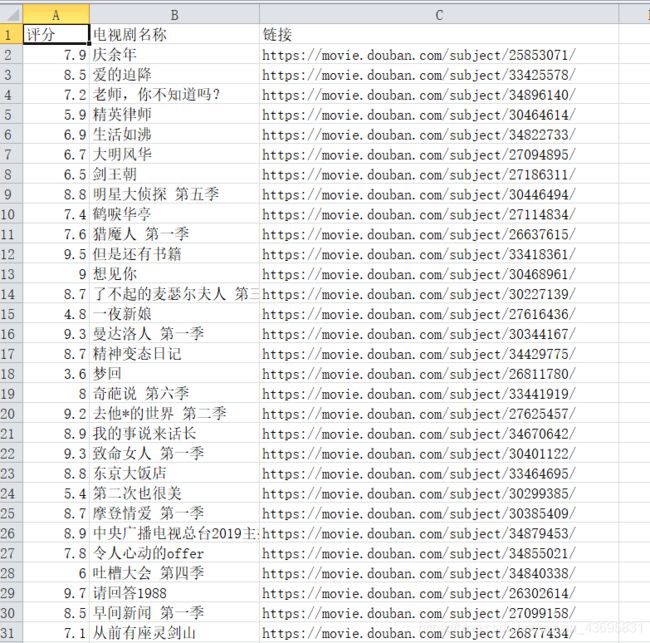
终于结束啦!下面附上提取信息的代码:
import re
with open("pc1.txt","rt",encoding="utf-8")as f:
c= re.findall('"rate": "(.*?)"|"title": "(.*?)"|"url": "(.*?)"',f.read())
list1 = []
list2 = []
list3 = []
count = 0
for i in c:
for j in i:
if j!="":
list1.append(j)
count+=1
if count==3:
list2.append(list1)
count=0
list1=[]
#print(list2)
for i in list2:
i=",".join(i)
i=i+"\n"
list3.append(i)
#print(list3)
with open("pc1.csv",'wt')as f:
f.write("评分,电视剧名称,链接\n")
for k in list3:
f.write(k)
欢迎大家点评~~