决策树与随机森林
目录
- 1 决策树
-
- (1)决策树的原理
- (2)决策树API与实例
- (3)决策树的优缺点
- 2 随机森林
-
- (1)集成学习方法
- (2)随机森林原理
- (3)为何要随机抽取训练集和有放回抽样
- (4)随机森林的API
- (5)pycharm连接服务器
-
- a 为项目配置远程解释器
- b 建立SFTP连接
1 决策树
(1)决策树的原理
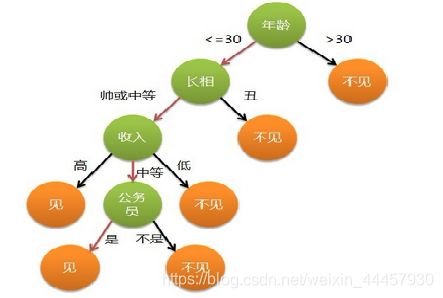
假如母亲要给女儿介绍男朋友,以下是母女之间的对话
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
如果用树状图来表示女儿的意愿,那么可以如下表示
再比如,银行拿到若干客户信息,要决定向哪些客户提供贷款
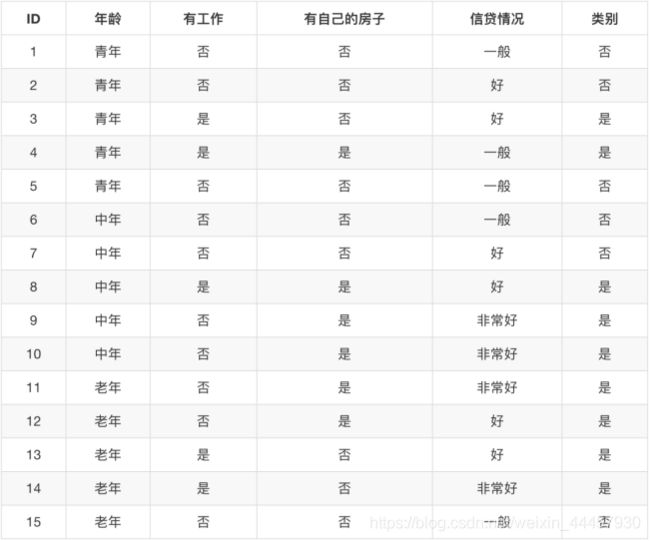
那么也可以用树状图来表示银行是否愿意给客户发放贷款
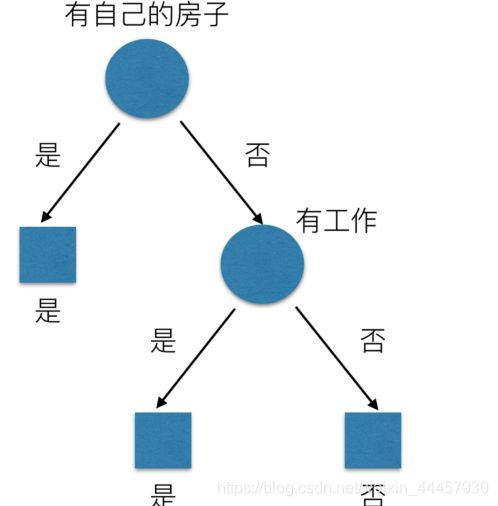
为何要把“是否有房”放在第一位?因为这个条件能消除最多的不确定性
“是否有房”,“是否有工作”这些都是特征,那么如何度量它们的能消除多少不确定性呢?
这里使用信息增益,所谓的信息增益,为得知特征X的信息而使得类Y的信息的不确定性减少的程度
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:

H(D)为初始信息熵的大小,H(D|A)表示当特征A给定之后的信息熵(条件熵)
若随机变量D表示银行是否贷款给客户,随机变量A表示客户的年龄,那么A的信息增益为

通过计算各个特征的信息增益,确定哪个特征该排在最前面。
使用信息增益选择特征的方法称为ID3算法。
除了ID3,常使用的算法还有
C4.5 信息增益比 最大的准则
CART 遍历给定特征的所有可能取值
现在的sklearn框架中的决策树,用的是CART算法,具体原理可以看《机器学习算法导论》王磊、王晓东著 P166-171
(2)决策树API与实例
决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None, max_features=None, random_state=None)
决策树分类器
criterion:默认是’gini’系数(基尼系数),也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
max_features:每次划分时考虑的最大特征数,默认是样本含有的特征总数(即 n_features),一般不用认为设置,为了方便理解后面的随机森林,所以在这里先列出来讲一下
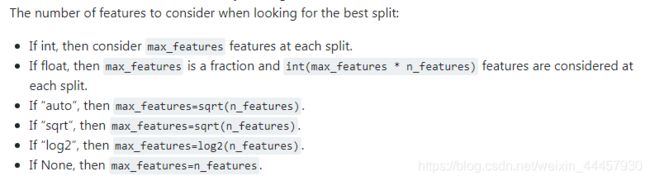
也就是说,每次划分数据时,未必考虑所有特征,而是只选择一部分特征进行考虑,选哪些,怎么选,则是随机的。
我们通过一个案例来说明上述API的使用
泰坦尼克号乘客信息
泰坦尼克号上的乘客,有人生还,有人死亡,titanic.txt中包含了乘客的若干特征,包括票的类别,存活与否,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。
乘坐班是指乘客班(1,2,3),是社会经济阶层的代表,其中age数据存在缺失。
若将乘客数据划分成训练集和测试集,根据训练集建立一个决策树模型,然后用判断测试集上的乘客是否生还,其步骤如下:
1、pd读取数据
2、选择有影响的特征,处理缺失值
3、进行特征工程,pd转换字典,特征抽取
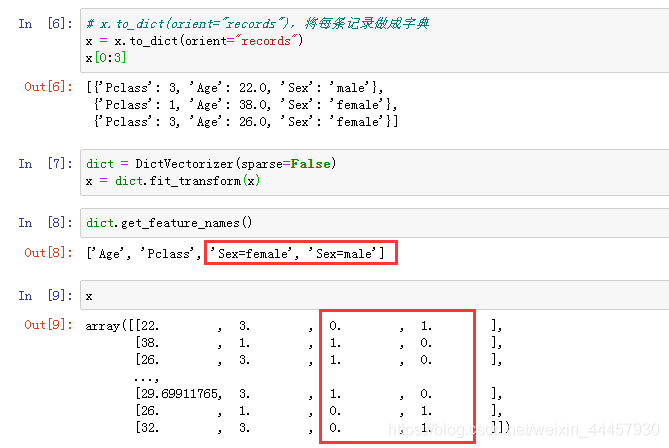
x_train.to_dict(orient=“records”),将每条记录做成字典
4、决策树估计器流程
下面使用jupyter notebook 来演示
首先导入相应的包和模块
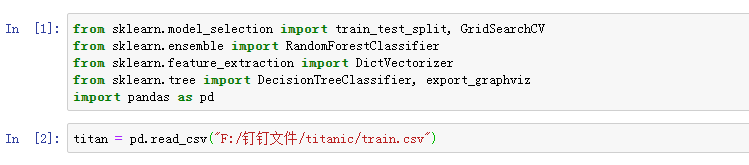
查看一下数据的前几行
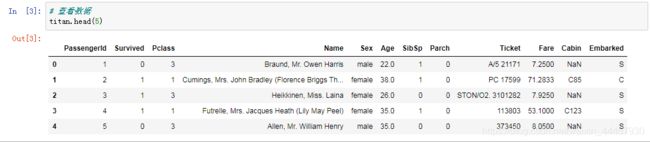
我们选择Pclass、Sex、Age作为特征值,Survived作为目标值
忽略警告,继续。
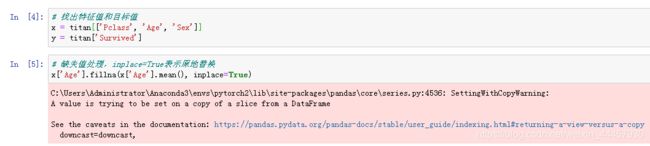
刚刚查看titan前5行的时候,可以看到 Sex 的数据不是数值型,而是字符串型,为了便于分析,需要将其转化为one-hot编码,在转化之前,需要将数据的每一条记录转化为字典,这里使用to_dict(orient=“records”)方法
然后分割数据

用训练数据去拟合决策树模型,然后将模型放到测试集上去跑

如果需要做推断的话,就用 dec.predict(x_test)
还可以把决策树的结构导出为dot文件

这里不能导出为png格式的图片,否则打不开,只能导出为dot文件。
将tree.dot传到linux的./root目录下,然后安装可视化工具Graphviz,命令为
yum install 'graphviz*' --skip-broken
然后将其转化成png格式的图片
dot -Tpng tree.dot -o tree.png
之后在相应的目录下,就会出现名为“tree.png”的图片
将其打开,可以看到非常复杂

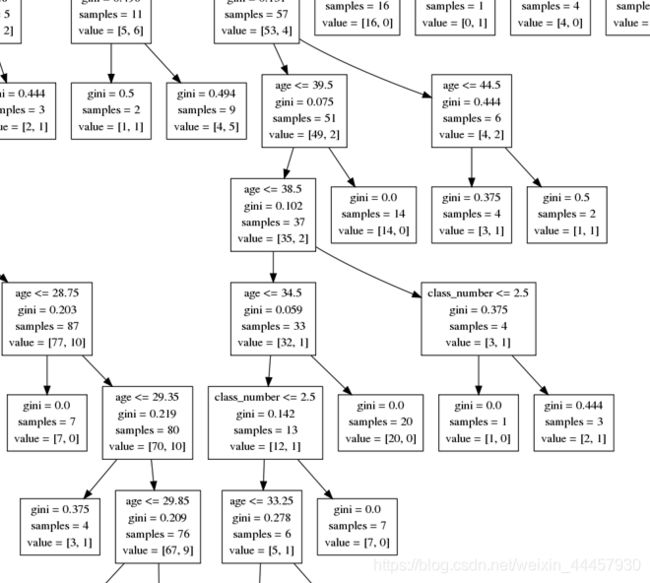
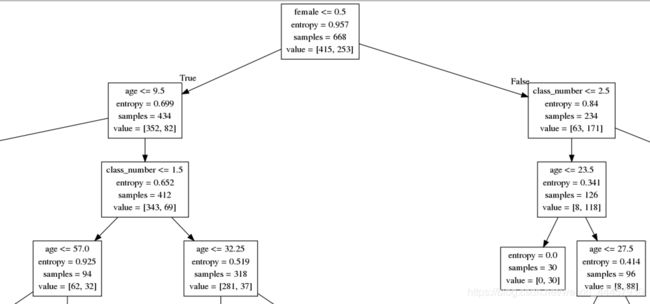
图中每一个方格,第一个若不是等号,则为判断条件,gini表示基尼系数,samples表示样本数,value表示根据条件,左右子树的样本树。
最上面的方格如下
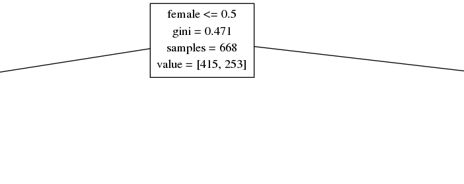
可以看到,用female<=0.5作为划分依据,可是人的性别,没有0.5之说,因此决策树的划分过细。
也可以指定信息增益作为特征排序的依据,于此同时,指定树的最大深度为5,代码如下

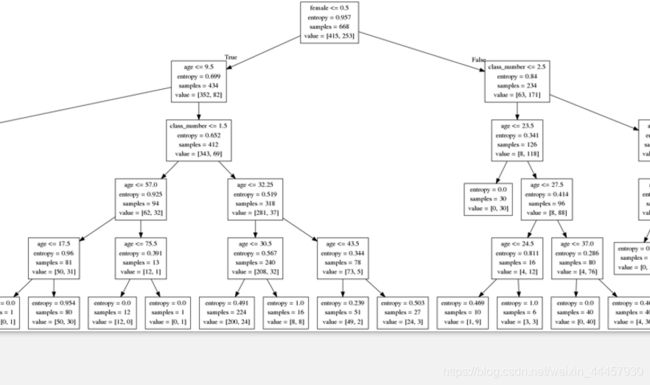
可以看到最深只有五层
放大之后,可以看到方格中有entropy
也可以将其转为jpg文件
dot -Tjpg tree.dot -o tree.jpg
(3)决策树的优缺点
优点:
简单的理解和解释,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化,
缺点:
有些树过于复杂,导致在过拟合而无法推广
决策树可能不稳定,因为数据的小变化可能会导致完全不同的树
被生成
2 随机森林
(1)集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后综合得到预测结果,因此优于任何一个单分类的做出预测。
(2)随机森林原理
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终结果会是True.
假设训练集有N个样本,M个特征,先要训练一片有k棵决策树的随机森林,每棵树的建立过程如下:
1 从N个样本中,有放回地抽N次,形成N个样本的子训练集,用这N个样本建立决策树
2 每次划分时,从M个输入特征里随机选择m个特征,这里是不放回地选择,划分数据的时候,只考虑这m个特征,一般m远远小于M
每次抽取训练集,都是从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个子训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
上述过程循环k次,就得到了一片随机森林。
(3)为何要随机抽取训练集和有放回抽样
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
(4)随机森林的API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None)
随机森林分类器
n_estimators:integer,optional(default = 10) 森林里的树木数量,经验值:120, 200, 300, 500, 800, 1200,这个参数经常由调参决定
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
bootstrap:boolean,可选(default = True)是否在构建树时使用放回抽样,否则使用整个训练集来训练每一棵树
max_features:每次划分时考虑的特征数

在前面讲述决策树时,有一个参数是 max_features ,随机森林在每次划分样本时,从M个输入特征里随机选择m个特征,这个m就是通过max_features 设置,在建立每棵树时,再传递给决策树的API
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pandas as pd
titan = pd.read_csv("titanic/train.csv")
# 获取特征值和目标值
x = titan[['Pclass', 'Age', 'Sex']]
y = titan['Survived']
# 缺失值处理,inplace=True表示原地替换
x['Age'].fillna(x['Age'].mean(), inplace=True)
# 特征工程
dict = DictVectorizer(sparse=False)
x = x.to_dict(orient="records")
x = dict.fit_transform(x)
# 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 用随机森林预测
rf = RandomForestClassifier()
# 网格搜索与交叉验证
param = {
"n_estimators": [120, 200, 300, 500, 800, 1200],
"max_depth": [5, 8, 15, 25, 30]}
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看最佳的参数组合:", gc.best_params_)
上述由于要进行交叉验证,若在本地执行则非常消耗时间,因此放到服务器上运行,输出
准确率: 0.7802690582959642
查看最佳的参数模型: {
'max_depth': 5, 'n_estimators': 500}
注意,随机森林不像决策树一样能输出树的结构,因为随机森林太多,结构无法输出。
(5)pycharm连接服务器
首先要用连接工具连上服务器,比如可以用Xshell
a 为项目配置远程解释器
File -> Settings
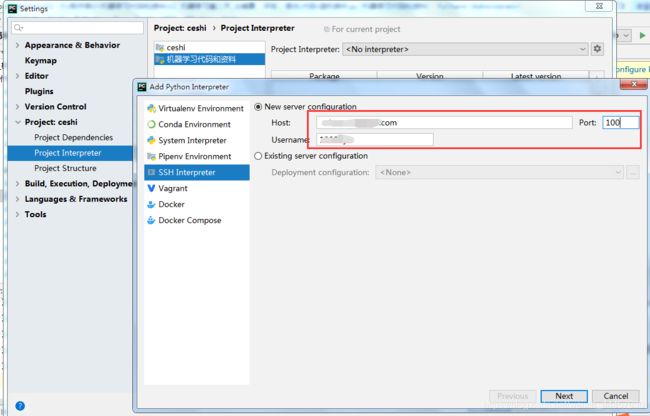
输出地址和用户名、端口号,然后Next
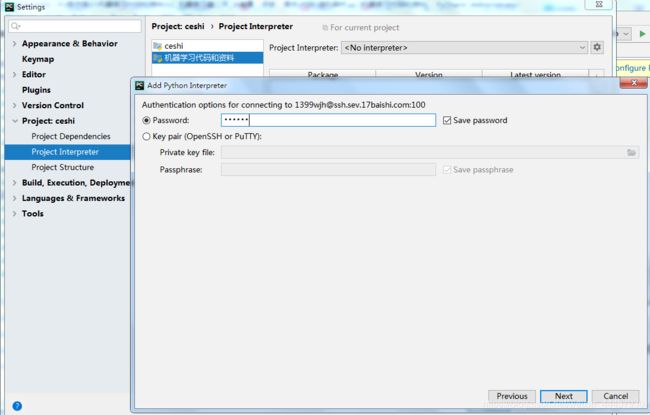
输入密码
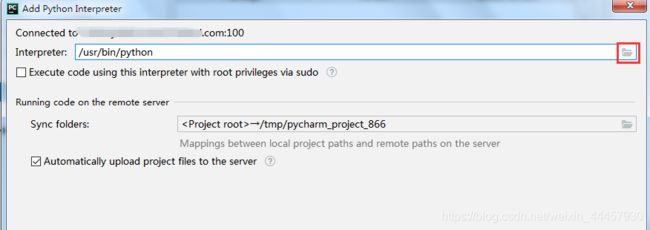
找解释器,并设置映射
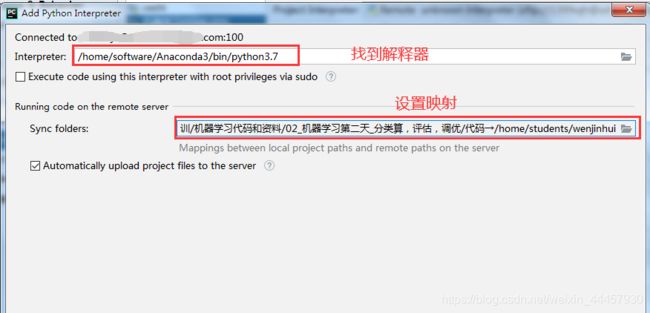

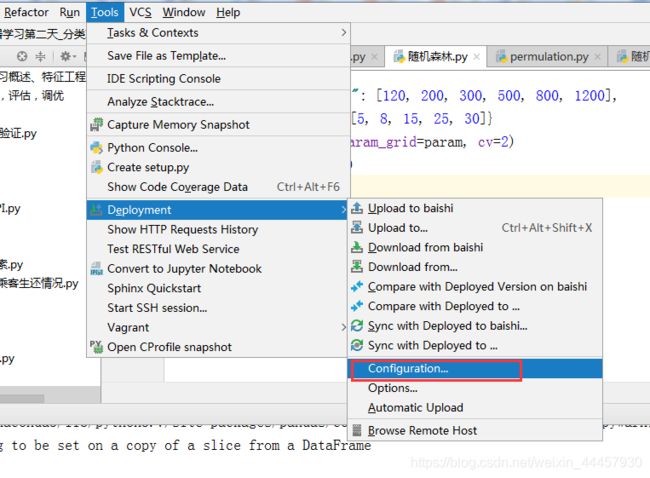
b 建立SFTP连接
Tools -> Deployment -> Configuration
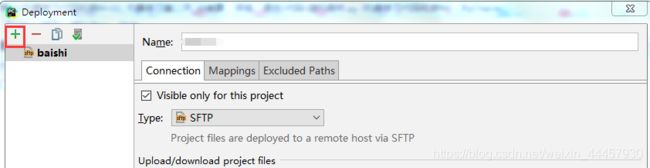
在弹出的对话框中,点击右上角的加号
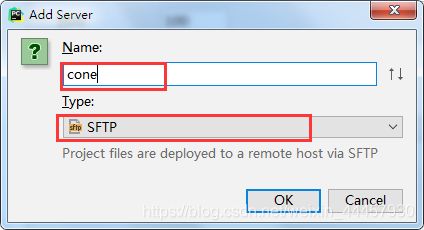
填上连接接名称并选择类型
填写服务器地址和端口号,并点击右边的测试 SFTP 连接
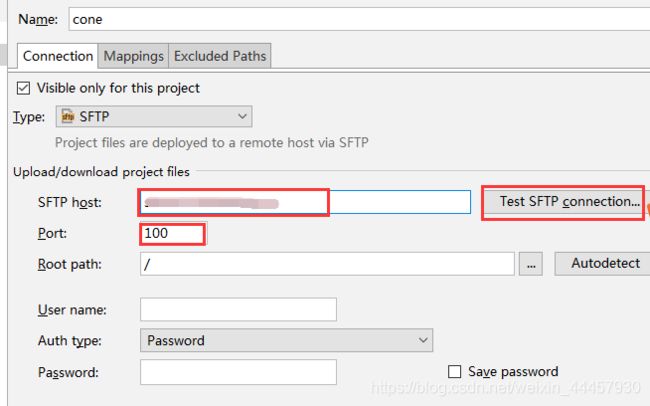
填写用户名和密码
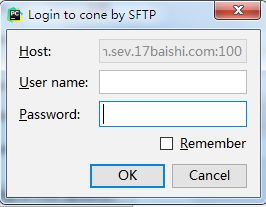
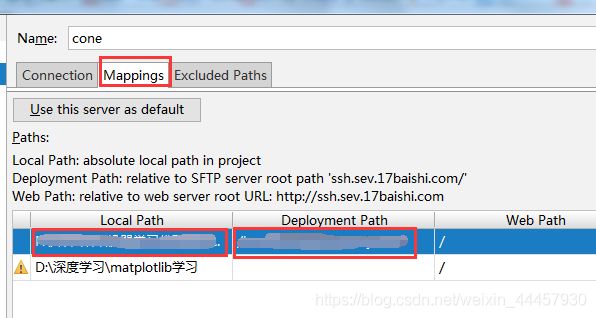
连接成功后,打开 Mapping 选项卡,建立本地路径和服务器路径的映射
接下来只要在本地文件夹上新建文件,就会被自动上传到服务器相应的目录
也可以把本地已有的文件传到服务器
Deployment -> Upload to XXX(连接名称)
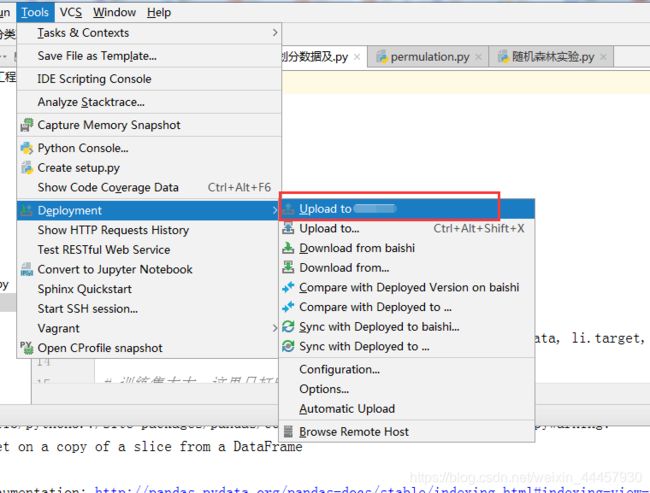
也可以把已有文件上传到服务器,上传之后才能在服务器运行。
Tools->Deployment->Upload to XXX