变分自编码器入门(Variational Auto Encoder, VAE)
目录
- 1学习体会
- 2变分的意义
- 3流程及存在的“对抗”
-
- 3.1流程
- 3.2Reparametrization
- 3.3“对抗”
- 4改进
- 5参考文献
1学习体会
如下图,我们假设头像图片的有三个特征 X = ( x 1 , x 2 , x 3 ) X=(x_1,x_2,x_3) X=(x1,x2,x3),(比如说 x 1 x_1 x1代表脸型, x 2 x_2 x2代表眼睛, x 3 x_3 x3代表嘴巴,这里选三个只是方便理解),确定值描述就是中间的坐标轴,每个特征都有确定的值;但在VAE中每个固定值是不存在的,而是以概率密度的形式存在。 X X X为隐变量 Z Z Z可能的值的一个。换而言之, X X X为隐变量 Z Z Z在低维的映射。所谓道生一,一衍万物,不外如是。一组确定的值限制了我们的想象空间,通过隐函数的空间,大千变化才有了可能。以素描照片为底板,我们利用VAE可以生成不同眼睛、脸型和嘴巴的头像。
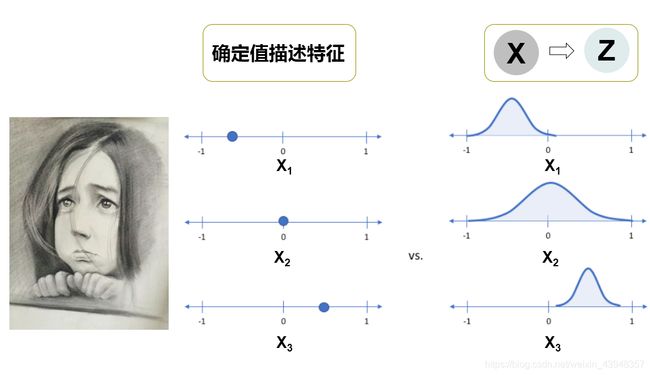
所谓隐函数参照这里。事实上我们只能看到 X X X, Z Z Z是不可知的。不要慌,知道了 X X X我们可以推求 Z Z Z的概率,即 p ( z ∣ x ) p\left( {z|x} \right) p(z∣x)。
p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p ( x ) p\left( {z|x} \right) = \frac{ {p\left( {x|z} \right)p\left( z \right)}}{ {p\left( x \right)}} p(z∣x)=p(x)p(x∣z)p(z)
但是数学上求解 p ( x ) = ∫ p ( x ∣ z ) p ( z ) d z p\left( x \right) = \int {p\left( {x|z} \right)p\left( z \right)dz} p(x)=∫p(x∣z)p(z)dz着实困难,因为对隐变量积分,尤其是高维的隐变量,大多数时候都是无法计算的【2】。求积分的方法一种是利用蒙特卡洛求积分,另一种就是要用到叫变分的东西了。
2变分的意义
这里不细述变分的数学含义(我也不懂),而倾向于变分怎么在VAE中发挥作用。精确不行就逼近,定义一个函数 q ( z ∣ x ) q\left( {z|x} \right) q(z∣x)无限逼近 p ( z ∣ x ) p\left( {z|x} \right) p(z∣x),如果我们可以定义q(z|x)的参数,使其非常类似于p(z|x),那么上述的积分问题就可以迎刃而解了。 q ( z ∣ x ) q\left( {z|x} \right) q(z∣x)也就是所谓变分分布。它应满足下面的条件,
min K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) \min KL\left( {q\left( {z|x} \right)||p\left( {z|x} \right)} \right) minKL(q(z∣x)∣∣p(z∣x))
其中,KL为KL散度,这个指标在熵理论中表述两个分布的接近程度,KL值越小,所谓的逼近就越成立,这也是我们VAE的一个约束条件。
言归正传,为了优化 l n ( P ( X ) ) ln(P(X)) ln(P(X))的最大似然,【2】给出了两种推导方法来解释如何将观测值的对数似然转换成下式,
max E q ( z ∣ x ) log p ( x ∣ z ) − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ‾ \max \underline{ {E_{q\left( {z|x} \right)}}\log p\left( {x|z} \right) - KL\left( {q\left( {z|x} \right)||p\left( z \right)} \right)} maxEq(z∣x)logp(x∣z)−KL(q(z∣x)∣∣p(z))
近一步转换为LOSS函数,
L ( x , x ^ ) + ∑ K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ( ∗ ) {\mathcal{L}}\left( {x,\hat x} \right) + \sum{KL\left( { {q}\left( {z|x} \right)||p\left( z \right)} \right)}\tag{$*$} L(x,x^)+∑KL(q(z∣x)∣∣p(z))(∗)
其中,第一项是给定隐变量时的条件分布的似然,第二项是变分分布和真实分布之间的KL散度。如果没有 KL 项,那VAE就等价于原始的AE模型。
3流程及存在的“对抗”
3.1流程
假设 x 1 x_1 x1, x 2 x_2 x2,…, x i x_i xi的先验分布均服从正态分布 N ( μ i , σ i ) \mathcal{Ν}~(\mu_i,\sigma_i) N (μi,σi)。那么 X X X就可以用 μ i \mu_i μi和 σ i \sigma_i σi矢量化表示。但都默认 x i x_i xi之间是独立不相关的,也就是说协方差只保存了对角线上的元素。这个假设一方面简化了计算,另一方面破坏了数据的结构,如各种相关性。下文先按简单的维度独立进行。

3.2Reparametrization
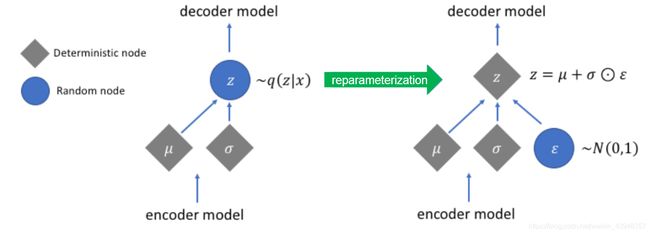
随机抽取参数以生成 x ^ \widehat{x} x 有一个技巧,即抽样的再参数化技巧(Reparametrization)。从一个单位正态分布 N ( 0 , 1 ) \mathcal{Ν}~(0,1) N (0,1)中随机取样,然后通过潜在分布的平均值偏移来移动随机取样的平均值,并通过潜在分布的方差方差来缩放它。
z ∼ q θ ( z ∣ x ) = N ( z ; μ θ ( x ) , σ θ ( x ) ) z \sim q_\theta (z \vert x) = \mathcal{N}(z; \mu_\theta (x), \sigma_\theta(x)) z∼qθ(z∣x)=N(z;μθ(x),σθ(x))
等价于
z = μ θ ( x ) + σ θ ( x ) ⋅ ϵ z = \mu_\theta (x) + \sigma_\theta (x) \cdot \epsilon z=μθ(x)+σθ(x)⋅ϵ
3.3“对抗”
借助文献【4】,我们审视下不同条件约束下,即公式( ∗ * ∗)不同项作为约束条件,隐空间 Z Z Z的分布的结果。
如下图,左图只关注重建损失的意味着我们得到了与 X X X一致的分布 X ^ \hat{X} X^;空间中存在着大量空白,这不意外,因为 X X X是 Z Z Z低维空间的体现,我们的输出结果只是优化了条件分布(重复了输入)。
如果我们只关注于确保先验分布 p ( z ) p\left( z \right) p(z)和潜在分布 q ( z ∣ x ) q\left( {z|x} \right) q(z∣x)相似(公式( ∗ * ∗)第二项,即KL散度损失项),我们最终会使用相同的高斯分布来描述每一个观察结果,我们随后从该分布中采样来描述可视化的潜在维数。这不可避免将每一次观察都视为具有相同的特征;换句话说,我们没有描述原始数据。
只有公式( ∗ * ∗)中的两项同时被优化时,如最右图,VAE才能描述一个观察的潜在状态,且分布接近先验,但在必要时偏离,从而保留了输入的显著特征。

由上述分析可知,公式( ∗ * ∗)中的两项起的作用不同,一项以保存局部特征,另一项以保存整体分布。那么顺理成章之中,我们可以调节公式( ∗ * ∗)的权重来匹配我们的目的。即Loss函数可进行如下转换。
加入权重 β \beta β后,
L ( x , x ^ ) + β ∑ K L ( q j ( z ∣ x ) ∣ ∣ p ( z ) ) {\mathcal{L}}\left( {x,\hat x} \right) + \beta\sum\ {KL\left( { {q_j}\left( {z|x} \right)||p\left( z \right)} \right)} L(x,x^)+β∑ KL(qj(z∣x)∣∣p(z))

4改进
由于VAE的向量化输入导致数据的空间相关性缺失,参考文献【1】将一维的向量化输入整理成了一个矩阵输入,以保持图片行列像素之间的相关性,但潜在变量的先验仍然采用单一高斯函数描述。参考文献【5】采用了高斯混合模型的假设。
本文知识总结了对VAE的一些粗浅认知,对于如何应用尚未实操,不足之处,恳请多多指正。
5参考文献
【1】A, J. L. , A, H. Y. , B, J. G. , A, D. K. , A, L. W. , & A, S. W. , et al. (0). Matrix-variate variational auto-encoder with applications to image process. Journal of Visual Communication and Image Representation, 67.
【2】https://zhuanlan.zhihu.com/p/57574493
【3】https://wizardkingz.github.io/VAE/
【4】https://www.jeremyjordan.me/variational-autoencoders/
【5】https://openaccess.thecvf.com/content_ICCV_2019/papers/Yang_Deep_Clustering_by_Gaussian_Mixture_Variational_Autoencoders_With_Graph_Embedding_ICCV_2019_paper.pdf