精度(precision),召回率(recall),map
目标检测中经常会见到precision,recall,map三个指标用来评估一个模型的优劣,当然在很多其他的应用中也可以看到这三个指标的具体应用;因此很有必要对这三个指标进行详细的了解。在介绍这三个指标之前有必要先了解几个基本的术语:True positives,True negatives,False positives,False negative。视频请戳
大雁和飞机
假设现有一个测试集,测试集中仅包含大雁和飞机两种目标,如图所示:

假设分类的目标是:取出测试集中所有飞机图片,而非大雁图片
现做如下定义:
True positives: 飞机的图片被正确识别为飞机
True negatives:大雁的图片被识别为大雁
False positives:大雁的图片被识别为飞机
False negatives:飞机的图片被识别为大雁
假设分类系统使用上述假设识别出了四个结果,如下图所示:

识别为飞机的图片中:
True positives:有三个,画绿色框的飞机
False positives:有一个,画红色框的大雁
识别为大雁的图片中:
True negatives:有四个,这四个大雁的图片被识别为大雁
False negatives:有两个,这两个飞机被识别为大雁
Precision与Recall
Precision其实就是识别为飞机的图片中,True positives所占的比率:
precision = tp / (tp + fp) = tp / n
其中n表示(True positives + False positives),也就是系统一个识别为飞机的图片数。该例子中,True positives为3,False positives为1,所以precision = 3 / (3 + 1) = 0.75,意味着识别为飞机的图片中,真正为飞机的图片占比为0.75。
Recall是被正确识别出来飞机个数与测试集中所有真正飞机个数的比值:
recall = tp / (tp + fn)
Recall的分母是(True positives + False negatives),这两个值的和,可以理解为一共有多少张真正的飞机图片。该例子中,True positives为3,False negatives为2,那么recall的值是3 / (3 + 2) = 0.6;即所有飞机图片中,0.6的飞机被正确识别为飞机。
调整阈值
当然对某一个具体的模型而言precision和recall并不是一成不变的,而是随着阈值的改变而改变的。当阈值以某一步伐从0变化到1,那么就可以得到关于precision和recall生成的曲线,具体示意图如下:
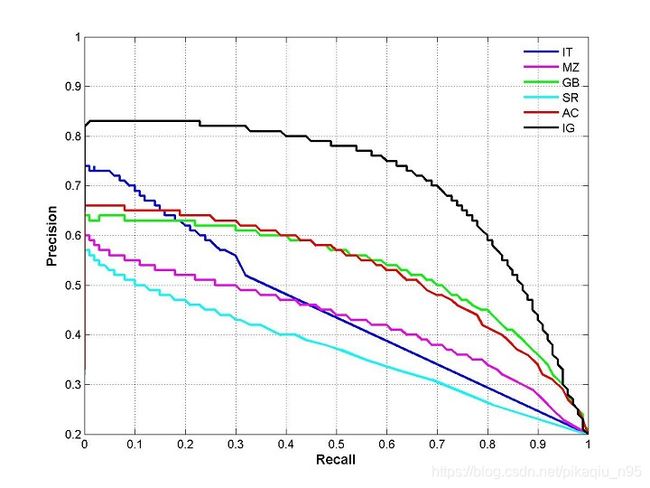
上图为一个pr曲线的例子,并不表示上面例子的pr曲线结果,从pr曲线可以看到precision和recall是相反的,因而在实际项目当中需要根据具体的情况来选取合适的阈值。为了更好的评估模型的性能,对于单个类别来说,pr曲线所包含的面积用来作为该类别的平均精度(average precision,ap);那么对于多个类别的模型而言,通常通过求各个类别的平均ap值作为其性能评估,即(mean average precision,map);实现程序如下,该程序摘自yolov3:
def ap_per_class(tp, conf, pred_cls, target_cls):
""" Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (list).
conf: Objectness value from 0-1 (list).
pred_cls: Predicted object classes (list).
target_cls: True object classes (list).
# Returns
The average precision as computed in py-faster-rcnn.
"""
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes = np.unique(target_cls)
# Create Precision-Recall curve and compute AP for each class
ap, p, r = [], [], []
for c in tqdm.tqdm(unique_classes, desc="Computing AP"):
i = pred_cls == c
n_gt = (target_cls == c).sum() # Number of ground truth objects
n_p = i.sum() # Number of predicted objects
if n_p == 0 and n_gt == 0:
continue
elif n_p == 0 or n_gt == 0:
ap.append(0)
r.append(0)
p.append(0)
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum()
tpc = (tp[i]).cumsum()
# Recall
recall_curve = tpc / (n_gt + 1e-16) #计算召回率
r.append(recall_curve[-1])
# Precision
precision_curve = tpc / (tpc + fpc) #计算准确度
p.append(precision_curve[-1])
# AP from recall-precision curve
ap.append(compute_ap(recall_curve, precision_curve)) #计算pr曲线下面的面积
# Compute F1 score (harmonic mean of precision and recall)
p, r, ap = np.array(p), np.array(r), np.array(ap)
f1 = 2 * p * r / (p + r + 1e-16)
return p, r, ap, f1, unique_classes.astype("int32")
def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves.
Code originally from https://github.com/rbgirshick/py-faster-rcnn.
# Arguments
recall: The recall curve (list).
precision: The precision curve (list).
# Returns
The average precision as computed in py-faster-rcnn.
"""
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([0.0], precision, [0.0]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) #因为precision精度为纵轴,理解为量化计算每个小间隔的高度
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0] #recall为横轴,理解为量化计算每个小间隔的宽度
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) #通过量化以后的precision和recall,计算各个小的近似小矩形的面积,然后相加就得到了该类别的ap值
return ap
test调用
def evaluate(model, path, iou_thres, conf_thres, nms_thres, img_size, batch_size):
model.eval()
# Get dataloader
dataset = ListDataset(path, img_size=img_size, augment=False, multiscale=False)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=False, num_workers=1, collate_fn=dataset.collate_fn
)
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
labels = []
sample_metrics = [] # List of tuples (TP, confs, pred)
for batch_i, (_, imgs, targets) in enumerate(tqdm.tqdm(dataloader, desc="Detecting objects")):
# Extract labels
labels += targets[:, 1].tolist()
# Rescale target
targets[:, 2:] = xywh2xyxy(targets[:, 2:])
targets[:, 2:] *= img_size
imgs = Variable(imgs.type(Tensor), requires_grad=False)
with torch.no_grad():
outputs = model(imgs)
outputs = non_max_suppression(outputs, conf_thres=conf_thres, nms_thres=nms_thres)
sample_metrics += get_batch_statistics(outputs, targets, iou_threshold=iou_thres)
if len(sample_metrics) == 0:
return np.array([]),np.array([]),np.array([]),np.array([]),np.array([])
# Concatenate sample statistics
true_positives, pred_scores, pred_labels = [np.concatenate(x, 0) for x in list(zip(*sample_metrics))]
precision, recall, AP, f1, ap_class = ap_per_class(true_positives, pred_scores, pred_labels, labels)
return precision, recall, AP, f1, ap_class