python外星人入侵游戏代码_权力的游戏收官,我用Python致敬这场血雨腥风(附代码)...
 标星★公众号,第一时间获取最新研究
标星★公众号,第一时间获取最新研究
作者:Rocky Kev
编译:公众号编辑部
近期原创文章:
♥ 基于无监督学习的期权定价异常检测(代码+数据)
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ 深入研读:利用Twitter情绪去预测股市
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 利用深度学习最新前沿预测股价走势
♥ 一位数据科学PhD眼中的算法交易
♥ 基于RNN和LSTM的股市预测方法
♥ 人工智能『AI』应用算法交易,7个必踩的坑!
♥ 神经网络在算法交易上的应用系列(一)
♥ 预测股市 | 如何避免p-Hacking,为什么你要看涨?
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市
Game of Thrones
在这篇文章中,我们将使用Selenium库实现web自动化,使用BeautifulSoup库实现web抓取,并使用csv模块生成报告。
所有的例子都会用到权力的游戏。
你不需要任何Python经验就可以做到这一点。我们将解释代码。

Web自动化
使用Python可以做的最酷的事情之一是web自动化。
例如,你可以编写一个Python脚本:
1、打开浏览器
2、自动访问特定网站
3、登录该站点
4、转到网站的另一部分
5、查找最新的博文
6、打开那篇博文
7、提交一条评论说:“写得好!666”
8、最后退出该网站
这似乎并不难做到。这需要什么,20秒?
如果你不得不一遍又一遍地这样做,你会发疯的。
例如,如果您的暂存网站仍在开发中,其中有100篇博客文章,并且你希望在每个页面上都发布一条评论来测试其功能,那么该怎么办?
100篇博客文章* 20秒 = 大约33分钟
如果有多个测试阶段,你不得不重复测试6次,结果会怎样?
web自动化的其他用例包括:
可能希望在站点上自动创建帐户。
你可能希望从在线课程中从头到尾运行一个机器人。
你可能需要推送100个机器人,使用单个脚本在你的站点上提交表单。
我们要做什么
在这一部分中,我们将自动登录《权力的游戏》粉丝网站。
当你不得不浪费时间登录westeros.org,/ r / freefolk subreddit,winteriscoming.net以及所有其他粉丝网站时,你不讨厌吗?

使用此模板,你可以自动登录各种网站!
现在来看《权力的游戏》。
代码
你需要安装Python 3、Selenium和Firefox web驱动程序才能开始。
https://rockykev.com/how-to-automate-form-submissions-logins/



分解代码
首先,导入Selenium库来帮助完成繁重的工作。
再导入了时间库,因此在每个操作之后,它将等待x秒。添加等待允许页面加载。

Selenium是什么?
Selenium是用于web自动化的Python库。Selenium开发了一个API,因此第三方作者可以开发web驱动程序来与浏览器通信。这样,Selenium团队可以专注于他们的代码库,而另一个团队可以专注于中间件。
例如:
Chromium团队为Selenium开发了自己的webdriver,称为chromedriver。
Firefox团队为Selenium开发了自己的web驱动程序geckodriver。
Opera团队为Selenium开发了自己的web驱动程序operadriver。

在上面的代码中,要求Selenium“将Firefox设置为首选浏览器”,“将此链接传递给Firefox”,最后“关闭Firefox”。 用geckodriver来做那件事。
登录到网站
为了便于阅读,我们编写了一个单独的函数来登录每个站点,以显示我们正在创建的模式。

如果我们把它进一步分解,每个函数都有以下元素。
我们告诉Python:
1、访问特定的页面
driver.get (“https://asoiaf.westeros.org/index.php?/login/”)
2.、寻找登录框
* 如果有,请清除文本
* 提交我的变量

3、寻找密码框
* 如有文本,请清除
* 提交我的变量
4、寻找提交按钮,然后单击它
注意:每个网站都有不同的方法来找到用户名/密码和提交按钮。你需要做一些搜索。
如何找到任何网站的登录框和密码框
Selenium库提供了许多方便的方法来查找网页上的元素。这里有一些我们喜欢用的:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_class_name
有关整个列表,请访问Selenium Python文档以查找元素。
https://selenium-python.readthedocs.io/locating-elements.html
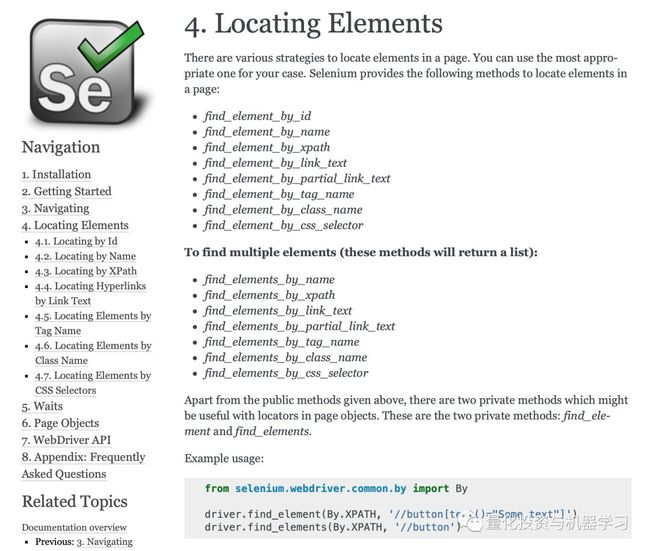
以asoiaf.westeros.com为例,当我们检查元素时,它们都有IDs。
https://asoiaf.westeros.org/index.php?/login/
运行代码
网络抓取
在这篇文章中,我们将探讨web-scrapping。
整体的过程是:
1、我们会让Python访问一个网页。
2、然后我们将用BeautifulSoup解析该页面。
3、然后设置代码以获取特定的数据。
例如:你可能想获取所有h1标记,或所有链接,或页面上的所有图像。
Web抓取的其他一些用例:
1、你可以抓取网页上的所有链接。
2、你可以在一个论坛里抓取所有帖子标题
3、你可以用它来抓取纳斯达克的每日市值,而无需访问该网站。
4、你可以使用它来下载没有“全部下载”的网站中的所有链接。
简而言之,web抓取允许你通过Python自动抓取web内容。
总的来说,这是一个非常简单的过程。
Web抓取图像的挑战
我的目标是将我web抓取的内容转化为抓取图像。
虽然web抓取链接、正文和标题非常简单,但是web抓取图像要复杂得多。
作为一个web开发人员,在一个页面上托管多个全尺寸的图像会降低整个页面的速度。相反,使用缩略图,然后只有在单击缩略图时才加载全尺寸图像。
例如:想象一下,如果我们的网页上有20个1兆字节的图像。登陆后,访客必须下载20兆字节的图像!更常见的方法是生成20个10kb的缩略图。现在,你的有效负载只有200kb,或者大约是大小的1/100 !
那么,这与web抓取图像和本文有什么关系呢?
这意味着编写一个通用的代码块对于每个网站都是非常困难的。网站采用各种不同的方法将缩略图转换成全尺寸图像,这使得创建“一码通”的模型成为一项挑战。
请注意,在其他站点上尝试该代码需要进行重大修改。
Python和权力的游戏
本文的目标是收集我们最喜欢的演员的照片!这将允许我们做一些奇怪的事情,比如做一个迷恋演员的拼贴画,可以挂在我们的卧室里(像这样)。

为了收集这些图像,我们将使用Python进行一些web抓取。我们将使用BeautifulSoup库访问一个web页面并从中获取所有图像标记。
https://www.crummy.com/software/BeautifulSoup/

注:在许多网站条款和条件,他们禁止任何网站抓取他们的数据。有些开发API允许您访问它们的数据。另外,要注意你正在占用他们的资源。因此,一次只处理一个请求,而不是并行地打开许多连接。
代码

让Python访问该页面
我们首先导入所需的库,然后将网页链接存储到一个变量中。
1、请求库用于处理各种HTTP请求。
2、时间库用于在每个请求之后放置1秒的等待。如果我们不包括它,整个循环将以尽可能快的速度启动,这对我们正在抓取的站点不是很友好。
3、BeautifulSoup库用于简化对DOM树的探索。
用BeautifulSoup解析该网页
接下来,我们将URL推送到BeautifulSoup中。
寻找内容
最后,我们使用一个循环来获取内容。
它以一个for循环开始。BeautifulSoup做了一些很酷的过滤,我们的代码要求BeautifulSoup找到所有的“img”标签,并将其存储在一个临时数组中。然后,len函数询问数组的长度。
![]()
如果数组包含51个项目,代码将是这样的:
![]()
接下来,我们将返回到soup对象,并执行真正的过滤。

记住,我们在for循环中,所以[i]表示一个数字。
因此,我们告诉BeautifulSoup查找所有' img '标签,将其存储在一个临时数组中,并根据循环中的位置引用一个特定的索引号。
因此,我们没有像allOfTheImages[10]那样直接调用数组,而是使用了soup.findAll(' img ')[10],然后将它传递给标记变量。
tag变量中的数据如下:
![]()
这就是为什么下一步是退出“src”。

下载内容
这是有趣的部分!我们进入循环的最后一部分。
这里有一些奇怪的设计元素:
1、IF语句实际上是为我们测试的其他站点所做的黑客攻击。有时候我们抓取的图像是根网站的一部分(比如favicon或社交媒体图标),并不是我们想要的。 所以使用IF语句允许我们忽略它。
2、我们还强制所有图片为.jpg。可以编写另一块IF语句来检查数据类型,然后添加正确的文件类型。但是这增加了大量代码。
3、我们还添加了所有的打印命令。如果你想抓取网页或特定内容的所有链接,你可以在这里停止!
我们还想指出的是request .get(link)和open(filename, 'wb').write(r.content)代码:

这是如何工作的?
1、请求获取链接。
https://realpython.com/python-requests/

2、Open是一个默认的python函数,它打开或创建一个文件,使其具有写入和二进制模式访问(因为图像只有1和0),并将链接的内容写入该文件。
https://docs.python.org/3/library/functions.html#open


Web Scraping有很多有用的功能。
这段代码对于大多数带有图像的站点来说不是开箱即用的,但是它可以作为在不同站点上获取图像的基础。
生成报告和数据
收集数据很容易。解释数据很困难。这就是为什么对能够理解这些数据的数据科学家的需求激增的原因。数据科学家使用R和Python等语言来解释它。
在本文中,我们将使用csv模块,它将足以生成一个报告。如果我们要处理一个巨大的数据集,一个大约50,000行或更大的数据集,我们必须使用Pandas库。
我们要做的是下载CSV,让Python解释数据,根据我们想要回答的问题发送查询,然后将答案打印出来。
Python VS基本电子表格函数
你可能会想:
“我可以很容易地使用诸如=SUM或=COUNT之类的电子表格函数,或者手动过滤掉不需要的行,为什么还要使用Python呢?”
就像第1部分和第2部分中的所有其他自动化技巧一样,你肯定可以手动完成此操作。
但是想象一下,如果必须每天生成一个新的报告。
例如:我建立在线课程。我们想要一份关于每个学生进步的每日报告。今天有多少学生开始上课?这周有多少学生在活动?有多少学生上了第二单元?有多少学生提交了他们的模块3作业?有多少学生在移动设备上点击了完成按钮?
我们可以花15分钟整理数据,为团队生成一份报告。或者编写每天都要做的Python代码。
使用代码代替默认电子表格函数的其他用例:
1、你可能正在处理大量数据(大约50,000行和20列)
2、你需要多个过滤器片和分割得到您的答案
3、你需要对重复更改的数据集运行相同的查询
制作《权力的游戏》的报道
《权力的游戏》新闻网站Winteriscoming.net每年都会举办一年一度的“疯狂三月”。参观者将投票选出他们最喜欢的角色,获胜者将与另一个人竞争。经过6轮投票,最终宣布获胜者。

https://winteriscoming.net

因为2019年的投票还在进行中,所以我们把2018年的全部6轮数据都收集起来,并将它们编译成CSV文件。要查看在winteriscoming.net上的投票结果,请在这里查看:
https://winteriscoming.net/2018/03/11/game-of-thrones-march-madness-round-1-vote-for-your-favorite-character/

我们还添加了一些额外的背景数据(比如它们来自哪里),使报告更加有趣。
提问问题
为了生成一份报告,我们必须问一些问题。
根据定义:报告的主要职责是回答问题。
基于这个数据集,这里有一些问题。
1、赢得了人气投票?
2、谁基于平均值获胜?
3、谁是最受欢迎的非维斯特洛人?(非维斯特洛出生的角色))
代码
为了让它更简单,我们编写了所有的代码,包括修改——在我最喜欢的在线IDE, Repl.it
https://repl.it/@RockyKev/Game-of-Thrones-Generate-Reports
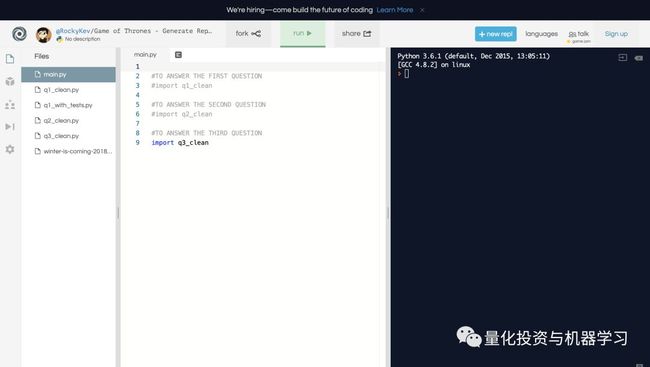
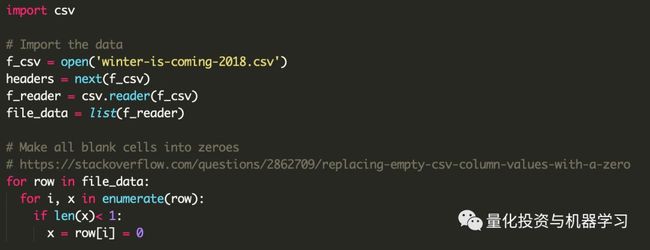
下面是我们编写代码的流程。
1、导入了csv模块。
2、导入了csv文件,并将其转换为名为file_data的列表类型。
Python读取文件的方法是首先将数据传递给对象。
删除了标题,因为它会篡改数据。
然后将对象传递给阅读器,最后传递一个列表。
注意:我们是通过python2实现的。在python3中有一种更简洁的方法。
3、为了对所有的总数进行求和,将所有空白单元格设置为0。
这是一个发现Stack Overflow解决方案比原来的版本更好的时刻。
https://stackoverflow.com/questions/2862709/replacing-empty-csv-column-values-with-a-zero
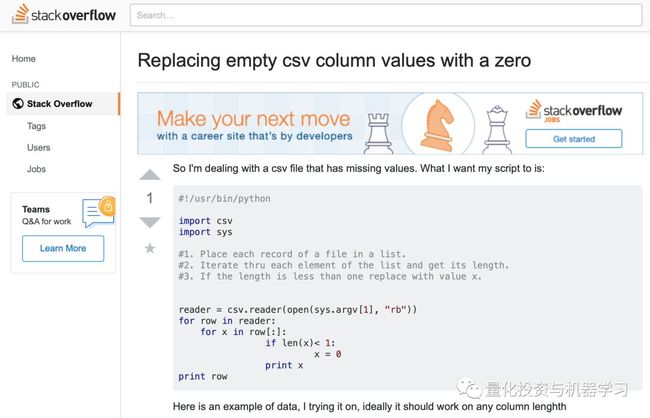
有了这个设置,我们现在可以循环遍历数据列表,并回答问题!
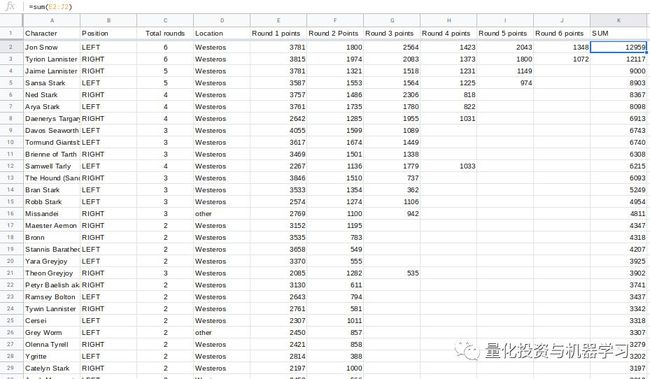
问题1:谁赢得了普选?
电子表格方法
最简单的方法是使用公式将每个单元格相加。以第2行为例,在空白列中,可以写出公式:
=sum(E2:J2)
然后可以将该公式拖放到其他行。然后,按总数排序。
Python方法
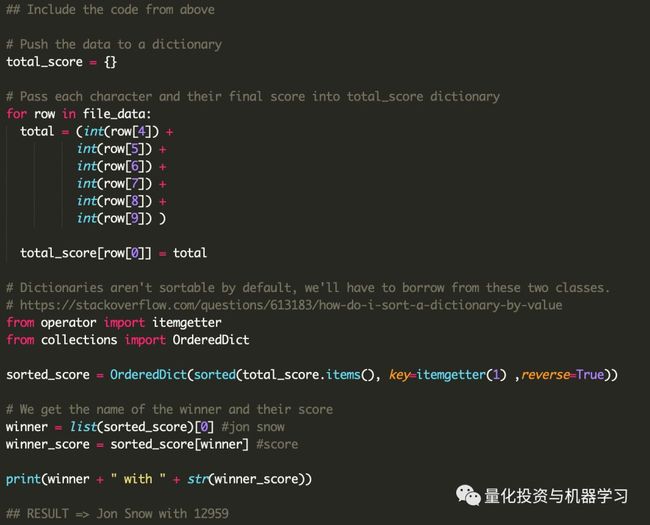
我们采取的步骤是:
1、数据集只是一个大列表。通过使用for循环,可以访问每一行。
2、在for循环中,我们添加了每个单元格。(模拟整个“=sum(E:J)”公式)
3、由于字典并不是完全可排序的,所以必须导入两个类来帮助我们根据它们的值从高到低对字典进行排序。
4、最后,通过了优胜者,并将优胜者的值作为文本。
为了帮助理解这个循环,我们画了一个图表。

总的来说,与电子表格方法相比,这个过程要长一些。但事情变得容易多了!

问题2:基于平均值谁赢了?
你可能已经注意到,排名靠前的人显然会得到更多的选票。
举个例子:如果Jon Snow 在第一轮得到500分,在第二轮得到1000分,他已经打败了Mountain,Mountain只有1000分,从来没有越过。
所以下一个最好的方法就是把总数加起来,然后根据他们参加了多少轮比赛来划分。
电子表格方法
这很简单。 在B列中他们参与了多少轮。你可以将轮数除以总和。
Python方法

注意到变化了吗?我们只是增加了一行。
这就是答案!

问题3:谁是非维斯特洛最受欢迎的人?
对于前两个示例,使用默认的电子表格函数很容易计算出总数。对于这个问题,情况有点复杂。
电子表格方法
1、假设你已经有和了;
2、现在你必须根据他们是否为Westeros / Other来过滤它;
3、然后按和排序。

Python方法

在问题2中,我们添加了一行代码来回答这个新问题。
在问题3中,我添加了IF-ELSE语句。如果他们是非维斯特洛人,那就算算他们的分数。否则,给他们0分。

回顾
虽然电子表格方法看起来不需要很多步骤,但它确实需要更多的点击。
Python方法的设置花费的时间要长得多,但是每个额外的查询只需要修改几行代码即可。
想象一下,你有一个大约50MB的数据集。这么大文件可能需要几分钟才能加载到Excel中。
总的来说,随着数据集的扩展,处理时间会越来越长。这就是Python的强大之处。
推荐阅读
01、经过多年交易之后你应该学到的东西(深度分享)
02、监督学习标签在股市中的应用(代码+书籍)
03、全球投行顶尖机器学习团队全面分析
04、使用Tensorflow预测股票市场变动
05、使用LSTM预测股票市场基于Tensorflow
06、美丽的回测——教你定量计算过拟合概率
07、利用动态深度学习预测金融时间序列基于Python
08、Facebook开源神器Prophet预测时间序列基于Python
09、Facebook开源神器Prophet预测股市行情基于Python
10、2018第三季度最受欢迎的券商金工研报前50(附下载)
11、实战交易策略的精髓(公众号深度呈现)
12、Markowitz有效边界和投资组合优化基于Python
13、使用LSTM模型预测股价基于Keras
14、量化金融导论1:资产收益的程式化介绍基于Python
15、预测股市崩盘基于统计机器学习与神经网络(Python+文档)
16、实现最优投资组合有效前沿基于Python(附代码)
17、精心为大家整理了一些超级棒的机器学习资料(附链接)
18、海量Wind数据,与全网用户零距离邂逅!
19、机器学习、深度学习、量化金融、Python等最新书籍汇总下载
20、各大卖方2019年A股策略报告,都是有故事的人!
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST等专业的主流自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新资讯。
