对于数字、字母这类的字符分类,用cnn是最好不过了,这是一次课程作业,记录一下吧。
给定的数据集是txt文件,存储了手写字体的轨迹:

第一行的70表示有70个点。
思路是这样的:
1、先将txt文件转换为png图片
2、对每张图片做一次形态学膨胀操作(因为轨迹点太稀疏)
3、数据增强(因为给定数据集样本太少,而CNN往往需要大量训练样本)
4、训练CNN模型(采用深度学习开源框架keras)
5、分类测试
1. 将txt文件转换为图片
用matlab实现(恩 老师给的代码,其实没怎么看懂)
function cor2img(filename)
fin=fopen(filename,'r');
fgetl(fin);
im_nlsize=[64,64];
re_im=[];
i=1;
while~feof(fin)
dt=str2num(fgetl(fin));
re_im(i,:)=dt;
i=i+1;
end
fclose(fin);
x_min=min(re_im(:,1))-1;
x_max=max(re_im(:,1))+1;
y_min=min(re_im(:,2))-1;
y_max=max(re_im(:,2))+1;
re_im(:,1)=round((re_im(:,1)-x_min)*(im_nlsize(1)-1)/(x_max-x_min)+1);
re_im(:,2)=round((re_im(:,2)-y_min)*(im_nlsize(2)-1)/(y_max-y_min)+1);
im_nlsize=[65,65];
grey_im=zeros(im_nlsize);
grey_im=double(grey_im);
for j=1:i-1
grey_im(re_im(j,2),re_im(j,1))=1;
end
grey_im=flipud(grey_im);
imwrite(grey_im, [filename, '.png']);
可以看到,我们得到的图片大小是65*65的。
2.膨胀操作
Matlab代码:
grey_im=flipud(grey_im);
filter = [0 1 0
1 1 1
0 1 0];
pengzhang_im = imdilate(grey_im, filter);
imwrite(pengzhang_im, [filename, '.png']);


3.数据增强
我们拿10套数据(1套有62类,包括0-9,a-z,A-Z)用来做数据增强,简单说下思路:先将65*65的图片的上下左右皆扩展5个像素变成75*75,然后截取100张65*65的图片,这样1张图片我们就可以得到100张,训练数据增加1062100 = 62000张。该想法来自Hinton2012年的那篇关于CNN和ImageNet的论文。
代码用Python实现,比较简单,贴点核心代码吧:
import os
from PIL import Image
from PIL import ImageOps
orImage = Image.open(filedir + '/' + filename)
image = ImageOps.expand(orImage, (5, 5, 5, 5), fill='black')
for x in xrange(0, 10):
for y in xrange(0, 10):
cropImage = ImageOps.crop(image, (x, y, 10 - x, 10 - y))
splits = filename.split('.')
newname = splits[0] + '_' + str(x) + '_' + str(y) + '.png'
cropImage.save(filedir + '/' + newname, 'png')
4.训练CNN模型
CNN网络结构采用经典的Lenet,只是做了一些修改,将最后一个全连接层的结点数改为200,softmax的输出改为62类。
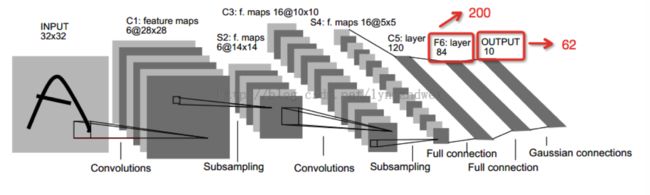
当然,每个卷积层之后加了Dropout以防止过拟合,实际上,这个项目是存在过拟合现象的,可以想象我们是在仅仅10套数据的基础上做的数据增强哎,怎么可能没有过拟合?
训练时的参数设置:
batch_size = 64
nb_epoch = 10,再迭代就严重过拟合了
validation_split = 0,恩不要验证集了
loss='categorical_crossentropy',损失函数使用交叉熵
训练过程的损失:

训练过程的准确率:
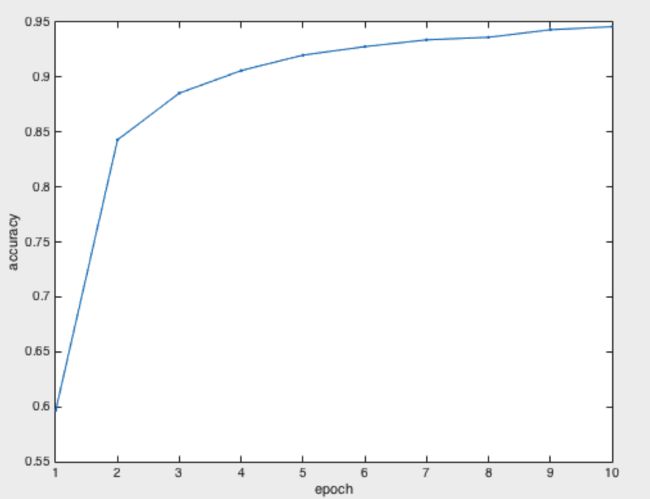
模型训练结束后,参数可以保存为文件,测试时可以直接拿来用。
5. 分类测试
测试数据有309,分类正确262,准确率84.78%,其实准确率不高,Lenet在Mnist数据集上的分类准确率可以达到99%,当然它那是10分类,而我们这是62分类。
数据集可在这里获取