Python与OpenCV(三)——基于光流法的运动目标检测程序分析
光流的概念是指在连续的两帧图像当中,由于图像中的物体移动或者摄像头的移动而使得图像中的目标形成的矢量运动轨迹叫做光流。本质上光流是个向量场,表示了一个像素点从第一帧过渡到第二帧的运动过程,体现该像素点在成像平面上的瞬时速度。
而当我们对图像当中每一个像素点都赋予一个速度矢量时,就形成了一个图像运动场。这个图像运动场可以表示出某一特定时刻,图像上所有像素点的瞬时相对运动关系。当图像中所有的像素点没有瞬时相对运动时,其矢量场是连续变化的,也就是说光流矢量在整个图像区域是连续变化的。而当图像中某些像素点与其他像素点对比存在瞬时相对运动时,其光流矢量在整个图像区域必然形成不连续性,这就是检测的依据。
光流法有三个假设前提:
(1)相邻帧之间的亮度恒定;
(2)相邻视频帧的取帧时间连续,或者,相邻帧之间物体的运动比较“微小”;
(3)保持空间一致性;即,同一子图像的像素点具有相同的运动
采用光流法进行运动物体检测的缺点是光流法计算耗时,实时性和实用性都较差。其优点在于光流不仅携带了运动物体的运动信息,而且还携带了有关景物三维结构的丰富信息,它能够在不知道场景的任何信息的情况下,检测出运动对象。
源码
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# ShiTomasi corner detection的参数
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7)
# 光流法参数
lk_params = dict(winSize=(15, 15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 创建随机生成的颜色
color = np.random.randint(0, 255, (100, 3))
ret, old_frame = cap.read() # 取出视频的第一帧
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY) # 灰度化
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
mask = np.zeros_like(old_frame) # 为绘制创建掩码图片
while True:
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流以获取点的新位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选择good points
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制跟踪框
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (int(a), int(b)), (int(c),int(d)), color[i].tolist(), 2)
frame = cv2.circle(frame, (int(a),int(b)), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('frame', img)
k = cv2.waitKey(30) # & 0xff
if k == 27:
break
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv2.destroyAllWindows()
cap.release()
源码分析
ShiTomasi 角点检测
角点检测(Corner Detection)是计算机视觉系统中用来获得图像特征的一种方法,广泛应用于运动检测、图像匹配、视频跟踪、三维建模和目标识别等领域中。也称为特征点检测。
角点通常被定义为两条边的交点,更严格的说,角点的局部邻域应该具有两个不同区域的不同方向的边界。而实际应用中,大多数所谓的角点检测方法检测的是拥有特定特征的图像点,而不仅仅是“角点”。这些特征点在图像中有具体的坐标,并具有某些数学特征,如局部最大或最小灰度、某些梯度特征等。
关于角点的具体描述可以有几种:
1)一阶导数(即灰度的梯度)的局部最大所对应的像素点;
2)两条及两条以上边缘的交点;
3)图像中梯度值和梯度方向的变化速率都很高的点;
4)角点处的一阶导数最大,二阶导数为零,指示物体边缘变化不连续的方向。
不管描述如何,角点检测本质上就是特征点检测。
OpenCV提供了多种角点选取的方式,其中包括ShiTomasiCorner Detector函数来进行角点选取的方法,本例中所使用的就是ShiTomasiCorner Detector方法。
在ShiTomasiCorner Detector方法中,用于检测的图像应该是一幅灰度图,对这一幅灰度图像进行ShiTomasiCorner Detectors 首先需要指定想要寻找的corners的数量(源码中的maxCorners=100),接着指定质量级别quality-level(源码中的qualityLevel=0.3),其值为0-1之间,这表示角点的最小质量,低于该值的Corners都将被拒绝。然后提供检测到的corners的最小欧式距离(源码中的minDistance=7)。
最后的结果是:在某一欧式距离所指定的区域中,所有低于所定义的quality-level的corner都将被丢弃,而剩余的corners基于quality-level降序的方式排列,然后函数取第一个最强壮的角点,这样就形成了某一区域内的一个检测到的角点。
在整个图像中,按上面的方式所提取出来的角点数不超过maxCorners所定义的数量。
同时在进行计算协方差矩阵时用blockSize窗口大小。
feature_params = dict(maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7)
maxCorners: 返回最大的角点数,是最有可能的角点数,如果这个参数不大于0,那么表示没有角点数的限制。
qualityLevel: 图像角点的最小可接受参数,质量测量值乘以这个参数就是最小特征值,小于这个数的会被抛弃。
minDistance: 返回的角点之间最小的欧式距离。
blockSize: 用于计算每个像素邻域上的导数协变矩阵的平均块的大小。
Lucas–Kanade算法及其参数定义
在计算机视觉中,Lucas–Kanade光流算法是一种两帧差分的光流估计算法。它由Bruce D. Lucas 和 Takeo Kanade提出。
在利用Lucas–Kanade光流算法对图像进行处理时,会利用到针对于某一特定图像的一系列图像,这些图像是按照某一算法的塔式变形,因此,借助这样的算法所完成的光流法简称为金字塔LK算法。

图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
在图像金字塔的构建中,高斯金字塔是最常用的一种形式。所谓的高斯金字塔就是采用归一化高斯卷积核进行卷积计算而对某层图像进行高斯模糊而形成上(下)层图像的过程。所以说标准意义上的高斯金字塔指的是不同分辨率的同一张图像所组成的图像结构,金字塔从上往下生成,图片的分辨率不断增大,称作上采样;金字塔从下往上生成,图片的分辨率不断下降,称作下采样。
# 光流法参数
lk_params = dict(winSize=(15, 15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
参数信息:
winSize表示选择多少个点进行u和v的求解。
在借助金字塔LK算法对图像进行求解的过程中,会用到一个经泰勒公式求解而得的光流公式:fxu+fyv+ft=0。
其中fx和fy分别是图像x方向和y方向的梯度,ft是图像沿着时间轴的梯度。这两个梯度可由金字塔参数得出,而在fxu+fyv+ft=0公式中,存在有两个未知量,一个是u,一个是v,一个方程是求不出两个未知数的,所以,我们取一个相应窗口的各个像素点,将每个像素点的灰度值都代入公式,我们就有了对于u和v两个未知数的若干个求解方程,那么未知数u和v就可以求解了。
在本例中,winSize=(15, 15)就表示选择了15*15个像素点的值代入光流方程来求解u和v的值。
maxLevel 使用的图像金字塔层数,本例中取2层。
Criteria:在高斯卷积进行迭代求解的过程中,收敛的值和最大收敛次数,这两个条件到达其中一个就可以结束收敛了,其中最大迭代次数是10,收敛的阈值是0.03
cv2.TERM_CRITERIA_EPS为收敛的值
cv2.TERM_CRITERIA_COUNT为最大收敛次数
识别前的初处理
# 创建随机生成的颜色
color = np.random.randint(0, 255, (100, 3))
ret, old_frame = cap.read() # 取出视频的第一帧
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY) # 灰度化
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
mask = np.zeros_like(old_frame) # 为绘制创建掩码图片
第一行:color = np.random.randint(0, 255, (100, 3)),生成一个100行3列的数组,并把这个数组的值赋给一个变量color。
np.random.randint(0, 255, (100, 3))的原函数可以写成 np.random.randint(low, high, size),表示的是生成一个size大小的数组,数组当中的每一个数值取自于[low,hign)之内,也就是包括low,不包括high,所以在本实例当中,数组当中的每一个数都取自于[0,255),size是指数组的大小,在本实例当中是(100,3),表示是100行3行。下面我们定义一个小一点的数组:
color= np.random.randint(0, 255, (5, 3)),运行一下,看一下结果:

如图结果3可以看到:生成了一个5行3列的数组,数组中的每一个值都在[0,255)之间。
那么我们定义这样的数组是要干什么呢?我们看一下结果图:

从图上可知,在图像上识别出若干个角点,同时这些角点的运行矢量形成了光流线。这些角点和每一条光流线是不同颜色的,那么这个颜色就是这个随机生成函数生成的颜色,所以每一行有三个值,对应于OpenCV的BGR颜色空间。
下面的两行代码:
ret, old_frame = cap.read() # 取出视频的第一帧
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY) # 灰度化
前面介绍过,不再赘述。
第五行:p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
cv2.goodFeaturesToTrack()函数是用来跟踪检测图像中的角点。old_gray表示输入的图片,mask表示掩模,feature_params是在程序的最开始创建的ShiTomasi 角点检测参数(maxCorners=100,qualityLevel=0.3,minDistance=7, blockSize=7)。所以p0得到的是对当前图片old_gray利用前面创建的feature_params参数进行角点追踪的图像。
那么这部分运行结束后,p0是什么样子的呢,我们执行一下print(p0),如图:

可以看出p0是一个数组,数组中有一系列数据,这些数据就是在当前帧识别到的角点,我们暂且称p0为角点群吧。。。每一行的数据是这个角点群中每一个角点的位置。
第六行:mask = np.zeros_like(old_frame)
np.zeros_like()函数主要是实现构造一个矩阵与括号内参数相同维度的矩阵,并且内部元素都为0,具体到本例,定义一个mask矩阵,其维度与矩阵old_frame一致,并为其初始化为全0。
识别处理
接着进行一个永真循环,开始逐帧分析。
while True:
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流以获取点的新位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选择good points
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制跟踪框
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (int(a), int(b)), (int(c),int(d)), color[i].tolist(), 2)
frame = cv2.circle(frame, (int(a),int(b)), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('frame', img)
第二,三行
ret,frame = cap.read()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
读入一帧,并将图像转为灰度图像。
第五行: p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params):用前面所定义的光流法参数lk_params,及前(old_gray)后(frame_gray)帧图像来检测p0角点群中各个角点的运行特性,返回值有三个:p1表示光流检测后的角点位置,同p0一样,也是一个数组,对应是第一个点的位置,st表示该角点是否是运动的角点,err表示是否出错。
第七、八行
# 选择good points
good_new = p1[st == 1]
good_old = p0[st == 1]
在p1和p0中选择具有活动特性的点,形成good_new和 good_old点数组(为方便观察,取maxCorners=3)。

接下来该绘制结果图了:
for i, (new, old) in enumerate(zip(good_new, good_old)):
解释两个函数:
1) enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
2)zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
在本例中执行以下操作,可得出如图所示结果(为方便观察,取maxCorners=6):
good_new = p1[st == 1]
print("good_new值为:")
print(good_new)
good_old = p0[st == 1]
print("good_old值为:")
print(good_old)
for each in zip(good_new, good_old):
print(each)
for each in enumerate(zip(good_new, good_old)):
print(each)
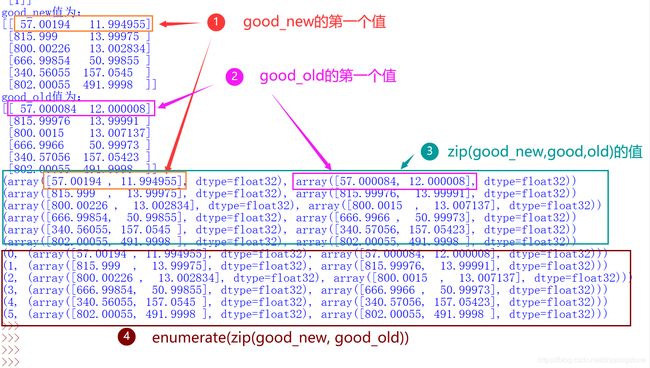
从图中可以看出zip是将good_new和good_old对应位置的值提取出来形成一个新值,而enumerate为这些值加上一个索引号。这时在语句for i, (new, old) in enumerate(zip(good_new, good_old)):中,索引号循环赋给了i,而后面的两个位置值分别赋给了new和old两个变量,new表示的是新点的位置值,old表示的是旧点的位置值。
下面的两句:
a, b = new.ravel()
c, d = old.ravel()
ravel()函数,该函数用于将二维数组或多维数组更改为连续的扁平数组。返回的数组与源数组或输入数组具有相同的数据类型。如果输入数组是掩码数组, 则返回的数组也将是掩码数组。
所以返回值是将数组的每一个数据提取出来赋给了a、b、c、d,a、b对应着new点的位置值,c、d对应着old点的位置值。
接下来的一句:
mask = cv2.line(mask, (int(a), int(b)), (int(c),int(d)), color[i].tolist(), 2)
cv2.line()方法用于在任何图像上绘制一条线。
cv2.line(image, start_point, end_point, color, thickness)
参数:
image:它是要在其上绘制线条的图像,在本例中,使用的是前面mask = np.zeros_like(old_frame) 所定义的基本数据都是0的,与old_gray相同维度的矩阵图片,这个图片作为掩膜图片。
start_point:它是线的起始坐标。坐标表示为两个值的元组,即(X坐标值,Y坐标值)。在本例中使用new点的位置值a,b的整数值。
end_point:它是直线的终点坐标。坐标表示为两个值的元组,即(X坐标值ÿ坐标值)。在本例中使用old点的位置值a,b的整数值。
color:它是要绘制的线条的颜色。对于BGR,我们通过一个元组。例如:(255,0,0)为蓝色。在本例中,使用的是color[i].tolist()。其中,color[i]选自前面color = np.random.randint(0, 255, (100, 3))创建随机生成的颜色数组当中的第i行数组,而tolist()是当提取出来的这个数组转换为列表来表示。
thickness:它是线的粗细像素,线宽。若是-1表示画封闭图像,如填充的圆。默认值是1。本例中选2。
frame = cv2.circle(frame, (int(a),int(b)), 5, color[i].tolist(), -1)
这一句与上一句类似,cv2.circle()方法用于在任何图像上绘制圆。格式为:
cv2.circle(image, center_coordinates, radius, color, thickness)
参数:
image:它是要在其上绘制圆的图像,本例取永真循环的第一句ret,frame = cap.read()所取的图像frame 。
center_coordinates:它是圆的中心坐标。坐标表示为两个值的元组,即(X坐标值,Y坐标值),本例中使用new点的位置值a,b的整数值。
radius:它是圆的半径,取5。
color:它是要绘制的圆的边界线的颜色。与画直线时含义一样。
thickness:它是圆边界线的粗细像素。厚度-1像素将以指定的颜色填充矩形形状。
再下一句:
img = cv2.add(frame, mask)
这一步将frame, mask进行相加。就是把mask所表示的直线叠加到frame图像上。
图像加法主要有两种用途,一种是可用于减少甚至消除图像采集中混入的噪声,由于图像各点的采集噪声是互不相关的,且噪声具有零均值的统计特性,因此可以对图像进行多次采集形成多副图像,然后将这多副图像相加再取平均值,就可以实现噪点的消除;另一种是用来做特效,把多幅图像叠加在一起,再进一步进行处理。
opencv的加运算就是两幅图像或一副图像和一个标量(标量即单一的数值)相加。对两副图像相加,要求两幅或多幅相加的图像的大小应该相同,处理时将两副图像相同位置的像素的灰度值(灰度图像)或彩色像素各通道值(彩色图像)分别相加;对一副图像和一个标量相加时,则将图像所有像素的各通道值分别与标量进行相加。
cv2.imshow('frame', img)
对上面处理形成的img图片进行显示。
这样识别的基本处理就完成了。。。
识别后处理
下面这部分是识别后的处理了。。。
k = cv2.waitKey(30)
if k == 27:
break
上面的三句话:1、等待按键事件30秒;2、如果按下了ESC键(ESC键的ASCII码为27)3、break:退出循环。
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
这两句用来更新 p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)当中old_gray的值,第一句把当前新帧的灰度图象的拷备版本作为下一次循环的旧图像old_gray。而p0 = good_new.reshape(-1, 1, 2)是对good_new位置矩阵进行重构,生成新的p0角点群。其中good_new.reshape(-1, 1, 2)中-1是指矩阵的行数由系统自动检测形成,后面的1,2表示生成的角点群的每一个元素都是一行两列的两个元素,是两个位置的值。
cv2.destroyAllWindows()
cap.release()
是用来停止捕获视频和关闭相应的显示窗口。