opencv 摄像头yuv_YOLOV4视频对象检测,python+opencv轻松实现

头条号:人工智能研究所
微信号:启示AI科技上期文章,我们介绍了YOLOV4对象检测算法的模型以及基本知识,哪里还进行了图片的对象检测,如何使用YOLOV4进行视频检测与实时视频检测呢?毕竟我们绝大多数的需求必然是视频的实时对象检测
YOLOV4视频检测
import numpy as np
import time
import cv2
import os
labelsPath = "yolo-coco/coco.names"
LABELS = None
with open(labelsPath, 'rt') as f:
LABELS = f.read().rstrip('n').split("n")
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
weightsPath = "yolo-coco/yolov4.weights"
configPath = "yolo-coco/yolov4.cfg"
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]首先加载模型在COCO数据集上的对象label,然后定义了随机的颜色,这里主要是为了后期检测到不同的对象时,采用不同的颜色边框进行标注
cv2.dnn.readNetFromDarknet(configPath, weightsPath)来加载YOLOV4的预训练模型,这里需要注意:opencv的版本需要时4.4版本
opencv4.4支持YOLOv4、EfficientDet检测模型,SIFT移至主库!

SIFT
支持谷歌目标检测算法 EfficientDet
EfficientDet检测模型
新增光流算法 FlowNet2 demo:

FlowNet2 demo
增加对OpenVINO 2020.3 LTS / 2020.4 支持

OpenVINO
由于opencv4.4支持了YOLOV4,因此我们可以使用opencv来实现YOLOV4的对象检测

代码截图
截取视频帧进行神经网络检测
#vs = cv2.VideoCapture('videos/a1.mp4')
vs = cv2.VideoCapture(0)
time.sleep(2.0)
writer = None
(W, H) = (None, None)
while True:
(grabbed, frame) = vs.read()
if not grabbed:
break
print('ok')
if W is None or H is None:
(H, W) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()cv2.VideoCapture(0)默认为打开摄像头,若想打开一段视频,直接在里面输入“路径地址”
(grabbed, frame) = vs.read()
if not grabbed:
break
print('ok')这里我们截取视频帧,若没有检测到视频,直接退出,若检测到视频,进行神经网络的检测
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()这里我们进行神经网络Blob 值的计算,然后进行神经网络的预测,并进行前向传递,这里跟其他神经网络不同的是,前向传递的是ln,神经网络的所有输出层

代码截图
遍历输出层,得到检测结果
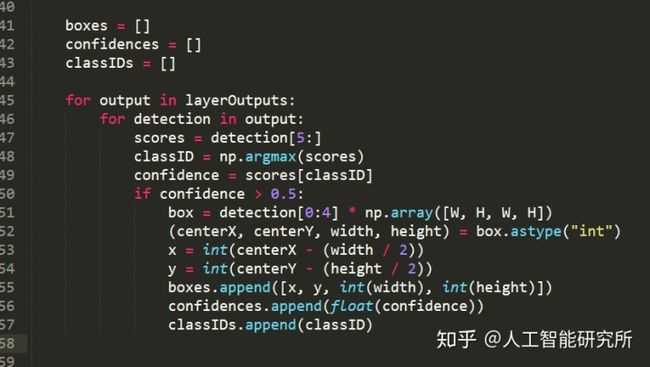
boxes = []
confidences = []
classIDs = []
for output in layerOutputs:
for detection in output:
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
if confidence > 0.5:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)首先我们初始化了3个参数,分别是box(对象检测到的坐标), confidence(对象检测到的置信度)ID(对象的ID)
通过遍历所有的输出层,提取置信度大于0.5的对象,并记录每个对象的box、confidence、ID。
代码截图
非最大值抑制
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
if len(idxs) > 0:
for i in idxs.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]], confidences[i])
cv2.putText(frame, text, (x, y - 5),cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
cv2.imshow("Image", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
'''
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter("videos/123.avi", fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
writer.write(frame)
'''
vs.release()
cv2.destroyAllWindows()为什么需要非最大抑制,因为YOLO系列对多个临近的对象检测会出3个以上的对象检测框,这些我们只需要提取边框最大,概率最大的那个对象
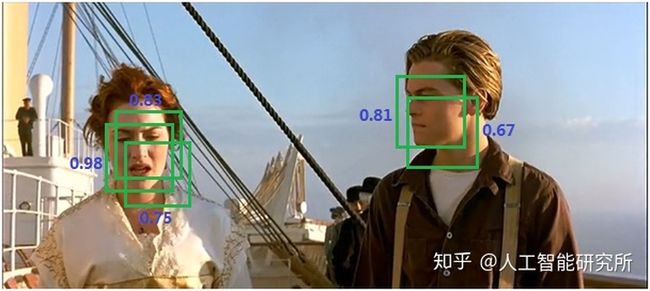
无最大抑制检测图形
当没有非最大值抑制时,可以看出,神经网络在同一个对象上会有多个框,每个框都带有分类器的得分,这些并不是我们需要的。
使用非最大值抑制来提取最大的检测边框以及得分,并把边框与分类ID以及置信度实时显示到屏幕上,最后,若想退出程序,可以直接输入字母q
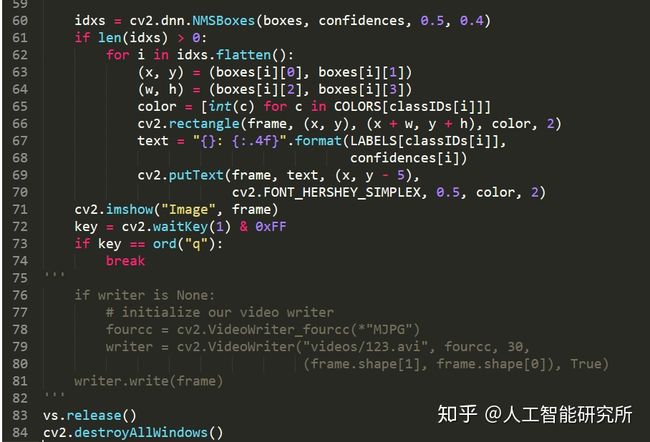
代码截图
视频对象检测保存视频
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter("videos/123.avi", fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
writer.write(frame)当然,这部分代码需要跟前面vs = cv2.VideoCapture('videos/a1.mp4')打开视频配合
当我们进行一段视频检测完成后,我们希望保存检测完成的视频,这里直接使用CV2的VideoWriter写入功能
编码参数:cv2.VideoWriter_fourcc('I','4','2','0')---未压缩的YUV颜色编码,
4:2:0色度子采样。兼容性好,但文件较大。文件扩展名.avi。
cv2.VideoWriter_fourcc('P','I','M','1')---MPEG-1编码类型,文件扩展名.avi。
cv2.VideoWriter_fourcc('X','V','I','D')---MPEG-4编码类型,视频大小为平均值,
MPEG4所需要的空间是MPEG1或M-JPEG的1/10,它对运动物体可以保证有良好的清晰度,
间/时间/画质具有可调性。文件扩展名.avi。
cv2.VideoWriter_fourcc('T','H','E','O')---OGGVorbis,音频压缩格式,
有损压缩,类似于MP3等的音乐格式。,兼容性差,件扩展名.ogv。
cv2.VideoWriter_fourcc('F','L','V','1')---FLV是FLASH VIDEO的简称,
FLV流媒体格式是一种新的视频格式。文件扩展名为.flv。这里需要特别注意,选择的视频编码格式与要保存的视频后缀要保持一致,以上编码格式请参考,小编首次运行时,保存的视频是MP4格式,一直报错,通过搜索资料,才发现是由于保存的视频后缀有问题。参数中的30是视频的帧30FPS。
信搜索小程序:AI人工智能工具,体验不一样的AI工具
