WSDM 2021部分领域优秀论文合集(附下载链接)
WSDM 2021部分领域优秀论文合集(附下载链接)

目录
- WSDM 2021部分领域优秀论文合集(附下载链接)
-
- 分类
-
- DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
- Semi-Supervised Text Classification via Self-Pretraining
- DECAF: Deep Extreme Classification with Label Features
- Modeling Across-Context Attention For Long-Tail Query Classification in E-commerce
- On the Impact of Predicate Complexity in Crowdsourced Classification Tasks
- Beyond Point Estimate: Inferring Ensemble Prediction Variation from Neuron Activation Strength in Recommender Systems
- 推荐系统
-
- Popularity-Opportunity Bias in Collaborative Filtering
- A Black-Box Attack Model for Visually-Aware Recommender Systems
- Leave No User Behind: Towards Improving the Utility of Recommender Systems for Non-mainstream Users
- Real-time Relevant Recommendation Suggestion
- User Response Models to Improve a REINFORCE Recommender System
- Diverse User Preference Elicitation with Multi-Armed Bandits
- 搜索&推荐
-
- Question Rewriting for Conversational Question Answering
- Adapting User Preference to Online Feedback in Multi-round Conversational Recommendation
- Denoising Implicit Feedback for Recommendation
- Origin-Aware Next Destination Recommendation with Personalized Preference Attention
- Event-Driven Query Expansion
- An Efficient and Effective Framework for Session-based Social Recommendation
- 神经网络
-
- RePBubLik: Reducing Polarized Bubble Radius with Link Insertions
- Node Similarity Preserving Graph Convolutional Networks
- BiTe-GCN: A New GCN Architecture via Bidirectional Convolution of Topology and Features on Text-Rich Networks
- Deconfounding with Networked Observational Data in a Dynamic Environment
- Balanced Influence Maximization in the Presence of Homophily
- Learning and Updating Node Embedding on Dynamic Heterogeneous Information Network
WSDM的英文全称是 The International Conference on Web Search and Data Mining,中文意思是国际互联网检索与数据挖掘会议,由SIGIR、SIGKDD、SIGMOD和SIGWEB四个专委会协调筹办,是一个有关搜索和数据挖掘的互联网启发式研究的主要会议之一,每年举办一届。WSDM是信息检索与数据挖掘的顶级会议。在互联网搜索、数据挖掘领域享有较高学术声誉,被中国计算机协会推荐为B类会议,在清华大学最新发布的新版计算机学科推荐学术会议和期刊列表中,WSDM已被列为准A类学术会议。
2021年第14届国际网络搜索与数据挖掘会议WSDM将在2021年3月8日到12日于线上举行。本次大会共收到了 603份篇投稿,录用了112篇论文,接收率仅为18.6%,其中Oral 69篇,接受率为11.4%。
完整的接收论文列表可以访问如下链接获取:
https://www.wsdm-conference.org/2021/accepted-papers.php
完整的录取论文列表可以访问如下链接获取:
http://www.wsdm-conference.org/2021/proceedings.php
本文梳理WSDM 2021有关分类、推荐系统、搜索和推荐、图神经网络等领域的最新研究成果,供大家参考。
分类
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
DeepXML:基于深度极限多标签学习框架的短文本文档
论文下载地址:http://manikvarma.org/pubs/dahiya21-main.pdf

在深度极限多标签学习中,可扩展性和准确性是公认的挑战,其目标是训练体系结构,以便用来自极大标签集中最相关的标签子集自动注释数据点。本文开发了DeepXML框架,通过将深度极限多标签任务分解为四个更简单的子任务来解决这些挑战,每个子任务都可以得到准确有效的训练。为四个子任务选择不同的组件允许DeepXML生成一系列算法,这些算法在准确性和可扩展性之间有不同的权衡。特别是,DeepXML产生的Astec算法比公共可用的短文本数据集上领先的深度极性分类器的精度高2-12%,训练速度快5-30倍。Astec还可以在包含多达6200万个标签的必应短文本数据集上进行高效培训,同时在商品硬件上每天为数十亿用户和数据点进行预测。这使得Astec可以在Bing搜索引擎上部署许多短文本应用程序,从匹配用户查询到广告商出价短语,再到显示个性化广告,在点击率、覆盖率、收入和其他在线指标方面,Astec都比目前生产的最先进的技术有了显著的提高。DeepXML的代码地址是https://github.com/Extreme-classification/deepxml。
Semi-Supervised Text Classification via Self-Pretraining
基于自预训练的半监督文本分类
论文下载地址:http://www.mathcs.emory.edu/~pkarisa/2021___WSDM___self_pretraining.pdf

我们提出了一种神经半监督学习模型,称为自训练。我们的模型受到经典自训练算法的启发。然而,与自训练相反,自预训练是无阈值的,它可以潜在地更新其对先前标记的文档的信念,并且可以处理语义漂移问题。自预处理是迭代的,由两个分类器组成。在每次迭代中,一个分类器随机抽取一组未标记的文档并给它们贴上标签。该集合用于初始化第二分类器,由标记文档集合进一步训练。算法进行到下一次迭代,分类器的角色被颠倒。为了改善迭代中的信息流,同时也为了解决语义漂移问题,自预处理采用迭代蒸馏过程,在迭代中转移假设,利用两阶段训练模型,使用有效的学习速率计划,并采用伪标签转换启发式算法。我们在三个公开的社交媒体数据集上评估了我们的模型。我们的实验表明,在多种设置下,自预处理优于现有的先进的半监督分类器。我们的代码可在https://github.com/p-karisani/self-pretraining获得。
DECAF: Deep Extreme Classification with Label Features
DECAF:基于标签特征的深度极限分类
论文下载地址:http://manikvarma.org/pubs/mittal21-main.pdf
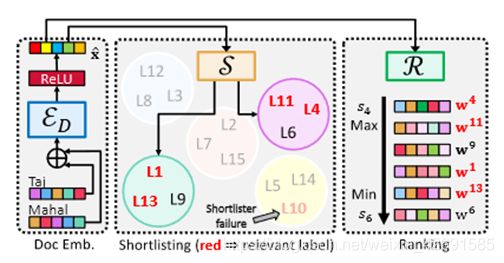
极限多标签分类(XML)包括用一个极其大的标签集中最相关的标签子集来标记一个数据点,有几个应用程序,例如具有数百万种产品的产品对产品推荐。尽管领先的XML算法可以扩展到数百万个标签,但它们在很大程度上忽略了标签元数据,如标签的文本描述。另一方面,可以通过使用深度网络的表示学习来利用标签元数据的经典技术在极端环境中举步维艰。本文开发了DECAF算法,通过学习由标签元数据丰富的模型来解决这些挑战,标签元数据使用深度网络联合学习模型参数和特征表示,并在数百万个标签的规模上提供准确的分类。DECAF对模型架构设计、初始化和训练做出了具体贡献,使其能够在公开可用的基准产品对产品推荐数据集(如LF-AmazonTitles-1.3M)上提供比领先的极端分类器高2-6%的预测精度。同时,DECAF的推理速度比领先的深度极限分类器快22倍,这使得它适用于需要在几毫秒内进行预测的实时应用。DECAF代码可在以下地址获得:https://github.com/Extremeclassification/DECAF。
Modeling Across-Context Attention For Long-Tail Query Classification in E-commerce
电子商务中长尾查询分类的跨上下文注意力建模
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441822
产品查询分类是查询理解的基本组成部分,其目的是在电子商务搜索引擎的预定义产品类别分类下将用户查询分类为多个类别。由于产品种类繁多,这是一项具有挑战性的任务。对查询的轻微修改将完全改变其对应的类别,例如,将“按钮”附加到查询“衬衫”上。对于缺乏足够客户监督信息的尾部查询,问题更为严重。受这一现象的启发,本文提出对这类相似查询之间的对比/相似关系进行建模。我们的框架由一个基本模型和一个跨上下文注意力模块组成。跨上下文注意力模块通过预测这些不同的查询的类别,来扮演从这些查询中导出和提取外部信息的角色。我们在现实世界的电子商务搜索引擎上进行离线和在线实验。实验结果证明了我们的跨上下文注意力模块的有效性。
On the Impact of Predicate Complexity in Crowdsourced Classification Tasks
众包分类任务中谓词复杂性的影响
论文下载地址:https://arxiv.org/pdf/2011.02891.pdf

本文探讨了众包任务设计中的一个具体而相关的问题,并提供了指导:如何制定一个复杂的问题来对一组项目进行分类。在微任务市场,分类仍然是最受欢迎的任务之一。我们将我们的工作置于信息检索和多谓词分类的背景下,即基于一组条件对一组项目进行分类。我们的实验涵盖了广泛的任务和领域,还考虑了单独的群体工作者和与机器学习分类器协同工作。我们提供经验证据来说明不同的谓词制定策略如何影响最终的分类性能,强调谓词制定作为众包中任务设计维度的重要性。
Beyond Point Estimate: Inferring Ensemble Prediction Variation from Neuron Activation Strength in Recommender Systems
超越点估计:从推荐系统中的神经元激活强度推断集成预测变化
论文下载地址:https://arxiv.org/pdf/2008.07032.pdf
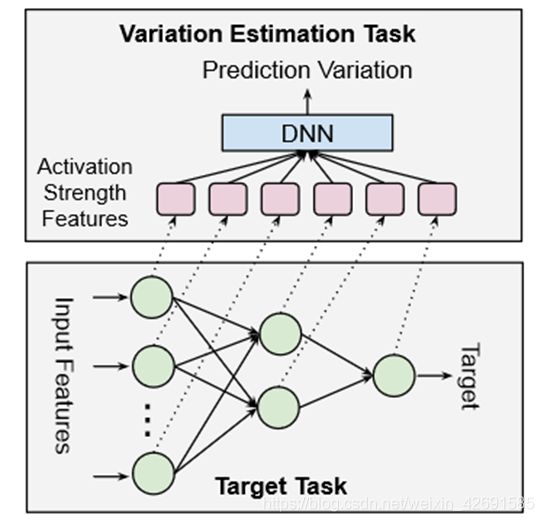
尽管深度神经网络(DNN)在各种领域具有令人印象深刻的预测性能,但众所周知,用相同的模型规格和完全相同的训练数据训练的一组DNN模型可能产生非常不同的预测结果。人们依靠最先进的集成方法来估计预测的不确定性。然而,对于网络规模的交通系统来说,训练和服务集群的成本很高。
在本文中,我们试图提高对集成方法估计的预测变化的理解。通过在推荐系统中两个广泛使用的基准数据集Movielens和Criteo上的实验,我们观察到预测变化来自各种随机性来源,包括训练数据洗牌和随机初始化。当我们向系综成员添加更多的随机性源时,我们看到这些系综成员之间更高的预测变化,以及更准确的平均预测。此外,我们建议从神经元激活强度推断预测变化,并证明其强大的预测能力。我们的方法为预测变异估计提供了一种简单的方法,并在许多感兴趣的领域(例如,基于模型的强化学习)为未来的工作开辟了新的机会,而不依赖于提供昂贵的集成模型。
推荐系统
Popularity-Opportunity Bias in Collaborative Filtering
基于协同过滤的流行度-机会偏置
论文下载地址:https://people.tamu.edu/~zhuziwei/pubs/Ziwei_WSDM_2021.pdf
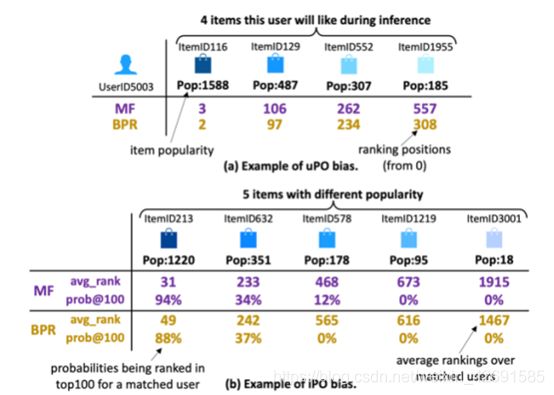
本文将隐性推荐者中的机会均等与流行度偏置联系起来,引入流行度-机会偏置问题。也就是说,以用户偏好为条件,即用户喜欢这两个项目,更流行度的项目比不太流行度的项目更有可能被推荐(或排名更高)给用户。这种类型的偏置是有不利的,对用户和项目提供商的参与产生负面影响。因此,我们进行了一个三部分的研究:(1)通过一个全面的实证研究,我们确定了四个数据集上的基本矩阵分解模型中流行度-机会偏置的存在;(2)结合这一实证研究,我们的理论研究表明,矩阵分解模型固有地产生偏置;和(3)我们证明了通过处理中和后处理算法减轻这种偏置的可能。在四个数据集上的大量实验表明,与为传统流行度偏置设计的基线相比,这些方法具有有效的去偏性能。
A Black-Box Attack Model for Visually-Aware Recommender Systems
基于黑盒攻击模型的视觉感知推荐系统
论文下载地址:https://arxiv.org/pdf/2011.02701

由于深度学习的发展,视觉感知推荐系统最近引起了越来越多的研究兴趣。这种系统将协作信号与图像相结合,通常表示为由预训练的图像模型输出的特征向量。由于商品目录可能非常庞大,推荐服务提供商通常依赖于商品提供商提供的图像。在这项工作中,我们表明,依赖这样的外部资源可以使遥感容易受到攻击,其中攻击者的目标是不公平地促进某些推项目。具体来说,我们演示了一种新的视觉攻击模型,即在不知道模型参数的情况下,如何以黑盒方式有效地影响项目分数和排名。主要的基本思想是系统地创建推送项目图像的人类不可察觉的小扰动,并设计适当的梯度近似方法来逐步提高推送项目的分数。在两个数据集上的实验评估表明,虽然视觉特征对推荐系统整体性能的贡献不大,新的攻击模型也是有效的。
Leave No User Behind: Towards Improving the Utility of Recommender Systems for Non-mainstream Users
不让用户掉队:提高非主流用户推荐系统的实用性
论文下载地址:https://arxiv.org/pdf/2102.01744
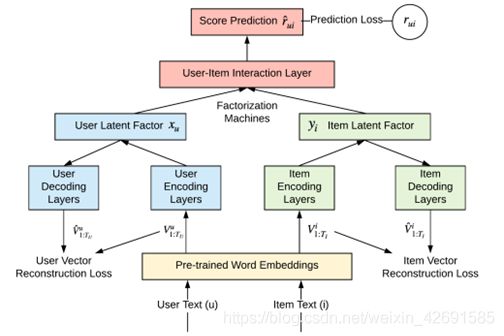
在协同过滤推荐场景中,数据中的偏差可能传递给正在训练学习的推荐系统。在本文中,主要关注的是主流偏好:推荐系统向具有主流偏好的用户提供更好的推荐的趋势,而不是向非主流用户提供推荐。我们提出NAECF,一个概念简单但有效的解决这种偏好的想法。这个想法包括在用基于文本的卷积神经网络学习用户和项目表示时添加一个自动编码器层。在学习如何推荐时,一个用于用户,一个用于项目的AE是最小化评级预测误差过程的对手。它们强制要求所有用户和项目的特定独特属性在学习的表示中被充分地合并和保存。这些表示被提取为相应的不良事件的瓶颈,预计将更少偏好主流用户,并在所有用户之间提供更平衡的推荐效用。我们的实验结果证实了这些期望,显著改善了非主流用户的推荐,同时保持了主流用户的推荐质量。我们的结果强调了部署广泛的基于内容的功能(如在线评论)的重要性,以便更好地代表用户和项目,最大限度地发挥去偏向效果。
Real-time Relevant Recommendation Suggestion
实时相关推荐建议
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441733
推荐系统的用户通常一次只关注一个主题。当阅读完一个项目时,用户可能希望访问与最后一次阅读相关的更多相关项目作为扩展阅读。然而,传统的推荐系统很难提供这些相关项目的连续扩展阅读功能,因为主要的推荐结果应该是多样化的。在本文中,我们提出了一个推荐建议的新任务,旨在(1)预测用户是否想要扩展阅读,以及(2)提供适当的相关项目作为建议。这些推荐的相关项目被排列在一个相关的框中,并立即插入到主提要中被点击项目的下方。相关项目推荐建议的挑战在于,除了CTR相关因素外,还应进一步考虑语义相关性和信息增益。而且,当用户不想要扩展阅读时,实时的相关插盒也可能损害整体性能。为了解决这些问题,我们提出了一个新的实时相关推荐框架,该框架由一个项目推荐器和一个盒子触发器组成。我们从特征交互、语义相似度和信息增益等多个方面提取特征作为不同的专家方法,并提出一种新的Multi-critic multi-gate mixture-of-experts (M3oE),将不同的专家与多名批评家联合考虑。在实验中,我们通过详细的消融测试对现实推荐系统进行离线和在线评估。item/box相关指标的显著改进验证了R3S的有效性。而且我们在微信Top Stories上部署了R3S,影响了数百万用户。源代码在https://github.com/modriczhang/R3S。
User Response Models to Improve a REINFORCE Recommender System
改进REINFORCE推荐系统的用户响应模型
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441764
强化学习技术被作为下一代工具来进一步提高推荐系统领域研究。与RL的经典应用不同,推荐代理,尤其是部署在商业推荐平台上的推荐代理,必须在极其庞大的状态和动作空间中运行,服务于数十亿量级的动态用户群,以及数百万或数十亿量级的长尾项语料库。回想起来,可用于训练此类代理的(正面)用户反馈非常少。因此,在为推荐系统开发反向传播代理时,提高反向传播算法的样本效率是至关重要的。在这项工作中,我们提出了一个通用的框架,用来增加无模型的RL代理的训练与辅助任务,以及提高样本效率。更具体地说,我们选择添加预测用户对推荐的即时响应(正面或负面)的附加任务,即用户响应建模,增强推荐代理对状态和动作表示的学习。我们还引入了基于梯度相关分析的工具来指导模型设计。在离线实验中,通过对数亿用户轨迹上学习和评估代理策略,该方法是有效性。还在一个为数十亿用户和数千万项目服务的行业推荐平台上进行现场实验,验证了其方法的优势。
Diverse User Preference Elicitation with Multi-Armed Bandits
基于多武装匪徒的用户偏好诱导研究
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441786
个性化推荐系统依靠用户偏好的知识来产生推荐。虽然这些偏好通常是从过去用户与推荐目录的交互中获得的,但在某些情况下,这样的获取是不够的或不可用的。最广泛研究的案例是新用户,虽然其他类似的情况出现时,明确的偏好启发是有价值的。与此同时,一个看似完全不同的挑战是,在推荐系统的许多算法方法中存在一个众所周知的流行偏好。应对这一挑战的最常见方式是多样化,在向用户呈现项目之前,多样化往往会应用于推荐算法的输出。我们把这两个问题联系在一起,表现出一种紧密的关系。我们的研究结果表明,偏好诱导研究中的受欢迎偏差导致推荐中的受欢迎偏差。特别是,大多数启发方法只直接针对从收集的偏好中产生的推荐的相关性进行优化。这种对推荐准确性的关注会使收集到的偏好产生偏差。我们演示了如何在启发时直接应用多样化。我们的模型多样化了使用多武装匪徒引发的偏好,这是一个来自强化学习的经典探索-开发框架。这将导致对用户偏好的更广泛理解,并改善推荐的多样性和意外发现,而不需要事后的去偏校正。
搜索&推荐
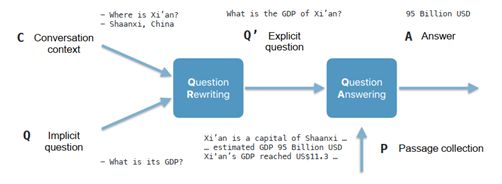
Question Rewriting for Conversational Question Answering
基于会话问答的问题重写
论文下载地址:https://arxiv.org/pdf/2004.14652
会话问答(QA)要求在先前会话轮次的语境中正确解读一个问题的能力。我们通过将对话式问答任务分解为问题重写和问题回答子任务来解决它。问题重写(QR)子任务是专门设计来将依赖于会话语境的模糊问题重新表述为可以在会话语境之外正确解释的明确问题。我们引入了一种对话问答架构,它为TREC CAsT 2019文章检索数据集设定了新的状态。此外,我们还证明了相同的二维码模型提高了问答数据集在答案跨度提取方面的性能,这是文章检索后问答的下一步。我们的评估结果表明,我们提出的二维码模型在两个数据集上都取得了接近人类水平的性能,而在端到端会话问答任务上的性能差距主要归因于问答中的错误。
Adapting User Preference to Online Feedback in Multi-round Conversational Recommendation
基于在线反馈适应的用户偏好的多轮会话推荐研究
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441791
本文研究多轮会话推荐系统中的用户偏好估计,该系统通过在一次会话中多次询问属性和推荐项目来与用户进行交互。诸如EAR的多轮CRS已经被提出,其中用户在属性级别和项目级别的在线反馈可以被用来估计用户偏好并做出推荐。尽管已经取得了初步的成功,但现有的用户偏好模型通常使用在线反馈信息作为独立的特征或训练实例,忽略了属性级和项目级反馈信号之间的关系。该关系可用于更精确地识别触发拒绝项目的原因(例如,某些属性),从而更细粒度地利用反馈信息。为了解决上述问题,本文提出了一种新的多轮偏好估计模型,称为反馈引导的偏好自适应网络(FPAN)。在FPAN,两个门控模块被设计成分别适应原始用户嵌入和项目级反馈,两者都根据在线属性级反馈。门控模块利用细粒度的属性级反馈来修正用户嵌入和粗粒度的项目级反馈来考虑反馈之间的关系来实现更准确的用户偏好估计。在两个基准上的实验结果表明,FPAN在用户偏好模型上的表现优于最先进的用户偏好模型,并且多轮用户偏好模型也可以通过使用FPAN作为其推荐组件而得到增强。
Denoising Implicit Feedback for Recommendation
去噪隐式反馈推荐
论文下载地址:https://arxiv.org/pdf/2006.04153
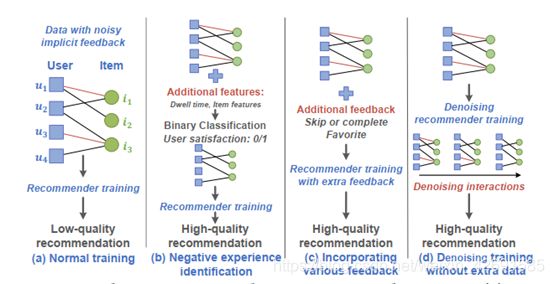
隐式反馈的普遍存在使得它们成为构建在线推荐系统的默认选择。虽然大量的隐式反馈缓解了数据稀疏问题,但缺点是它们在反映用户的实际满意度方面不够干净。例如,在电子商务中,很大一部分点击并不转化为购买,许多购买最终会得到负面评价。因此,考虑隐式反馈中不可避免的噪声对于推荐器的训练至关重要。然而,关于推荐的工作很少考虑到隐式反馈的嘈杂性质。
在这项工作中,我们探索的中心主题去噪隐式反馈推荐训练。我们发现噪声隐式反馈有严重的负面影响,即拟合噪声数据会阻碍推荐者学习实际的用户偏好。我们的目标是识别和修剪有噪声的交互,从而提高推荐训练的效率。通过观察正常的推荐训练过程,我们发现噪声反馈在早期通常具有较大的损失值。受此启发,我们提出了一种新的训练策略——自适应去噪训练,该策略在训练过程中自适应地修剪噪声交互。具体来说,我们为自适应损失公式设计了两个范例:截断损失,在每次迭代中丢弃具有动态阈值的大损失样本;自适应,降低大损失样本权重的重加权损失。我们在广泛使用的二元交叉熵损失上实例化了两个范例,并在三个有代表性的推荐数据上测试了所提出的自动数据挖掘策略。在三个基准上的大量实验表明,ADT显著提高了推荐质量。
Origin-Aware Next Destination Recommendation with Personalized Preference Attention
基于个性化偏好注意力机制的始发地感知下一目的地的推荐
论文下载地址:https://arxiv.org/pdf/2012.01915

七个真实的用户轨迹滑行数据集表明,我们的模型明显优于基线和最先进的方法。下一个目的地推荐是出租车和叫车服务的运输领域中的一项重要任务,在该领域中,给用户当前的出发地位置,向用户推荐个性化的目的地。然而,最近的推荐作品不满足这种起源意识属性,并且仅考虑从历史目的地位置学习,而没有起源信息。因此,所得到的方法不能基于用户的当前位置来学习和预测起源感知推荐,导致次优的性能和较差的实际实用性。因此,在这项工作中,我们研究的起源意识下一个目的地推荐任务。我们提出了时空源-目的地个性化偏好注意(STOD-PPA)编码-解码模型来学习源-源(OO)、目的地-目的地(DD)和源-目的地(OD)之间的关系,首先在局部和全局视图中用时空因素对源和目的地序列进行编码,然后通过个性化偏好注意力解码它们来预测下一个目的地。
Event-Driven Query Expansion
事件驱动的查询扩展
论文下载地址:https://arxiv.org/pdf/2012.12065

在网络搜索中,会发出大量与事件相关的查询。在本文中,我们试图通过利用事件来提高检索性能,并专门针对经典的查询扩展任务。我们提出了一种扩展事件相关查询的方法,首先检测与之相关的事件,然后我们将扩展候选项作为与查询和事件语义相关的术语。为了识别候选词,我们利用一种新的机制将单词和事件同时嵌入到同一个向量空间中。我们表明,在各种新闻TREC数据集上,与现有方法相比,我们提出的利用事件的方法显著提高了查询扩展性能。
An Efficient and Effective Framework for Session-based Social Recommendation
基于会话的高效社交推荐框架
论文下载地址:https://www.researchgate.net/publication/349896484_An_Efficient_and_Effective_Framework_for_Session-based_Social_Recommendation
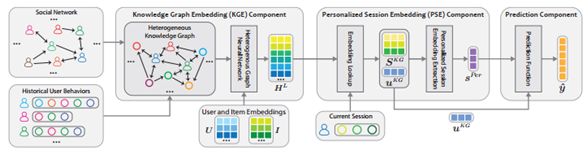
在许多基于会话的推荐应用中,社交网络通常是可用的。由于用户的兴趣受朋友的影响,推荐系统可以利用社交网络来更好地了解用户的偏好,从而提供更准确的推荐。然而,现有的基于会话的社交推荐方法效率不高。为了预测用户正在进行的会话的下一个项目,这些方法需要处理用户的朋友的许多附加会话以捕捉社会影响,而非社交感知方法(即,那些不使用社交网络的方法)只需要处理一个会话。为了解决效率问题,我们提出了一个基于会话的社会推荐的有效框架。在该框架中,首先,异构图神经网络用于学习用户和项目表示,这些表示集成了来自社交网络的知识。然后,为了生成预测,只有与当前会话相关的用户和项目表示被传递到非社交感知模型。在推理过程中,由于用户和项目表示可以预先计算,整个模型的运行速度与原始的非社交感知模型一样快,同时它可以通过利用来自社交网络的知识来实现更好的性能。除了高效之外,我们的框架还有两个额外的优势。首先,该框架是灵活的,因为它与任何现有的非社交感知模型兼容,并且可以轻松地整合除社交网络之外的更多知识。其次,我们的框架可以捕获跨会话的项目转换,而现有的方法只能捕获会话内的项目转换。在三个公共数据集上进行的大量实验证明了该框架的有效性和高效性。我们的代码可在https://github.com/twchen/SEFrame获得。
神经网络
RePBubLik: Reducing Polarized Bubble Radius with Link Insertions
RePBubLik:链接插入减少极化气泡半径
论文下载地址:https://arxiv.org/pdf/2101.04751

表达不同观点的页面之间的超链接拓扑图可能会影响读者对不同内容的感触。结构偏好可能会把读者困在一个“两极分化”的泡泡里,无法接触到其他观点。我们将读者的行为建模为随机行走。如果从一个节点到不同观点的页面的随机行走的预期长度很大,则该节点处于“极化”气泡中。图形结构偏差是高度极化气泡的半径之和。我们研究通过边缘插入来减少结构偏差的问题。“修复”所有具有高极化气泡半径的节点很难在对数因子内近似,因此我们专注于找到最佳的k边来插入,以最大限度地减少结构偏差。我们提出了RePBubLik,一种利用随机游走贴近度中心的变体来选择要插入的边的算法。RePBubLik在温和的条件下得到一个常数因子近似。它比现有的边推荐方法更快地减少了结构偏差,包括一些旨在减少图极化的方法。
Node Similarity Preserving Graph Convolutional Networks
基于节点相似性的图卷积网络
论文下载地址:https://arxiv.org/pdf/2011.09643
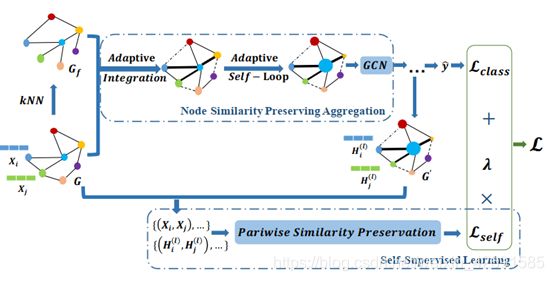
图神经网络由于其强大的图表示学习能力,在各种实际应用中取得了巨大的成功。GNNs通过聚集和转换节点邻域内的信息来探索图结构和节点特征。然而,通过理论和实证分析,我们揭示了神经网络的聚集过程往往会破坏原始特征空间中的节点相似性。在许多场景中,节点相似性起着至关重要的作用。因此,它激发了所提出的框架SimP-GCN,该框架可以有效地保持节点相似性,同时利用图结构。具体来说,为了平衡图结构和节点特征的信息,我们提出了一种自适应集成图结构和节点特征的特征相似度保持聚合。此外,我们使用自监督学习来明确地捕捉节点之间复杂的特征相似和相异关系。我们在包括三个分类图和四个分解图的七个基准数据集上验证了SimP-GCN算法的有效性。结果表明,辛普森-GCN优于代表性的基线。进一步的探索显示了所提出的框架的各种优点。GCN简易程序在https://github.com/ChandlerBang/SimP-GCN实施。
BiTe-GCN: A New GCN Architecture via Bidirectional Convolution of Topology and Features on Text-Rich Networks
BiTe-GCN:基于网络拓扑和特征双向卷积的文本GCN模型
论文下载地址:https://arxiv.org/pdf/2010.12157
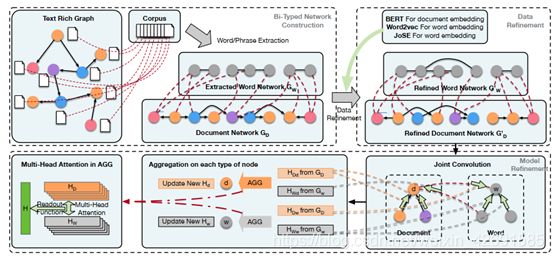
图卷积网络旨在通过堆叠图卷积层集成高阶邻域信息来获得节点嵌入,在节点分类和链路预测等网络分析任务中显示出较好的效果。然而,遗传神经网络的一个基本弱点,即拓扑限制,包括拓扑的过平滑和局部同质性,限制了它们表示网络的能力。现有的解决这些拓扑限制的研究通常只关注网络拓扑上特征的卷积,这不可避免地严重依赖于网络结构。此外,大多数网络都是文本丰富的,因此不仅要整合文档级信息,还要整合本地文本信息,这一点非常重要,但现有方法往往会忽略这一点。为了解决这些限制,我们提出了BiT-GCN,一种新颖的GCN体系结构模型,通过双向卷积的拓扑和文本丰富的网络功能。具体来说,我们首先将原始的文本网络转换成一个增强的双类型异构网络,从文本中捕获全局文档级信息和本地文本序列信息;然后我们引入判别卷积机制,在这个扩充的双类型网络上执行卷积,在同一个系统中实现拓扑和特征的卷积,并为给定的学习目标自动学习这两个部分(即网络部分和文本部分)的不同贡献。在文本丰富的网络上进行的大量实验表明,我们的新架构通过突破性的改进超越了现有技术。此外,该架构还可以应用于多种电子商务搜索场景,如JD搜索,在JD数据集上的实验表明了该架构相对于相关方法的优越性。
Deconfounding with Networked Observational Data in a Dynamic Environment
基于动态环境的网络观测数据
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441818
因果推断中的一个基本问题是学习个体治疗效果(ITE)。针对每个数据实例,评估某一治疗(如药物处方)对重要结果(如疾病治愈)的因果效果,但是大多数现有方法的有效性通常受到隐藏混杂因素的限制。最近的研究表明,数据之间的辅助关系信息可以用来减轻混淆偏差。然而,这些工作假设观测数据和它们之间的关系是静态的,而在现实中,它们都将随着时间的推移而不断演变,我们将这些数据称为时间演变的网络观测数据。
本文对这类数据的ITE估计进行了初步探讨。由于以下挑战,该问题仍然是困难的:(1)建模随时间演变的网络观测数据的演变模式;(2)用当前数据和历史信息控制隐藏的混杂因素;(3)缓解对照组和治疗组之间的差异。为了应对这些挑战,我们提出了一个新的ITE估计框架动态网络观测数据解耦器,旨在通过利用当前的网络观测数据和历史信息来了解隐藏混杂因素随时间的表现。此外,一种新的基于敌对学习的表示平衡方法被引入无偏ITE估计。大量的实验验证了我们的框架在衡量最先进的基线时的优越性。该实现可在https://github.com/jma712/DNDC获得。
Balanced Influence Maximization in the Presence of Homophily
同性存在下的平衡影响最大化
论文下载地址:https://web.stanford.edu/~msaveski/assets/publications/2021_balanced_inf_max/paper.pdf

所提算法在改善不同类别暴露节点之间的平衡方面的有效性。影响力最大化的目标是选择一组种子用户,他们将通过网络以最佳方式传播信息。在本文中,我们研究了应用传统的影响最大化算法如何影响最终将接触到消息的不同受众类别(如性别细分)之间的平衡。更具体地说,我们研究了结构同质性(即,与相似的其他人联系的趋势)和影响扩散同质性(即,受相似的其他人影响的趋势)如何影响激活节点之间的平衡。我们发现,即使在适度的同质性水平下,暴露节点之间的平衡也明显差于整个群体之间的平衡,导致一个组的显著劣势。为了应对这一挑战,我们提出了一种算法,在保持传统影响最大化算法的理论保证的同时,联合最大化节点间的影响和平衡。我们在多个合成数据集和四个真实数据集上运行了一系列实验来演示。
Learning and Updating Node Embedding on Dynamic Heterogeneous Information Network
动态异构信息网络中节点嵌入的学习和更新
论文下载地址:https://dl.acm.org/doi/10.1145/3437963.3441745
异构信息网络由多种类型的边和节点组成,这些边和节点具有很强的能力来表示支撑网络结构的丰富语义。最近,网络动力学已经在许多任务中被研究,例如社交媒体分析和推荐系统。然而,现有的方法主要集中在静态网络或动态同构网络上,这些方法在动态异构信息网络的建模方面能力不足或效率低下。本文提出了一种动态异构信息网络嵌入方法,该方法可以在网络演化时更新嵌入信息。该方法包含两个关键设计:(1)一个动态时间序列嵌入模块,它采用分层注意力机制聚集邻居特征和时间随机游走来捕获动态交互;(2)在线实时更新模块,其通过动态算子有效地更新计算的嵌入。在三个真实数据集上的实验证明了我们的模型在时态链接预测任务上的有效性。