信用评分卡模型 —— 基于Lending Club数据
1、前言
Lending Club是全球最大的撮合借款人和投资人的线上金融平台,它利用互联网模式建立了一种比传统银行系统更有效率的、能够在借款人和投资人之间自由配置资本的机制。本次分析的源数据基于Lending Club 2017年全年和2018年一二季度的公开数据,目的是建立一个贷前评分卡。数据原址:https://www.lendingclub.com/info/download-data.action 。
2、数据清洗
2.1 导入分析模块和源数据
import numpy as np
import pandas as pd
from scipy.stats import mode
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
import chisqbin
import warnings
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,auc
from imblearn.over_sampling import SMOTE
pd.set_option('display.max_columns',200)
warnings.filterwarnings('ignore')
%matplotlib inline
names=['2017Q1','2017Q2','2017Q3','2017Q4','2018Q1','2018Q2']
data_list=[]
for name in names:
data=pd.read_table('C:/Users/H/Desktop/lending_club/LoanStats_'+name+'.csv',sep=',',low_memory=False)
data_list.append(data)
loan=pd.concat(data_list,ignore_index=True)
接下来,我们看一下目标变量loan_status,
loan_status=pd.DataFrame({
'意思':['还款中','审核通过','全额结清','宽限期','逾期(31-120天)','逾期(16-30天)','坏账','违约'],'数量':loan['loan_status'].value_counts().values},
index=loan['loan_status'].value_counts().index)
print(loan_status)
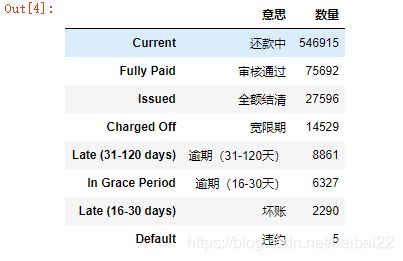
因为主要目的是贷前评分,这里只考虑全额结清和未按时还款的的情况,还款中暂时不考虑。
loan['loan_status']=loan['loan_status'].replace(['Fully Paid','In Grace Period','Late (31-120 days)','Late (16-30 days)','Charged Off','Default'],
['0','1','1','1','1','1'])
loan=loan[loan['loan_status'].isin(['0','1'])]
loan['loan_status']=loan['loan_status'].astype('int')
2.2 缺失值处理
数据集的变量虽然有100多个,但其中不少变量包含大量缺失值,缺失比例在50%以上,还有部分变量与我们的目标变量关系不大,这些变量一并剔除。
null_cols=loan.isna().sum().sort_values(ascending=False)/float(loan.shape[0])
null_cols[null_cols > .3]
loan=loan.dropna(thresh=loan.shape[0]*.7,axis=1)
names=['sub_grade','emp_title','pymnt_plan','title','zip_code','total_rec_late_fee','recoveries','collection_recovery_fee','last_pymnt_d','last_pymnt_amnt',
'last_credit_pull_d','collections_12_mths_ex_med','policy_code','acc_now_delinq','num_tl_120dpd_2m','num_tl_30dpd','hardship_flag','debt_settlement_flag',
'funded_amnt','funded_amnt_inv','out_prncp_inv','total_pymnt','total_pymnt_inv','out_prncp','total_rec_prncp','total_rec_int']
loan=loan.drop(names,axis=1)
loan=loan.drop(loan[loan['earliest_cr_line'] == '1900/1/0'].index)

接下来进行进行数据的清洗,把数据转成需要的形式,同时对缺失值进行插补。
loan['int_rate']=loan['int_rate'].str.replace('%','').astype('float')
loan['revol_util']=loan['revol_util'].str.replace('%','').astype('float')
loan['issue_d']=pd.to_datetime(loan['issue_d'],format='%Y/%m/%d')
loan['earliest_cr_line']=pd.to_datetime(loan['earliest_cr_line'],format='%Y/%m/%d')
loan['mth_interval']=loan['issue_d']-loan['earliest_cr_line']
loan['mth_interval']=loan['mth_interval'].apply(lambda x: round(x.days/30,0))
loan['issue_m']=loan['issue_d'].apply(lambda x: x.month)
loan=loan.drop(['issue_d','earliest_cr_line'],axis=1)
loan['emp_length']=loan['emp_length'].fillna('0')
loan['emp_length']=loan['emp_length'].str.replace(' year','')
loan['emp_length']=loan['emp_length'].str.replace('s','')
loan['emp_length']=loan['emp_length'].replace(['10+','< 1'],['11','0']).astype('int')
loan['income_vs_loan']=loan['annual_inc']/loan['loan_amnt']
loan['delinq_2yrs']=loan['delinq_2yrs'].astype('int')
loan['revol_bal']=loan['revol_bal'].astype('int')
loan['total_acc']=loan['total_acc'].astype('int')
剩下的含缺失值的变量都是浮点属性,我们用这些变量的众数进行查补。
na_cols=loan.isna().sum()[loan.isna().sum() > 0].index.values
print(loan[na_cols].dtypes)
for col in na_cols:
loan[col][loan[col].isna()]=mode(loan[col][loan[col].notna()])[0][0]

初步的数据清洗已经完毕,所有变量未含有缺失值。
3、特征工程
最后的模型是一个评分卡,我们需要知道哪些变量对目标变量loan_status最重要,接下来会进行一系列方式对变量进行筛选。
3.1 强相关性变量
首先,剩下的变量中有一些相关性较强,这些变量不利后面的操作,需要剔除。
num_features=[]
obj_features=[]
for i in loan.columns.values:
if loan[i].dtype == 'object':
obj_features.append(i)
else:
num_features.append(i)
num_features.remove('loan_status')
fig,ax=plt.subplots(figsize=(20,20))
sns.heatmap(loan[num_features].corr().round(2))
cor=(np.abs(loan[num_features].corr()) < 0.6)
l=[]
for i in range(len(num_features)):
s=(cor.iloc[i+1:,i].sum() == (len(num_features)-i-1))
l.append(s)
num_feats=[]
for i in range(len(num_features)):
if l[i]:
num_feats.append(num_features[i])
fig,ax=plt.subplots(figsize=(20,20))
sns.heatmap(loan[num_feats].corr().round(2),annot=True)
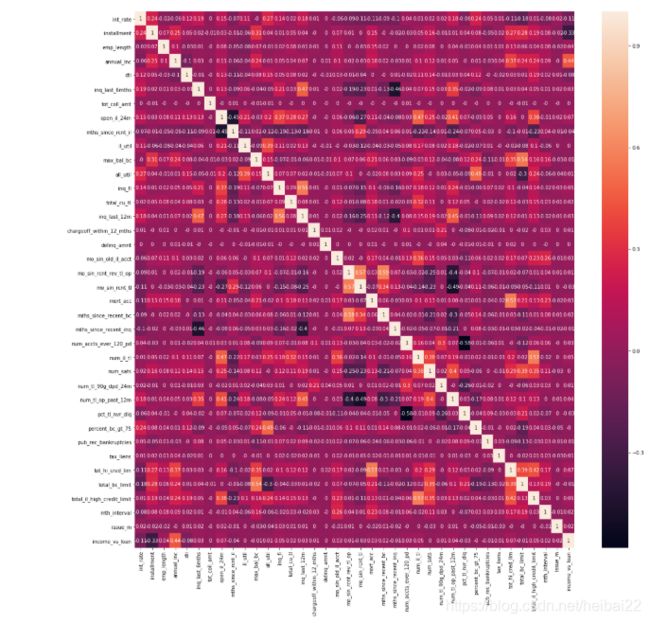
这是强相关变量删除后的相关图,变量间的相关系数不高于0.6。
3.2 随机森林过滤变量
接下来,通过随机森林对变量进行过滤,按照变量在随机森林模型中的重要性排序,可以剔除后面重要性很低的变量
loan_1=loan.copy()
loan_1[obj_features]=loan_1[obj_features].apply(LabelEncoder().fit_transform)
data_1=loan_1[loan_1['loan_status'] == 1]
data_0=loan_1[loan_1['loan_status'] == 0]
data_1_train,data_1_test=train_test_split(data_1,test_size=.3,random_state=12)
data_0_train,data_0_test=train_test_split(data_0,test_size=.3,random_state=12)
train=pd.concat([data_1_train,data_0_train])
test=pd.concat([data_1_test,data_0_test])
train_X=train.drop(['loan_status'],axis=1)
train_y=train['loan_status']
test_X=test.drop(['loan_status'],axis=1)
test_y=test['loan_status']
#resampled_X,resampled_y=SMOTE(random_state=12).fit_sample(train_X,train_y)
rf=RandomForestClassifier(n_estimators=500,max_depth=10,random_state=1).fit(train_X,train_y)
importance=pd.DataFrame({
'features':train_X.columns.values,'importance':rf.feature_importances_})
importance.sort_values(by='importance',ascending=False).style.bar()
loan=loan.drop(importance[importance['importance'] < 0.01]['features'].values,axis=1)
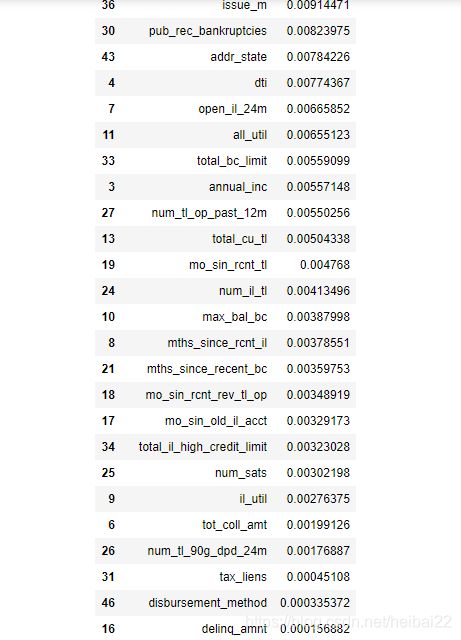
3.3 卡方分箱
在逻辑回归建立评分卡的过程中,变量的分箱是很重要的一步。下面将对剩下的连续性变量进行卡方分箱,并计算所有变量的WOE和IV值,并根据IV值进行最后的筛选。
purpose=chisqbin.BadRateEncoding(loan,'purpose','loan_status')
#state=chisqbin.BadRateEncoding(loan,'addr_state','loan_status')
loan['purpose']=purpose['encoding']
#loan['addr_state']=state['encoding']
num_features=[]
obj_features=[]
for i in loan.columns.values:
if loan[i].dtype == 'object':
obj_features.append(i)
else:
num_features.append(i)
num_features.remove('loan_status')
train,test=train_test_split(loan,test_size=.3,random_state=12)
cuts=[]
for i in num_features:
cut=chisqbin.ChiMerge(train,i,'loan_status',max_interval=5)
cut=[float('-inf')]+cut
cut.append(float('inf'))
cuts.append(cut)
train[i]=pd.cut(train[i],cut)
columns=train.columns.values.tolist()
columns.remove('loan_status')
WOEs={
}
IVs=[]
for i in columns:
woe,iv=chisqbin.CalcWOE(train,i,'loan_status')
WOEs[i]=woe
IVs.append(iv)
IV=pd.DataFrame({
'feature':columns,'IV':IVs})
IV.sort_values(by='IV',ascending=False).style.bar()

选取出IV值大于0.02的变量,用它们对应的WOE对数据进行替换。
features=IV.loc[IV['IV'] > 0.02,'feature'].values
features=features.tolist()
features.append('loan_status')
for i in range(len(columns)):
col=columns[i]
train[col]=train[col].replace(WOEs[col])
for i in range(len(num_features)):
col=num_features[i]
test[col]=pd.cut(test[col],cuts[i])
for i in range(len(columns)):
col=columns[i]
test[col]=test[col].replace(WOEs[col])
4、建立评分卡
准备工作已经完成,下面开始建立评分卡。
首先先建立逻辑回归模型,获取变量的参数,同时可以发现,变量的显著性检验全部通过。
train=train[features]
test=test[features]
train_X=train.drop('loan_status',axis=1)
train_y=train['loan_status']
test_X=test.drop('loan_status',axis=1)
test_y=test['loan_status']
train_X=sm.add_constant(train_X)
logit=sm.Logit(train_y,train_X).fit()
logit.summary()
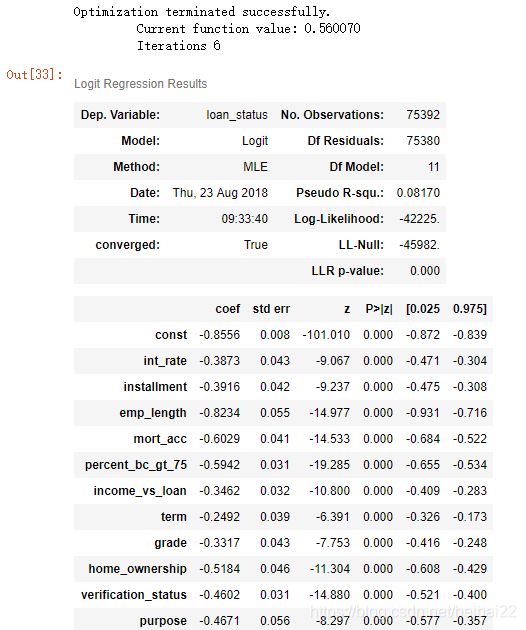
计算得出模型的AUC为0.69,水平一般,后面会进行优化。
test_X=sm.add_constant(test_X)
result=logit.predict(test_X)
fpr,tpr,th=roc_curve(test_y,result)
rocauc=auc(fpr,tpr)
plt.plot(fpr,tpr,'b',label='AUC = %.2f' %rocauc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0,1])
plt.ylim([0,1])
plt.xlabel('fpr')
plt.ylabel('tpr')
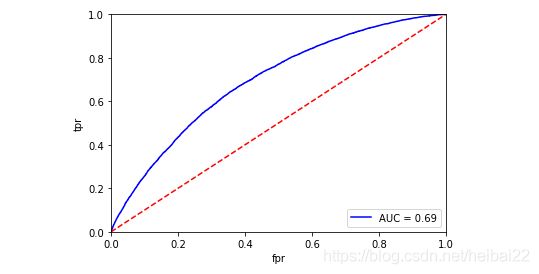
最终,我们可以得到如下的评分卡。
B=20/np.log(2)
A=600+20*np.log(1/60)/np.log(2)
basescore=round(A-B*logit.params[0],0)
scorecard=[]
#features.remove('loan_status')
for i in features:
woe=WOEs[i]
interval=[]
scores=[]
for key,value in woe.items():
score=round(-(value*logit.params[i]*B))
scores.append(score)
interval.append(key)
data=pd.DataFrame({
'interval':interval,'scores':scores})
scorecard.append(data)
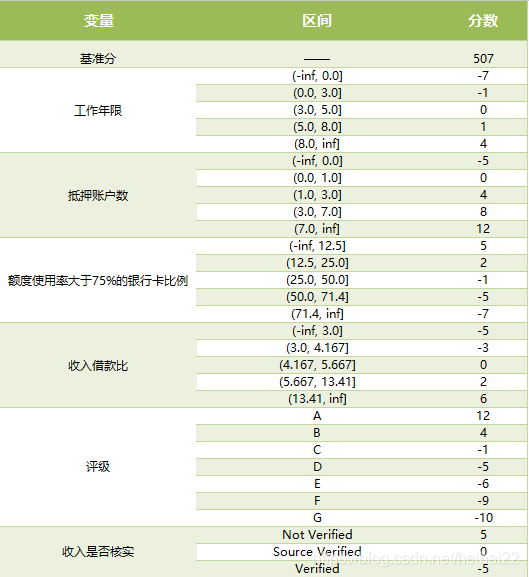

5、小结
经过上述步骤,建立了一个基本的评分卡,由于源数据缺失客户的人口信息数据(当然,lending club也不可能透露),所以评分卡还是有瑕疵,AUC值只有0.69,后续会改进代码和流程。