四、分组函数(多行函数)
分组函数作用于一组数据,并对一组数据返回一个值。

组函数语法:
SELECT [column,] group_function(column), ...
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
1.组函数(多行函数:多个行---->一个值)
--sum:求和,会忽略空值
--计算工资总额
SQL> select sum(sal) from emp;
-->结果:29025
--COUNT(expr):计数, 返回 expr不为空的记录总数。
--计算员工人数
SQL> select count(*) from emp;
-->结果:14
注:
可以把count函数和distinct关键字结合使用统计表中非空且不重复的记录数,即:
COUNT(DISTINCTexpr) 返回expr非空且不重复的记录总数
--avg:求均值
--平均奖金
SQL> select sum(comm)/count(*) 方式一,sum(comm)/count(comm) 方式二, avg(comm) 方式三 from emp;
-->结果:

注:
1)这三个结果哪个对?不好说,要看具体的业务场景
2)组函数会自动滤空
看下面这个语句的执行结果:(comm列只有4行有值)
SQL> select count(*), count(comm) from emp;
-->结果:

3)可以使用NVL函数使分组函数无法忽略空值
SQL> select count(*), count(nvl(comm,0)) from emp;
-->结果:

--max,min:分别求最大和最小值,会忽略空值
SQL> select max(sal) 最高的工资,min(sal) 最低的工资 from emp;
-->结果:
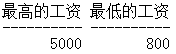
2.group by子句:可以使用GROUP BY 子句将表中的数据分成若干组
--分组数据: 求每个部门的平均工资
SQL> select deptno,avg(sal) from emp group by deptno;
-->结果:

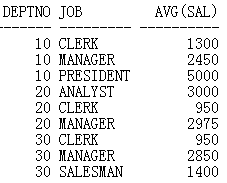
--group by后面接多列的情况
SQL> select deptno,job,avg(sal)
from emp
group by deptno,job
order by 1;
-->结果:
注:
所用包含于SELECT 列表中,而未包含于组函数中的列都必须包含于 GROUP BY 子句中。
举例:
SQL> select deptno,job,avg(sal)
from emp
group by deptno
order by 1;
这是错误的,因为job未包含在组函数中,因此其必须要包含于group by子句中,否则报错。
3.having子句:过滤分组
--求部门平均工资大于2000的部门
SQL> select deptno,avg(sal)
from emp
group by deptno
having avg(sal)> 2000;
-->结果:

注:
1.使用 HAVING 过滤分组:
1)行已经被分组。
2)使用了组函数。
3)满足HAVING 子句中条件的分组将被显示。
2.不能在 WHERE 子句中使用组函数(注意)。如果需要使用组函数的返回值过滤数据可以使用 HAVING 子句
--求10号部门的平均工资(下面两条语句结果一样,哪个好?)
SQL> select deptno,avg(sal)
from emp
group by deptno
having deptno=10;
SQL> select deptno,avg(sal)
from emp
where deptno=10
group by deptno;
-->结果:

补:Oracle中的sql优化:
2.在既可以使用having也可以使用where过滤数据的情况下,应尽可能使用where。当数据量很大时(上亿+),where会先筛选出需要的数据再计算,而不是先计算再过滤
4.group by增强:group by rollup(a,b)
--不同部门,不同职位的工资小计,以及最后的工资总计
SQL> break on deptno skip 1
SQL> select deptno,job,sum(sal)
from emp
group by rollup(deptno,job);
-->结果:

注:
1.第一条语句:break on deptno skip 1
是sqlplus的设置语句,break on deptno表示相同的部门号只显示一次,连上skip 1表示不同的部门号之间空一行。
2.group by rollup(a,b) = group by a,b + group by a + group by null