【python爬虫】爬取洛谷习题并转为md格式
背景
因为自己经常需要把做过的题目记录为博文,为了让读者方便阅读所以还要把题目摘过来,但直接在网页复制粘贴再转格式太麻烦了,就想着写个脚本爬下来并自动转为md格式,就不用在复制题目上浪费时间了。下面是编写流程。
逻辑分析
爬取逻辑
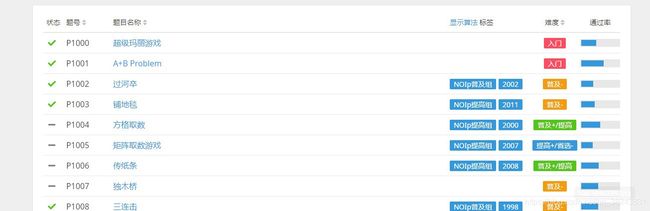
从题库中可以看出题目编号是从1000开始连着的,所以都没必要模拟分页了(特殊题号会提供方法直接获取md),直接https://www.luogu.com.cn/problem/+题目编号就为题目网页。但有些题号不存在或无权查看,所以还需要做一下判断。
主函数:
baseUrl = "https://www.luogu.com.cn/problem/P"
savePath = "C:\\Users\\46361\\Documents\\洛谷习题\\problems\\"
minn = 1000
maxn = 2000 #最大题号
def main():
print("计划爬取到P{}".format(maxn))
for i in range(minn,maxn+1):
print("正在爬取P{}...".format(i),end="")
html = getHTML(baseUrl + str(i))
if html == "error":
print("爬取失败,可能是不存在该题或无权查看")
else:
problemMD = getMD(html)
print("爬取成功!正在保存...",end="")
saveData(problemMD,"P"+str(i)+".md")
print("保存成功!")
print("爬取完毕")
转为md逻辑
先分析题目网页源码

可以看出,主要有用的标记为h1、h2、h3,将这些标记转为对应个数的#号+空格,然后去除其余标记即可。
转换代码:
core = bs.select("article")[0]
md = str(core)
md = re.sub(""
,"# ",md)
md = re.sub(""
,"## ",md)
md = re.sub(""
,"#### ",md)
md = re.sub("]*>","",md)
完整源码
import re
import urllib.request,urllib.error
import bs4
baseUrl = "https://www.luogu.com.cn/problem/P"
savePath = "C:\\Users\\46361\\Documents\\洛谷习题\\problems\\"
minn = 1316
maxn = 2000 #最大题号
def main():
print("计划爬取到P{}".format(maxn))
for i in range(minn,maxn+1):
print("正在爬取P{}...".format(i),end="")
html = getHTML(baseUrl + str(i))
if html == "error":
print("爬取失败,可能是不存在该题或无权查看")
else:
problemMD = getMD(html)
print("爬取成功!正在保存...",end="")
saveData(problemMD,"P"+str(i)+".md")
print("保存成功!")
print("爬取完毕")
def getHTML(url):
headers = {
"user-agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 85.0.4183.121 Safari / 537.36"
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
if str(html).find("Exception") == -1: #洛谷中没找到该题目或无权查看的提示网页中会有该字样
return html
else:
return "error"
def getMD(html):
bs = bs4.BeautifulSoup(html,"html.parser")
core = bs.select("article")[0]
md = str(core)
md = re.sub(""
,"# ",md)
md = re.sub(""
,"## ",md)
md = re.sub(""
,"#### ",md)
md = re.sub("]*>","",md)
return md
def saveData(data,filename):
cfilename = savePath + filename
file = open(cfilename,"w",encoding="utf-8")
for d in data:
file.writelines(d)
file.close()
if __name__ == '__main__':
main()
实现效果
执行后,控制台输出:

保存文件夹:
打开效果
注:此为复制到csdn编写博客页面上的效果,如果用例如有道云笔记打开,数学公式需要用``括起来,在getMD方法添加替换的代码即可。

补充(单个转换)
如果需要快速将单个题目转为md格式,只要复制上述代码新建脚本然后做出如下改动即可.
baseUrl = "https://www.luogu.com.cn/problem/" #去掉了P
#savePath = "C:\\Users\\46361\\Documents\\洛谷习题\\problems\\"
def main():
pNum = input("请输入题目编号:")
html = getHTML(baseUrl+pNum)
if html == "error":
print("爬取失败,可能是不存在该题或无权查看")
else:
problemMD = getMD(html)
print("爬取转换完成!\nmd为:\n")
print(problemMD)