JavaScript 基础(超详细)
前言
这篇笔记大概囊括了 JavaScript 基础的所有知识点。知识点的梳理参照了《JavaScript 高级程序设计》的内容,所以这算是一篇读书笔记。知识点的具体介绍主要有书中重要讲述、代码示例、思维图表、重难点解析、个人思考总结和他人的启发。虽不敢说这是最详细的笔记,但对于每个知识我都会尽力将自己的所思所想清楚地记录下来并分享。适合 js 初学者去查看特定知识点或者已经自学完 js 的伙伴去完成查漏补缺的过程。觉得对你有用的话记得点赞。 其他相关笔记还有如下几篇:
- JavaScript 基础(超详细)
- js 中的引用类型(内置对象)
- js 中的对象属性——configurable、writable 等(数据属性和访问器属性)
- js 中原型、原型链和继承概念(详细全面)
- 函数使用进阶——递归——闭包
目录
-
- 前言
- 1. JavaScript 简介
-
- 1.1 概述
- 1.2 ECMAScript 的实现
- 1.3 JavaScript 的使用
-
- 1.3.1 在网页中使用 javaScript
- 1.3.2 代码屏蔽
- 2. 基础概念
-
- 2.1 语法
-
- 2.1.1 区分大小写
- 2.1.2 标识符
- 2.1.3 关键字和保留字
- 2.1.4 注释
- 2.1.5 语句中可选的分号
- 2.1.6 严格模式
- 2.2 变量
-
- 2.2.1 变量声明和初始化
- 2.3 数据类型
-
- 2.3.1 typeof 操作符
- 2.3.2 Undefined 类型
- 2.3.3 Null 类型
- 2.3.4 Boolean 类型
- 2.3.5 Number 类型
- 2.3.6 String类型
- 2.3.7 Object 类型
- 2.3.8 数据类型转换
- 2.4 操作符
-
- 2.4.1 算数运算符(含++、- -)
- 2.4.2 赋值运算符
- 2.4.3 比较运算符
- 2.4.3 逻辑运算符
- 2.4.4 三元运算符
- 2.4.5 位运算符
- 2.4.6 其他运算符
- 2.4.7 运算符优先级
- 2.5 语句
-
- 2.5.1 分支语句
- 2.5.2 循环语句
- 2.5.3 label、break 和 continue 语句
- 2.5.4 其他语句
- 2.6 初识函数
-
- 2.6.1 函数声明
- 2.6.2 函数的参数
- 2.6.3 js 中函数没有重载
- 3. 变量、作用域链和内存问题
-
- 3.1 变量
-
- 3.1.1 基本类型和引用类型的值
- 3.1.2 变量复制
- 3.1.3 参数传递
- 3.1.4 instanceof 操作符
- 3.2 执行环境及作用域
-
- 3.2.1 执行环境
- 3.2.2 全局执行环境和函数执行环境
- 3.2.3 作用域链
- 3.2.4 延长作用域
- 3.2.5 变量预解析
- 3.3 垃圾收集
-
- 3.3.1 垃圾收集机制及变量的生命周期
- 3.3.2 标记清除(mark-and-sweep)
- 3.3.3 引用计数(了解)
- 3.3.4 内存的管理
- 总结
1. JavaScript 简介
1.1 概述
JavaScript 是 Netscape 公司的布兰登 · 艾奇(Brendan Eich)为 1995 年 2 月发布的 Netscape Navigator 2 开发的一种名为 LiveScript 脚本语言。在 Netscape Navigator 2 浏览器发布前夕将名字改为 JavaScript 。由于 Javascript1.0 取得巨大成功,Netscape 又在 Netscape Navigator3 中发布了 Javascript1.1 。1996 年 8 月,微软在 Internet Explorer3 中加入名为 JScript 的 Javascript 实现。1997年欧洲计算机制造商协会(ECMA,European Computer Manufacturers Association)以 Javascript1.1 为蓝本完成了 ECMA-262 — 定义一种名为 ECMAScript(发音为 “ek-ma-script”)的新脚本语言标准。 自此给浏览器开发商就开始致力于将 ECMAScript 作为各自 javascript 实现的基础。
JavaScript 诞生时,其主要目的是处理一些由服务器负责的输入验证操作(前端验证)。如今,JavaScript 的用途早已不再局限于简单的数据验证,而是具备了与浏览器窗口及其内容等几乎所有方面的交互的能力。
1.2 ECMAScript 的实现
ECMAScript 代表的是一种语法标准,而我们常说的 javaScript 指的是该标准在不同浏览器环境下的实现。JavaScript 的实现包括下列三个部分组成。
- 核心(ECMAScript)
- 文档对象模型(DOM)
- 浏览器对象模型(BOM)
还有在 node 环境下的实现使其具备了服务器端编程语言的能力,其在node 环境下的实现(node.js)包括两个部分组成。
- ECMAScript
- Node 模块API
1.3 JavaScript 的使用
1.3.1 在网页中使用 javaScript
想要在网页中使用 JavaScript 有三种方式
- 通过在
标签中直接编写 JavaScript 程序代码, script 标签可以放在 html 文档的任何位置。 - 作为某个元素的事件属性或者超链接的 herf 属性值。
- 通过
引入外部的 js 文件。
注意:方式三中的 script 标签中不允许再编写脚本。
1.3.2 代码屏蔽
在浏览器不支持 JavaScript 脚本或者脚本被禁用的时候,为了让页面平稳地退化可以使用一个 标签。这个元素可以包含能够出现在文档 body 元素中的任何 html 元素(script 标签除外)。其包含的内容只有在上述特殊情况下才会呈现。
<html>
<head>...head>
<body>
<noscript>
<p>本页面需要浏览器支持(启用)JavaScript。p>
noscript>
body>
html>
2. 基础概念
2.1 语法
2.1.1 区分大小写
ECMAScript 中的一切(变量、函数名和操作符)都区分大小写。例如 temp 和 Temp 指的是两个不同的变量。typeof 不能作为变量名或者函数名,但是 typeOf 则可以。
2.1.2 标识符
标识符是指变量、函数或者对象属性的名字,或者函数的参数等。遵循以下命名规则:
- 由字母、数字、美元符号 $ 和下划线(_)组成。
- 不能以数字开头。
- 一般采用驼峰命名方法,即第一个字母小写,其余每个单词的首字母大写。例如:userName、averageTemp 等。
- 不能使用关键字或者保留字作为标识符。
2.1.3 关键字和保留字
关键字是在 ECMA 中已经规定好用途的一组特殊标识。关键字可用于表示控制语句的开始或结束,或者用于执行特定的操作等。关键字是语言保留的,不能用作标识符。以下就是 ECMAScript (ES5) 的全部关键字。
/*
* break do instanceof typeof
* case else new var
* catch finally return void
* continue for switch while
* debugger function this with
* default if throw delete
* in try
*/
保留字是指一组在这门语言中还没有任何特定的用途,但是可能在将来被用作关键字的标识,所以也不能用作标识符。以下是 ES3 定义的全部保留字。
/*
* abstract enum int short boolean export interface
* static byte extends long super char final
* native synchronized class float package throws
* const goto private transient debugger implements
* protected volatile double import public
*/
// es5在非严格模式下运行时的保留字缩减为下列这些:
// class enum extends const export import super
// es5在严格模式下运行时还对以下保留字施加了限制
// implements package public interface private static let
// protected yield
学过 ES6 或者更高版本后会发现 ES3 ES5 的很多保留字已经作为关键字使用。保留字和关键字不需要我们特别去学习记忆,只做一些了解,避免在以后变量、函数等命名时误用。
2.1.4 注释
ECMAScript 里面的单行注释以两个斜杠开头不能换行;块级注释以 /* 开头,以 */ 结尾表示,可以换行。为提高块级注释的可读性可以像上面示例一样在每行前面添加一个星号。
// 这是单行注释内容(双斜杠后面要加一个空格)
/*
这里是多行注释的内容
可以换行
*/
2.1.5 语句中可选的分号
ECMAScript 中的语句以一个分号结尾。但分号并不是必须的,如果省略则由解释器来确定语句的结尾(不推荐不写分号)。加上分号可以避免很多错误,或者可以更加放行地对代码进行压缩。加上分号解释器就不必要花时间判断推测应该在哪里插入分号了,提高了代码性能。况且解释器也可能推测加错分号的位置导致程序出错。总而言之为了代码更加清晰准确建议使用分号结尾。有关分号的详细说明可以阅读 JavaScript 权威指南章节2.5 。
2.1.6 严格模式
ES5 引入了严格模式(strict mode)的概念。严格模式是为 JavaScript 定义了一种不同的解析与执行模型。在严格模式下,一些不确定的行为将得到处理,对某些不安全的操作也会抛出错误。严格模式可以在整个脚本启用,也可以只在某个函数块作用域中启用严格模式。
- 整个脚本启用严格模式,可以在脚本顶部添加代码
"use strict"; - 只在某个函数块作用域启用严格模式则在函数体顶部添加代码
"use strict";
个人对严格模式的理解:严格模式只是要求开发者以更加严谨的语法和逻辑去编写更加安全程序,而并不是大量的更改了我们学习的语法。例如严格模式下无法再意外创建全局变量。在普通的JavaScript里面给一个错误命名的变量名赋值会使全局对象新增一个属性并继续“工作”(尽管将来可能会失败:在现代的JavaScript中有可能)。严格模式中意外创建全局变量被抛出错误。要了解严格模式的详细介绍可以查阅 MDN 文档。
2.2 变量
ECMAScript 的变量是松散类型的,所谓松散类型是指变量声明时不用指明数据类型,在变量更新时也可以改变变量的数据类型。变量仅仅是一个用于保存值得占位符而已。
2.2.1 变量声明和初始化
// 变量的声明使用关键字 var(variable的前三个字母)
var temp;
temp = 30;
// 更新变量的值,可以改为不同类型的值但是不提倡这么做
temp = 'TKOP_';
// 声明的同时进行赋值,即变量的初始化
var flag = true;
// 同时声明或者初始化几个变量
var a = 10,
b = '扬尘',
c,
d = false;
2.3 数据类型
ECMAScript 中一共有 6 种数据类型,有 5 种简单数据类型(也称基本数据类型):Undefined、Null、Boolean、Number 和 String,还有 1 种复杂数据类型 Object。ECMAScript 不支持任何创建自定义类型的机制,而所有值最终都将是上述 6 种数据类型之一。(ES6 中新增一种 Symbol 类型,那个是 ES6 的内容暂不在此记录)
2.3.1 typeof 操作符
typeof 操作符可以用来检测字面量或者变量的数据类型。对一个值使用 typeof 操作符返回表示该值数据类型的字符串。typeof 是一个操作符而不是函数,其操作数可以是变量也可以是字面量。
var a, b = null,
c = true,
d = 10,
e = 'TKOP_',
f = {
};
a = typeof(a);
b = typeof(b);
c = typeof(c);
d = typeof(d);
e = typeof(e);
f = typeof(f);
console.log(a, b, c, d, e, f); // ->undefined object boolean number string object
function fn() {
};
console.log(typeof fn); // ->function
问题1:为什么使用 typeof 检测 null 的数据类型不是 null 而是 Object ?
问题2:在 6 大数据类型中没有 function 数据类型,为什么使用 typeof 检测函数的数据类型返回 function ?
2.3.2 Undefined 类型
Undefined 类型只有一个值,即特殊的 undefined 。在使用 var 声明变量但未对变量加以初始化时,该变量的值就是 undefined 。当然我们也可以使用 undefined 值显式初始化一个变量。
var udf0;
console.log(udf0); // ->undefined
var udf1 = undefined;
console.log(udf1); // ->undefined
- 一般而言,不存在需要显式地把一个变量初始化为 undefined 值的情况。字面值 undefined 的主要目的是用于比较,而 ES3 之前并没有规定这个值。ES3 引入这个值是为了区分空对象指针(空对象指针会使用 null 进行初始化,表示这个变量会用以保存一个对象类型的数据)与未经初始化的变量。
- 但即使未初始化的变量会自动被赋值未 undefined 值,但提倡显示初始化变量。如果能够所有的变量都进行了初始化,typeof 操作符返回 undefined 值时被检测的变量还没有声明,而不是没有初始化。
2.3.3 Null 类型
Null 类型是第二个只有一个值的数据类型,这个特殊的值是 null 。从逻辑的角度来看,null 值表示一个空对象指针,而这也是使用 typeof 操作符检测 Null 型数据时会返回 Object 的原因。
var myGirlFriend = Null;
if (myGirlFriend !=null) {
console.log('我有对象了');
}
// null 与 undefined 返回 true 因为undefined派生自null
console.log(myGirlFriend == undefined); // ->true
如果定义的变量准备用于保存对象(但是还不确定数据的具体值),那么最好将该变量初始化为 null 而不是其他的值。这样直接检查 null 值就可以知道相应的变量是否已经保存了一个对象的引用。
总结:
- 不要也不需要显示将一个变量初始化为 undefined 。
- 尽量做到所有变量在声明的同时进行初始化,这样在使用 typeof 检测到的变量为 undefined 则表示该变量未声明(函数形参除外)。
- 如果声明用以保存某个对象的变量,但是还不确定其内容时,可以同时将其初始化为 null 。
2.3.4 Boolean 类型
Boolean 类型只有两个字面值:true 和 false 。但是其他所有类型的值都有与之对应等价的一个布尔值。可以调用转型函数 Boolean() 将其他类型数据转换成对应的布尔值。
var succeed = true;
var fail = false;
var num = 1;
var numBoolean = Boolean(num); // true
2.3.5 Number 类型
Number 类型即数字类型数据。这里主要学习他们的表示方法、运用时需要注意的一个问题、几个特殊的数值和将其他类型转换为数字类型的方法。
1、Number 类型数据的表示
(1) number 类型数据的字面量除了可以使用十进制表示外还可以使用八进制(在严格模式下无效并抛出错误)和十六进制表示。
// 第一位为 0 的数会被解析为八进制数。但是如果字面值中的数值超出了范围
// 那么前导 0 将会被忽略,数值将被当作十进制数值解析
var octalNum1 = 070; // 56
var octalNum1 = 080; // 无效的八进制数值,解析为 80
var octalNum1 = 081; // 无效的八进制数值,解析为 81
// 十六进制字面量的前两位必须是 0x,后跟任何十六进制数字(0~9及A~F或a~f)
var hexNum1 = 0xb; // 11
var hexNum1 = 0x2a; // 42
(2) 在表示浮点数值时可以使用通用的表示方法也可以使用科学计数法。浮点数值的最高精度是 17 位小数,但是在使用浮点数计算或者测试变量的浮点数值(永远不要这么做)时要注意舍入误差的问题。这是使用基于 IEEE754 数值浮点计算的编程语言的通病,ECMAScript 并非独此一家,例如 python 浮点数计算也有舍入误差。
// 浮点数数值中必须包含一个小数点且小数点后面至少有一位数字
var floatNum1 = 0.1;
var floatNum2 = 0.2;
var floatNum3 = .1415; // 有效但是不推荐使用
var floatNum4 = 2. // 小数点后面没有数字,解析为 2
var floatNum5 = 2.0 // 整数,为节约内存会解析为 2
if (floatNum1 + floatNum2 == 0.3) {
// false
console.log('true');
}
// 使用科学计数法
var a = 3.12e4; // 31200
var b = 3.12e-4 // 0.000312
计算机内部存储数据的编码的时候,0.1在计算机内部根本就不是精确的0.1,而是一个有舍入误差的0.1。当代码被编译或解释后,0.1已经被四舍五入成一个与之很接近的计算机内部数字,以至于计算还没开始,一个很小的舍入错误就已经产生了。这也就是 0.1 + 0.2 不等于0.3 的原因。另外要注意,不是所有浮点数都有舍入误差。二进制能精确地表示位数有限且分母是2的倍数的小数,比如 0.5,0.5 在计算机内部就没有舍入误差。所以 0.5 + 0.5 === 1
可以先都将浮点数通过乘以10 n转化为整数计算后结果再除以相应的倍数来解决这个问题。
也可以在浮点计算后使用 Number 的内置方法在保证不会改变计算结果的前提下保留小数点后特定的位数作为结果解决这个问题。
2、Infinity 和 -Infinity
由于内存的限制,ECMAScript 并不能毫无限制地保存所有数值。它能够表示(保存)的最小值保存在 Number.MIN_VALUE 中,最大值保存在 Number.MAX_VALUE 中。当超过最大值时若为负则其值将被转换为 -infinity(负无穷),若为正则其值将被转换为 infinity(正无穷)。使用 isFinity() 函数可以判断一个变量的数值是否位于负无穷和正无穷之间,如果参数是无穷的返回 false,反正返回 true 。
访问 Number.NEGATIVE_INFINITY 和 Number.POSITIVE_INFINITY 也可以得到负和正的 infinity 值。
如图,各个数值的含义如下:

- x : -infinity
- y : +infinity
- a : -Number.MAX_VALUE
- d : +Number.MAX_VALUE(在大多数浏览器中这个值约为1.797e+308)
- b : -Number.MIN_VALUE
- c : +Number.MIN_VALUE (在大多浏览器中这个值为 5e-324)
3、NaN
NaN,即非数值(Not a Number)是 infinity 之外的另一个特殊的数值。NaN 用于表示一个本来要返回数值的操作数未返回数值的情况(这样可以避免抛出错误)。Number 型数值 NaN 有以下两个特点:
- 任何涉及 NaN 的操作都会返回 NaN。
- NaN 与任何值都不相等,包括 NaN 本身。
为此需要用到 isNaN() 函数来确定传入该函数的参数是否 “不是数值”。isNaN() 函数在接收到一个值后,会尝试将这个值转换为数值。不是 Number 类型的值若可以转换为数值则也会返回 true ,例如 “10” 或者 true 等。如果不能转换为数值的值都会导致这个函数返回 false 。
var a = NaN / 10; // a = NaN
console.log(NaN == NaN); // false
alert(isNaN(NaN)); // true
alert(isNaN(10)); // false
alert(isNaN('10')); // false
alert(isNaN('abc')); // true
4、数值转换
有 3 个函数可以将其他数据类型的数据转换为数字型数据,它们分别是Number()、parseInt() 和 parseFloat() 。第一个函数即转型函数 Number() 可以用于任何数据类型,而另外两个函数则专门用于把字符串类型值转换为数字型值。将其他类型数据转换为数字型数据在类型转换那节专门介绍,下面主要讨论它们将字符串转换为数字时的区别。
- Number()
- parseInt()
- parseFloat()
// Number()
/*
* 1、从字符串中的第一个非空字符开始解析,如果为空字符串则返回 0
* 2、遇到非数字型字符则返回 NaN ,前面的正负号和第一个小数点正常解析。
* 3、前导 0 会被忽略(无法识别八进制数)
* 4、如果字符串中包含有效的十六进制格式,例如从 "0x" 开始解析则转换为对
* 应的十进制数(可以识别十六进制数)
*/
var a = [Number(''), Number(' '), Number(' -01'), Number(' 0.2'), Number('3a'), Number('0.2.0'), Number('0xab')];
console.log(a); // ->[0, 0, -1, 0.2, NaN, NaN, 171]
// parseInt(str, x); 参数str为要解析的字符串,x指定以多少进制对字符串进行解析(重要理解)
/*
* 1、也是从字符串中的第一个非空字符开始解析,但是空字符串返回 NaN
* 2、遇到非数字型字符(第一个负号除外)或者小数点则结束解析并返回已经解析得到的数值。
* 3、一般都明确指明第二个参数。
*/
var a = [parseInt(''), parseInt('a1'), parseInt(' -01'), parseInt(' 0.2'), parseInt('3a'), parseInt('13a0', 8), parseInt('0xab', 16)];
console.log(a); // ->[NaN, NaN, -1, 0, 3, 11, 171]
// parseFloat()
/*
* 1、只以十进制方式解析,所以可以以十六进制解析的字符串会被解析为0
* 2、解析遇到一个无效的浮点数字字符为止,注意科学计数法
*/
var a = [parseFloat(''), parseFloat('a'), parseFloat(' 00.2f'), parseFloat('03a'), parseFloat('1.3e2a'), parseFloat('0xab')];
console.log(a); // ->[NaN, NaN, 0.2, 3, 130, 0]
2.3.6 String类型
String 类型用于表示由零个或多个 16 位 Unicode 字符组成的序列,即字符串。在 JavaScript 中,字符串可以使用双引号或者单引号表示。一般习惯在 html 中使用双引号,在 js 中习惯使用单引号。需要注意的是左右引号必须匹配,且使用时不能换行(在 ES6 中引入模板字符串可以换行)。
1、转义字符
String 数据类型包含一些特殊的字符字面量,也叫转义序列,用于表示非打印字符,或者具有其他用途的字符。常用的转义字符如下:
- \n 换行
- \t 制表
- \b 退格
- \r 回车
- \\ 斜杆
- \" 双引号(同理可以得到单引号),例如:‘i say \‘hi,friend\’’
- \unnnn 以十六进制代码 nnnn 表示的一个 unicode 字符。
- \xnn 以十六进制代码 nn 表示的一个字符。
2、字符串不可变的特点
ECMAScript 中字符串是不可变的,即字符串一旦创建,他们的值就不能改变。要改变某个变量保存的字符串,首先要销毁原来的字符串,然后再用另一个包含新值的字符串填充该变量。
var str0 = 'hello';
str0 = str0 + ' friend';
// 操作:
// 1、分别创建(开辟内存保存)两个字符串 'hello' 和 ' friend' 并将前者赋值给变量 str0
// 2、再创建(开辟内存保存)一个新的字符串 'hello friend'(两者相加)
// 3、将步骤二的值赋值给变量 str0
// 4、将前两个字符串销毁,因为他们已经没用了。
字符串的不可变性是我们在使用 innerHTML 创建多个元素时,避免使用字符串拼接的方式,使用数组元素追加的方式实现效率提高很多的原因。
3、其他类型转换为字符串的方式
将其他类型的数据转换为字符串类型数据的方式有两种。
方式一:使用几乎每个值都有的 toString() 方法,该方法只有 null 和 undefined 值没有。
方式二:使用转型函数 String()
// toString() 方法,只示范数字型数据转换为字符串型数据,其他的在类型转换那节介绍
var num = 11;
var str0 = num.toString(); // '11'
var str1 = num.toString(16); // 'b'
// String()
var str2 = String(num); // '11'
两者的区别:toString() 方法 null 和 undefined 值没有该方法,可以传递一个参数指定转换为什么进制(默认十进制)的数值后再转换为字符串。String() 函数可以转换任何类型数据。
2.3.7 Object 类型
ECMAScript 中把对象定义为:“无序属性的集合,其属性可以包含基本值、对象或者函数”。形象的说对象就是一组没有特定顺序的值和功能的集合。
1、 对象的创建方式
// 1、通过对象字面量创建对象
var obj0 = {
uname:'TKOP_', age: 18};
// 2、通过执行new操作符后跟要创建的对象类型的名称来创建
var obj1 = new Object();
// 通过以上两种方法创建Object类型的实例后,就可以为其添加属性或者方法,即创建自定义对象
obj1.uname = '扬尘';
obj2.age = 19;
// 3、当然我们可以创建自定义类对象(使用构造函数或者 class),这是面向对象编程(进阶)部分的内容,后面再详细总结
2、 Object 类对象实例具有的属性和方法
如果仅仅创建 Object 的实例并没有什么用处,但关键是要理解一个重要的思想:即在 ECMAScript 中 Object 类型是所有它的实例的基础。换句话说,Object 类型所具有的任何属性和方法也同样存在于更具体地对象中。(书中原话,但个人认为严谨地说是实例成员)。这些知识是面向对象编程的重难点后面详细总结。
Object 地每个实例都具有下列属性和方法:
- constructor : 保存着用于创建当前对象地函数。 对于前面的例子而言,构造函数(constructor)就是 Object()
- hasOwnProperty(propertyName) : 用于检查给定属性在当前对象中是否存在(而不是在对象原型__proto__中,即继承自类)。其中作为参数的属性名必须以字符串的形式指定。例如 obj0.hasOwnProperty(‘name’)。
- isPrototypeOf(object) : 用于检查当前对象是否是传入的对象的原型 (这个地方个人觉得书上写反了所以私自换了过来)。
- propertyIsEnumerable(propertyName) : 用于检查给定属性是否能够使用 for-in 语句来枚举。
- toLocaleString() : 返回对象的字符串表示,该字符串与执行环境的地区对应,区别明显的是时间对象。
- toString() : 返回对象的字符串表示。
- valueOf() : 返回对象的字符串、数值或者布尔值表示。通常与 toString() 方法的返回值相同。
3、 初步整体理解对象(引用类型)
2.3.8 数据类型转换
数据类型转换是指在开发时我们可以根据需要可预见地将一种类型的数据转换为另一种类型的数据。例如使用 prompt() 得到地用户输入均为 String 类型数据,但由于想得到的是数字型数据,则可以通过显式将其进行类型转换得到 Number 类型数据,这种为显式转换数据类型。再例如,分支语句中的判断条件不是返回 Boolean 类型值表的达式而是其他类型的值时,解释器会自动将其转换为 Boolean 类型的值,这种为隐式转换。
1、显式转换总结
- 转型函数 Boolean() : 将其他类型的值转换为 Boolean 类型。
- 转型函数 Number() : 将其他类型的值转换为 Number 类型。
- parseInt() : 将 String 类型的值转换为 Number 类型(整型)。
- parseFloat() : 将 String 类型的值转换为 Number 类型(浮点型)。
- 转型函数 String() : 将其他类型数据转换为 String 类型。
- toString() 方法 : 将除了 null 和 undefined 外的其他类型转换为 String 类型。
他们具体用法已在前面介绍过了
2、隐式转换总结
- 一元操作符加和减可以实现字符串转数字类型
- 二元操作符 - / * 可以实现字符串转数字类型
- 二元加法可以实现数字类型转换为字符串类型(字符串拼接)。
除了可以使用 typeof 判断数据类型外,还可以在控制台输出数据后进行判断。例如 10 和 ‘10’ 的颜色是不一样的,true 和 ‘true’ 在控制台输出的颜色一不一样。
// 字符串隐式转换为数字类型
var num0 = '20' / '2'; //10
var num1 = '20' * '2'; // 40
var num2 = -'20'; // -20
var num3 = '20' - 0; // 20
var num3 = +'20'; // 20
var num4 = true / '2'; // 0.5
// 数字类型隐式转换为字符串类型
var str0 = '' + 20 // '20'
var str0 = 20 + 10 + '' + undefined; // '30undefined'
3、各类型数据间转换规则总结
这是我在看视频学习时有关类型转换的思维导图笔记。在这里就不花费时间以表格形式展示了,直接贴图。
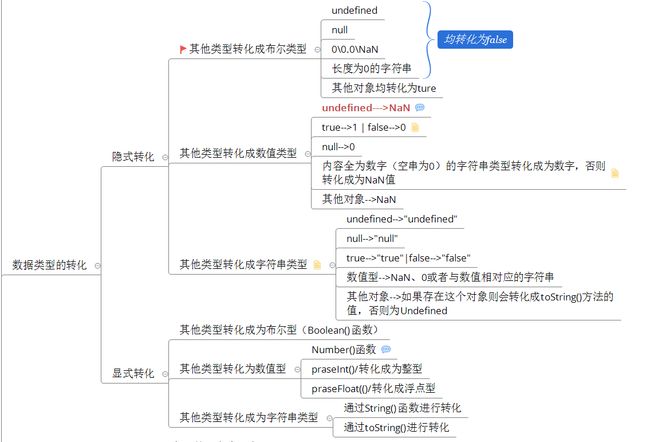
// 1、其他类型转换为布尔类型:null undefined NaN 0 空字符串均会转换为false;
// 其他对象均转换为 true; 需要注意的是这里空字符串是指 str.length = 0
var b = ' ';
if (b) {
console.log('true');
} else {
console.log('false');
}
// 输出的是 true
var b0 = Boolean({
}); // true
var b1 = Boolean(' '); // true
var b2 = Boolean(''); // false
var b3 = Boolean(undefined); // false
var b4 = Boolean(null); // false
var b5 = Boolean(NaN); // false
var b6 = Boolean(0); // false
var b7 = Boolean(0.0); // false
var a = [b0, b1, b2, b3, b4, b5, b6, b7]
console.log(a)
// 2、其他类型转换为数字类型:null false 空字符串转换为 0;undefined 转换为 NaN。
// 内容为数字的字符串转换为相应的数字类型,true 转换为1,其他转换为 NaN
var num0 = ' ' / 1; // 0
var num1 = null / 1; // 0
var num2 = false / 1; // 0
var num3 = undefined / 1; // NaN
var num4 = '20' / 1; // 20
var num5 = true / 1; // 1
var num6 = '20 ' / 1; // 20
var num7 = '20a ' / 1; // NaN
// 其他类型转换为字符串类型则非常简单:相当于在两边加引号。
var str0 = '' + undefined; // 'undefined'
var str1 = '' + null; // 'null'
var str2 = '' + NaN; // 'NaN'
var str3 = '' + 10; // '10'
var str4 = '' + true; // 'true'
2.4 操作符
表达式是用于 JavaScript 脚本运行时进行运算的式子,可以包含常量、变量和运算符。操作符的分类主要有算数运算符、赋值运算符、比较运算符、逻辑运算符和三元运算符,当然还有其他运算符,例如位运算、一元加减运算符等。这里不去记录所有操作符的用法细节。只去记录某些操作符的使用细节。
注意:在写代码时操作符与操作数间要加一个空格,一元操作符除外。
2.4.1 算数运算符(含++、- -)
算数运算符有 +、-、*、/、%、++、-- 等。后面两个是一元操作符,+、- (取反)也可以当成一元操作符,在数据类型转换那节有用到。
注意:只要使用 ‘+’ 连接两个操作数中有一个为字符串类型,js 就会自动把非字符串类型数据隐式转换为字符串类型处理。但是在遇到字符串之前所有的数字型数据仍会做为数值型数据处理。为避免这种情况,我们可以在表达式前面拼接一个空串。
// 1、++ -- 的前置递增递减与后置递增递减的区别
var num0 = 0;
++num0; // num0此时为1
num0++; // num0此时为2
console.log(num0); // ->2
var a = num0++; // 先将先执行表达式后num0自加1,即先执行a=num0;后num0++
console.log(a, num0); // ->2,3
var b = ++num0; // num0先自加1后执行表达式,即先执行++num0;后执行b=num0
console.log(b, num0); // ->4,4
// 2、判断以下结果
var a = 10;
++a;
var b = ++a + 2;
console.log(b);
var c = 10;
c++;
var d = c++ + 2;
console.log(d);
var e = 10;
var f = e++ + ++e;
console.log(f);
// 3、总结:前置递增递减和后置递增递减单独使用时结果一样,都是使操作数自增1或者自减1
// 在与其他代码联用时,前置递增递减会先执行表达式后执行自增自减操作;后置递增递减则相反
var str = '10';
console.log(+str); // 数值型的 10
2.4.2 赋值运算符
赋值运算符有 =、+=、-=、*=、/=、%=、.= 等。
// 复合型赋值运算符说明:例如 a += b 相当于 a = a + b; 其他同理
2.4.3 比较运算符
比较运算符有 >、>=、<、<=、==、!=、===、!== 等。注意 == 和 === 的区别。
2.4.3 逻辑运算符
逻辑运算符 &&、||、! 。主要是理解逻辑中断(逻辑与和逻辑或操作均属于短路操作)。
- 对于逻辑与,如果第一个操作数逻辑为 false ,则不会再去判断第二各操作数的逻辑值,而会直接返回第一个操作数。反之则返回第二个操作数。
// 1、由于a=0,即与的第一个操作数逻辑为false,所以不会再判断(执行)第二各操作数,而直接返回第一个操作数0
var a = 0;
var b = a && ++a;
console.log(b, a); // ->0 0 注意:a的值不变,还是0
// 2、由于a=1,即与的第一个操作数逻辑为true,所以需要判断(执行)第二各操作数,并返回第二个操作数
a = 1;
b = a && a++;
console.log(b, a) // ->1 2 注意a的值已经改变,但是由于是后置递减,所以b的值是 1 (但不是第一个操作数的值)
c = b && --b;
console.log(c, b) // ->0 0 这里验证确实返回的是第二个操作数
- 对于逻辑或,如果第一个操作数逻辑为 true ,则不会再去判断第二各操作数的逻辑值,而会直接返回第一个操作数。反之则返回第二个操作数。
// 使用类似的代码验证或运算
var a = 1;
var b = a || --a;
console.log(b, a); // 1 1
a = 0;
b = a || a++;
console.log(b, a) // 0 1
c = b || --b;
console.log(c, b) // ->-1 -1
如下图,这是我在看视频学习时老师讲了一句误导性的话然后记下的笔记。在这里更正一下:比较运算符的结果才为布尔类型,逻辑运算符的结果为两个操作数之一;只不过是在大多数情况下逻辑运算符的结果会隐式转换成布尔类型值而已。

var a = 1;
var b = 2;
var c = a > b;
var d = a && b;
console.log(c, d); // ->false 2
// 这也是为什么我们可以使用逻辑或来简单实现某些代码功能
// 例如在事件对象的使用时,如果系统不默认传入则使用window.event获取
e = e || window.event;
2.4.4 三元运算符
三元运算符又称条件运算符,其实我们可以将其看成非常简单的 if…else… 语句。它的使用如下:
// 语法: 表达式1 ? 表达式2 : 表达式3;
// 表达式1为true则返回表达式2,表达式1为false则返回表达式3
var a = 10;
var b = 20;
var max = a > b ? a : b;
// 有stopPropagation方法则使用该方法阻止事件冒泡,否则设置cancelBubble属性阻止冒泡
e.stopPropagation ? e.stopPropagation() : (e.cancelBubble = true);
2.4.5 位运算符
对于位运算,如果不看书或者没有自己去学习。好像网上找的学习视频基本上没有去详细地讲他们。这里我就参照自己百度得到的资料和 JavaScript 高级程序设计上的介绍做一个相对详细的介绍。
位操作符用于在最基本的层次上,即按内存中表示数值的位来操作数值。ECMAScript 中的所有数值都以 IEEE-754 64 位的格式存储(浮点数的形式),但是位操作符并不直接操作 64 位的值。而是先将 64 位的值转换成 32 位的整数,然后执行操作,最后再将结果换回 64 位。
看到这没耐心认真看的人(比如当时看书的我)可能疑惑什么乱七八糟的 64 位 32 位的呀。你可以这么想,内存中无论整数还是浮点数都以浮点数的格式进行存储。存储他们一共使用了 64 bit(位)的内存,其中 32 bit(位)用于存储整数部分,32 bit(位)用于存储小数部分。但是在进行位运算的时候并不是直接操作全部 64 位,而是只操作存储整数部分的 32 位。操作完了它直接将 32 位操作的结果直接存储为 64 位,这小子就不管人家小数部分了。
而对于有符号整数,32 位中的前 31 位用于表示整数的值。第 32 位(符号位)用于表示数值的符号:0 表示正数,1 表示负数。由于 CPU 只有加法运算器,所以计算机在存储整数的时候都是以补码的形式存储的,正数的补码就是本身,负数是反码+1。
// 25 的补码是其本身,所以其在内存中表示为
0000 0000 0000 0000 0000 0000 0001 1001
// 如果是 -25 ?
原码:0000 0000 0000 0000 0000 0000 0001 1001
反码:1111 1111 1111 1111 1111 1111 1110 0110
补码:1111 1111 1111 1111 1111 1111 1110 0111 (内存存储内容)
// 怎么实现二进制和十进制间的转换(如何得到原码和根据原码判断数值)?
// 1、使用前面学习的其他类型数据转换为字符串类型的toString()方法
// 2、使用字符串类型转换为数字类型的函数 parseInt()
var num = 25;
var numbB0 = num.toString(2); // 指定返回数字类型num二进制表示的字符串 '11001'
var numB1 = parseInt(numB0,2); // 指定以二进制数字类型来解析numB0字符串 25
// 其实我们也可以自己去算
// 十进制整数转换为二进制的方法:除2取余,逆序排列(自己去了解,以前在学校学过了)
回到正题位操作符是什么?有什么用?请原谅我偷懒直接贴 w3school 的截图了(要了解更具体详尽自己看书哈)。

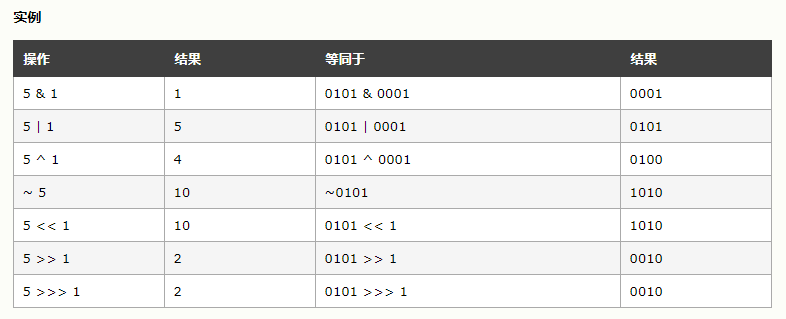
需要特别注意的是 w3school 的实例表中 ~5 和 5>>>1 并没有按内存中实际存储数据的场景去分析。无符号右移(>>>)对于负数这种情况也需要特别地去的理解。
学了他们有什么应用场景吗?(其实本不想写太多有关他们的笔记,就是百度后看到他们的应用场景后才去看了一下)
1、按位非(~)的应用场景:要知道其运用场景首先直观了解这个运算符的操作结果。对一个数进行按位非操作的结果是操作数取反减 1 。
var a = 3;
var b = -3;
var c = -100
console.log(~a, ~b, ~c); // -4 2 99
// 应用场景:判断数组中是否具有该元素
// 原理:按位非返回操作数的取反减1值,即 ~a = -a - 1
if (arr.indexOf(item) > -1) {
// 常用是判断 indexOf()方法返回的索引值是否大于 -1(即不为-1)
}
// 根据前面的铺垫我们知道-1的按位非的值为0,-1在内存所有位均为1
if (~arr.indexOf(item)) {
// 如果为-1条件判断为false,不为-1时为true,即与上面的逻辑相同
}
2、按位或(|)操作符:根据数值之间的按位或的运算规则,可知两操作数对应位上有一个为 0 ,则结果为另一个操作数对应位上的数值;只要有一个为 1 ,则结果的该位即为 1 。因此出现了以下两种特征:
- 任何整数与 0 按位或返回原数值。
- 可以使用 2n 的值代表程序的不同状态,这样使用他们互相按位或运算后,最后结果则为不同状态的组合状态( 本质上是使用不同的位是否为 1 来表示某独立状态是否发生)。
3、按位与(&)操作符:根据数值之间的按位与的运算规则,可知两操作数对应位上有一个为 1 ,则结果为另一个操作数对应位上的数值;只要有一个为 0 ,则结果的该位即为 0 。因此出现了以下两种特征:
- 任何整数与 2n 按位与操作可以检测概述第 n 位的数值(状态)。
- 如果组合状态由 n 个独立状态产生(一共由 n bit 数据记录)。组合状态发生更新时,不想再次去使用按位或去操作所有独立状态时,可以使用按位与根据更新的独立状态去更新组合状态。
总结:可以利用数值某位的数值存储程序状态,而可以使用按位或监查组合状态,使用按位与可以检测单个独立状态。
4、按位或(|)和按位与(&)的应用场景:
以下内容容易引起不适,因为是个人的思考,无论是思路或表达方面都可能存在差异。特别是应用场景这一块个人觉得有些东西被我搞复杂了
你可以去看:深入研究js中的位运算及用法 或者 js中的位运算及应用场景
// 场景一:浮点数取整
// 原理:任何数与0按位或返回原数值,位运算只操作整数部分的32位,具体已在上面说明
var a = 3.5;
var b = -3.5;
console.log(a | 0, b | 0); // 3 -3
// 场景二:边界判断
// 原理:按位或的第二个特征
/*
* 需求:规定鼠标需要在某范围内运动,这时就有边界判断。
* 这其中又包括上,下,左,右四种单一边界,同时还有类似上右,上左等叠加边界。
* 如果我们需要记录这种状态,通过位运算要比使用if判断要简单一些
*/
// 一共可以由四个状态组成,逻辑上可判断16种情况,但场景只需判断9种。
var flag = 0; // 如果在范围内移动即四个状态均不发生
if(x < minX) {
flag = flag | 1;} // x 鼠标位置
if(x > maxX) {
flag = flag | 2;}
if(y < minY) {
flag = flag | 4;}
if(y > minY) {
flag = flag | 8;}
switch(flag) {
case 1: // 超出左边界(x < minX)
...
break;
case 2: // 超出右边界(x > maxX)
...
break;
case 4: // 超出上边界(y < minY)
...
break;
case 5: // 同时超出左边界和上边界(x < minX && y < minY)
...
break;
case 6: // 同时超出右边界和上边界(x > maxX && x > maxX)
...
break;
case 8: // 超出下边界(y > minY)
...
break;
case 9: // 同时超出左边界和下边界(x < minX && y > minY)
...
break;
case 10: // 同时超出右边界和下边界(x > maxX && y > minY)
...
break;
default: // flag=0 范围内(x >= minX && x <= maxX && y >= minY && y <= maxY)
...
break;
}
场景二在这里我直接使用以前一个 小 demo 的部分代码说明,因为它和别人笔记里面的边界界定应用场景接近,但个人觉得这个场景有不太切合实际。因为从代码中可以看到会复用大量的代码。详细可以看其他笔记:js实现放大镜效果
之所出现大量代码复用,按位或结果是四个状态的组合状态。而本例子中可以直接使用单个状态作为分支条件,不需要使用复合状态作为判断条件。
// 场景三:判断奇偶
// 原理:利用按位与的第一个特征
return number & 1 === 1
// 场景四:系统权限判断,某个复选框的选中状态
// 原理:利用按位与的第一个特征
// 场景五:综合利用按位或 按位与
// 这个的使用场景我就不在这里贴代码了
/*
* 实现全选和全不选按钮跟随下面多个复选框状态改变时,以前每点击下面复选框都
* 需要循环检查所有复选框状态然后确定全选按钮的 checked 属性。如果有一个为
* false 则全选按钮为false。但是现在我可以给每个按钮自定义一个 flags 属性
* 他们的值为2的i次方(同时定义一个变量 count 为他们自定义属性的总和),定
* 义一个变量flag监测所有复选框的组合状态。当点击下面的复选框时如果只需要检
* 测this.checked为false则flag更新为flag & (count - this.getAttribute)
* 反之则为 flag | this.getAttribute,这样只需要在 flag 值为count时全选
* 其他则全选按钮checked为false
*/
// 当然这里也可以直接使用按位或就可以,不使用按位与的第二个特征,每次下面
// 的复选框发生变化将 flag 重置为0,所有flags进行一次按位或运算(再次去使
// 用按位或去操作所有独立状态)
5、按位异或(^):运算规则我就不详细列出了。我的记忆方法是异(不同)则为 1 。以下是它的应用场景:交换变量、切换0和1状态和简单字符串加密。
// 1、切换0、1状态
function update(num) {
return num = num ? 0 : 1;
}
update(num);
// 通过异或我们可以这么写
num = num ^ 1;
// 2、在不使用第三个变量情况下,交换两个变量。
a = a ^ b;
b = a ^ b;
a = a ^ b;
// 3、简单字符串加密
// 核心思想使用密钥与原字符进行异或后改变字符,从而实现加密
const key = 313;
function encryption(str) {
let s = '';
str.split('').map(item => {
s += handle(item);
})
return s;
}
function decryption(str) {
let s = '';
str.split('').map(item => {
s += handle(item);
})
return s;
}
function handle(str) {
if (/\d/.test(str)) {
return str ^ key;
} else {
let code = str.charCodeAt();
let newCode = code ^ key;
return String.fromCharCode(newCode);
}
}
let init = 'hello world 位运算';
let result = encryption(init); // őŜŕŕŖęŎŖŋŕŝę乴軩窮
let decodeResult = decryption(result); // hello world 位运算
2.4.6 其他运算符
逗号运算符( , ):逗号用来将多个表达式连接为一个表达式,新表达式的值为最后一个表达式的值。
void 运算符:用来指明一个表达式没有返回结果。
typyof :返回一个字符串,该字符串代表的是操作数的数据类型。
var a = 1,
b = 2,
c;
c = a > b ? (a + b, b) : (b, a + b); // c = (b, a + b)
// 由于逗号运算符特性会得到 c = a + b
console.log(c) // 3
// 对于 void 的使用常见的是在html结构中a链接如果不想实现锚点跳转
// 可以对其href属性做如下设置。href="javascript:void (0)" 可以不加括号
2.4.7 运算符优先级

2.5 语句
ECMA-262 规定了一组语句(也叫流控制语句)。从本质上讲,语句定义了 ECMAScript 中主要语法,语句通常使用一个或多个关键字来完成指定任务。语句可以很简单,例如赋值语句和函数退出语句等,也可以很复杂,例如指定重复执行特定次数某些命令。
2.5.1 分支语句
代码从上往下执行过程中,可以根据不同的判断条件选择执行不同路径的代码(执行代码多选一的过程)。这样可以实现程序在不同状态时执行不同的操作。js 中提供了两种与分支结构有关的语句:
- if 语句
- switch 语句
1、if 语句分单分支语句,双分支语句和多分支语句。他们的处理逻辑如图所示:

他们的语法规范如下:
// 1、单分支,如果条件判断为 true 则执行相应代码块,否则跳过
if (条件判断) {
语句块...
}
// 2、双分支,如果条件判断为true,执行if部分代码,否则执行else部分代码
if (条件判断) {
语句块1...
} else {
语句块2...
}
// 3、多分支,依次执行条件判断,如果为true则执行相应语句块并退出分支语句。
// 如果都为false则执行 else 部分内容
if (条件判断1) {
语句块1...
} else if (条件判断2) {
语句块2...
} else if (条件判断3) {
语句块3...
} else {
语句块4...
}
其中的条件判断可以是任意表达式。而且对这个表达式求值的结果不一定是布尔值。ECMAScript 会自动调用 Boolean() 转换函数将这个表达式的结果转换为一个布尔值。
if 语句小结:
- 如果语句块中只有一条语句可省略花括号(不推荐)。
- 使用时注意语法规范:关键字、操作符之间要加空格。
- if 语句在执行一个语句块后会退出整个分支语句,不会继续往下执行判断。
- 使用多分支语句要注意条件判断之间的顺序关系。
有关小结后面两个知识点的一个小案例:
var score = prompt('请您输入分数:');
if (score >= 90) {
console.log('A');
} else if (score >= 80) {
console.log('B');
} else if (score >= 70) {
console.log('C');
} else if (score >= 60) {
console.log('D');
} else {
console.log('不及格');
}
上面的代码当然你可以在每个 else if 的条件判断中添加另一端的条件约束,例如 score>=80 && score<90 。但是由于第三点所以可以省掉 score<90 的约束,因为能执行后面的代码说明已经不符合前面的条件了,即已经确定 score 的范围 <90 。但是对于不同的条件判断要注意顺序。例如,下面如果我想反着写,那就需要更改判断条件了,不然会有逻辑错误。
var score = prompt('请您输入分数:');
if (score < 60) {
console.log('不及格');
} else if (score < 70) {
console.log('D');
} else if (score < 80) {
console.log('C');
} else if (score < 90) {
console.log('B');
} else {
console.log('A');
}
对于书写顺序和判断条件的关系个人的理解是结合韦恩(Venn)图来理解的。一个简单的韦恩图如下:

在程序中如果从范围 A 开始,那还剩下圈 2 包含的范围(B、C、D)。下一个范围B(圈2到圈3),但是由于 if 语句的特点我们不必要同时使用圈2和圈3约束得到该范围而是只使用圈3(即中间位置的那个黑色箭头)。其他范围或者从 D 开始同理。需要提取的范围在剩下的集合中,使用的界定条件可以包含前面的范围。
2、switch 语句
基本语法:
switch (expression) {
case value1:
statement1;
break;
case value2:
statemen2;
break;
...
case valueN:
statementN;
break;
default:
statement;
break;
}
// value值是表达式时的情形
// 由此思考很多人所说的可以if实现的switch不一定能实现这句话是否可靠
var score = parseInt(prompt('请您输入分数:'));
switch (true) {
case score >= 90 :
console.log('A');
break;
case score >= 80 :
console.log('B');
break;
case score >= 70 :
console.log('C');
break;
case score >= 60 :
console.log('D');
break;
default:
console.log('不及格');
break;
}
switch 语句中的每个情形(case)的含义是:“如果表达式等于这个值(value),则执行后面的语句(statement)”。而 break 关键字会导致代码执行流跳出 switch 语句。如果省略就会导致执行完当前 case 后会继续执行下面的 case 直到遇到 break 或者整个switch 语句结束。default 关键字则用于在表达式不匹配前面任何一种情形时执行的代码。
使用时注意点:
(1) 通过每个 case 后面都添加 break 语句来避免同时执行多个 case 代码。假如确实需要混合几种情形,可以省略 break 语句,但是尽量添加注释说明。
(2) switch 语句中 case 的 value 可以是常量、变量或者表达式。并且值可以是任何数据类型,无论是字符串还是对象都可以。
(3) switch 语句在比较值时使用的是全等操作符,因此不会发生类型转换。这是重点,例如 ‘10’ 与 10 是不相等的。
3、switch 语句和 if 的区别和选择
- if 语句可以进行范围判断,而 switch 语句只能进行值判断。
- if 语句最少比较次数为 1 ,它需要遍历条件分支直到找到符合的条件或者都不符合时执行相应的代码。
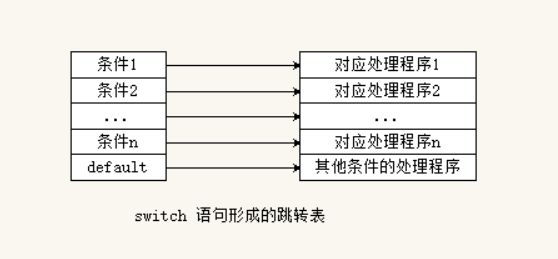
- switch 语句比较次数为 1 ,它会生成一个跳转表(如图)来实现分支结构。不需要依次进行比较每一个所需要的条件。
- 两者比较,在时间方面,switch 语句的执行速度比 if 语句要快,但是在程序执行占用的内存方面,switch语句需要一张跳转表来维护,因此所占用内存比较大。
综上所述,两者存在处理条件、执行原理、效率和内存占用方面的差异。这些可以作为我们选择时的依据。当然对于范围判断我们可以像上面那样转换为值判断,但是有没有必要则根据实际场景来说。if 语句使用的比较多。
2.5.2 循环语句
循环语句在需要重复执行某些相同的操作时使用。js 中提供了三种与循环有关的语句,他们分别是:
- while 语句
- do while 语句
- for 语句
他们的实现逻辑如图所示:

1、while 语句
while (条件表达式) {
// 循环体代码
}
while 语句属于前测试循环语句(当型,当满足条件时执行)。也就是说,首先会对出口条件求值判断并决定是执行循环体还是退出循环,如果为 true 则执行循环体,为 false 则退出循环。循环体执行完毕再次执行上述操作。示例:
var i = 0;
while (i < 10) {
console.log(i);
i++;
}
while (true) {
var num = parseInt(prompt('请选择你要执行的操作(3为退出):'));
if (num == 3) break;
}
注意:像示例中的第二个循环,循环条件一直为 true ,如果不在循环体内添加循环退出语句(break 语句),则会一直重复执行循环体(死循环)。
2、do while 语句
do {
// 循环体代码 - 条件表达式为 true 时重复执行循环体代码
} while(条件表达式);
do while 语句是一种后测试循环语句,即首先会执行一次循环体后再对出口条件进行求值判断并决定是继续执行循环体,还是退出循环(直到型,直到不满足条件时退出循环)。常用于代码至少要被执行一次的情形。
// 获取用户输入必须执行一次
do {
var num = parseInt(prompt('请选择你要执行的操作(3为退出):'));
} while (num != 3)
3、for 语句
for (初始化变量; 条件表达式; 操作表达式) {
//循环体
}
为什么我要将 for 语句放到后面来讲呢?主要是因为 for 循环只是把与循环有关的代码集中在了一个位置。使用 while 循环做不到的,使用 for 循环同样也做不到。例如上面的 while 循环使用 for 循环实现如下:
/*
* for循环将用于循环计数的变量的初始化,条件判断和计数变
* 量的更新集中在了小括号内
*/
for (var i = 0; i < 10; i++) {
console.log(i);
}
// 当然这些东西其实是等价下面这样的,其实就是上述的while循环
var i = 0;
for (;i < 10;) {
console.log(i);
i++;
}
// for 语句中括号内的三个表达式都是可选的,但是为避免死循环需要使用 break
for(;;) {
var num = parseInt(prompt('请选择你要执行的操作(3为退出):'));
if (num == 3) break;
}
有必要指出的是,在循环初始化表达式中使用 var 声明变量与在循环外部初始化变量的效果一样。因为在 ECMAScript 中不存在块级作用域,在循环内部定义的变量也可以在外部访问到。但是如果使用 let 关键字声明变量则两者的效果是不一样的(ES6 中 let 关键字声明的变量具有块级作用域,有关作用域内容后面会讲)。这也是以前我们使用循环给某些元素注册事件处理程序,当需要访问到计数变量时要格外注意它是全局变量,而事件为异步任务。
for (let i = 0; i < 10; i++) {
console.log(i);
}
console.log(i); // 报错,因为无法访问到 i
小结:处理与数值有关的循环常使用 for 循环。
2.5.3 label、break 和 continue 语句
1、label 语句
使用 label 语句可以在代码中添加标签,以便将来使用。以下是 label 语句的语法:
// 语法:label: statement; label表示标签名,statement表示被标记的代码块
// 例如使用 forStar便签标记一个for循环代码块
forStar: for (let i = 0; i < 10; i++) {
console.log(i);
}
定义的标签可以被 break 和 continue 语句引用,加标签的语句一般都要与 for 等循环语句配合使用。
2、break 和 continue 语句
break 和 continue 语句用于在循环中精确地控制代码地执行。break 语句会强制退出循环,执行循环后面地语句。continue 语句则会强制退出本次循环,执行下一次循环。示例如下:
// 示例1:打印到4就会停止循环,不会执行打印5和后面的循环过程
for (let i = 0; i < 10; i++) {
if (i == 5) break;
console.log(i)
}
// 示例2:在判断后执行continue退出本次循环
// 不会打印5但是会继续执行后面的循环过程打印6、7、8、9
for (let i = 0; i < 10; i++) {
if (i == 5) continue;
console.log(i)
}
// 示例3:当出现多层循环时他们控制的是最近的一层循环
for (let i = num = 0; i < 10; i++) {
for (let j = 0; j < 10; j++) {
if (i == 5 && j == 5) {
break;
}
num++;
}
}
console.log(num); // 95 因为break退出了内层循环,外层循环继续执行
for (let i = num = 0; i < 10; i++) {
for (let j = 0; j < 10; j++) {
if (i == 5 && j == 5) {
continue;
}
num++;
}
}
console.log(num); // 99 因为continue退出本次内层循环,开次下次内层循环
从上面的例子可以看到,无论时 break 还是 continue 控制的都是最近的内层循环。但是如果确实有需要在内层循环里面使用他们来控制外层循环呢?这就需要用搭配 label 语句使用了。
请注意我的措辞:在内层循环里面使用 break 和 continue 控制外层循环。 如果你纯粹只是想控制外层循环那没必要,比如上面如果是在 i = 8 时跳过本次外层循环,只需要像以下示例 1 即可实现。但是如果你是想在 i == 5 && j == 5 时跳过本次外层循环或者退出外层循环,则必须搭配 label 语句实现,如示例 2 。因为你要访问 j 变量且是在执行内层循环的时候(即 break 或者 continue 必须写在内层循环)对外层实现控制,所以就必须要搭配 label 语句。
// 示例1:并不涉及j且不用在内层循环控制外层循环
for (let i = num = 0; i < 10; i++) {
if (i == 8) {
continue;
}
for (let j = 0; j < 10; j++) {
num++;
}
}
console.log(num); // 90 因为continue退出本次外层循环,开始下次外层循环
// 示例2:
outsideFor:
for (let i = num = 0; i < 10; i++) {
for (let j = 0; j < 10; j++) {
if (i == 5 && j == 5) {
continue outsideFor;
}
num++;
}
}
console.log(num); // 95 因为continue退出本次外层循环,开次下次外层循环
// 如果将示例2改为break,则输出为55,因为直接结束了外层循环
示例 2 中输出 95 是因为当 i == 5 && j == 5 时跳过本次外层循环,导致内层循环在 i = 5 时只执行了 5 次。与使用 break 结束内层循环的结果一样。
小结:label、continue 和 break 语句是与循环控制有关的语句。label 语句一般需要搭配后两个使用,用于标识需要控制的是那个语句块。break 语句在前面我们也了解过它在 switch 语句的使用。
2.5.4 其他语句
1、with 语句(了解即可)
with 语句的作用是将代码的作用域设置到一个特定的对象当中。with 语句的语法如下:
// 基本语法: with (expression) {statement}
// 定义 with 语句的目的主要是为了简化多次编写同一个对象的工作。示例:
var qs = location.search.substring(1);
var hostName = location.hostname;
var url = location.href;
// 使用 with 语句改写
with(location) {
var qs = search.substring(1);
var hostName = hostname;
var url = href;
}
with语句关联了 location 对象。这意味着在 with 语句的代码块内部,每个变量首先会被认为是一个局部变量,而如果在局部环境中找不到该变量的定义,就会查找 location 对象中是否有同名的属性。如果有则以该属性的值为变量的值(JavaScript高级程序上的内容)。with 语句的更多内容 3.2.4 节。
2、异常处理语句。。。
。。。。。
。。。。
2.6 初识函数
函数用于封装实现某项功能的多条语句,方便代码重用和程序维护。可以在任意地方任意时候调用。在这里我们只是对函数有一个基本的了解,更深刻地去理解学习函数(例如函数的本质是什么,什么是匿名函数、回调函数、立即执行函数和 es6 中箭头函数的特点等等)会在引用类型这篇笔记或者其他专题的笔记总结(有空写时会贴个链接)。
2.6.1 函数声明
函数的声明知道有三种方式
// 1、使用function关键字声明函数
function sum(num1, num2) {
return num1 + num2;
}
// 2、使用函数表达式的方式声明函数
var sum = function(num1, num2) {
return num1 + num2;
}
// 3、使用构造函数创建函数(了解即可)
var sum = new Function('num1', 'num2', 'return num1 + num2;');
知道函数调用时,执行完 return 语句后立即退出函数,位于 return 语句之后的任何代码都永远不会执行(但是变量依旧会预解析并声明提升)。另外如果函数中没有 return 语句或者函数结束时没有执行 return 语句函数默认返回值为 undefined 。在需要提前退出函数的情况下也可以利用 return 语句,如果不需要返回值则直接使用该语句而不带任何参数或者字面量值。
2.6.2 函数的参数
函数的参数在内部是用一个伪数组来表示的。函数接收到的始终都是这个伪数组,而不关心伪数组中包含哪些参数(元素)。而函数内部则是通过 arguments 这个对象来访问这个参数伪数组的,从而获取传递给函数的每一个参数。js 函数的参数有以下几个特点:
特点一 :命名的形参只是为了在函数内部使用提供便利(没有必要使用没有语义的 arguments[n]),但不是必需的。
function getSum() {
var sum = 0;
for (var i = 0; i < arguments.length; i++) {
sum += arguments[i];
}
return sum;
}
console.log(getSum(1, 3, 6, 23)); // 33
特点二 :arguments 对像中的值会自动反映到对应的命名参数,所以每次修改 arguments[n] 相当于执行了 n(对应形参) = arguments[n] = newValue;。也可以看出两者的内存空间是独立的。
function getSum(num1, num2) {
var sum = 0;
arguments[1] = 6; // 等价 num2 = arguments[1] = 6
console.log(num2);
for (var i = 0; i < arguments.length; i++) {
sum += arguments[i];
}
return sum;
}
console.log(getSum(1, 3, 6, 23)); // ->6 36
特点三 :arguments 对象的长度由传入的参数个数决定,不是由定义函数时命名参数的个数决定,也不会在函数内部自动更新(与数组有区别)。
// 若上述函数传一个实参,则num2自动赋值为undefined且arguments长度固定为1
function getSum(num1, num2) {
var sum = 0;
arguments[1] = 6; // 无法自动更新arguments的长度,即无效操作
console.log(num2);
for (var i = 0; i < arguments.length; i++) {
sum += arguments[i];
}
return sum;
}
console.log(getSum(1)); // ->undefined 1
没有传递实参的命名形参将自动被赋值为 undefined 。ECMAScript 中所有参数传递的都是值,不可能通过引用传递参数(需要理解透彻)。
2.6.3 js 中函数没有重载
函数重载是指可以使用同一个函数名定义不同的函数实现不同的功能(为同一个函数编写多个定义),但是他们必须具有不同的函数签名。函数签名指可以唯一确定这个函数的相关信息,通常包括函数名称、参数列表(函数参数的顺序和类型)和返回值等组成 。可以用来实现类型检查、函数重载、接口等等。但是回顾我们学过的知识,js 变量声明时都不用确定类型,参数只是通过 arguments 对象访问。所以就不会具有上述这些东西,也就没有重载。即 js 中函数只是一个对象,访问时只会根据标识符(函数名)存储的引用进行访问。一旦重新定义该函数,则会覆盖以前的内容。
function addSome(num) {
return num + 100;
}
// 等价var sddSome = function() {...}
function addSome(num) {
return num + 200;
}
// 等价 sddSome = function() {...}
console.log(addSome(10)); // ->210
3. 变量、作用域链和内存问题
这部分内容不多,但个人感觉挺重要。所以个人建议认真看书理解和总结。
3.1 变量
3.1.1 基本类型和引用类型的值
- 基本数据类型:基本数据类型指的是简单的数据段。基本数据类型有 string、number、boolean、undefined、null、symbol(ES6) 。基本数据类型在存储时变量中存储的是值本身,因此又叫做值类型或简单数据类型。
- 引用数据类型:引用数据类型值指那些由多个值构成的对象。通过 new 关键字创建的对象(系统对象、自定义对象),如 Object、Array、Date 等都是复杂数据类型。复杂数据类型在存储时变量中存储的仅仅是地址(引用),又叫做复杂数据类型。
基本数据类型是按值访问的,因为可以操作保存在变量中的实际值。引用类型在栈内存保存的不是对象值而是对象的引用,对象值保存在引用指向的堆内存中。引用类型是按引用访问的。具体的表现可以详细阅读 js 中的浅拷贝和深拷贝
还有一个小点是只能给引用类型动态地添加属性,基本类型不可以。
var person = new Object();
var uname = 'TKOP_';
person.age = 18;
uname.age = 19;
console.log(person.age) // ->18
console.log(uname.age) // ->undefined
3.1.2 变量复制
基本类型变量复制:从一个变量向另一个变量复制基本类型的值,会在变量对象上创建一个新值(副本),然后将新值(副本)保存到为新变量分配的位置上。(改变副本不会影响原变量)
引用类型变量复制:复制的值的数据类型如果是引用类型,则基本步骤一样。不过复制的副本是该值的引用,将副本保存到为新变量分配的位置上后,新变量保存的引用(指针)和原变量保存的引用指向的其实是同一个对象。(改变副本但不是直接改变其保存的指针值,则会影响原变量)
var b = a = 10;
b = 15;
console.log(a, b); // ->10 15
var obj0 = {
uname: 'TKOP_'
};
var obj1 = obj0;
obj1.uname = '扬尘';
console.log(obj0.uname); // ->'扬尘'
下图中将引用类型与基本类型分开展示

3.1.3 参数传递
ECMAScript 中所有函数的参数都是按值传递的。也就是说,把函数外部的值复制给函数内部的参数,就和把值从一个变量复制到另一个变量一样。所以传参原理可以参照上述的变量复制理解。请记住访问变量有按值访问和按引用访问两种方式,而参数只能按值传递。只不过但其类型为引用类型时这个“值”为一个对象指针(引用)。
var a = 10,
b = {
};
function changeValue(value0, value1) {
value0 = 15;
value1.uname = 'TKOP_';
}
changeValue(a, b);
console.log(a, b.uname); // ->10 'TKOP_'

3.1.4 instanceof 操作符
前面有介绍过 typeof 操作符用于检测数据类型。但是在检测引用类型的值时,这个操作符的用处不大。因为 typeof 只能区分该值是对象还是基本的数据类型(null 除外)。通常我们并不是想知道某个值是对象,而是要判断它是什么类型(class)的对象。例如判断一个对象是否是数组类型、日期类型或者某些自定义的类型对象。语法如下:
// result = variable instanceof constructor;
var arr = [],
fn = function() {
},
obj = {
};
console.log(arr instanceof Object);
console.log(fn instanceof Object);
console.log(obj instanceof Object);
console.log(arr instanceof Array);
console.log(fn instanceof Function); // 以上均为 true
console.log(arr instanceof Function); // false
如果检测对象是引用类型(根据原型链来识别判断,原型链专题会做详细笔记)的实例,那么 instanceof 操作符会返回 true ,否则会返回 false 。
根据规定所有引用类型的值都是 Object 的实例。因此检测一个引用类型值是否是 Object 类的实例时返回值都为 true 。
3.2 执行环境及作用域
这部分的内容非常重要,我在看 JavaScript 高级程序设计这本书的相关内容时,里面的讲述虽少但每句话都非常干货满满,导致我差不多用笔将所有句子都画了横线。里面的每一句话使我们对平常所说的作用域和作用域链的理解会更加深刻。也是后面我们理解深刻理解闭包(closure)的基础。
3.2.1 执行环境
执行环境(execution context)是 JavaScript 中最为重要的一个概念。执行环境定义了变量或者函数有权访问的其他数据,决定了他们各自的行为。每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数(本质也是对象型变量)都保存在这个对象中(虽然我们编写的代码无法访问这个对象,但是解释器在处理数据时会在后台使用它)。
3.2.2 全局执行环境和函数执行环境
全局执行环境是最外围的一个执行环境(全局作用域)。根据 ECMAScript 实现所在的宿主环境不同,与之关联的变量对象也不一样。在 Web 服务器中,与全局执行环境关联的变量对象是 window(在 nodejs 中是 global)对象。因此所有在全局执行环境下所有的变量和函数都是作为 window 对象的属性和方法创建的。
每个函数都有自己的执行环境(局部作用域)。当执行流进入一个函数时,函数的执行环境就会被推入一个环境栈中。而在函数执行之后,栈将其环境弹出,把控制权返回给之前的执行环境。即某个执行环境中的所有代码执行完毕后,该环境被销毁,保存在其中的所有变量和函数定义也随之销毁(全局执行环境知道应用程序退出,例如关闭网页或者浏览器时销毁)。这就是 ECMAScript 执行流的控制机制。
与函数执行环境关联的变量对象是其活动对象(activation object)。活动对象在最开始时只包含一个变量,即前面说的用于接收实参的 arguments 对象(这个对象在全局环境中是不存在的)。之后在该执行环境中声明的变量都会保存在这个活动对象(变量对象)中
看完初学时我写的作用域相关笔记,发觉自己当时的理解是那么的片面和粗浅:
在函数外面的作用域称为全局作用域(理解全局作用域但表达不严谨,比如在函数里面定义执行一个函数,外层函数也不是全局作用域呀),定义一个函数所形成的作用域称为函数作用域也称局部作用域(在函数执行时才会产生自己的执行环境—局部作用域)。在全局作用域使用 var 关键字声明的变量称为全局变量,在局部作用域下使用 var 声明的变量称为局部变量。在局部作用域不使用 var 关键字声明变量会意外创建全局变量。
var num1 = '全局变量';
var num3 = '测试';
function fn() {
var num2 = '局部变量';
num3 = '这是在局部作用域下访问了全局作用域中的变量';
num4 = '在局部作用域意外创建了全局变量';
}
fn(); // 函数必须先执行才会有num4变量,否则在输出num4时同样会报错
console.log(num1); // ->全局变量
console.log(num3); // ->这是在局部作用域下访问了全局作用域中的变量
console.log(num4); // ->在局部作用域意外创建了全局变量
console.log(num2); // ->报错 num2 is not defined
// 注意:使用连等初始化多个变量时注意只是最前面那个使用了var关键字
function fn0() {
var a = b = c = 10;
}
fn0()
console.log(b); // ->10
console.log(c); // ->10
console.log(a); // 报错:a is not difined
3.2.3 作用域链
由上节可知局部变量会在函数退出后销毁(除非产生闭包,闭包在有关专题笔记总结)。因此可以在局部作用域访问全局变量,但是不能在全局作用域访问局部变量。但是不同的函数执行环境间的变量访问又是使用什么机制来规范使用的呢? 这就是下面要学的作用域链的内容。
当代码在一个环境中执行时,会创建变量对象的一个作用域链(scope chain)。作用域链的用途是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端始终都是当前执行环境的变量对象。作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样一直延续到全局执行环境,全局执行环境的变量对象(浏览器中是 window)始终都是作用域链中的最后一个对象。
我们在访问一个变量时,标识符的解析是沿着作用域链一级一级地搜索标识符的过程。从作用域链的前端开始逐级地向后回溯,直到找到标识符为止(如果找不到会通常会导致错误发生 xx is not defined at …)。示例如下,案例 1 比较简单,我们来分析一下案例 2 :先看看代码
// 案例1 : 结果是几?
function f1() {
var num = 123;
function f2() {
var num = 0;
console.log(num); // 站在目标出发,一层一层的往外查找
}
f2();
}
var num = 456;
f1(); // -> 输出0
// 案例2 :结果是几?
var a = 1;
function fn1() {
var a = 2;
var b = '22';
fn2();
function fn2() {
var a = 3;
fn3();
function fn3() {
var a = 4;
console.log(a); //a的值 ?
console.log(b); //b的值 ?
}
}
}
fn1();
案例 2 分析:
执行环境和作用域链的产生过程如下图,相信看完这个图我也没必要再说什么了,结果也就出来了。

图核心解析: window 对象(即全局执行环境变量对象)包含的变量有 a=1、fn1;fn1 函数执行环境变量对象包含的变量有 a = 2、b=“22”、fn2;fn2 函数执行环境变量对象包含的变量有 a=3、fn3;fn3 函数执行环境(当前)执行环境的变量对象包含的变量有 a=4 。
3.2.4 延长作用域
看到这个标题时,如果没有看过相关内容而学过后面闭包的伙伴也许会第一个想到的会是闭包。他们都跟变量的作用域有关并且都跟变量对象隐隐约约有着丝丝的联系,所以我有理由怀疑他们有一腿。在此不去过多涉及闭包的知识,提一下是想说我是由此处启发而去深究了闭包比较本质的实现原理的(最后发现他们纯粹就是都跟变量对象有关而已)。接下来进入正题。
虽然执行环境的类型总共只有两种—全局和局部(函数),但还是有其他办法来延长作用域链。有些语句可以在作用域的前端临时添加一个变量对象,该变量对象会在代码执行后被移除。当执行流进入下列语句时,作用域就会加长。
- try-catch 语句中的 catch 块(异常捕获)
- with 语句
这两个语句都会在作用域链的前端添加一个变量对象。对 with 语句来说,会将指定的对象添加到作用域链中。对 catch 语句来说,会创建一个新的变量对象,其中包含的是被抛出的错误对象的声明。
var obj = {
uname: 'TKOP_',
};
function fn() {
var age = 30;
with(obj) {
// var uname = '扬尘';
console.log(uname);
var testVar = 0;
}
console.log(testVar);
}
fn(); // ->'TKOP_' 0
个人认为理解重点是:with 只是延长了作用域链但是并没有产生新的执行环境。并且 with 块代码执行完后作用域链又会恢复(临时变量对象被移除)。如果将上面注释掉的代码解开会怎么样?为什么输出的是 “扬尘” 和 0 ?
再看一个示例加深理解:
var obj = {
uname: 'TKOP_'
};
(function() {
with(obj) {
var age = 18;
var uname = '局部同名变量';
console.log(uname) // ->'局部同名变量'
uname = '扬尘';
}
console.log(obj.uname); // ->'扬尘'
console.log(uname); // ->undefined
console.log(age); // ->18
})();
作用域链的形成图示:
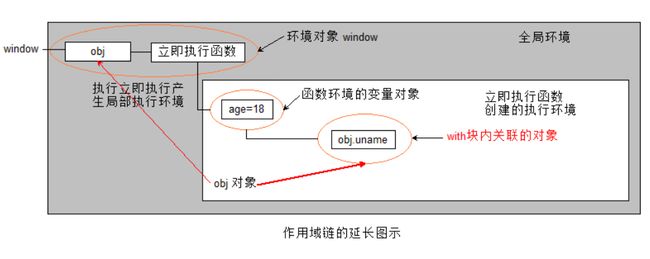 代码执行刚进入 with 语句块时,会产生一个关联一个对象的临时变量对象 (With block)如图:
代码执行刚进入 with 语句块时,会产生一个关联一个对象的临时变量对象 (With block)如图:

此时 var age = 18 还没有执行为什么在 Local 内会存在且值为 undefined ,这是变量预解析的结果。uname 同理。
为什么 age 和 uname 在 with 内部同样是使用 var 关键字初始化而为什么产生的结果会不同呢?这也是我在刚接触这个内容时踩的一个坑(思维定式后很难爬起来)。有些人也许会说 age 初始化一个局部变量有什么问题吗?uname 改变的是 obj 同名属性也没有问题呀?确实是这样,不过为什么后面输出 uname 为什么不报错呢?因为 var uname = ‘局部同名变量’; 不是只是改变了 obj 同名属性而已吗?那局部环境没有 uname 不报错?
var uname = '局部同名变量';
// var uname;
// uname = '局部同名变量';
以上想法出现在我脑海时,我想把自己杀了(这么简单基础的东西想不通?)。也让我知道了定式思维的可怕之处(但其实如果我有注意看调试时作用域 scope,即上图时应该也会很快想得到这点吧)。
- 在 with 内声明变量并初始化是一定要将两个步骤视为是分开的,如上注释部分。
- 声明是在声明一个局部环境变量。
- 而赋值操作是在更新 obj 对象的属性值。
3.2.5 变量预解析
js 引擎(解释器)运行 js 分为预解析和代码执行两个步骤。预解析时 js 引擎会把 js 里面所有使用 var 还有 function 关键字声明的变量提升到当前作用域的最前面。预解析后按照代码书写的顺序从上往下依次执行。
注意:使用 var 关键字声明的变量不提升赋值操作,使用 function 关键字声明的函数会将整个声明部分提升。
console.log(num); // ->undefined
var num = 10;
console.log(fn0); // ->输出fn0函数的定义
fn0(); // ->可以在声明函数前进行调用
function fn0() {
console.log('可以在声明函数前进行调用');
}
console.log(fn1); // ->undefined
fn1(); // ->报错:fn1 is not a function
// var fn1 = new Function('a', 'b', 'console.log("使用 var 表达式的方式声明的函数")');
var fn1 = function() {
console.log('使用 var 表达式的方式声明的函数')
}
3.3 垃圾收集
3.3.1 垃圾收集机制及变量的生命周期
JavaScript 具有自动垃圾收集机制,执行环境会负责管理代码执行过程中使用的内存。代码执行时内存的分配以及无用内存的回收完全实现了自动管理。了解 JavaScript 垃圾收集机制之前先明确一下全局变量和函数中局部变量的正常生命周期。
- 全局变量的生命周期:从程序开始执行并声明变量到整个页面关闭前均存在,但是没有被引用的变量数据的内存会被垃圾收集机制回收。
- 局部变量的生命周期:从函数调用执行并声明变量后存在,函数执行完毕后销毁。
在需要延长局部变量的生命周期时,可以使用闭包。闭包的本质是在定义函数(对象)时,函数对象内部会包含一个我们不可访问的属性 [[scope]] 。[[scope]] 属性包含的是当前执行环境(定义该函数时的执行环境,即全局执行环境或者定义该函数时外层函数执行环境)可直接访问的变量对象(作用域链)。调用函数时程序内部变量的作用域链的构建需要用到这个属性,闭包部分详细探究。
那 js 引擎是如何实现自动垃圾收集机制的呢?垃圾收集机制的原理是找出那些不再继续使用的变量然后释放其占用的内存空间。具体实现是从一个变量的声明开始,垃圾收集器会跟踪每个变量的状态变化。不再有用的变量会被以某种方式打上标记,垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间)周期性地释放这些变量所占用地内存。当然标记后未被释放期间这些变量也已经不可使用了(为什么外部正常情况下总是访问不到局部变量)。 代码示例如下:
var a = 3;
var obj0 = {
scope:'global obj0'};
var obj1 = {
scope:'global obj1'};
function fn(x) {
var b = 4;
var obj2 = {
scope:'local obj2'};
x = null;
obj1 = null;
}
fn(obj0);
- 各变量声明后内存如图 1 所示,红色为全局变量,黑色为函数执行并声明后的局部变量。
- 将两个引用类型的变量值改为 null 后内存内容如图 2 所示,此时 id1 地址存储的变量没有被环境中的变量引用,所以会被标记为待释放。
- id0 则不同,虽然函数环境中的变量 x 不再引用该变量,但是其还被全局变量 obj0 所引用,所以不会被标记为待释放。
- 当函数执行结束(退出函数执行环境回到全局执行环境)时,所有的局部变量被标记为待释放,如图 3 所示。
- 被标记为待释放的局部变量被清除,如图 4 所示。
 具体怎么去判断一个变量是否应该被标记,怎么去标记一个无用变量?用于标识无用变量的策略因实现而异,但具体到浏览器中的实现,则通常有下面两种策略,标记清除和引用计数。
具体怎么去判断一个变量是否应该被标记,怎么去标记一个无用变量?用于标识无用变量的策略因实现而异,但具体到浏览器中的实现,则通常有下面两种策略,标记清除和引用计数。
3.3.2 标记清除(mark-and-sweep)
标记清除是 JavaScript 中最常用的垃圾收集方式。这种方式也是比较好理解的一种垃圾收集方式。涉及的点如下:
1、有关变量进入环境和离开环境
- 变量进入执行环境(例如执行函数时,在函数中声明一个变量)时,垃圾收集器会将其标记为 “进入环境”。
- 而当变量离开环境时,则将其标记为 “离开环境”,例如退出某个函数,里面声明的变量会被标记为 “离开环境”。
- 逻辑上永远不会释放进入环境的变量所占用的内存(例如上例执行函数 fn 时里面的变量 x b obj2)。因为只要执行流进入相应的环境,就可能会用到他们。
- 全局变量就是一个很好的例子,执行流一直都在全局执行环境中(即使在执行某个函数,进入函数执行环境时也是如此)。所以全局变量所占用的内存逻辑上永远不会释放,除非页面关闭。
2、关于如何标记的问题
可以使用任何方式对变量进行标记。例如,通过翻转某个位来记录一个变量何时进入或者离开环境;或者使用两个列表分别跟踪记录 “进入环境” 和 “离开环境” 的变量。
3、标记的策略(重点)
垃圾收集器在运行的时候会给储存在内存中的所有变量都加上标记(怎么标记不重要)。然后它会去掉环境中的变量以及被环境中的变量引用的变量的标记。而在此之后再被加上标记的变量将都被视为待释放的变量,原因是环境中的变量已经无法访问到这些变量了。最后,垃圾收集器完成内存清除工作,销毁那些带标记的值并回收它们所占用的内存空间。
3.3.3 引用计数(了解)
引用计数(reference counting)垃圾收集策略是指跟踪每个值被引用的次数。当声明一个变量并将一个引用类型的值赋给该变量时,则这个值的引用次数为 1 。如果将该值又赋给另一个变量,则该值的引用次数加 1 。反之,如果将保存该值的引用的变量取得其他值,则该值的引用次数减 1 。当一个值的引用次数为 0 时,则说明没有办法再访问到这个值了,垃圾收集器会在下次运行时释放引用次数为 0 的值所占用的内存空间。
该策略存在一个严重的问题:循环引用。循环引用指对象A中包含一个指向对象B的指针,而对象B中也包含一个指向对象A的引用。示例如下:
(function() {
var objA = new Object();
var objB = new Object();
objA.b = objB;
objB.a = objA;
})();
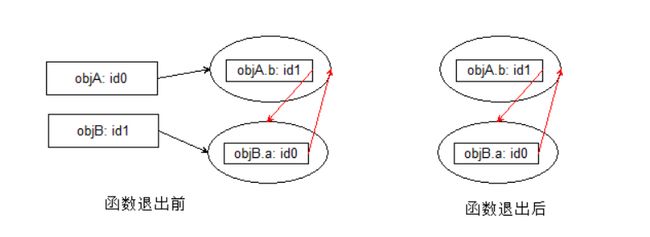
这也许就是传说中的孽缘吧,但凡它们有一个没有去引用另一个都不会发生这种事(它们的引用次数永远不为 0)。引用永远不为 0 ,两个变量在程序运行期间永远占用内存空间。如果不是立即执行函数,而是一个多次调用的函数,会导致大量内存得不到回收。这也是为什么现在的浏览器都弃用这种垃圾收集方式的原因。
大多数浏览器都弃用了这种方式了,那为什么还要了解一下它呢?这就要表扬一下我们的 IE 浏览器了(有爸爸撑腰了不起)。IE9 之前的浏览器的 BOM 和 DOM 中的对象使用 C++ 以 COM(Component Object Model,组件对象模型)对象的形式实现的(并不是真正的 js 原生对象),其垃圾收集机制采用的就是引用计数策略。所以涉及 COM 对象时就要注意循环引用的问题。
怎么去避免这类问题?在不使用它们时手动断开连接。
(function() {
var domObj = document.getElementById('btn0');
var myDomObjs = new Object();
myDomObjs.btn0 = domObj;
domObj.inset = myDomObjs;
....
// 不使用时
myDomObjs.btn0 = null;
domObj.inset = null;
})();
当然 IE9 及以上不用管这些了,因为已经将这些对象都转换为了真正的 JavaScript 对象。
3.3.4 内存的管理
出于安全方面的考虑,防止运行 JavaScript 的网页耗尽全部系统内存而导致系统崩溃。系统会限制分配给浏览器运行的内存的大小(通常比分配给桌面应用程序的少)。这样会影响内存的分配、调用栈以及在一个线程中能够同时执行的语句的数量。
可用内存有限,因此,确保占用最少的内存可以让页面获得更好的性能。而优化内存占用的最佳方式,就是执行中的代码只保存必要的数据。一旦数据不再有用,最好将其值设置为 null 来解除引用。这种做法使用于大多数全局变量和全局对象的属性。局部变量会再它们离开时自动被解除引用。但是,解除一个值的引用并不意味着自动回收该值占用的内存(垃圾收集器并不是立即或者每时每刻都在执行)。解除引用的作用时让该值脱离执行环境,以便垃圾收集器下次运行时将其回收。
var obj0 = new Object();
var obj1 = new Object();
obj0.gFriend = new Object();
// .....执行某些操作后,不再需要 obj0.gFriend
obj0.gFriend = null;
// .....执行某些操作后,不再需要 obj1
obj1 = null;
总结
这篇笔记大概一共有 4w 多字(写的非常辛苦),不会有人一次看完。本来打算将它拆分为几个大体的知识进行总结。但是出于知识间的联系和方便查找相关笔记最终决定还是写在了一起。还有就是这篇笔记对于对象的介绍可以说等于没有,因为我打算后面做一下引用类型的一个总结,接着再逐一对象(面向对象)的有关知识进行总结。这篇笔记如果对你有用先收藏(别忘了顺便给个大拇指,你们的鼓励也是我尽力写好每一篇笔记的动力一部分),以后用到里面的东西更方便瞅一瞅。最后感谢自己的坚持(不然很难完成这么长篇的笔记),希望以后的自己能够保持这种不断学习的状态。也希望各位自学编程的伙伴能挺过前面自己摸索的黑暗的过程,最终实现自己的理想。