分布式训练 — 理论基础
起初为调用大规模的模型训练,单卡GPU是不够使用的,需要借用服务器的多GPU使用。就会涉及到单机多卡,多机多卡的使用。在这里记录一下使用的方式和踩过的一些坑。文中若有不足,请多多指正。
由于分布式的内容较多,笔者准备分几篇来讲一次下深度学习的分布式训练,深度学习的框架使用的是Pytorch框架。
----1.分布式训练的理论基础
----2.GPU训练
----3.单机多卡的使用
----4.多机多卡的使用
分布式训练的需求和重要性不需要多说,最近新提出的预训练模型,普通的16G的显存已经不足以支撑深度学习模型训练的要求了,这时候就需要用到分布式训练来提高效率。
总的来说,分布式训练分为这几类:
按照并行方式来分:模型并行 vs 数据并行
按照更新方式来分:同步更新 vs 异步更新
按照算法来分:Parameter Server算法 vs AllReduce算法
模型并行VS数据并行
假设我们有n张GPU:
- 模型并行:不同的GPU输入相同的数据,运行模型的不同部分,比如多层网络的不同层;
- 数据并行:不同的GPU输入不同的数据,运行相同的完整的模型。

当模型非常大,一张GPU已经存不下的时候,可以使用模型并行,把模型的不同部分交给不同的机器负责,但是这样会带来很大的通信开销,而且模型并行各个部分存在一定的依赖,规模伸缩性差。因此,通常一张可以放下一个模型的时候,会采用数据并行的方式,各部分独立,伸缩性好。
同步更新VS异步更新
对于数据并行来说,由于每个GPU负责一部分数据,那就涉及到如果更新参数的问题,分为同步更新和异步更新两种方式。
1. 同步更新:每个batch所有GPU计算完成后,再统一计算新权值,然后所有GPU同步新值后,再进行下一轮计算。
2. 异步更新:每个GPU计算完梯度后,无需等待其他更新,立即更新整体权值并同步。
同步更新:

异步更新:

同步更新有等待,速度取决于最慢的那个GPU;异步更新没有等待,但是涉及到更复杂的梯度过时,loss下降抖动大的问题。所以实践中,一般使用同步更新的方式。
Parameter Server算法 vs Ring AllReduce算法
这里讲一下常用的两种参数同步的算法:Parameter Server 和 Ring AllReduce。
假设有5张GPU:
- Parameter Server:GPU 0将数据分成五份分到各个卡上,每张卡负责自己的那一份mini-batch的训练,得到grad后,返回给GPU 0上做累积,得到更新的权重参数后,再分发给各个卡。
- Ring AllReduce:5张以环形相连,每张卡都有左手卡和右手卡,一个负责接收,一个负责发送,循环4次完成梯度累积,再循环4次做参数同步。分为Scatter Reduce和All Gather两个环节。
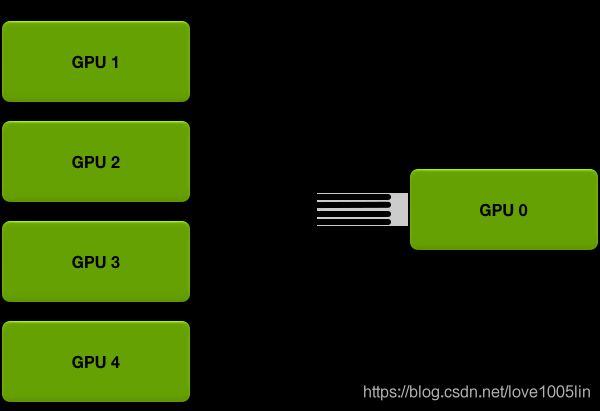
Parameter Server的思想其实有点类似于MapReduce,以上讲同步异步的时候,都是用的这种算法,但是它存在两个缺点:
- 每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束,并行的卡很多的时候,木桶效应就会很严重,计算效率低。
- 所有的GPU卡需要和Reducer进行数据、梯度和参数的通信,当模型较大或者数据较大的时候,通信开销很大。
假设有N个GPU,通信一次完整的参数所需时间为K,那么使用PS架构,花费的通信成本为:
T=2(N-1)K
所以我们亟需一种新的算法来提高深度学习模型训练的并行效率。
2017 年 Facebook 发布了《Accurate, large minibatch SGD: Training ImageNet in 1 hour 》验证了大数据并行的高效性,同年百度发表了《Bringing HPC techniques to deep learning 》,验证了全新的梯度同步和权值更新算法的可行性,并提出了一种利用带宽优化环解决通信问题的方法——Ring AllReduce。

Parameter Service最大的问题就是通信成本和GPU的数量线性相关。而Ring AllReduce的通信成本与GPU数量无关。Ring AllReduce分为两个步骤:Scatter Reduce和All Gather。在Scatter-Reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在All Gather步骤中,GPU将交换这些块,以便所有GPU得到完整的最终结果。
Scatter Reduce过程:
为简单起见,让我们假设目标是对一个浮点数的大数组求和; 系统中有N个GPU,每个GPU都有一个相同大小的数组,并且在AllReduce的末尾,每个GPU都应该有一个相同大小的数组,其中包含原始数组中数字的总和。
首先,GPU将数组划分为N个更小的块(其中N是环中的GPU数)。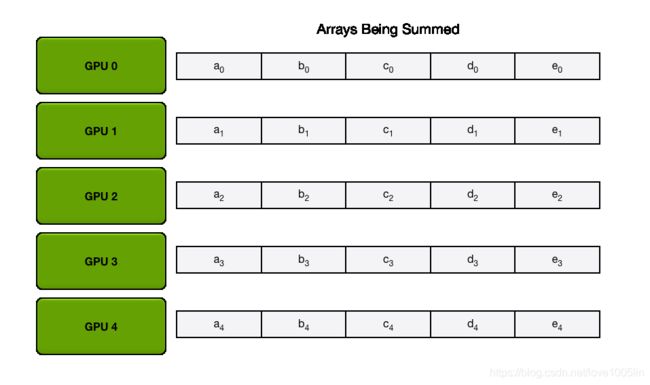
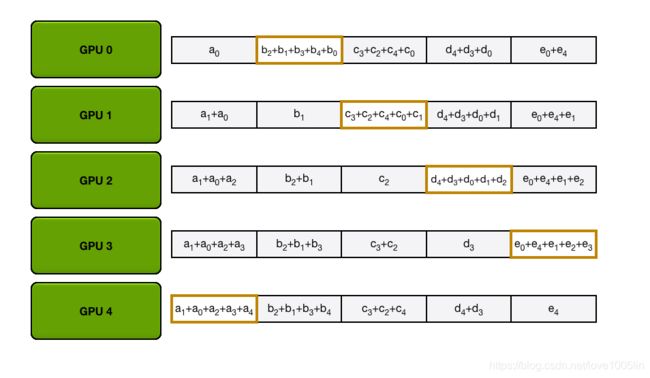
接下来,GPU将进行N-1次 Scatter-Reduce 迭代;在每次迭代中,GPU将向其右邻居发送一个块,并从其左邻居接收一个块并累积到该块中。每个GPU发送和接收的块在每次迭代中都是不同的;第n个GPU从发送块N和接收块N - 1开始,然后从那里向后进行,每次迭代都发送它在前一次迭代中接收到的块。
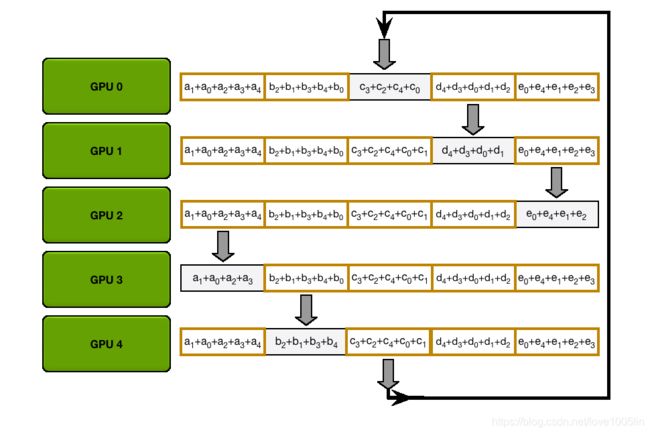
例如,在第一次迭代中,上图中的五个GPU将发送和接收以下区块:


在第一次发送和接收完成之后,每个GPU将拥有一个块,该块由两个不同GPU上相同块的和组成。例如,第二个GPU上的第一个块将是该块中来自第二个GPU和第一个GPU的值的和。

在下一次迭代中,该过程继续进行,到最后,每个GPU将有一个块,该块包含所有GPU中该块中所有值的总和。下图展示了所有数据传输和中间结果,从第一次迭代开始,一直持续到Scatter-Reduce完成。


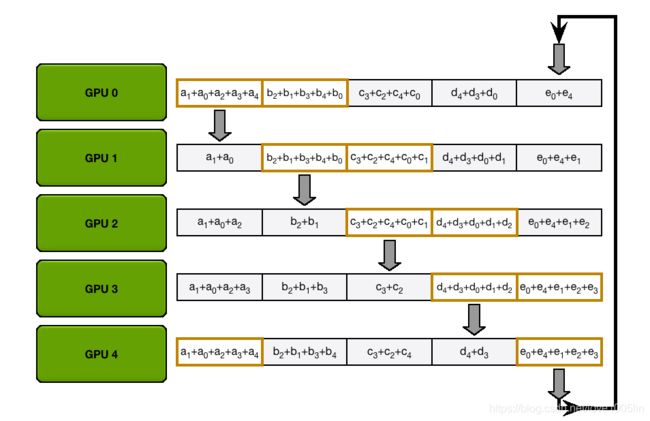
The Allgather 过程
在Scatter-Reduce步骤完成之后,每个GPU都有一个值数组,其中一些值(每个GPU一个块)是最终的值,其中包括来自所有GPU的贡献。为了完成Allreduce, GPU必须交换这些块,以便所有GPU都具有所有必需的值。
环的收集过程与Scatter-Reduce是相同的(发送和接收的N-1次迭代),只是GPU接收的值没有累加,而是简单地覆盖块。第n个GPU首先发送第n+1个块并接收第n个块,然后在以后的迭代中总是发送它刚刚接收到的块。
例如,在我们的5个GPU设置的第一次迭代中,GPU将发送和接收以下块:


第一次迭代完成后,每个GPU将拥有最终数组的两个块。
在下一个迭代中,该过程将继续,到最后,每个GPU将拥有整个数组的完整累积值。下面的图像演示了所有数据传输和中间结果,从第一次迭代开始,一直到Allgather完成。


在我们描述的系统中,N个GPU中的每一个都将发送和接收N-1次Scatter-Reduce,N-1次Allgather。每次,GPU都会发送K / N值,其中K是数组中不同GPU上相加的值总数。因此,传输到每个GPU和从每个GPU传输的数据总量为:

重要的是,这与GPU的数量无关。
由于所有传输都是在离散迭代中同步进行的,因此所有传输的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。给定每个GPU的邻居的正确选择,该算法是带宽最优的,并且是执行全面操作的最快算法(假设延迟成本与带宽相比可以忽略不计)。一般来说,如果一个节点上的所有GPU在环中彼此相邻,则该算法的功能最佳;这最小化了网络争用的量,否则这可能会显著降低GPU-GPU连接的有效带宽。
参考文章链接:
链接1:https://zhuanlan.zhihu.com/p/158886284
链接2:https://fyubang.com/2019/07/08/distributed-training/