积跬步以致千里,积怠惰以致深渊
注:本篇文章在整理时主要参考了 周志华 的《机器学习》。

主要内容
决策树是机器学习中一类常见算法,其核心思想是通过构建一个树状模型来对新样本进行预测。树的叶结点是决策结果,而所有非叶结点对应于一个个决策过程。
基本流程
一般的,一颗决策树包含一个根结点、若干内部结点和若干个叶结点;叶结点对应于决策结果,其它每个内部结点(包括根结点)则对应一个属性测试。决策树根据内部结点的属性测试结果将该结点所包含的样本集按照属性测试的结果被划分到不同的子结点中。这是一种简单且直观的“分而治之”(divide-and-conquer)策略。
决策树学习的目的是为了产生一颗泛化能力强的决策树。
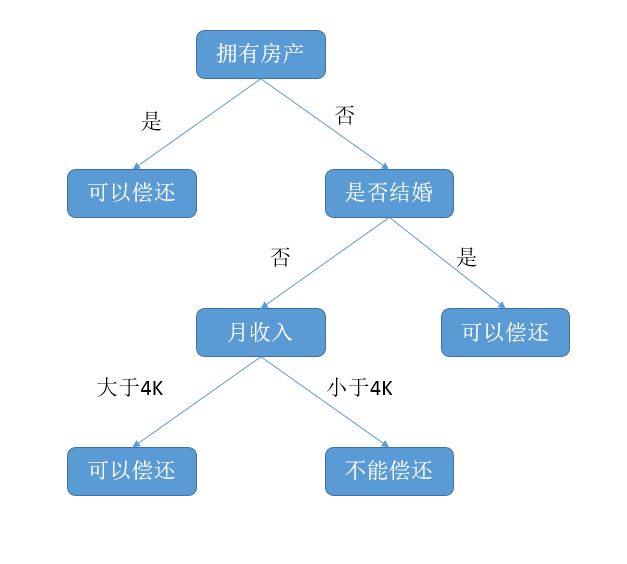
上图是一棵结构简单的决策树,用于预测贷款用户是否具有偿还贷款的能力。贷款用户主要具备三个属性:是否拥有房产,是否结婚,平均月收入。每一个内部节点都表示一个属性条件判断,叶子节点表示贷款用户是否具有偿还能力。例如:用户甲没有房产,没有结婚,月收入5K。通过决策树的根节点判断,用户甲符合右边分支 (拥有房产为“否”);再判断是否结婚,用户甲符合左边分支(是否结婚为否);然后判断月收入是否大于 4k,用户甲符合左边分支 (月收入大于4K),该用户落在“可以偿还”的叶子节点上。所以预测用户甲具备偿还贷款能力。
属性划分选择
那么,我们应该如何选择最优划分属性呢?随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
要使得结点纯度越来越高,我们得要选择合适的指标来对纯度进行评估,并且我们也得要在这些指标上对属性的划分进行选择。目前决策树主流使用的属性划分指标为以下三个:
信息增益
“信息熵”(information entropy)是度量样本集合纯度最常用的一种指标。其代表了不同的类别的数据在总数据集中的熵的和,当样本集合越“纯”时,信息熵越小(信息熵的取值范围为0~log2(k))。
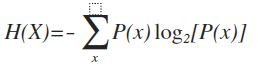
信息增益(information gain):Gain(A)=Info(D)-Info_A(D),用属性对样本集进行划分。
决策树归纳算法(ID3):
[1] 树以代表训练样本的单个结点开始。
[2] 如果样本都在同一个类,则该结点成为树叶,并用该类标号。
[3] 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性。该属性称为该结点的“测试”或“判定”属性。
[4] 在算法的该版本中,所有的属性都是分类的,即离散值。连续属性必须离散化。
[5] 对测试属性的每个已知的值,创建一个分枝,并据此划分样本。
[6] 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它。
递归划分步骤仅当下列条件之一成立停止:
(a) 给定结点的所有样本属于同一类。
(b) 没有剩余属性可以用来进一步划分样本。在此情况下,使用多数表决。
这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结
点样本的类分布。
(c) 分枝
test_attribute=ai没有样本。在这种情况下,以samples中的多数类创建一个树叶。
增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,不直接使用信息增益,而是使用“增益率”(gain ratio)来选择最优划分属性。
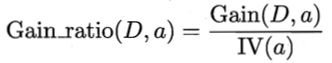
其中
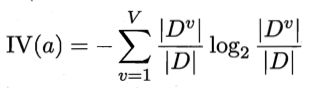
增益率是让信息增益除以选择的划分属性的“固有值”(intrinsic value)。一般来说属性a的可能取值数目越多,则固有值越大,所以信息增益除以固有值后,抵消了信息增益对取值数目多的属性的偏好。
增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
决策树归纳算法(C4.5):
基尼指数
CART(Classification and Regression Tree)决策树使用“基尼指数”(Gini index)来选择划分属性。数据集D的纯度可用基尼值来度量。
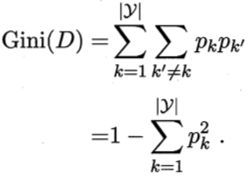
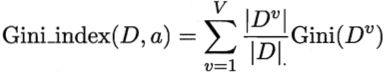
基尼值反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,基尼值越小,则数据集D的纯度越高。
我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
剪枝处理
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。为了尽可能正确分类训练样本,会不断的进行结点划分,有时会造成决策树分支过多,这时就可能因为训练过程学得太好了,将训练集自身的一些特点当作普遍化特征进行学习而会导致过拟合。
因此,可通过主动去掉一些分支来降低过拟合的风险。目前决策树剪枝的基本策略有以下两种:
[1]预剪枝
指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分并将当前结点标记为叶结点;
[2]后剪枝
在训练出一颗完整的决策树之后,自底向上的对非叶结点进行考察,若将该结点对应的子树替换成叶结点能提升泛化性能,则将该子树替换为叶结点。
[3]泛化性能
如何判断决策树泛化性能是否提升呢?我们采用性能评估策略将数据集分为测试集和验证集,基于属性划分准则对训练集进行属性划分,若验证集精度下降,则剪枝策略将禁止结点被划分,若验证集精度上升,则剪枝策略将保留结点划分。
一般情形下,后剪枝策略的欠拟合风险小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树要大得多。
连续与缺失值
在前边提到的决策树处理逻辑中的属性使用的都是离散值,那么当遇到属性是连续或缺失时,我们应该知道该如何处理。
[1]连续值处理
连续值属性一个合理的处理逻辑是:连续属性离散化。我们需要做的是将训练样本中该属性的所有取值进行排序,并对这排好序的取值队列进行分区划分,每一个分区即为该属性的一个离散点取值。
不失一般性,我们就取二分法(即分为两个分区,可以根据需要分为N个)来进行描述。以身高划分为例,训练集中身高数据取值(cm)排序如下:
{160,163,168,170,171,174,177,179,180,183}
因为是二分法,我们只需要找到一个划分点即可。每个划分点可放在两个取值之间,也可放在一个取值之上,这里我们取两个取值之间的中位数。那么上边例子中可选的划分点为:
{161.5,165.5,169,170.5,172.5,175.5,178,179.5,181.5}
根据不同的划分,我们可以分别计算一下信息增益的大小,然后选出一个最好的划分来。
需注意的是,和离散值不同,连续值的划分是可以在子结点上继续划分的。即你将身高划分为“小于175”和“大于等于175”两部分,对于“小于175”的子结点,你仍然可以继续划分为“小于160”和“大于160”两部分。
[2]缺失值处理
为了避免由于样本出现缺失值而导致数据信息浪费,我们需要解决两个问题:
如何在属性值缺失的情况下进行划分属性选择?
不将缺失值的样本代入选择判断的公式计算(信息增益、增益率、基尼指数)之中,只在计算完后乘以一个有值的样本比例即可。
比如训练集有10个样本,在属性 a 上,有两个样本缺失值,那么计算该属性划分的信息增益时,我们可以忽略这两个缺失值的样本来计算信息增益,然后在计算结果上乘以8/10即可。
给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
若样本 x 在划分属性 a 上取值未知,则将 x 划入所有子结点,但是对划入不同子结点中的 x 赋予不同的权值(不同子结点上的不同权值一般体现为该子结点所包含的数据占父结点数据集合的比例)。
多变量分类器
在学习任务的真实分类边界比较复杂时,必须使用很多段划分才能获得较好的近似,此时的决策树会相当复杂,由于要进行大量的属性测试,预测时间开销会很大。
若能使用斜的划分边界,则决策树模型将大为简化,这就是多变量决策树(multivariate decision tree)。在此类决策树中,非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试;换言之,每个非叶结点时一个形如线性回归的线性分类器了。下图是一个在连续属性密度和含糖率上的选瓜多变量决策树样例:
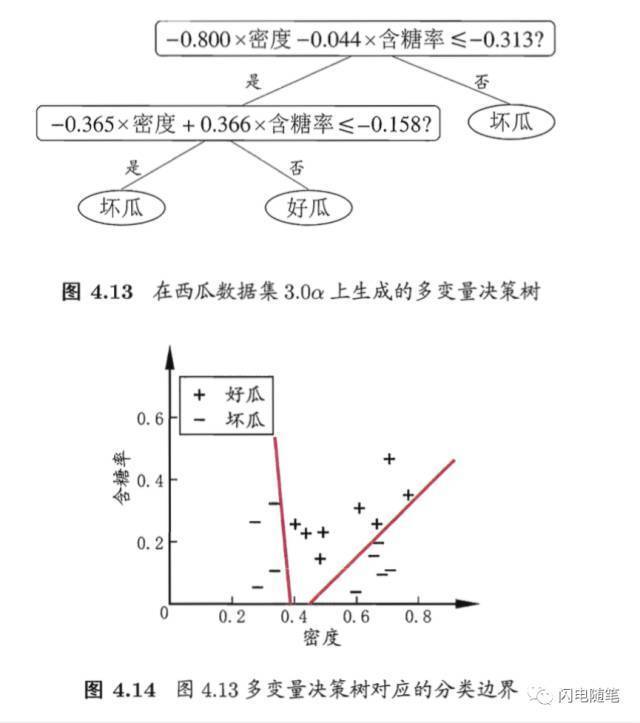
注解
决策树的优点:直观,便于理解,小规模数据集有效。
决策树的缺点:不方便处理连续变量;类别较多时,错误率增长较快;可规模性一般。
总结
1)决策树采用的是一种简单且直观的“分而治之”(divide-and-conquer)策略
2)决策树根据数据集的总体纯度来衡量不同属性划分的优劣
3)当属性选择过于频繁会导致模型过拟合,这时候就需要使用剪枝算法来进行处理
4)剪枝算法的判断标准是剪枝前后模型的性能指标是否提高
5)当遇到连续值的属性时,可以通过将其拆解成两块的方式将数据转换为连续值
6)当遇到缺失值属性时,可以通过在属性选择算法中加入缺失值数据的影响来适应
7)在处理真实分类边界比较复杂的学习任务时,我们可以使用属性的线性组合来对数据进行划分