2021华中杯A题思路点播
赛题思路 完结
- 0引言
- 1、数据处理读入
- 2、赛题分析
-
- 2.1问题一
- 2.2问题二
- 2.3问题三
- 3、代码资源
-
- 3.1问题一代码资源
- 3.2问题二代码资源
- 3.3华中杯A题资源合集
0引言
华中杯赛题已于2021年4月30日(今天)晚上20:00发布,下面是发布网址,大家感兴趣的可以下载查看交流。
今晚(2021年4月30)看了看A题,感觉还行。因为自己这次没参加,就寻思着从建模手和编程手的角度写份思路把,大家有更好的想法和处理技术欢迎再评论区积极留言呀。
本文思路使用的软件是R语言3.6.3版本。编程语言不重要,关键是处理思路。其实大部分工作excel就可以解决。低年级的同学不用太过纠结。
思路会持续更新三天,大家可以关注收藏呀。
1、数据处理读入
数据总共有如下五份,两份输出格式数据"result1.txt" "result2.txt"告诉你结果应该以啥格式输出。两份需求数据"附件2:图像1颜色列表.txt" "附件3:图像2颜色列表.txt"给出了规格为216和200的两份数据。数据信息包含,序号和RGB。
> Txt <- list.files(path = ".", pattern = "txt")
> Txt
[1] "result1.txt" "result2.txt" "附件2:图像1颜色列表.txt" "附件3:图像2颜色列表.txt"
[5] "附件5.txt"
最后一份数据"附件5.txt"是我自己整理的,是把下面的数据:
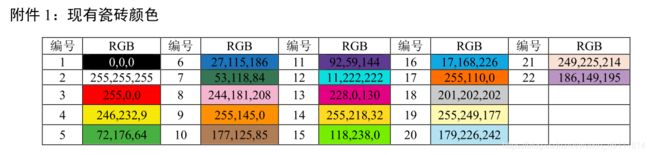
整理成下面的数据格式读入R语言。
> fig3 <- read.csv(Txt[5], header = T, encoding = "UTF-8")
> fig3
R G B
1 0 0 0
2 255 255 255
3 255 0 0
4 246 232 9
5 72 176 64
6 27 115 186
7 53 118 84
8 244 181 208
9 255 145 0
10 177 125 85
11 92 59 144
12 11 222 222
13 228 0 130
14 255 218 32
15 118 238 0
16 17 168 226
17 255 110 0
18 201 202 202
19 255 249 177
20 179 226 242
21 249 225 214
22 186 149 195
需求数据经过处理导入R语言如下:
> fig1 <- read.csv(Txt[3], header = T, encoding = "UTF-8")
> data.table(fig1)
s R G B
1: 1 0 20 39
2: 2 0 20 82
3: 3 0 20 125
4: 4 0 20 168
5: 5 0 20 211
---
212: 212 215 235 82
213: 213 215 235 125
214: 214 215 235 168
215: 215 215 235 211
216: 216 215 235 254
> fig2 <- read.csv(Txt[4], header = T, encoding = "UTF-8")
> data.table(fig2)
S R G B
1: 1 1 253 203
2: 2 2 232 102
3: 3 4 82 157
4: 4 4 101 180
5: 5 5 155 54
---
196: 196 248 191 234
197: 197 250 131 201
198: 198 251 39 131
199: 199 254 18 84
200: 200 254 135 7
2、赛题分析
下面是原赛题的三个要求:
1)附件 2 是图像 1 中的 216 种颜色,附件 3 是图像 2 中的 200 种颜色,请找出与每种颜色最接近的瓷砖颜色,将选出的瓷砖颜色的编号按照附件 4 的要求输出至结果文件。
2)如果该厂技术革新,计划研发新颜色的瓷砖。那么,不考虑研发难度,只考虑到拼接图像的表现力,应该优先增加哪些颜色的瓷砖?当同时增加 1 种颜色、同时增加 2 种颜色、……、同时增加 10 种颜色时,分别给出对应颜色的 RGB 编码值。
3)如果研发一种新颜色瓷砖的成本是相同的,与颜色本身无关,那么,综合考虑成本和表现效果,你们建议新增哪几种颜色,说明理由并给出对应的RGB 编码值。
2.1问题一
思路探索:,再第一部分已经对数据进行读取,再给出第一部分思路之前对已有的数据进行数据可视化,一遍寻找解题思路。
已有色系22:

图片1 216

图片2 200

我们第一问的认为是把现有的数据集合216和200每一个颜色和瓷砖颜色22中找出最接近的颜色匹配,我们假设颜色是关于RGB连续渐变的,且认为两个颜色RGB的空间位置接近即可认定颜色接近。给出以下思路。
针对问题一,寻找算法准则,为两组需求数据自动对应颜色,换句话说根据RGB信息自动匹配相近的颜色。假设把RGB看成空间的坐标,我们可以定义不同的距离来衡量需求数据中的每一个点和已有22组颜色的距离。寻找距离最短的记为最相似。最后可视化出自动匹配的效果。常用的距离有马氏距离、欧氏距离、以及相似余弦等;
下面是以欧式距离为例做出的两组判别图(左:判断 右:原色)。


> data.table(序号 = 1:216, 选择颜色块 = w)
序号 选择颜色块
1: 1 1
2: 2 1
3: 3 11
4: 4 6
5: 5 6
---
212: 212 14
213: 213 19
214: 214 19
215: 215 21
216: 216 20
> data.table(序号 = 1:200, 选择颜色块 = w2)
序号 选择颜色块
1: 1 12
2: 2 5
3: 3 6
4: 4 6
5: 5 7
---
196: 196 8
197: 197 8
198: 198 13
199: 199 13
200: 200 9
2.2问题二
如果该厂技术革新,计划研发新颜色的瓷砖。那么,不考虑研发难度,只考虑到拼接图像的表现力,应该优先增加哪些颜色的瓷砖?当同时增加 1 种颜色、同时增加 2 种颜色、……、同时增加 10 种颜色时,分别给出对应颜色的 RGB 编码值。
问题探索:
因为显示生活中颜色种类要比我们瓷砖的颜色多很多,所以需要开发新颜色,更方便我们寻找接近的颜色,增加图型的表现力。
问题二而是个优化问题:我们可以从以下角度来对颜色进行选择。一个是需求侧:可以统计哪一个段RGB段的颜色出现需求比较高。一个是供给侧,看22种已有颜色的分配是否均匀。
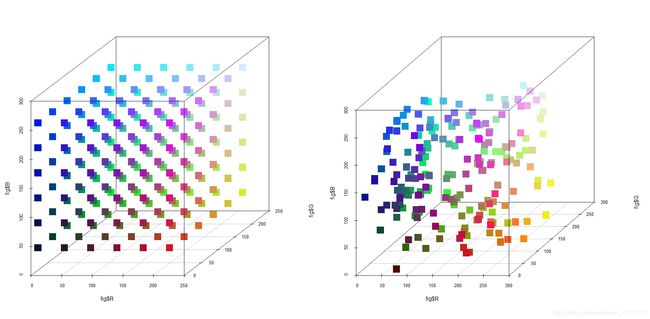
以上我们把题目给定的数据进行了平面可视化,但是没有看出颜色的空间分布。我们只有知道了空间分布才可以确定以那种思路来添加新的颜色。
下面是两个附件的空间颜色分布图(左 216 右 200)。
下面22个颜色的已有瓷砖。
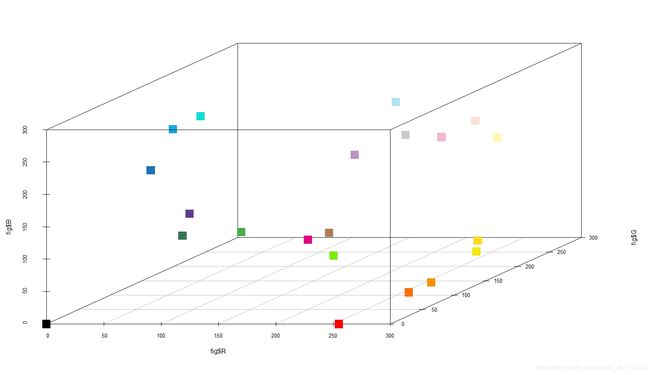
我们可以看出图一216颜色是有规律的等间隔采集数据。针对这种数据我们可以假设只有使得备选颜色尽量均匀分布再整个空间才能是的颜色的覆盖率达到最大,表现效果更好。想再原有的数据中添加数据,需要先统计研究原有数据的分布,是添加之后的数据更加均匀即可。
下面画出22个数据RGB的统计条形图。
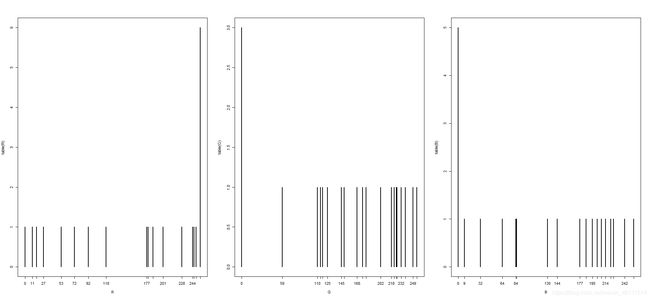
图中可以清晰的看出RGB并不是均匀的分布再整个空间中的。下面我们利用贪心算法的原理,优先填补间隔最大的位置。
可以得到新的RGB坐标为:
> R_G_B(R)
[1] 147
> R_G_B(G)
[1] 29
> R_G_B(B)
[1] 107
依然画出图看一下效果:
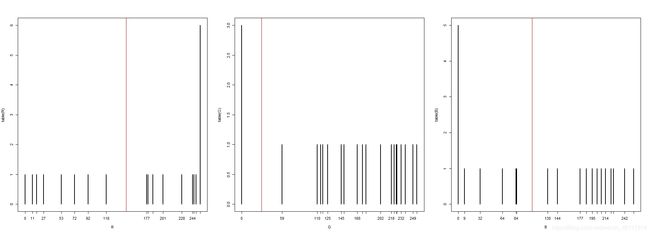
可以看出效果还是可以的。但是我们需要再空间中看到添加到了什么位置。
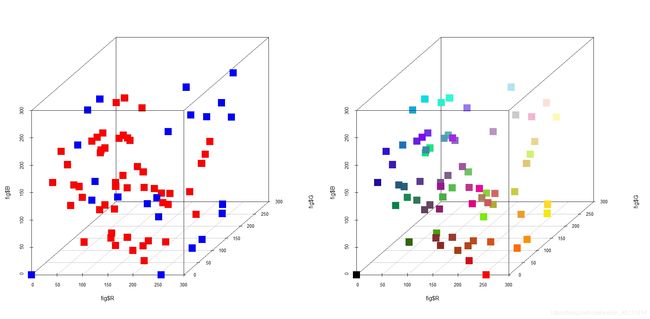
这是使用贪心算法的原则添加了20个点,下面是具体RGB坐标,上图中左红色就新添加的点,右图是添加之后的点。
> data.table(new)
R G B
1: 147 29 107
2: 162 84 160
3: 132 44 48
4: 214 14 20
5: 40 97 118
6: 105 71 96
7: 82 191 74
8: 62 135 168
9: 236 158 40
10: 139 210 56
11: 154 21 152
12: 169 36 234
13: 193 51 137
14: 125 7 248
15: 221 77 26
16: 33 90 124
17: 46 103 14
18: 98 65 90
19: 111 196 101
20: 207 243 112
除了这种方法外,大家还可以使用选址模型、最大覆盖模型等算法来进行新的RGB的选择。
2.3问题三
如果研发一种新颜色瓷砖的成本是相同的,与颜色本身无关,那么,综合考虑成本和表现效果,你们建议新增哪几种颜色,说明理由并给出对应的RGB 编码值。
这一问是对第一问和第二问的应用,所以不需要新的模型。这里只给出简单的思路,不在给出实际代码了。
对于增强图型表现力的单目标问题来说肯定是颜色越丰富表现力越强。但是因为时间管理成本、开发成本不能够这么干,所以我们应该提高颜色的利用率。建议定义如下指标:
- 已有颜色的对整个颜色空间的
覆盖率,每增加一个,覆盖率越高,但是覆盖率的增加速率会变慢。所有个数临界值可以选择每增加一个颜色颜色覆盖率变慢时的颜色个数。 - 第一问中我们针对每一个颜色都选择距离最近的颜色编号,同时我认为所有颜色数据和对应编号之前的
距离(绝对或者相对距离都可)也是一个不错的指标。
3、代码资源
本文的代码都是使用R写的,不会使用R的同学严禁购买。
正文已更完,大家有新想法的欢迎评论区指出,本文涉及代码资源再今晚(2021年5月11)之前会慢慢发布,我会注明内容大家按需下载。
3.1问题一代码资源
后台很多私信要代码的,一一回复太麻烦,这里统一上传建立链接。大家可能没有C币,充值不合算我这里上传的是用RMB下载的。这里是第一问的代码资料,感兴趣的可以下载参考。

3.2问题二代码资源
如果下载过问题一的可以直接下载这部分资源,这里是第二问的代码资料。
内容如下:
3.3华中杯A题资源合集
大家也可以直接下载两问的合集: