电商数仓项目-上篇
下一篇:电商数仓项目-下篇
文章目录
- 第1章 数仓分层
-
- 1.1 为什么要分层
- 1.2 数据集市与数据仓库概念
- 1.3 数仓命名规范
-
- 1.3.1 表命名
- 1.3.2 脚本命名
- 1.3.3 表字段类型
- 第2章 数仓理论
-
- 2.1 范式理论
-
- 2.1.1 范式概念
- 2.1.2 函数依赖
- 2.1.3 三范式区分
- 2.2.1 关系建模
- 2.2.2 维度建模
- 2.3 维度表和事实表(重点)
-
- 2.3.1 维度表
- 2.3.2 事实表
- 2.4 数据仓库建模(绝对重点)
-
- 2.4.1 ODS层
- 2.4.2 DWD层
- 2.4.3 DWS层
- 2.4.4 DWT层
- 2.4.5 ADS层
- 第3章 数仓搭建-ODS层
-
- 3.1 Hive环境准备
-
- 3.1.1 Hive引擎简介
- 3.1.2 Hive on Spark配置
- 3.1.3 Hive on Spark测试
- 3.1.4 Yarn容量调度器并发度问题演示
- 3.1.5 增加ApplicationMaster资源比例
- 3.1.6 增加Yarn容量调度器队列
- 3.1.7 创建数据库
- 3.1.8 datagrip工具
- 3.2 ODS层(用户行为数据)
-
- 3.2.1 创建日志表ods_log
- 3.2.2 Shell中单引号和双引号区别
- 3.2.3 ODS层加载数据脚本
- 3.3 ODS层(业务数据)
-
- 3.3.1 订单表(增量及更新)
- 3.3.2 订单详情表(增量)
- 3.3.3 SKU商品表(全量)
- 3.3.4 用户表(增量及更新)
- 3.3.5 商品一级分类表(全量)
- 3.3.6 商品二级分类表(全量)
- 3.3.7 商品三级分类表(全量)
- 3.3.8 支付流水表(增量)
- 3.3.9 省份表(特殊)
- 3.3.10 地区表(特殊)
- 3.3.11 品牌表(全量)
- 3.3.12 订单状态表(增量)
- 3.3.13 SPU商品表(全量)
- 3.3.14 商品评论表(增量)
- 3.3.15 退单表(增量)
- 3.3.16 加购表(全量)
- 3.3.17 商品收藏表(全量)
- 3.3.18 优惠券领用表(新增及变化)
- 3.3.19 优惠券表(全量)
- 3.3.20 活动表(全量)
- 3.3.21 活动订单关联表(增量)
- 3.3.22 优惠规则表(全量)
- 3.3.23 编码字典表(全量)
- 3.3.24 ODS层加载数据脚本
- 第4章 数仓搭建-DWD层
-
- 4.1 DWD层(用户行为日志解析)
-
- 4.1.1 日志格式回顾
- 4.1.2 get_json_object函数使用
- 4.1.3 启动日志表
- 4.1.4 页面日志表
- 4.1.5 动作日志表
- 4.1.6 曝光日志表
- 4.1.7 错误日志表
- 4.1.8 DWD层用户行为数据加载脚本
- 4.2 DWD层(业务数据)
-
- 4.4.1 商品维度表(全量)
- 4.4.2 优惠券维度表(全量)
- 4.4.3 活动维度表(全量)
- 4.4.4 地区维度表(特殊)
- 4.4.5 时间维度表(特殊)
- 4.4.6 支付事实表(事务型事实表)
- 4.4.7 退款事实表(事务型事实表)
- 4.4.8 评价事实表(事务型事实表)
- 4.4.9 订单明细事实表(事务型事实表)
- 4.4.10 加购事实表(周期型快照事实表,每日快照)
- 4.4.11 收藏事实表(周期型快照事实表,每日快照)
- 4.4.12 优惠券领用事实表(累积型快照事实表)
- 4.4.13 系统函数(concat、concat_ws、collect_set、STR_TO_MAP)
- 4.4.14 订单事实表(累积型快照事实表)
- 4.4.15 用户维度表(拉链表)
- 4.4.16 DWD层业务数据导入脚本
第1章 数仓分层
1.1 为什么要分层

1.2 数据集市与数据仓库概念

1.3 数仓命名规范
1.3.1 表命名
Ø ODS层命名为ods_表名
Ø DWD层命名为dwd_dim/fact_表名
Ø DWS层命名为dws_表名
Ø DWT层命名为dwt_表名
Ø ADS层命名为ads_表名
Ø 临时表命名为xxx_tmp
Ø 用户行为表,以log为后缀。
1.3.2 脚本命名
Ø 数据源_to_目标_db/log.sh
Ø 用户行为脚本以log为后缀;业务数据脚本以db为后缀。
1.3.3 表字段类型
Ø 数量类型为bigint
Ø 金为decimal(16, 2),表示:16位有效数字,其中小数部分2位
Ø 字符额类型串(名字,描述信息等)类型为string
Ø 主键外键类型为string
Ø 时间戳类型为bigint
第2章 数仓理论
2.1 范式理论
2.1.1 范式概念
1)定义
范式可以理解为设计一张数据表的表结构,符合的标准级别、规范和要求。
2)优点
采用范式,可以降低数据的冗余性。
为什么要降低数据冗余性?
(1)十几年前,磁盘很贵,为了减少磁盘存储。
(2)以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的
(3)一次修改,需要修改多个表,很难保证数据一致性
3)缺点
范式的缺点是获取数据时,需要通过Join拼接出最后的数据。
4)分类
目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
2.1.2 函数依赖

2.1.3 三范式区分
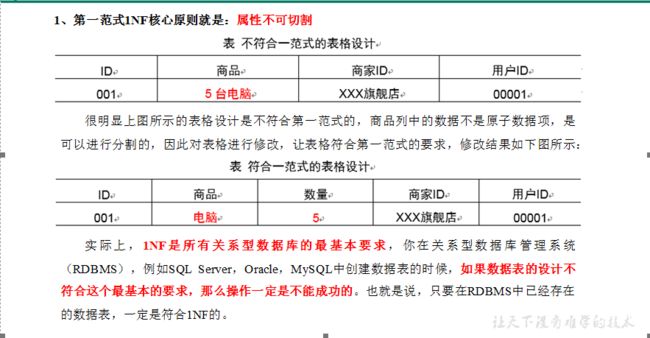
2.2 关系建模与维度建模
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。二者的主要区别对比如下表所示。
| 对比属性 | OLTP | OLAP |
|---|---|---|
| 读特性 | 每次查询只返回少量记录 | 对大量记录进行汇总 |
| 写特性 | 随机、低延时写入用户的输入 | 批量导入 |
| 使用场景 | 用户,Java EE项目 | 内部分析师,为决策提供支持 |
| 数据表征 | 最新数据状态 | 随时间变化的历史状态 |
| 数据规模 | GB | TB到PB |
2.2.1 关系建模

关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用于OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
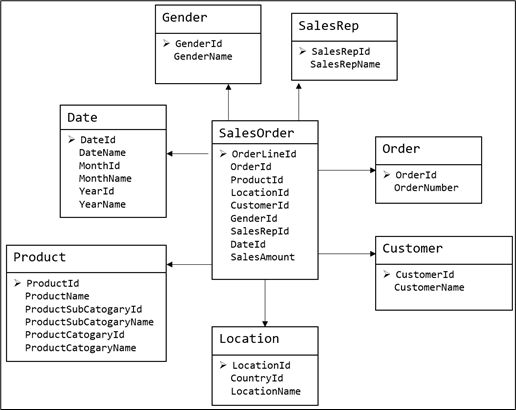
图 维度模型示意图
维度模型如图所示,主要应用于OLAP系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
2.2.2 维度建模
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
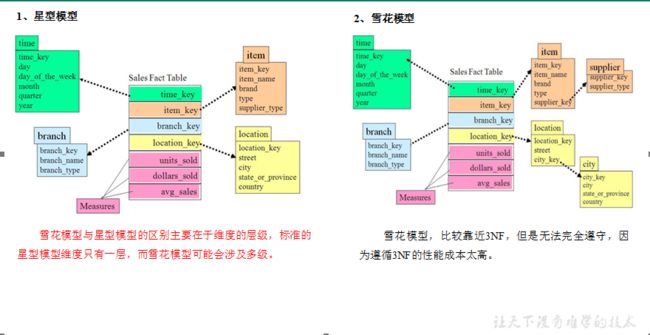
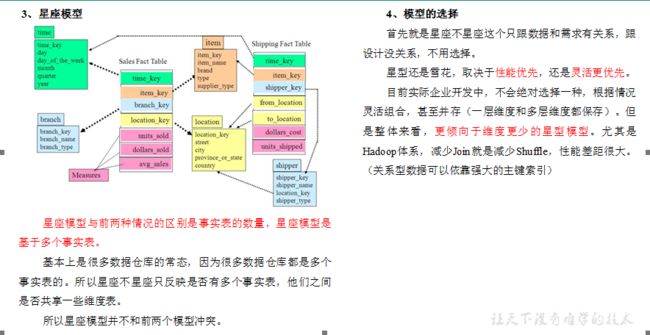
2.3 维度表和事实表(重点)
2.3.1 维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
Ø 维表的范围很宽(具有多个属性、列比较多)
Ø 跟事实表相比,行数相对较小:通常< 10万条
Ø 内容相对固定:编码表
时间维度表:
| 日期ID | day of week | day of year | 季度 | 节假日 |
|---|---|---|---|---|
| 2020-01-01 | 2 | 1 | 1 | 元旦 |
| 2020-01-02 | 3 | 2 | 1 | 无 |
| 2020-01-03 | 4 | 3 | 1 | 无 |
| 2020-01-04 | 5 | 4 | 1 | 无 |
| 2020-01-05 | 6 | 5 | 1 | 无 |
2.3.2 事实表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等)**,例如,2020年5月21日,宋宋老师在京东发了250块钱买了一瓶海狗人参丸。维度表:时间、用户、商品、商家。事实表:250块钱、一瓶
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
事实表的特征:
Ø 非常的大
Ø 内容相对的窄:列数较少(主要是外键id和度量值)
Ø 经常发生变化,每天会新增加很多。
1)事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。
2)周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
例如购物车,有加减商品,随时都有可能变化,但是我们更关心每天结束时这里面有多少商品,方便我们后期统计分析。
3)累积型快照事实表
**累计快照事实表用于跟踪业务事实的变化。**例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
| 订单id | 用户id | 下单时间 | 打包时间 | 发货时间 | 签收时间 | 订单金额 |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
2.4 数据仓库建模(绝对重点)
2.4.1 ODS层
1)HDFS用户行为数据
2)HDFS业务数据

3)针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
(1)保持数据原貌不做任何修改,起到备份数据的作用。
(2)数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右)
(3)创建分区表,防止后续的全表扫描
2.4.2 DWD层
DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
如果是中小公司,尽量把所有业务过程都选择。
如果是大公司(1000多张表),选择和需求相关的业务线。
(2)声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
订单当中的每个商品项作为下单事实表中的一行,粒度为每次。
每周的订单次数作为一行,粒度为每周。
每月的订单次数作为一行,粒度为每月。
如果在DWD层粒度就是每周或者每月,那么后续就没有办法统计细粒度的指标了。所以建议采用最小粒度。
(3)确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
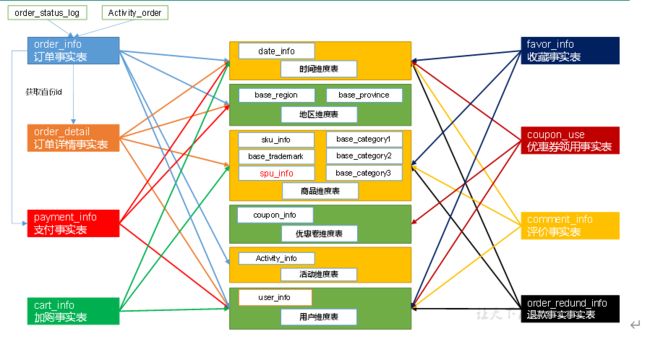
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
维度表:需要根据维度建模中的星型模型原则进行维度退化。
(4)确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。如何判断是否能够关联上呢?在业务表关系图中,只要两张表能通过中间表能够关联上,就说明能关联上。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | √ | 件数/金额 | |||
| 订单详情 | √ | √ | √ | √ | 件数/金额 | |||
| 支付 | √ | √ | √ | 金额 | ||||
| 加购 | √ | √ | √ | 件数/金额 | ||||
| 收藏 | √ | √ | √ | 个数 | ||||
| 评价 | √ | √ | √ | 个数 | ||||
| 退款 | √ | √ | √ | 件数/金额 | ||||
| 优惠券领用 | √ | √ | √ | 个数 |
至此,数据仓库的维度建模已经完毕,DWD层是以业务过程为驱动。
DWS层、DWT层和ADS层都是以需求为驱动,和维度建模已经没有关系了。
DWS和DWT都是建宽表,按照主题去建表。主题相当于观察问题的角度。对应着维度表。
2.4.3 DWS层
DWS层统计各个主题对象的当天行为,服务于DWT层的主题宽表。
(1)问题引出:两个需求,统计每个省份订单的个数、统计每个省份订单的总金额
(2)处理办法:都是将省份表和订单表进行join,group by省份,然后计算。相当于类似的需求重复计算了两次。
那怎么设计能避免重复计算呢?
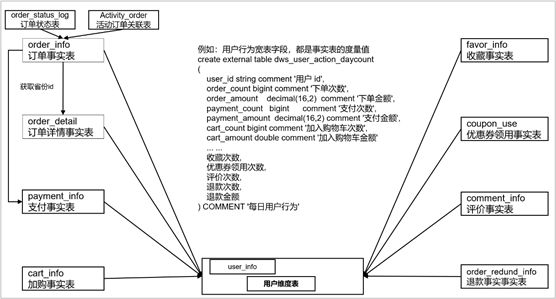
地区宽表的字段设计为:下单次数、下单金额、支付次数、支付金额等。只需要和每个事实表一次join。
(3)总结:
需要建哪些表:以维度为基准,去关联对应多个事实表
宽表里面的字段:是站在不同维度的角度去看事实表,重点关注事实表聚合后的度量值。
(4)DWS层宽表包括:每日设备行为、每日会员行为、每日商品行为、每日活动统计、每日地区统计。
2.4.4 DWT层
DWT层统计各个主题对象的累积行为。
(1)需要建哪些表:和DWS层一样。以维度为基准,去关联对应多个事实表
(2)宽表里面的字段:我们站在维度表的角度去看事实表,重点关注事实表度量值的累积值、事实表行为的首次和末次时间。
例如,订单事实表的度量值是下单次数、下单金额。订单事实表的行为是下单。我们站在用户维度表的角度去看订单事实表,重点关注订单事实表至今的累积下单次数、累积下单金额和某时间段内的累积次数、累积金额,以及关注下单行为的首次时间和末次时间。

(4)DWS层宽表包括:每日设备行为、每日会员行为、每日商品行为、每日活动统计、每日地区统计。
2.4.5 ADS层
对电商系统各大主题指标分别进行分析。
第3章 数仓搭建-ODS层
1)保持数据原貌不做任何修改,起到备份数据的作用。
2)数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内。
3)创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
4)创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
3.1 Hive环境准备
3.1.1 Hive引擎简介
Hive引擎包括:默认MR、tez、spark
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
3.1.2 Hive on Spark配置
1)兼容性说明
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
2)在Hive所在节点部署Spark
如果之前已经部署了Spark,则该步骤可以跳过,但要检查SPARK_HOME的环境变量配置是否正确。
(1)Spark官网下载jar包地址:
http://spark.apache.org/downloads.html
(2)上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[atguigu@hadoop105 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[atguigu@hadoop105 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置SPARK_HOME环境变量
[atguigu@hadoop105 software]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
source 使其生效
[atguigu@hadoop105 software]$ source /etc/profile.d/my_env.sh
(4)新建spark配置文件
[atguigu@hadoop105 software]$ vim /opt/module/hive/conf/spark-defaults.conf
添加如下内容(在执行任务时,会根据如下参数执行)
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop105:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
(5)在HDFS创建如下路径,用于存储历史日志
[atguigu@hadoop105 software]$ hadoop fs -mkdir /spark-history
3)向HDFS上传Spark纯净版jar包
说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
(1)上传并解压spark-3.0.0-bin-without-hadoop.tgz
[atguigu@hadoop105 software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
(2)上传Spark纯净版jar包到HDFS
[atguigu@hadoop105 software]$ hadoop fs -mkdir /spark-jars
[atguigu@hadoop105 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
4)修改hive-site.xml文件
[atguigu@hadoop105 ~]$ vim /opt/module/hive/conf/hive-site.xml
添加如下内容
<property> <name>spark.yarn.jarsname> <value>hdfs://hadoop105:8020/spark-jars/*value> property> <property> <name>hive.execution.enginename> <value>sparkvalue> property> <property> <name>hive.spark.client.connect.timeoutname> <value>10000msvalue> property>
注意:hive.spark.client.connect.timeout的默认值是1000ms,如果执行hive的insert语句时,抛如下异常,可以调大该参数到10000ms
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session d9e0224c-3d14-4bf4-95bc-ee3ec56df48e
3.1.3 Hive on Spark测试
(1)启动hive客户端
[atguigu@hadoop105 hive]$ bin/hive
(2)创建一张测试表
hive (default)> create table student1(id int, name string);
(3)通过insert测试效果
hive (default)> insert into table student1 values(1,'abc');
若结果如下,则说明配置成功

3.1.4 Yarn容量调度器并发度问题演示
Yarn默认调度器为Capacity Scheduler(容量调度器),且默认只有一个队列——default。如果队列中执行第一个任务资源不够,就不会再执行第二个任务,一直等到第一个任务执行完毕。
(1)启动1个hive客户端,执行以下插入数据的sql语句。
hive (default)> insert into table student1 values(1,'abc');
执行该语句,hive会初始化一个Spark Session,用以执行hive on spark任务。由于未指定队列,故该Spark Session默认占用使用的就是default队列,且会一直占用该队列,直到退出hive客户端。
可访问ResourceManager的web页面查看相关信息。
(2)在hive客户端开启的状态下,提交一个MR。
[atguigu@hadoop105 ~]$ hadoop jar /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1
MR任务同样未指定队列,所以其默认也提交到了default队列,由于容量调度器单个队列的并行度为1。故后提交的MR任务会一直等待,不能开始执行。
任务提交界面如下:

ResourceManager的web页面如下:
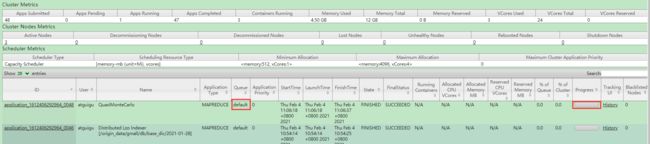
(3)容量调度器default队列中,同一时间只有一个任务执行,并发度低,如何解决呢?
方案一:增加ApplicationMaster资源比例,进而提高运行app数量。
方案二:创建多队列,比如增加一个hive队列。
3.1.5 增加ApplicationMaster资源比例
针对容量调度器并发度低的问题,考虑调整yarn.scheduler.capacity.maximum-am-resource-percent该参数。默认值是0.1,表示集群上AM最多可使用的资源比例,目的为限制过多的app数量。
(1)在hadoop105的/opt/module/hadoop/etc/hadoop/capacity-scheduler.xml文件中修改如下参数值
[atguigu@hadoop105 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percentname>
<value>0.5value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
description>
property>
说明:
集群中用于运行应用程序ApplicationMaster的资源比例上限,
该参数通常用于限制处于活动状态的应用程序数目。该参数类型为浮点型,
默认是0.1,表示10%。所有队列的ApplicationMaster资源比例上限可通过参数
yarn.scheduler.capacity.maximum-am-resource-percent设置,而单个队列可通过参数yarn.scheduler.capacity..maximum-am-resource-percent设置适合自己的值。
(2)分发capacity-scheduler.xml配置文件
[atguigu@hadoop105 hadoop]$ xsync capacity-scheduler.xml
(3)关闭正在运行的任务,重新启动yarn集群
[atguigu@hadoop106 hadoop]$ sbin/stop-yarn.sh
[atguigu@hadoop106 hadoop]$ sbin/start-yarn.sh
3.1.6 增加Yarn容量调度器队列
方案二:创建多队列,也可以增加容量调度器的并发度。
在企业里面如何配置多队列:
按照计算引擎创建队列hive、spark、flink
按照业务创建队列:下单、支付、点赞、评论、收藏(用户、活动、优惠相关)
有什么好处?
假如公司来了一个菜鸟,写了一个递归死循环,公司集群资源耗尽,大数据全部瘫痪。
解耦。
假如11.11数据量非常大,任务非常多,如果所有任务都参与运行,一定执行不完,怎么办?
可以支持降级运行。
下单 √
支付√
点赞X
1)增加容量调度器队列
(1)修改容量调度器配置文件
默认Yarn的配置下,容量调度器只有一条default队列。在capacity-scheduler.xml中可以配置多条队列,修改以下属性,增加hive队列。
<property>
<name>yarn.scheduler.capacity.root.queuesname>
<value>default,hivevalue>
<description>
The queues at the this level (root is the root queue).
再增加一个队列
description>
property>
<property>
<name>yarn.scheduler.capacity.root.default.capacityname>
<value>50value>
<description>Default queue target capacity.description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.capacityname>
<value>50value>
<description>
hive队列的容量为50%
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factorname>
<value>1value>
<description>
一个用户最多能够获取该队列资源容量的比例,取值0-1
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacityname>
<value>80value>
<description>
hive队列的最大容量(自己队列资源不够,可以使用其他队列资源上限)
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.statename>
<value>RUNNINGvalue>
<description>
开启hive队列运行,不设置队列不能使用
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applicationsname>
<value>*value>
<description>
访问控制,控制谁可以将任务提交到该队列,*表示任何人
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queuename>
<value>*value>
<description>
访问控制,控制谁可以管理(包括提交和取消)该队列的任务,*表示任何人
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priorityname>
<value>*value>
<description>
指定哪个用户可以提交配置任务优先级
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetimename>
<value>-1value>
<description>
hive队列中任务的最大生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
description>
property>
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetimename>
<value>-1value>
<description>
hive队列中任务的默认生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。
description>
property>
(2)分发配置文件
[atguigu@hadoop105 ~]$ xsync /opt/module/hadoop/etc/hadoop/capacity-scheduler.xml
(3)重启Hadoop集群
2)测试新队列
设置Hive 队列
set mapreduce.job.queuename=hive;
(1)提交一个MR任务,并指定队列为hive
[atguigu@hadoop105 ~]$ hadoop jar /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -Dmapreduce.job.queuename=hive 1 1
(2)查看ResourceManager的web页面,观察任务被提交到的队列

3.1.7 创建数据库
1)启动hive
[atguigu@hadoop105 hive]$ bin/hive
2)显示数据库
hive (default)> show databases;
3)创建数据库
hive (default)> create database gmall;
4)使用数据库
hive (default)> use gmall;
3.1.8 datagrip工具
datagrip安装及使用教程:https://blog.csdn.net/qq_39346903/article/details/113585688
3.2 ODS层(用户行为数据)
3.2.1 创建日志表ods_log

1)创建支持lzo压缩的分区表
hive (gmall)>
drop table if exists ods_log;
CREATE EXTERNAL TABLE ods_log (`line` string)
PARTITIONED BY (`dt` string) -- 按照时间创建分区
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_log' -- 指定数据在hdfs上的存储位置
;
说明Hive的LZO压缩:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
2)加载数据
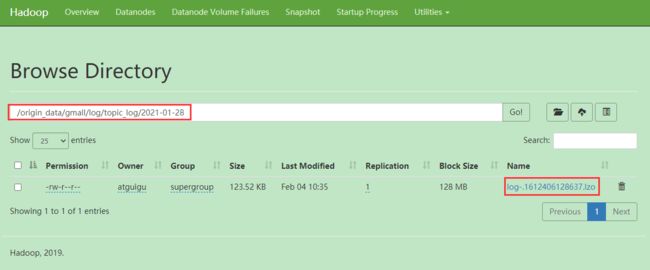
hive (gmall)> load data inpath '/origin_data/gmall/log/topic_log/2021-01-28' into table ods_log partition(dt='2021-01-28');
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
3)查看是否加载成功
hive (gmall)> select * from ods_log limit 2;
4)为lzo压缩文件创建索引
[atguigu@hadoop105 bin]$ hadoop jar /opt/module/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2021-01-28
3.2.2 Shell中单引号和双引号区别
1)在/home/atguigu/bin创建一个test.sh文件
[atguigu@hadoop105 bin]$ vim test.sh
在文件中添加如下内容
#!/bin/bash
do_date=$1
echo '$do_date'
echo "$do_date"
echo "'$do_date'"
echo '"$do_date"'
echo `date`
2)查看执行结果
[atguigu@hadoop105 bin]$ test.sh 2021-01-28
$do_date
2021-01-28
'2021-01-28'
"$do_date"
Thu Feb 4 11:13:57 CST 2021
3)总结:
(1)单引号不取变量值
(2)双引号取变量值
(3)反引号`,执行引号中命令
(4)双引号内部嵌套单引号,取出变量值
(5)单引号内部嵌套双引号,不取出变量值
3.2.3 ODS层加载数据脚本
1)在hadoop105的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop105 bin]$ vim hdfs_to_ods_log.sh
在脚本中编写如下内容
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/opt/module/hive/bin/hive
hadoop=/opt/module/hadoop/bin/hadoop
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/${APP}/log/topic_log/$do_date' into table ${APP}.ods_log partition(dt='$do_date');
"
$hive -e "$sql"
$hadoop jar /opt/module/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/${APP}/ods/ods_log/dt=$do_date
(1)说明1:
[ -n 变量值 ] 判断变量的值,是否为空
– 变量的值,非空,返回true
– 变量的值,为空,返回false
注意:[ -n 变量值 ]不会解析数据,使用[ -n 变量值 ]时,需要对变量加上双引号(" ")
(2)说明2:
查看date命令的使用,date --help
2)增加脚本执行权限
[atguigu@hadoop105 bin]$ chmod 777 hdfs_to_ods_log.sh
3)脚本使用
[atguigu@hadoop105 module]$ hdfs_to_ods_log.sh 2021-01-28
4)查看导入数据
hive (gmall)> select * from ods_log where dt='2021-01-28' limit 2;
5)脚本执行时间
企业开发中一般在每日凌晨30分~1点
3.3 ODS层(业务数据)
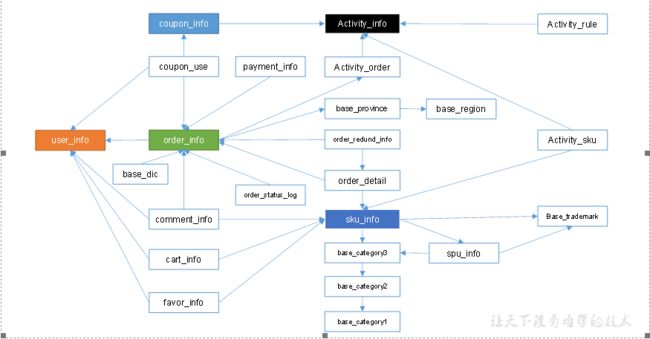

3.3.1 订单表(增量及更新)
hive (gmall)>
drop table if exists ods_order_info;
create external table ods_order_info (
`id` string COMMENT '订单号',
`final_total_amount` decimal(16,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`province_id` string COMMENT '省份ID',
`benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',
`original_total_amount` decimal(16,2) COMMENT '原价金额',
`feight_fee` decimal(16,2) COMMENT '运费'
) COMMENT '订单表'
PARTITIONED BY (`dt` string) -- 按照时间创建分区
row format delimited fields terminated by '\t' -- 指定分割符为\t
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;输出数据采用TextOutputFormat
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_order_info/' -- 指定数据在hdfs上的存储位置
;
3.3.2 订单详情表(增量)
hive (gmall)>
drop table if exists ods_order_detail;
create external table ods_order_detail(
`id` string COMMENT '编号',
`order_id` string COMMENT '订单号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT '商品id',
`sku_name` string COMMENT '商品名称',
`order_price` decimal(16,2) COMMENT '商品价格',
`sku_num` bigint COMMENT '商品数量',
`create_time` string COMMENT '创建时间',
`source_type` string COMMENT '来源类型',
`source_id` string COMMENT '来源编号'
) COMMENT '订单详情表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_order_detail/';
3.3.3 SKU商品表(全量)
hive (gmall)>
drop table if exists ods_sku_info;
create external table ods_sku_info(
`id` string COMMENT 'skuId',
`spu_id` string COMMENT 'spuid',
`price` decimal(16,2) COMMENT '价格',
`sku_name` string COMMENT '商品名称',
`sku_desc` string COMMENT '商品描述',
`weight` string COMMENT '重量',
`tm_id` string COMMENT '品牌id',
`category3_id` string COMMENT '品类id',
`create_time` string COMMENT '创建时间'
) COMMENT 'SKU商品表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_sku_info/';
3.3.4 用户表(增量及更新)
hive (gmall)>
drop table if exists ods_user_info;
create external table ods_user_info(
`id` string COMMENT '用户id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日',
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间'
) COMMENT '用户表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_user_info/';
3.3.5 商品一级分类表(全量)
hive (gmall)>
drop table if exists ods_base_category1;
create external table ods_base_category1(
`id` string COMMENT 'id',
`name` string COMMENT '名称'
) COMMENT '商品一级分类表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_category1/';
3.3.6 商品二级分类表(全量)
hive (gmall)>
drop table if exists ods_base_category2;
create external table ods_base_category2(
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category1_id string COMMENT '一级品类id'
) COMMENT '商品二级分类表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_category2/';
3.3.7 商品三级分类表(全量)
hive (gmall)>
drop table if exists ods_base_category3;
create external table ods_base_category3(
`id` string COMMENT ' id',
`name` string COMMENT '名称',
category2_id string COMMENT '二级品类id'
) COMMENT '商品三级分类表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_category3/';
3.3.8 支付流水表(增量)
hive (gmall)>
drop table if exists ods_payment_info;
create external table ods_payment_info(
`id` bigint COMMENT '编号',
`out_trade_no` string COMMENT '对外业务编号',
`order_id` string COMMENT '订单编号',
`user_id` string COMMENT '用户编号',
`alipay_trade_no` string COMMENT '支付宝交易流水编号',
`total_amount` decimal(16,2) COMMENT '支付金额',
`subject` string COMMENT '交易内容',
`payment_type` string COMMENT '支付类型',
`payment_time` string COMMENT '支付时间'
) COMMENT '支付流水表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_payment_info/';
3.3.9 省份表(特殊)
hive (gmall)>
drop table if exists ods_base_province;
create external table ods_base_province (
`id` bigint COMMENT '编号',
`name` string COMMENT '省份名称',
`region_id` string COMMENT '地区ID',
`area_code` string COMMENT '地区编码',
`iso_code` string COMMENT 'iso编码,superset可视化使用'
) COMMENT '省份表'
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_province/';
3.3.10 地区表(特殊)
hive (gmall)>
drop table if exists ods_base_region;
create external table ods_base_region (
`id` string COMMENT '编号',
`region_name` string COMMENT '地区名称'
) COMMENT '地区表'
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_region/';
3.3.11 品牌表(全量)
hive (gmall)>
drop table if exists ods_base_trademark;
create external table ods_base_trademark (
`tm_id` string COMMENT '编号',
`tm_name` string COMMENT '品牌名称'
) COMMENT '品牌表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_trademark/';
3.3.12 订单状态表(增量)
hive (gmall)>
drop table if exists ods_order_status_log;
create external table ods_order_status_log (
`id` string COMMENT '编号',
`order_id` string COMMENT '订单ID',
`order_status` string COMMENT '订单状态',
`operate_time` string COMMENT '修改时间'
) COMMENT '订单状态表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_order_status_log/';
3.3.13 SPU商品表(全量)
hive (gmall)>
drop table if exists ods_spu_info;
create external table ods_spu_info(
`id` string COMMENT 'spuid',
`spu_name` string COMMENT 'spu名称',
`category3_id` string COMMENT '品类id',
`tm_id` string COMMENT '品牌id'
) COMMENT 'SPU商品表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_spu_info/';
3.3.14 商品评论表(增量)
hive (gmall)>
drop table if exists ods_comment_info;
create external table ods_comment_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户ID',
`sku_id` string COMMENT '商品sku',
`spu_id` string COMMENT '商品spu',
`order_id` string COMMENT '订单ID',
`appraise` string COMMENT '评价',
`create_time` string COMMENT '评价时间'
) COMMENT '商品评论表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_comment_info/';
3.3.15 退单表(增量)
hive (gmall)>
drop table if exists ods_order_refund_info;
create external table ods_order_refund_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户ID',
`order_id` string COMMENT '订单ID',
`sku_id` string COMMENT '商品ID',
`refund_type` string COMMENT '退款类型',
`refund_num` bigint COMMENT '退款件数',
`refund_amount` decimal(16,2) COMMENT '退款金额',
`refund_reason_type` string COMMENT '退款原因类型',
`create_time` string COMMENT '退款时间'
) COMMENT '退单表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_order_refund_info/';
3.3.16 加购表(全量)
hive (gmall)>
drop table if exists ods_cart_info;
create external table ods_cart_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT 'skuid',
`cart_price` decimal(16,2) COMMENT '放入购物车时价格',
`sku_num` bigint COMMENT '数量',
`sku_name` string COMMENT 'sku名称 (冗余)',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '修改时间',
`is_ordered` string COMMENT '是否已经下单',
`order_time` string COMMENT '下单时间',
`source_type` string COMMENT '来源类型',
`source_id` string COMMENT '来源编号'
) COMMENT '加购表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_cart_info/';
3.3.17 商品收藏表(全量)
hive (gmall)>
drop table if exists ods_favor_info;
create external table ods_favor_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT 'skuid',
`spu_id` string COMMENT 'spuid',
`is_cancel` string COMMENT '是否取消',
`create_time` string COMMENT '收藏时间',
`cancel_time` string COMMENT '取消时间'
) COMMENT '商品收藏表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_favor_info/';
3.3.18 优惠券领用表(新增及变化)
hive (gmall)>
drop table if exists ods_coupon_use;
create external table ods_coupon_use(
`id` string COMMENT '编号',
`coupon_id` string COMMENT '优惠券ID',
`user_id` string COMMENT 'skuid',
`order_id` string COMMENT 'spuid',
`coupon_status` string COMMENT '优惠券状态',
`get_time` string COMMENT '领取时间',
`using_time` string COMMENT '使用时间(下单)',
`used_time` string COMMENT '使用时间(支付)'
) COMMENT '优惠券领用表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_coupon_use/';
3.3.19 优惠券表(全量)
hive (gmall)>
drop table if exists ods_coupon_info;
create external table ods_coupon_info(
`id` string COMMENT '购物券编号',
`coupon_name` string COMMENT '购物券名称',
`coupon_type` string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` decimal(16,2) COMMENT '满额数',
`condition_num` bigint COMMENT '满件数',
`activity_id` string COMMENT '活动编号',
`benefit_amount` decimal(16,2) COMMENT '减金额',
`benefit_discount` decimal(16,2) COMMENT '折扣',
`create_time` string COMMENT '创建时间',
`range_type` string COMMENT '范围类型 1、商品 2、品类 3、品牌',
`spu_id` string COMMENT '商品id',
`tm_id` string COMMENT '品牌id',
`category3_id` string COMMENT '品类id',
`limit_num` bigint COMMENT '最多领用次数',
`operate_time` string COMMENT '修改时间',
`expire_time` string COMMENT '过期时间'
) COMMENT '优惠券表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_coupon_info/';
3.3.20 活动表(全量)
hive (gmall)>
drop table if exists ods_activity_info;
create external table ods_activity_info(
`id` string COMMENT '编号',
`activity_name` string COMMENT '活动名称',
`activity_type` string COMMENT '活动类型',
`start_time` string COMMENT '开始时间',
`end_time` string COMMENT '结束时间',
`create_time` string COMMENT '创建时间'
) COMMENT '活动表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_activity_info/';
3.3.21 活动订单关联表(增量)
hive (gmall)>
drop table if exists ods_activity_order;
create external table ods_activity_order(
`id` string COMMENT '编号',
`activity_id` string COMMENT '优惠券ID',
`order_id` string COMMENT 'skuid',
`create_time` string COMMENT '领取时间'
) COMMENT '活动订单关联表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_activity_order/';
3.3.22 优惠规则表(全量)
hive (gmall)>
drop table if exists ods_activity_rule;
create external table ods_activity_rule(
`id` string COMMENT '编号',
`activity_id` string COMMENT '活动ID',
`condition_amount` decimal(16,2) COMMENT '满减金额',
`condition_num` bigint COMMENT '满减件数',
`benefit_amount` decimal(16,2) COMMENT '优惠金额',
`benefit_discount` decimal(16,2) COMMENT '优惠折扣',
`benefit_level` string COMMENT '优惠级别'
) COMMENT '优惠规则表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_activity_rule/';
3.3.23 编码字典表(全量)
hive (gmall)>
drop table if exists ods_base_dic;
create external table ods_base_dic(
`dic_code` string COMMENT '编号',
`dic_name` string COMMENT '编码名称',
`parent_code` string COMMENT '父编码',
`create_time` string COMMENT '创建日期',
`operate_time` string COMMENT '操作日期'
) COMMENT '编码字典表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_base_dic/';
3.3.24 ODS层加载数据脚本
1.编写脚本
1)在/home/atguigu/bin目录下创建脚本hdfs_to_ods_db.sh
[atguigu@hadoop105 bin]$ vim hdfs_to_ods_db.sh
在脚本中填写如下内容
#!/bin/bash
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
sql1="
load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table ${APP}.ods_sku_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table ${APP}.ods_user_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table ${APP}.ods_payment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table ${APP}.ods_base_category1 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table ${APP}.ods_base_category2 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table ${APP}.ods_base_category3 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_trademark/$do_date' OVERWRITE into table ${APP}.ods_base_trademark partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_info/$do_date' OVERWRITE into table ${APP}.ods_activity_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_order/$do_date' OVERWRITE into table ${APP}.ods_activity_order partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/cart_info/$do_date' OVERWRITE into table ${APP}.ods_cart_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/comment_info/$do_date' OVERWRITE into table ${APP}.ods_comment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/coupon_info/$do_date' OVERWRITE into table ${APP}.ods_coupon_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/coupon_use/$do_date' OVERWRITE into table ${APP}.ods_coupon_use partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/favor_info/$do_date' OVERWRITE into table ${APP}.ods_favor_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_refund_info/$do_date' OVERWRITE into table ${APP}.ods_order_refund_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_status_log/$do_date' OVERWRITE into table ${APP}.ods_order_status_log partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/spu_info/$do_date' OVERWRITE into table ${APP}.ods_spu_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_rule/$do_date' OVERWRITE into table ${APP}.ods_activity_rule partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_dic/$do_date' OVERWRITE into table ${APP}.ods_base_dic partition(dt='$do_date');
"
sql2="
load data inpath '/origin_data/$APP/db/base_province/$do_date' OVERWRITE into table ${APP}.ods_base_province;
load data inpath '/origin_data/$APP/db/base_region/$do_date' OVERWRITE into table ${APP}.ods_base_region;
"
case $1 in
"first"){
$hive -e "$sql1$sql2"
};;
"all"){
$hive -e "$sql1"
};;
esac
2)修改权限
[atguigu@hadoop105 bin]$ chmod 777 hdfs_to_ods_db.sh
2.脚本使用说明
1)初次导入
初次导入时,脚本的第一个参数应为first,线上环境不传第二个参数,自动获取前一天日期
[atguigu@hadoop105 bin]$ hdfs_to_ods_db.sh first 2021-01-28
2)每日导入
每日重复导入,脚本的第一个参数应为all,线上环境不传第二个参数,自动获取前一天日期。
[atguigu@hadoop105 bin]$ hdfs_to_ods_db.sh all 2021-01-28
3)测试数据是否导入成功
hive (gmall)>
select * from ods_order_detail where dt='2021-01-28';
第4章 数仓搭建-DWD层
1)对用户行为数据解析。
2)对核心数据进行判空过滤。
3)对业务数据采用维度模型重新建模。
4.1 DWD层(用户行为日志解析)
4.1.1 日志格式回顾
(1)页面埋点日志

(2)启动日志
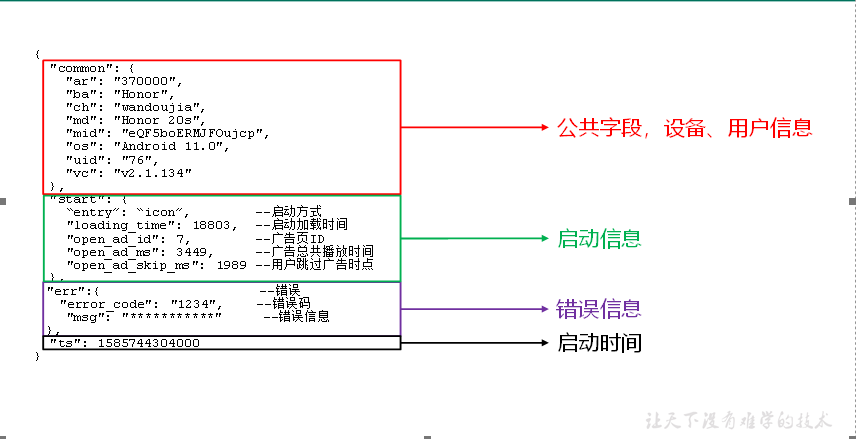
4.1.2 get_json_object函数使用
1)数据
[{
"name":"大郎","sex":"男","age":"25"},{
"name":"西门庆","sex":"男","age":"47"}]
2)取出第一个json对象
hive (gmall)>
select get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]','$[0]');
结果是:{“name”:“大郎”,“sex”:“男”,“age”:“25”}
3)取出第一个json的age字段的值
hive (gmall)>
SELECT get_json_object('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]',"$[0].age");
结果是:25
4.1.3 启动日志表
**启动日志解析思路:**启动日志表中每行数据对应一个启动记录,一个启动记录应该包含日志中的公共信息和启动信息。先将所有包含start字段的日志过滤出来,然后使用get_json_object函数解析每个字段。

1)建表语句
hive (gmall)>
drop table if exists dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员id',
`version_code` string COMMENT 'app版本号',
`entry` string COMMENT ' icon手机图标 notice 通知 install 安装后启动',
`loading_time` bigint COMMENT '启动加载时间',
`open_ad_id` string COMMENT '广告页ID ',
`open_ad_ms` bigint COMMENT '广告总共播放时间',
`open_ad_skip_ms` bigint COMMENT '用户跳过广告时点',
`ts` bigint COMMENT '时间'
) COMMENT '启动日志表'
PARTITIONED BY (dt string) -- 按照时间创建分区
stored as parquet -- 采用parquet列式存储
LOCATION '/warehouse/gmall/dwd/dwd_start_log' -- 指定在HDFS上存储位置
TBLPROPERTIES('parquet.compression'='lzo') -- 采用LZO压缩
;
说明:数据采用parquet存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的text方式存储数据,需要采用支持切片的,lzop压缩方式并创建索引。
2)数据导入
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_start_log partition(dt='2021-01-28')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.ts')
from ods_log
where dt='2021-01-28'
and get_json_object(line,'$.start') is not null;
3)查看数据
hive (gmall)>
select * from dwd_start_log where dt='2021-01-28' limit 2;
4)Hive读取索引文件问题
(1)两种方式,分别查询数据有多少行
hive (gmall)> select * from ods_log;
Time taken: 0.706 seconds, Fetched: 2955 row(s)
hive (gmall)> select count(*) from ods_log;
2959
(2)两次查询结果不一致。
原因是select * from ods_log不执行MR操作,默认采用的是ods_log建表语句中指定的DeprecatedLzoTextInputFormat,能够识别lzo.index为索引文件。
select count(*) from ods_log执行MR操作,默认采用的是CombineHiveInputFormat,不能识别lzo.index为索引文件,将索引文件当做普通文件处理。更严重的是,这会导致LZO文件无法切片。
hive (gmall)> set hive.input.format;
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
解决办法:修改CombineHiveInputFormat为HiveInputFormat
(3)再次测试
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
hive (gmall)> select * from ods_log;
Time taken: 0.706 seconds, Fetched: 2955 row(s)
hive (gmall)> select count(*) from ods_log;
2955
4.1.4 页面日志表
**页面日志解析思路:**页面日志表中每行数据对应一个页面访问记录,一个页面访问记录应该包含日志中的公共信息和页面信息。先将所有包含page字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
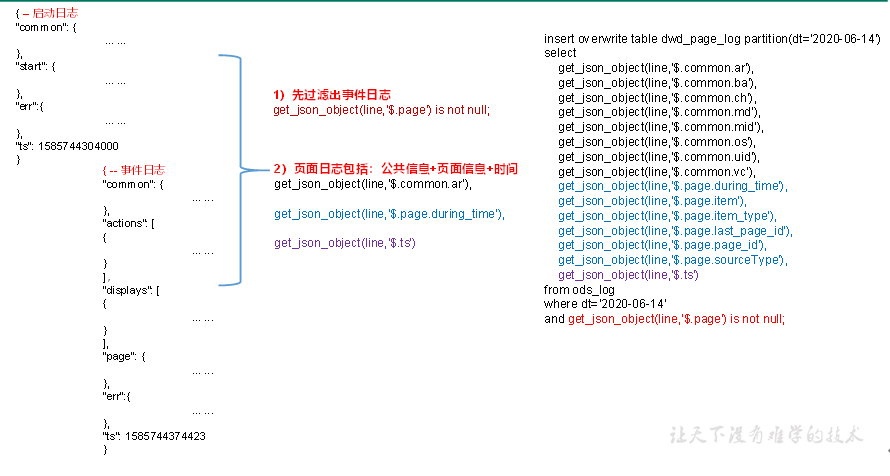
1)建表语句
hive (gmall)>
drop table if exists dwd_page_log;
CREATE EXTERNAL TABLE dwd_page_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员id',
`version_code` string COMMENT 'app版本号',
`during_time` bigint COMMENT '持续时间毫秒',
`page_item` string COMMENT '目标id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面ID ',
`source_type` string COMMENT '来源类型',
`ts` bigint
) COMMENT '页面日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_page_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_page_log partition(dt='2021-01-28')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts')
from ods_log
where dt='2021-01-28'
and get_json_object(line,'$.page') is not null;
3)查看数据
hive (gmall)>
select * from dwd_page_log where dt='2021-01-28' limit 2;
4.1.5 动作日志表
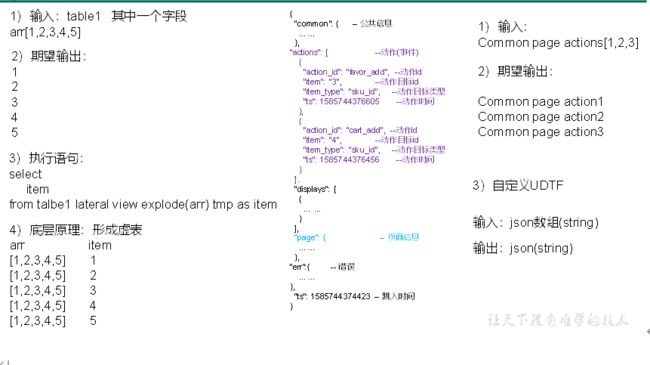
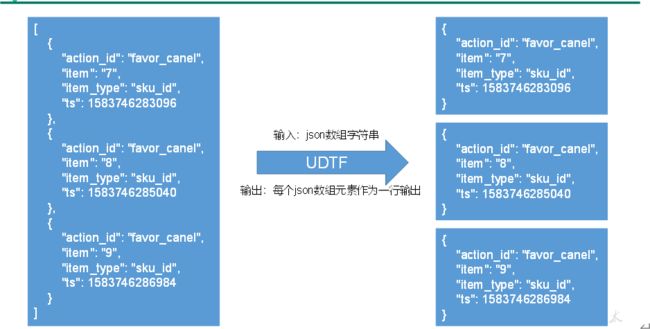
**动作日志解析思路:**动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含action字段的日志过滤出来,然后通过UDTF函数,将action数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

1)建表语句
hive (gmall)>
drop table if exists dwd_action_log;
CREATE EXTERNAL TABLE dwd_action_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员id',
`version_code` string COMMENT 'app版本号',
`during_time` bigint COMMENT '持续时间毫秒',
`page_item` string COMMENT '目标id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面id ',
`source_type` string COMMENT '来源类型',
`action_id` string COMMENT '动作id',
`item` string COMMENT '目标id ',
`item_type` string COMMENT '目标类型',
`ts` bigint COMMENT '时间'
) COMMENT '动作日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_action_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)创建UDTF函数——设计思路
3)创建UDTF函数——编写代码
(1)创建一个maven工程:hive
(2)创建包名:com.atguigu.hive.udtf
(3)引入如下依赖
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.2version>
dependency>
dependencies>
(4)编码
package com.atguigu.hive.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import java.util.ArrayList;
import java.util.List;
public class ExplodeJSONArray extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
// 1 参数合法性检查
if (argOIs.getAllStructFieldRefs().size() != 1) {
throw new UDFArgumentException("ExplodeJSONArray 只需要一个参数");
}
// 2 第一个参数必须为string
if (!"string".equals(argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector().getTypeName())) {
throw new UDFArgumentException("json_array_to_struct_array的第1个参数应为string类型");
}
// 3 定义返回值名称和类型
List<String> fieldNames = new ArrayList<String>();
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("items");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] objects) throws HiveException {
// 1 获取传入的数据
String jsonArray = objects[0].toString();
// 2 将string转换为json数组
JSONArray actions = new JSONArray(jsonArray);
// 3 循环一次,取出数组中的一个json,并写出
for (int i = 0; i < actions.length(); i++) {
String[] result = new String[1];
result[0] = actions.getString(i);
forward(result);
}
}
@Override
public void close() throws HiveException {
}
}
4)创建函数
(1)打包
(2)将hive-1.0-SNAPSHOT.jar上传到hadoop105的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
[atguigu@hadoop105 module]$ hadoop fs -mkdir -p /user/hive/jars
[atguigu@hadoop105 module]$ hadoop fs -put hive-1.0-SNAPSHOT.jar /user/hive/jars
(3)创建永久函数与开发好的java class关联
hive (gmall)>create function explode_json_array as 'com.atguigu.hive.udtf.ExplodeJSONArray' using jar 'hdfs://hadoop105:8020/user/hive/jars/hive-1.0-SNAPSHOT.jar';
(4)注意:如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
5)数据导入
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_action_log partition(dt='2021-01-28')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(action,'$.action_id'),
get_json_object(action,'$.item'),
get_json_object(action,'$.item_type'),
get_json_object(action,'$.ts')
from ods_log lateral view explode_json_array(get_json_object(line,'$.actions')) tmp as action
where dt='2021-01-28'
and get_json_object(line,'$.actions') is not null;
3)查看数据
hive (gmall)>
select * from dwd_action_log where dt='2021-01-28' limit 2;
4.1.6 曝光日志表
**曝光日志解析思路:**曝光日志表中每行数据对应一个曝光记录,一个曝光记录应当包含公共信息、页面信息以及曝光信息。先将包含display字段的日志过滤出来,然后通过UDTF函数,将display数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。

1)建表语句
hive (gmall)>
drop table if exists dwd_display_log;
CREATE EXTERNAL TABLE dwd_display_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员id',
`version_code` string COMMENT 'app版本号',
`during_time` bigint COMMENT 'app版本号',
`page_item` string COMMENT '目标id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面ID ',
`source_type` string COMMENT '来源类型',
`ts` bigint COMMENT 'app版本号',
`display_type` string COMMENT '曝光类型',
`item` string COMMENT '曝光对象id ',
`item_type` string COMMENT 'app版本号',
`order` bigint COMMENT '出现顺序'
) COMMENT '曝光日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_display_log'
TBLPROPERTIES('parquet.compression'='lzo');
2)数据导入
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_display_log partition(dt='2021-01-28')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts'),
get_json_object(display,'$.displayType'),
get_json_object(display,'$.item'),
get_json_object(display,'$.item_type'),
get_json_object(display,'$.order')
from ods_log lateral view explode_json_array(get_json_object(line,'$.displays')) tmp as display
where dt='2021-01-28'
and get_json_object(line,'$.displays') is not null;
3)查看数据
hive (gmall)> select * from dwd_display_log where dt='2021-01-28' limit 2;
4.1.7 错误日志表
**错误日志解析思路:**错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含err字段的日志过滤出来,然后使用get_json_object函数解析所有字段。

1)建表语句
hive (gmall)>
drop table if exists dwd_error_log;
CREATE EXTERNAL TABLE dwd_error_log(
`area_code` string COMMENT '地区编码',
`brand` string COMMENT '手机品牌',
`channel` string COMMENT '渠道',
`model` string COMMENT '手机型号',
`mid_id` string COMMENT '设备id',
`os` string COMMENT '操作系统',
`user_id` string COMMENT '会员id',
`version_code` string COMMENT 'app版本号',
`page_item` string COMMENT '目标id ',
`page_item_type` string COMMENT '目标类型',
`last_page_id` string COMMENT '上页类型',
`page_id` string COMMENT '页面ID ',
`source_type` string COMMENT '来源类型',
`entry` string COMMENT ' icon手机图标 notice 通知 install 安装后启动',
`loading_time` string COMMENT '启动加载时间',
`open_ad_id` string COMMENT '广告页ID ',
`open_ad_ms` string COMMENT '广告总共播放时间',
`open_ad_skip_ms` string COMMENT '用户跳过广告时点',
`actions` string COMMENT '动作',
`displays` string COMMENT '曝光',
`ts` string COMMENT '时间',
`error_code` string COMMENT '错误码',
`msg` string COMMENT '错误信息'
) COMMENT '错误日志表'
PARTITIONED BY (dt string)
stored as parquet
LOCATION '/warehouse/gmall/dwd/dwd_error_log'
TBLPROPERTIES('parquet.compression'='lzo');
说明:此处为对动作数组和曝光数组做处理,如需分析错误与单个动作或曝光的关联,可先使用explode_json_array函数将数组“炸开”,再使用get_json_object函数获取具体字段。
4)数据导入
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_error_log partition(dt='2021-01-28')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.actions'),
get_json_object(line,'$.displays'),
get_json_object(line,'$.ts'),
get_json_object(line,'$.err.error_code'),
get_json_object(line,'$.err.msg')
from ods_log
where dt='2021-01-28'
and get_json_object(line,'$.err') is not null;
5)查看数据
hive (gmall)>
select * from dwd_error_log where dt='2021-01-28' limit 2;
4.1.8 DWD层用户行为数据加载脚本
1)在hadoop105的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop105 bin]$ vim ods_to_dwd_log.sh
在脚本中编写如下内容
#!/bin/bash
hive=/opt/module/hive/bin/hive
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
SET mapreduce.job.queuename=hive;
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_start_log partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.ts')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.start') is not null;
insert overwrite table ${APP}.dwd_action_log partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(action,'$.action_id'),
get_json_object(action,'$.item'),
get_json_object(action,'$.item_type'),
get_json_object(action,'$.ts')
from ${APP}.ods_log lateral view ${APP}.explode_json_array(get_json_object(line,'$.actions')) tmp as action
where dt='$do_date'
and get_json_object(line,'$.actions') is not null;
insert overwrite table ${APP}.dwd_display_log partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts'),
get_json_object(display,'$.displayType'),
get_json_object(display,'$.item'),
get_json_object(display,'$.item_type'),
get_json_object(display,'$.order')
from ${APP}.ods_log lateral view ${APP}.explode_json_array(get_json_object(line,'$.displays')) tmp as display
where dt='$do_date'
and get_json_object(line,'$.displays') is not null;
insert overwrite table ${APP}.dwd_page_log partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.during_time'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.ts')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.page') is not null;
insert overwrite table ${APP}.dwd_error_log partition(dt='$do_date')
select
get_json_object(line,'$.common.ar'),
get_json_object(line,'$.common.ba'),
get_json_object(line,'$.common.ch'),
get_json_object(line,'$.common.md'),
get_json_object(line,'$.common.mid'),
get_json_object(line,'$.common.os'),
get_json_object(line,'$.common.uid'),
get_json_object(line,'$.common.vc'),
get_json_object(line,'$.page.item'),
get_json_object(line,'$.page.item_type'),
get_json_object(line,'$.page.last_page_id'),
get_json_object(line,'$.page.page_id'),
get_json_object(line,'$.page.sourceType'),
get_json_object(line,'$.start.entry'),
get_json_object(line,'$.start.loading_time'),
get_json_object(line,'$.start.open_ad_id'),
get_json_object(line,'$.start.open_ad_ms'),
get_json_object(line,'$.start.open_ad_skip_ms'),
get_json_object(line,'$.actions'),
get_json_object(line,'$.displays'),
get_json_object(line,'$.ts'),
get_json_object(line,'$.err.error_code'),
get_json_object(line,'$.err.msg')
from ${APP}.ods_log
where dt='$do_date'
and get_json_object(line,'$.err') is not null;
"
$hive -e "$sql"
2)增加脚本执行权限
[atguigu@hadoop105 bin]$ chmod 777 ods_to_dwd_log.sh
3)脚本使用
[atguigu@hadoop105 module]$ ods_to_dwd_log.sh 2021-01-28
4)查询导入结果
hive (gmall)>
select * from dwd_start_log where dt='2021-01-28' limit 2;
5)脚本执行时间
企业开发中一般在每日凌晨30分~1点
4.2 DWD层(业务数据)
业务数据方面DWD层的搭建主要注意点在于维度的退化,减少后续大量Join操作。

4.4.1 商品维度表(全量)
商品维度表主要是将商品表SKU表、商品一级分类、商品二级分类、商品三级分类、商品品牌表和商品SPU表退化为商品表。

1)建表语句
hive (gmall)>
DROP TABLE IF EXISTS `dwd_dim_sku_info`;
CREATE EXTERNAL TABLE `dwd_dim_sku_info` (
`id` string COMMENT '商品id',
`spu_id` string COMMENT 'spuid',
`price` decimal(16,2) COMMENT '商品价格',
`sku_name` string COMMENT '商品名称',
`sku_desc` string COMMENT '商品描述',
`weight` decimal(16,2) COMMENT '重量',
`tm_id` string COMMENT '品牌id',
`tm_name` string COMMENT '品牌名称',
`category3_id` string COMMENT '三级分类id',
`category2_id` string COMMENT '二级分类id',
`category1_id` string COMMENT '一级分类id',
`category3_name` string COMMENT '三级分类名称',
`category2_name` string COMMENT '二级分类名称',
`category1_name` string COMMENT '一级分类名称',
`spu_name` string COMMENT 'spu名称',
`create_time` string COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_sku_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_sku_info partition(dt='2021-01-28')
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
ob.tm_name,
sku.category3_id,
c2.id category2_id,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
spu.spu_name,
sku.create_time
from
(
select * from ods_sku_info where dt='2021-01-28'
)sku
join
(
select * from ods_base_trademark where dt='2021-01-28'
)ob on sku.tm_id=ob.tm_id
join
(
select * from ods_spu_info where dt='2021-01-28'
)spu on spu.id = sku.spu_id
join
(
select * from ods_base_category3 where dt='2021-01-28'
)c3 on sku.category3_id=c3.id
join
(
select * from ods_base_category2 where dt='2021-01-28'
)c2 on c3.category2_id=c2.id
join
(
select * from ods_base_category1 where dt='2021-01-28'
)c1 on c2.category1_id=c1.id;
3)查询加载结果
hive (gmall)> select * from dwd_dim_sku_info where dt='2021-01-28' limit 2;
4.4.2 优惠券维度表(全量)
把ODS层ods_coupon_info表数据导入到DWD层优惠卷维度表,在导入过程中可以做适当的清洗。
1)建表语句
hive (gmall)>
drop table if exists dwd_dim_coupon_info;
create external table dwd_dim_coupon_info(
`id` string COMMENT '购物券编号',
`coupon_name` string COMMENT '购物券名称',
`coupon_type` string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` decimal(16,2) COMMENT '满额数',
`condition_num` bigint COMMENT '满件数',
`activity_id` string COMMENT '活动编号',
`benefit_amount` decimal(16,2) COMMENT '减金额',
`benefit_discount` decimal(16,2) COMMENT '折扣',
`create_time` string COMMENT '创建时间',
`range_type` string COMMENT '范围类型 1、商品 2、品类 3、品牌',
`spu_id` string COMMENT '商品id',
`tm_id` string COMMENT '品牌id',
`category3_id` string COMMENT '品类id',
`limit_num` bigint COMMENT '最多领用次数',
`operate_time` string COMMENT '修改时间',
`expire_time` string COMMENT '过期时间'
) COMMENT '优惠券维度表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_coupon_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_coupon_info partition(dt='2021-01-28')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from ods_coupon_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_dim_coupon_info where dt='2021-01-28' limit 2;
4.4.3 活动维度表(全量)

1)建表语句
hive (gmall)>
drop table if exists dwd_dim_activity_info;
create external table dwd_dim_activity_info(
`id` string COMMENT '编号',
`activity_name` string COMMENT '活动名称',
`activity_type` string COMMENT '活动类型',
`start_time` string COMMENT '开始时间',
`end_time` string COMMENT '结束时间',
`create_time` string COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_activity_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_activity_info partition(dt='2021-01-28')
select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from ods_activity_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_dim_activity_info where dt='2021-01-28' limit 2;
4.4.4 地区维度表(特殊)

1)建表语句
hive (gmall)>
DROP TABLE IF EXISTS `dwd_dim_base_province`;
CREATE EXTERNAL TABLE `dwd_dim_base_province` (
`id` string COMMENT 'id',
`province_name` string COMMENT '省市名称',
`area_code` string COMMENT '地区编码',
`iso_code` string COMMENT 'ISO编码',
`region_id` string COMMENT '地区id',
`region_name` string COMMENT '地区名称'
) COMMENT '地区维度表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_base_province/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.region_id,
br.region_name
from
ods_base_province bp
join
ods_base_region br
on bp.region_id = br.id;
3)查询加载结果
hive (gmall)> select * from dwd_dim_base_province limit 2;
4.4.5 时间维度表(特殊)
1)建表语句
hive (gmall)>
DROP TABLE IF EXISTS `dwd_dim_date_info`;
CREATE EXTERNAL TABLE `dwd_dim_date_info`(
`date_id` string COMMENT '日',
`week_id` string COMMENT '周',
`week_day` string COMMENT '周的第几天',
`day` string COMMENT '每月的第几天',
`month` string COMMENT '第几月',
`quarter` string COMMENT '第几季度',
`year` string COMMENT '年',
`is_workday` string COMMENT '是否是周末',
`holiday_id` string COMMENT '是否是节假日'
) COMMENT '时间维度表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_date_info/'
tblproperties ("parquet.compression"="lzo");
2)把date_info.txt文件上传到hadoop105的/opt/module/db_log/路径
3)数据装载
注意:由于dwd_dim_date_info是列式存储+LZO压缩。直接将date_info.txt文件导入到目标表,并不会直接转换为列式存储+LZO压缩。我们需要创建一张普通的临时表dwd_dim_date_info_tmp,将date_info.txt加载到该临时表中。最后通过查询临时表数据,把查询到的数据插入到最终的目标表中。
(1)创建临时表,非列式存储
hive (gmall)>
DROP TABLE IF EXISTS `dwd_dim_date_info_tmp`;
CREATE EXTERNAL TABLE `dwd_dim_date_info_tmp`(
`date_id` string COMMENT '日',
`week_id` string COMMENT '周',
`week_day` string COMMENT '周的第几天',
`day` string COMMENT '每月的第几天',
`month` string COMMENT '第几月',
`quarter` string COMMENT '第几季度',
`year` string COMMENT '年',
`is_workday` string COMMENT '是否是周末',
`holiday_id` string COMMENT '是否是节假日'
) COMMENT '时间临时表'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/dwd/dwd_dim_date_info_tmp/';
(2)将数据导入临时表
hive (gmall)>
load data local inpath '/opt/module/db_log/date_info.txt' into table dwd_dim_date_info_tmp;
(3)将数据导入正式表
hive (gmall)>
insert overwrite table dwd_dim_date_info select * from dwd_dim_date_info_tmp;
4)查询加载结果
hive (gmall)> select * from dwd_dim_date_info;
4.4.6 支付事实表(事务型事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 支付 | √ | √ | √ | 金额 |

1)建表语句
hive (gmall)>
drop table if exists dwd_fact_payment_info;
create external table dwd_fact_payment_info (
`id` string COMMENT 'id',
`out_trade_no` string COMMENT '对外业务编号',
`order_id` string COMMENT '订单编号',
`user_id` string COMMENT '用户编号',
`alipay_trade_no` string COMMENT '支付宝交易流水编号',
`payment_amount` decimal(16,2) COMMENT '支付金额',
`subject` string COMMENT '交易内容',
`payment_type` string COMMENT '支付类型',
`payment_time` string COMMENT '支付时间',
`province_id` string COMMENT '省份ID'
) COMMENT '支付事实表表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_payment_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_payment_info partition(dt='2021-01-28')
select
pi.id,
pi.out_trade_no,
pi.order_id,
pi.user_id,
pi.alipay_trade_no,
pi.total_amount,
pi.subject,
pi.payment_type,
pi.payment_time,
oi.province_id
from
(
select * from ods_payment_info where dt='2021-01-28'
)pi
join
(
select id, province_id from ods_order_info where dt='2021-01-28'
)oi
on pi.order_id = oi.id;
3)查询加载结果
hive (gmall)> select * from dwd_fact_payment_info where dt='2021-01-28' limit 2;
4.4.7 退款事实表(事务型事实表)
把ODS层ods_order_refund_info表数据导入到DWD层退款事实表,在导入过程中可以做适当的清洗。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 退款 | √ | √ | √ | 件数/金额 |
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_order_refund_info;
create external table dwd_fact_order_refund_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户ID',
`order_id` string COMMENT '订单ID',
`sku_id` string COMMENT '商品ID',
`refund_type` string COMMENT '退款类型',
`refund_num` bigint COMMENT '退款件数',
`refund_amount` decimal(16,2) COMMENT '退款金额',
`refund_reason_type` string COMMENT '退款原因类型',
`create_time` string COMMENT '退款时间'
) COMMENT '退款事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_refund_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_refund_info partition(dt='2021-01-28')
select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from ods_order_refund_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_fact_order_refund_info where dt='2021-01-28' limit 2;
4.4.8 评价事实表(事务型事实表)
把ODS层ods_comment_info表数据导入到DWD层评价事实表,在导入过程中可以做适当的清洗。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 评价 | √ | √ | √ | 个数 |
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_comment_info;
create external table dwd_fact_comment_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户ID',
`sku_id` string COMMENT '商品sku',
`spu_id` string COMMENT '商品spu',
`order_id` string COMMENT '订单ID',
`appraise` string COMMENT '评价',
`create_time` string COMMENT '评价时间'
) COMMENT '评价事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_comment_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_comment_info partition(dt='2021-01-28')
select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from ods_comment_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_fact_comment_info where dt='2021-01-28' limit 2;
4.4.9 订单明细事实表(事务型事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单详情 | √ | √ | √ | √ | 件数/金额 |


1)建表语句
hive (gmall)>
drop table if exists dwd_fact_order_detail;
create external table dwd_fact_order_detail (
`id` string COMMENT '订单编号',
`order_id` string COMMENT '订单号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT 'sku商品id',
`sku_name` string COMMENT '商品名称',
`order_price` decimal(16,2) COMMENT '商品价格',
`sku_num` bigint COMMENT '商品数量',
`create_time` string COMMENT '创建时间',
`province_id` string COMMENT '省份ID',
`source_type` string COMMENT '来源类型',
`source_id` string COMMENT '来源编号',
`original_amount_d` decimal(20,2) COMMENT '原始价格分摊',
`final_amount_d` decimal(20,2) COMMENT '购买价格分摊',
`feight_fee_d` decimal(20,2) COMMENT '分摊运费',
`benefit_reduce_amount_d` decimal(20,2) COMMENT '分摊优惠'
) COMMENT '订单明细事实表表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_detail/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_detail partition(dt='2021-01-28')
select
id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
create_time,
province_id,
source_type,
source_id,
original_amount_d,
if(rn=1,final_total_amount -(sum_div_final_amount - final_amount_d),final_amount_d),
if(rn=1,feight_fee - (sum_div_feight_fee - feight_fee_d),feight_fee_d),
if(rn=1,benefit_reduce_amount - (sum_div_benefit_reduce_amount -benefit_reduce_amount_d), benefit_reduce_amount_d)
from
(
select
od.id,
od.order_id,
od.user_id,
od.sku_id,
od.sku_name,
od.order_price,
od.sku_num,
od.create_time,
oi.province_id,
od.source_type,
od.source_id,
round(od.order_price*od.sku_num,2) original_amount_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_amount_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d,
row_number() over(partition by od.order_id order by od.id desc) rn,
oi.final_total_amount,
oi.feight_fee,
oi.benefit_reduce_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2)) over(partition by od.order_id) sum_div_final_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2)) over(partition by od.order_id) sum_div_feight_fee,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) sum_div_benefit_reduce_amount
from
(
select * from ods_order_detail where dt='2021-01-28'
) od
join
(
select * from ods_order_info where dt='2021-01-28'
) oi
on od.order_id=oi.id
)t1;
3)查询加载结果
hive (gmall)> select * from dwd_fact_order_detail where dt='2021-01-28' limit 2;
4.4.10 加购事实表(周期型快照事实表,每日快照)
由于购物车的数量是会发生变化,所以导增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
周期型快照事实表劣势:存储的数据量会比较大。
解决方案:周期型快照事实表存储的数据比较讲究时效性,时间太久了的意义不大,可以删除以前的数据。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 加购 | √ | √ | √ | 件数/金额 |
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_cart_info;
create external table dwd_fact_cart_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT 'skuid',
`cart_price` string COMMENT '放入购物车时价格',
`sku_num` string COMMENT '数量',
`sku_name` string COMMENT 'sku名称 (冗余)',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '修改时间',
`is_ordered` string COMMENT '是否已经下单。1为已下单;0为未下单',
`order_time` string COMMENT '下单时间',
`source_type` string COMMENT '来源类型',
`srouce_id` string COMMENT '来源编号'
) COMMENT '加购事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_cart_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_cart_info partition(dt='2021-01-28')
select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from ods_cart_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_fact_cart_info where dt='2021-01-28' limit 2;
4.4.11 收藏事实表(周期型快照事实表,每日快照)
收藏的标记,是否取消,会发生变化,做增量不合适。
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 收藏 | √ | √ | √ | 个数 |
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_favor_info;
create external table dwd_fact_favor_info(
`id` string COMMENT '编号',
`user_id` string COMMENT '用户id',
`sku_id` string COMMENT 'skuid',
`spu_id` string COMMENT 'spuid',
`is_cancel` string COMMENT '是否取消',
`create_time` string COMMENT '收藏时间',
`cancel_time` string COMMENT '取消时间'
) COMMENT '收藏事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_favor_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_favor_info partition(dt='2021-01-28')
select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from ods_favor_info
where dt='2021-01-28';
3)查询加载结果
hive (gmall)> select * from dwd_fact_favor_info where dt='2021-01-28' limit 2;
4.4.12 优惠券领用事实表(累积型快照事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 优惠券领用 | √ | √ | √ | 个数 |
优惠卷的生命周期:领取优惠卷-》用优惠卷下单-》优惠卷参与支付
累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_coupon_use;
create external table dwd_fact_coupon_use(
`id` string COMMENT '编号',
`coupon_id` string COMMENT '优惠券ID',
`user_id` string COMMENT 'userid',
`order_id` string COMMENT '订单id',
`coupon_status` string COMMENT '优惠券状态',
`get_time` string COMMENT '领取时间',
`using_time` string COMMENT '使用时间(下单)',
`used_time` string COMMENT '使用时间(支付)'
) COMMENT '优惠券领用事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_coupon_use/'
tblproperties ("parquet.compression"="lzo");
注意:dt是按照优惠卷领用时间get_time做为分区。
分区的目的,为了避免每天修改全表。
2)数据装载
hive (gmall)>
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_coupon_use partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.coupon_id is null,old.coupon_id,new.coupon_id),
if(new.user_id is null,old.user_id,new.user_id),
if(new.order_id is null,old.order_id,new.order_id),
if(new.coupon_status is null,old.coupon_status,new.coupon_status),
if(new.get_time is null,old.get_time,new.get_time),
if(new.using_time is null,old.using_time,new.using_time),
if(new.used_time is null,old.used_time,new.used_time),
date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from dwd_fact_coupon_use
where dt in
(
select
date_format(get_time,'yyyy-MM-dd')
from ods_coupon_use
where dt='2021-01-28'
)
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from ods_coupon_use
where dt='2021-01-28'
)new
on old.id=new.id;
3)查询加载结果
hive (gmall)> select * from dwd_fact_coupon_use where dt='2021-01-28' limit 2;
4.4.13 系统函数(concat、concat_ws、collect_set、STR_TO_MAP)
1)concat函数
concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
hive> select concat('a','b');
ab
hive> select concat('a','b',null);
NULL
2)concat_ws函数
concat_ws函数在连接字符串的时候,只要有一个字符串不是NULL,就不会返回NULL。concat_ws函数需要指定分隔符。
hive> select concat_ws('-','a','b');
a-b
hive> select concat_ws('-','a','b',null);
a-b
hive> select concat_ws('','a','b',null);
ab
3)collect_set函数
(1)创建原数据表
hive (gmall)>
drop table if exists stud;
create table stud (name string, area string, course string, score int);
(2)向原数据表中插入数据
hive (gmall)>
insert into table stud values('zhang3','bj','math',88);
insert into table stud values('li4','bj','math',99);
insert into table stud values('wang5','sh','chinese',92);
insert into table stud values('zhao6','sh','chinese',54);
insert into table stud values('tian7','bj','chinese',91);
(3)查询表中数据
hive (gmall)> select * from stud;
stud.name stud.area stud.course stud.score
zhang3 bj math 88
li4 bj math 99
wang5 sh chinese 92
zhao6 sh chinese 54
tian7 bj chinese 91
(4)把同一分组的不同行的数据聚合成一个集合
hive (gmall)> select course, collect_set(area), avg(score) from stud group by course;
chinese ["sh","bj"] 79.0
math ["bj"] 93.5
(5)用下标可以取某一个
hive (gmall)> select course, collect_set(area)[0], avg(score) from stud group by course;
chinese sh 79.0
math bj 93.5
3)STR_TO_MAP函数
(1)语法描述
STR_TO_MAP(VARCHAR text, VARCHAR listDelimiter, VARCHAR keyValueDelimiter)
(2)功能描述
使用listDelimiter将text分隔成K-V对,然后使用keyValueDelimiter分隔每个K-V对,组装成MAP返回。默认listDelimiter为( ,),keyValueDelimiter为(=)。
(3)案例
str_to_map('1001=2021-01-28,1002=2021-01-28', ',' , '=')
输出
{“1001”:“2021-01-28”,“1002”:“2021-01-28”}
4.4.14 订单事实表(累积型快照事实表)
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | √ | 件数/金额 |
订单生命周期:创建时间=》支付时间=》取消时间=》完成时间=》退款时间=》退款完成时间。
由于ODS层订单表只有创建时间和操作时间两个状态,不能表达所有时间含义,所以需要关联订单状态表。订单事实表里面增加了活动id,所以需要关联活动订单表。
1)建表语句
hive (gmall)>
drop table if exists dwd_fact_order_info;
create external table dwd_fact_order_info (
`id` string COMMENT '订单编号',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间(未支付状态)',
`payment_time` string COMMENT '支付时间(已支付状态)',
`cancel_time` string COMMENT '取消时间(已取消状态)',
`finish_time` string COMMENT '完成时间(已完成状态)',
`refund_time` string COMMENT '退款时间(退款中状态)',
`refund_finish_time` string COMMENT '退款完成时间(退款完成状态)',
`province_id` string COMMENT '省份ID',
`activity_id` string COMMENT '活动ID',
`original_total_amount` decimal(16,2) COMMENT '原价金额',
`benefit_reduce_amount` decimal(16,2) COMMENT '优惠金额',
`feight_fee` decimal(16,2) COMMENT '运费',
`final_total_amount` decimal(16,2) COMMENT '订单金额'
) COMMENT '订单事实表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_fact_order_info/'
tblproperties ("parquet.compression"="lzo");
2)数据装载

3)常用函数
hive (gmall)> select order_id, concat(order_status,'=', operate_time) from ods_order_status_log where dt='2021-01-28';
3210 1001=2021-01-28 00:00:00.0
3211 1001=2021-01-28 00:00:00.0
3212 1001=2021-01-28 00:00:00.0
3210 1002=2021-01-28 00:00:00.0
3211 1002=2021-01-28 00:00:00.0
3212 1002=2021-01-28 00:00:00.0
3210 1005=2021-01-28 00:00:00.0
3211 1004=2021-01-28 00:00:00.0
3212 1004=2021-01-28 00:00:00.0
hive (gmall)> select order_id, collect_set(concat(order_status,'=',operate_time)) from ods_order_status_log where dt='2021-01-28' group by order_id;
3210 ["1001=2021-01-28 00:00:00.0","1002=2021-01-28 00:00:00.0","1005=2021-01-28 00:00:00.0"]
3211 ["1001=2021-01-28 00:00:00.0","1002=2021-01-28 00:00:00.0","1004=2021-01-28 00:00:00.0"]
3212 ["1001=2021-01-28 00:00:00.0","1002=2021-01-28 00:00:00.0","1004=2021-01-28 00:00:00.0"]
hive (gmall)>
select order_id, concat_ws(',', collect_set(concat(order_status,'=',operate_time))) from ods_order_status_log where dt='2021-01-28' group by order_id;
3210 1001=2021-01-28 00:00:00.0,1002=2021-01-28 00:00:00.0,1005=2021-01-28 00:00:00.0
3211 1001=2021-01-28 00:00:00.0,1002=2021-01-28 00:00:00.0,1004=2021-01-28 00:00:00.0
3212 1001=2021-01-28 00:00:00.0,1002=2021-01-28 00:00:00.0,1004=2021-01-28 00:00:00.0
hive (gmall)>
select order_id, str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))), ',' , '=') from ods_order_status_log where dt='2021-01-28' group by order_id;
3210 {
"1001":"2021-01-28 00:00:00.0","1002":"2021-01-28 00:00:00.0","1005":"2021-01-28 00:00:00.0"}
3211 {
"1001":"2021-01-28 00:00:00.0","1002":"2021-01-28 00:00:00.0","1004":"2021-01-28 00:00:00.0"}
3212 {
"1001":"2021-01-28 00:00:00.0","1002":"2021-01-28 00:00:00.0","1004":"2021-01-28 00:00:00.0"}
4)数据装载
hive (gmall)>
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_fact_order_info partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.order_status is null,old.order_status,new.order_status),
if(new.user_id is null,old.user_id,new.user_id),
if(new.out_trade_no is null,old.out_trade_no,new.out_trade_no),
if(new.tms['1001'] is null,old.create_time,new.tms['1001']),--1001对应未支付状态
if(new.tms['1002'] is null,old.payment_time,new.tms['1002']),
if(new.tms['1003'] is null,old.cancel_time,new.tms['1003']),
if(new.tms['1004'] is null,old.finish_time,new.tms['1004']),
if(new.tms['1005'] is null,old.refund_time,new.tms['1005']),
if(new.tms['1006'] is null,old.refund_finish_time,new.tms['1006']),
if(new.province_id is null,old.province_id,new.province_id),
if(new.activity_id is null,old.activity_id,new.activity_id),
if(new.original_total_amount is null,old.original_total_amount,new.original_total_amount),
if(new.benefit_reduce_amount is null,old.benefit_reduce_amount,new.benefit_reduce_amount),
if(new.feight_fee is null,old.feight_fee,new.feight_fee),
if(new.final_total_amount is null,old.final_total_amount,new.final_total_amount),
date_format(if(new.tms['1001'] is null,old.create_time,new.tms['1001']),'yyyy-MM-dd')
from
(
select
id,
order_status,
user_id,
out_trade_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
province_id,
activity_id,
original_total_amount,
benefit_reduce_amount,
feight_fee,
final_total_amount
from dwd_fact_order_info
where dt
in
(
select
date_format(create_time,'yyyy-MM-dd')
from ods_order_info
where dt='2021-01-28'
)
)old
full outer join
(
select
info.id,
info.order_status,
info.user_id,
info.out_trade_no,
info.province_id,
act.activity_id,
log.tms,
info.original_total_amount,
info.benefit_reduce_amount,
info.feight_fee,
info.final_total_amount
from
(
select
order_id,
str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=') tms
from ods_order_status_log
where dt='2021-01-28'
group by order_id
)log
join
(
select * from ods_order_info where dt='2021-01-28'
)info
on log.order_id=info.id
left join
(
select * from ods_activity_order where dt='2021-01-28'
)act
on log.order_id=act.order_id
)new
on old.id=new.id;
5)查询加载结果
hive (gmall)> select * from dwd_fact_order_info where dt='2021-01-28' limit 2;
4.4.15 用户维度表(拉链表)
用户表中的数据每日既有可能新增,也有可能修改,但修改频率并不高,属于缓慢变化维度,此处采用拉链表存储用户维度数据。
1)什么是拉链表

2)为什么要做拉链表

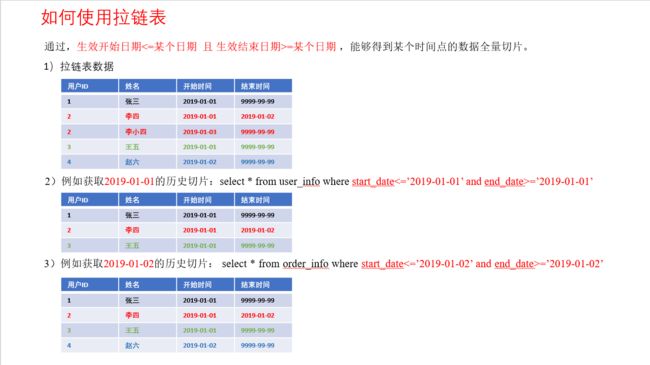
3)拉链表形成过程

4)拉链表制作过程图

5)拉链表制作过程
步骤0:初始化拉链表(首次独立执行)
(1)建立拉链表
hive (gmall)>
drop table if exists dwd_dim_user_info_his;
create external table dwd_dim_user_info_his(
`id` string COMMENT '用户id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日',
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '用户拉链表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_user_info_his/'
tblproperties ("parquet.compression"="lzo");
(2)初始化拉链表
Start_date 为当天日期
End_date 为9999-99-99
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_user_info_his
select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time,
'2021-01-28',
'9999-99-99'
from ods_user_info oi
where oi.dt='2021-01-28';
步骤1:制作当日变动数据(包括新增,修改)每日执行
2021-01-29
(1)如何获得每日变动表
a.最好表内有创建时间和变动时间(Lucky!)
b.如果没有,可以利用第三方工具监控比如canal,监控MySQL的实时变化进行记录(麻烦)。
c.逐行对比前后两天的数据,检查md5(concat(全部有可能变化的字段))是否相同(low)
d.要求业务数据库提供变动流水(人品,颜值)
(2)因为ods_user_info本身导入过来就是新增变动明细的表,所以不用处理
a)数据库中新增2021-01-29一天的数据
b)通过Sqoop把2021-01-29日所有数据导入
mysql_to_hdfs.sh all 2021-01-29
c)ods层数据导入
hdfs_to_ods_db.sh all 2021-01-29
步骤2:先合并变动信息,再追加新增信息,插入到临时表中
1)建立临时表
hive (gmall)>
drop table if exists dwd_dim_user_info_his_tmp;
create external table dwd_dim_user_info_his_tmp(
`id` string COMMENT '用户id',
`name` string COMMENT '姓名',
`birthday` string COMMENT '生日',
`gender` string COMMENT '性别',
`email` string COMMENT '邮箱',
`user_level` string COMMENT '用户等级',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链临时表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_dim_user_info_his_tmp/'
tblproperties ("parquet.compression"="lzo");
2)导入数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t4rXTt9f-1612417842028)(http://qn9nvz7jf.hn-bkt.clouddn.com/image-20210204133935149.png)]
hive (gmall)>
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table dwd_dim_user_info_his_tmp
select * from
(
select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time,
'2021-01-28' start_date,
'9999-99-99' end_date
from ods_user_info where dt='2021-01-29'
union all
select
uh.id,
uh.name,
uh.birthday,
uh.gender,
uh.email,
uh.user_level,
uh.create_time,
uh.operate_time,
uh.start_date,
if(ui.id is not null and uh.end_date='9999-99-99', date_add(ui.dt,-1), uh.end_date) end_date
from dwd_dim_user_info_his uh left join
(
select
*
from ods_user_info
where dt='2021-01-29'
) ui on uh.id=ui.id
)his
order by his.id, start_date;
步骤3:把临时表覆盖给拉链表
1)导入数据
hive (gmall)>
insert overwrite table dwd_dim_user_info_his
select * from dwd_dim_user_info_his_tmp;
2)查询导入数据
hive (gmall)>
select id, start_date, end_date from dwd_dim_user_info_his limit 2;
4.4.16 DWD层业务数据导入脚本
1.编写脚本
1)在/home/atguigu/bin目录下创建脚本ods_to_dwd_db.sh
[atguigu@hadoop105 bin]$ vim ods_to_dwd_db.sh
在脚本中填写如下内容
#!/bin/bash
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
sql1="
set mapreduce.job.queuename=hive;
set hive.exec.dynamic.partition.mode=nonstrict;
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_dim_sku_info partition(dt='$do_date')
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
ob.tm_name,
sku.category3_id,
c2.id category2_id,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
spu.spu_name,
sku.create_time
from
(
select * from ${APP}.ods_sku_info where dt='$do_date'
)sku
join
(
select * from ${APP}.ods_base_trademark where dt='$do_date'
)ob on sku.tm_id=ob.tm_id
join
(
select * from ${APP}.ods_spu_info where dt='$do_date'
)spu on spu.id = sku.spu_id
join
(
select * from ${APP}.ods_base_category3 where dt='$do_date'
)c3 on sku.category3_id=c3.id
join
(
select * from ${APP}.ods_base_category2 where dt='$do_date'
)c2 on c3.category2_id=c2.id
join
(
select * from ${APP}.ods_base_category1 where dt='$do_date'
)c1 on c2.category1_id=c1.id;
insert overwrite table ${APP}.dwd_dim_coupon_info partition(dt='$do_date')
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from ${APP}.ods_coupon_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_dim_activity_info partition(dt='$do_date')
select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from ${APP}.ods_activity_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_fact_order_detail partition(dt='$do_date')
select
id,
order_id,
user_id,
sku_id,
sku_num,
order_price,
sku_num,
create_time,
province_id,
source_type,
source_id,
original_amount_d,
if(rn=1,final_total_amount-(sum_div_final_amount-final_amount_d),final_amount_d),
if(rn=1,feight_fee-(sum_div_feight_fee-feight_fee_d),feight_fee_d),
if(rn=1,benefit_reduce_amount-(sum_div_benefit_reduce_amount-benefit_reduce_amount_d),benefit_reduce_amount_d)
from
(
select
od.id,
od.order_id,
od.user_id,
od.sku_id,
od.sku_name,
od.order_price,
od.sku_num,
od.create_time,
oi.province_id,
od.source_type,
od.source_id,
round(od.order_price*od.sku_num,2) original_amount_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2) final_amount_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2) feight_fee_d,
round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2) benefit_reduce_amount_d,
row_number() over(partition by od.order_id order by od.id desc) rn,
oi.final_total_amount,
oi.feight_fee,
oi.benefit_reduce_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.final_total_amount,2)) over(partition by od.order_id) sum_div_final_amount,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.feight_fee,2)) over(partition by od.order_id) sum_div_feight_fee,
sum(round(od.order_price*od.sku_num/oi.original_total_amount*oi.benefit_reduce_amount,2)) over(partition by od.order_id) sum_div_benefit_reduce_amount
from
(
select * from ${APP}.ods_order_detail where dt='$do_date'
) od
join
(
select * from ${APP}.ods_order_info where dt='$do_date'
) oi
on od.order_id=oi.id
)t1;
insert overwrite table ${APP}.dwd_fact_payment_info partition(dt='$do_date')
select
pi.id,
pi.out_trade_no,
pi.order_id,
pi.user_id,
pi.alipay_trade_no,
pi.total_amount,
pi.subject,
pi.payment_type,
pi.payment_time,
oi.province_id
from
(
select * from ${APP}.ods_payment_info where dt='$do_date'
)pi
join
(
select id, province_id from ${APP}.ods_order_info where dt='$do_date'
)oi
on pi.order_id = oi.id;
insert overwrite table ${APP}.dwd_fact_order_refund_info partition(dt='$do_date')
select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from ${APP}.ods_order_refund_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_fact_comment_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from ${APP}.ods_comment_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_fact_cart_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from ${APP}.ods_cart_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_fact_favor_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from ${APP}.ods_favor_info
where dt='$do_date';
insert overwrite table ${APP}.dwd_fact_coupon_use partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.coupon_id is null,old.coupon_id,new.coupon_id),
if(new.user_id is null,old.user_id,new.user_id),
if(new.order_id is null,old.order_id,new.order_id),
if(new.coupon_status is null,old.coupon_status,new.coupon_status),
if(new.get_time is null,old.get_time,new.get_time),
if(new.using_time is null,old.using_time,new.using_time),
if(new.used_time is null,old.used_time,new.used_time),
date_format(if(new.get_time is null,old.get_time,new.get_time),'yyyy-MM-dd')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from ${APP}.dwd_fact_coupon_use
where dt in
(
select
date_format(get_time,'yyyy-MM-dd')
from ${APP}.ods_coupon_use
where dt='$do_date'
)
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from ${APP}.ods_coupon_use
where dt='$do_date'
)new
on old.id=new.id;
insert overwrite table ${APP}.dwd_fact_order_info partition(dt)
select
if(new.id is null,old.id,new.id),
if(new.order_status is null,old.order_status,new.order_status),
if(new.user_id is null,old.user_id,new.user_id),
if(new.out_trade_no is null,old.out_trade_no,new.out_trade_no),
if(new.tms['1001'] is null,old.create_time,new.tms['1001']),--1001对应未支付状态
if(new.tms['1002'] is null,old.payment_time,new.tms['1002']),
if(new.tms['1003'] is null,old.cancel_time,new.tms['1003']),
if(new.tms['1004'] is null,old.finish_time,new.tms['1004']),
if(new.tms['1005'] is null,old.refund_time,new.tms['1005']),
if(new.tms['1006'] is null,old.refund_finish_time,new.tms['1006']),
if(new.province_id is null,old.province_id,new.province_id),
if(new.activity_id is null,old.activity_id,new.activity_id),
if(new.original_total_amount is null,old.original_total_amount,new.original_total_amount),
if(new.benefit_reduce_amount is null,old.benefit_reduce_amount,new.benefit_reduce_amount),
if(new.feight_fee is null,old.feight_fee,new.feight_fee),
if(new.final_total_amount is null,old.final_total_amount,new.final_total_amount),
date_format(if(new.tms['1001'] is null,old.create_time,new.tms['1001']),'yyyy-MM-dd')
from
(
select
id,
order_status,
user_id,
out_trade_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
province_id,
activity_id,
original_total_amount,
benefit_reduce_amount,
feight_fee,
final_total_amount
from ${APP}.dwd_fact_order_info
where dt
in
(
select
date_format(create_time,'yyyy-MM-dd')
from ${APP}.ods_order_info
where dt='$do_date'
)
)old
full outer join
(
select
info.id,
info.order_status,
info.user_id,
info.out_trade_no,
info.province_id,
act.activity_id,
log.tms,
info.original_total_amount,
info.benefit_reduce_amount,
info.feight_fee,
info.final_total_amount
from
(
select
order_id,
str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=') tms
from ${APP}.ods_order_status_log
where dt='$do_date'
group by order_id
)log
join
(
select * from ${APP}.ods_order_info where dt='$do_date'
)info
on log.order_id=info.id
left join
(
select * from ${APP}.ods_activity_order where dt='$do_date'
)act
on log.order_id=act.order_id
)new
on old.id=new.id;
"
sql2="
insert overwrite table ${APP}.dwd_dim_base_province
select
bp.id,
bp.name,
bp.area_code,
bp.iso_code,
bp.region_id,
br.region_name
from ${APP}.ods_base_province bp
join ${APP}.ods_base_region br
on bp.region_id=br.id;
"
sql3="
insert overwrite table ${APP}.dwd_dim_user_info_his_tmp
select * from
(
select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time,
'$do_date' start_date,
'9999-99-99' end_date
from ${APP}.ods_user_info where dt='$do_date'
union all
select
uh.id,
uh.name,
uh.birthday,
uh.gender,
uh.email,
uh.user_level,
uh.create_time,
uh.operate_time,
uh.start_date,
if(ui.id is not null and uh.end_date='9999-99-99', date_add(ui.dt,-1), uh.end_date) end_date
from ${APP}.dwd_dim_user_info_his uh left join
(
select
*
from ${APP}.ods_user_info
where dt='$do_date'
) ui on uh.id=ui.id
)his
order by his.id, start_date;
insert overwrite table ${APP}.dwd_dim_user_info_his
select * from ${APP}.dwd_dim_user_info_his_tmp;
"
case $1 in
"first"){
$hive -e "$sql1$sql2"
};;
"all"){
$hive -e "$sql1$sql3"
};;
esac
2)增加脚本执行权限
[atguigu@hadoop105 bin]$ chmod 777 ods_to_dwd_db.sh
2.脚本使用说明
1)初次导入
(1)时间维度表
参照4.4.5节数据装载
(2)用户维度表
参照4.4.15节拉链表初始化
(3)其余表
初次导入时,脚本的第一个参数应为first,线上环境不传第二个参数,自动获取前一天日期。
[atguigu@hadoop105 bin]$ ods_to_dwd_db.sh first 2021-01-28
2)每日定时导入
每日定时导入,脚本的第一个参数应为all,线上环境不传第二个参数,自动获取前一天日期。
[atguigu@hadoop105 bin]$ ods_to_dwd_db.sh all 2021-01-28
下一篇:电商数仓项目-下篇