注:本文的java环境为:max os x 10 ,jdk8
1、前言
说到ArrayList,就不得不说Array。光看名字,还以为这2个是同一个东西。其实不然。
Array:指容量为固定的数组,常见的初始化方法如下:
String[] names = {"david","tom","kate"};
在声明的时候直接声明了内部元素,这样jvm就可以快速的分配给指定大小的空间。同时,看Array源码可知,Array的方法基本上都是native方法,其底层实现均为c/c++实现。
ArrayList:动态数组,允许新增、删除等操作,常见的初始化方法:
List nameList = new ArrayList<>();
看完概念,我们开始正题,开始源码的解读。
2、与其他容器对比
与hashmap不同,ArrayList为集合的一种,来源自数据结构中的数组概念,与hashmap源自数据结构中的图概念不同。
我们先看ArrayList的uml图。
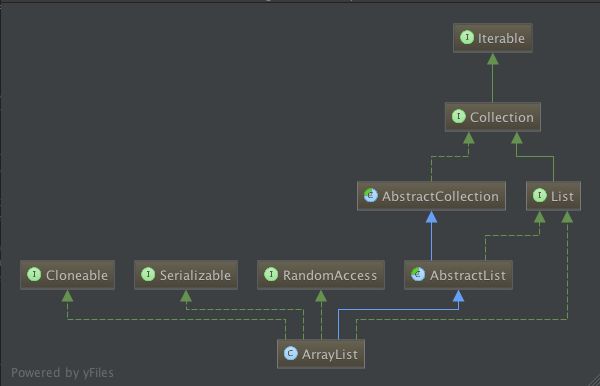
可以看出,ArrayList不仅实现了Cloneable、Serializable接口,还 实现了RandomAccess接口、List接口。
3、简述RandomAccess接口
在后续代码中,还可以看到RandomAccess这个接口。若实现了该接口,则表明该类可以进行下标式访问,类似于这样:
List nameList = new ArrayList<>();
String david = names[0];
(这个会提示越界了)
4、成员变量分析
ArrayList的成员变量分析如下:
//默认容量
private static final int DEFAULT_CAPACITY = 10;
//空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//也是空数组,作用是在新增元素的时候用
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//数组
transient Object[] elementData;
//数组大小
private int size;
//数组最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//继承自AbstractList,用于fail-fast机制
protected transient int modCount = 0;
从成员变量来看,数组用transient修饰符修饰,作用应该是类似于hashmap的Node[]。
5、核心方法分析
5.1 容量扩增
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//新空间分配直接扩大50%
int newCapacity = oldCapacity + (oldCapacity >> 1);
//得出较大的值
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//元素复制
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
//这一点比较特殊,见下面分析
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
关于hugeCapacity的判断小于0则为溢出,由于在jvm内部是以反码存储的数据,首位为符号位,当容量扩增后,若溢出,首位则变为1,此时变为负数,则可以快速判断出是否溢出。
5.2 trimToSize 压缩空间
去掉多余的空对象,精简存储空间
public void trimToSize() {
modCount++;
//代码也写的很简洁,经常使用三元表达式
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
由上面的扩增容量可知,如果原始容量是100,在扩增容量后,那么分配的容量为150.但是实际上可能只存110个对象实例,那么此时调用这个方法,就可以节约一定的存储空间。不过若数组较大,那么操作可能会耗费一点时间。
5.3 fail-fast机制
这个其实在hashmap中也采取了类似机制,就是额外有一个成员变量,用于快速判断该实例是否有变化,若在进行迭代的时候有变更,那么就抛出一个并发修改异常(ConcurrentModificationException)。
5.4 indexOf 求 下标
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
这段代码略过,用的比较多,没什么亮点。
5.5 新增一个元素
既然是数组,那么就有两种 新增的方式:指定特定的位置、向后插入。
向指定位置写入元素:
public void add(int index, E element) {
//下标检查,是否越界了
rangeCheckForAdd(index);
//扩增容量,同时改变modcount
ensureCapacityInternal(size + 1); // Increments modCount!!
//index后面的元素后移
System.arraycopy(elementData, index, elementData, index + 1, size - index);
//指定位置放置元素
elementData[index] = element;
//元素数量大小自增
size++;
}
向后插入一个元素:
public boolean add(E e) {
//扩大容量,修改modcount
ensureCapacityInternal(size + 1); // Increments modCount!!
//注意
//数组是从0开始的存元素的,而数组个数是从1开始计数的
//这个地方是往第size个位置上存元素
//再将元素个数加1
elementData[size++] = e;
return true;
}
从以上源码可以看出,向后插入一个元素不用进行元素的复制,自然效率要大于指定位置插入一个元素。
5.6 移除一个元素
同新增,也是分2种。
移除指定位置的元素:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//元素迁移
System.arraycopy(elementData, index+1, elementData, index, numMoved);
//这个与新增类似,但是是左自减运算,自己体会吧
//特地表明将该位置的置空,让gc回收空间
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
删除指定元素:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//类似指定位置删除元素
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
}
看到这个指定删除某个元素的代码,那么有人就会有疑问了,如果我里面有多个一样的元素,那这不是删不完吗?这个时候你得使用removeAll:
public boolean removeAll(Collection c) {
//参数校验,仅判断c != null,感觉不太严谨
Objects.requireNonNull(c);
return batchRemove(c, false);
}
private boolean batchRemove(Collection c, boolean complement) {
//常量数组,不允许再赋值,但是数组内部的元素允许自由移动、被重新赋值
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
//不包含该元素,则存到新数组,其实是位置前移
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
//上面if内类型不匹配抛异常时,r与size不等
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
//由于将已包含的元素前移了,那么不包含的元素都在后面,直接将后面的元素删掉
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
5.7 序列化
这个源码类似于hashmap,就不重复分析了。
5.8 其他
set、get方法比较简单, 就不分析了。
需要注意的是,arraylist继承的AbstractList覆写了hashcode和equals方法。
6 小结
总的来说,arraylist的源码比较简单,可供分析的内容不多。