上周实现了离散变量的决策树的构建(ID3算法),它的做法是每次选取当前最佳的特征来分割数据,并按照该特征所有的可能值来切分。也就是说,如果一个特征有4种取值,那么数据被切分成4份,一旦按某特征切分后,便固定死了,该特征在之后的算法执行过程中将不会再起作用,显然,这种切分方式过于迅速。而此外,ID3算法不能直接处理连续型特征。
再补充一下用ID3算法生成决策树的图例。
我们的例子是李航的《统计学习方法》第五章的表5.1,根据该表生成决策树,在已知年龄、有工作、有自己房子、信贷情况的情况下判断是否给贷款.

用ID3算法生成的决策树如下(画图的程序实现在最后,参照的是Peter Harrington的《机器学习实战》):
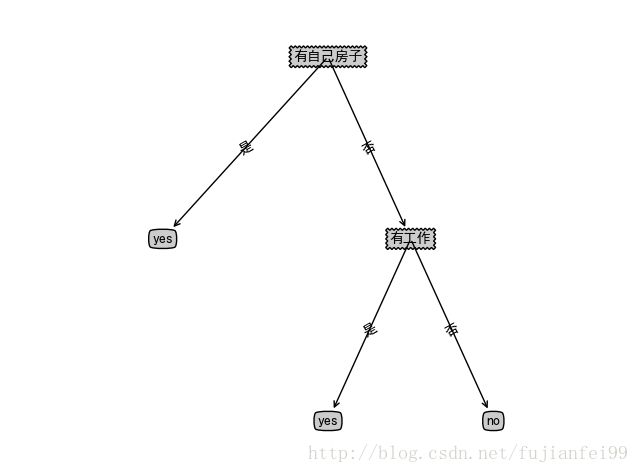
效果很明显,从杂乱无章的15条记录中提取出这么精辟的决策树,有了这棵决策树便很轻易的可以判断该不该给某人贷款,如果他有房子,就给贷,如果没有,但他有工作,也给贷,如果都没有,就不给贷。比表5.1精简有效多了。
再来看一个例子,周志华的《机器学习》的判断是否为好瓜的数据:

判断一个西瓜可以从色泽,根蒂,敲声,纹理,脐部,触感6个特征去判断,每个特征都有2-3个值,用ID3算法生成的决策树如下:

这里一个节点可以有2个以上的分支,取决于每个特征的所有可能值。这样也使一团杂乱无章的数据有了个很清晰的决策树。
**总结:
ID3算法可以使离散的问题清晰简单化,但也有两点局限:
- 切分过于迅速
- 不能直接处理连续型特征**
如遇到连续变化的特征或者特征可能值很多的情况下,算法得出的效果并不理想而且没有多大用处。大多数情况下,生成决策树的目的是用来分类的。
这周,生成决策树的算法是CART算法,不像ID3算法,它是一种二元切分法,具体处理方法:如果特征值大于给定值就走左子树,否则就走右子树。解决了ID3算法的局限,但同时,如果用来分类,生成的决策树容易太贪心,满足了大部分训练数据,出现过拟合。为提高泛化能力,需对其
进行剪枝,把某些节点塌陷成一类。
在本文,构建CART的实现算法有两种(程序在最后)
一种是Peter Harrington的《机器学习实战》的对连续数据的构建算法,核心方法(选取最优特征)的伪代码如下:
遍历每个特征:
遍历每个特征值:
将数据切分成两份
计算切分的误差
如果当前误差小于当前最小误差:
更新当前最小误差
更新当前最优特征和最优切分点
返回最优切分特征和最优切分点
一种是李航的《统计学习方法》的用基尼指数构建的算法,程序是自己实现的,目前只能针对离散性数据,核心方法的伪代码如下:
遍历每个特征:
遍历每个特征值:
将数据切分成两份
计算切分的基尼指数
如果基尼指数小于当前基尼指数:
更新当前基尼指数
更新当前最优特征和最优切分点
返回最优切分特征和最优切分点
只是把误差计算方式变成了基尼指数,其他基本类似。
对前面两例用CART算法生成的决策树如下:


图5和图2是一样的,因为用来切分的特征都只有两类
但图6和图4便不一样。
再来对连续的数据构建决策树,数据来自于Peter Harrington的《机器学习实战》的第九章ex0.txt

肉眼可以分辨,整段数据可分为5段,用CART算法生成的结果如下:
{'spInd': 0, 'spVal': 0.39434999999999998, 'left': {'spInd': 0, 'spVal': 0.58200200000000002, 'left': {'spInd': 0, 'spVal': 0.79758300000000004, 'left': 3.9871631999999999, 'right': 2.9836209534883724}, 'right': 1.980035071428571}, 'right': {'spInd': 0, 'spVal': 0.19783400000000001, 'left': 1.0289583666666666, 'right': -0.023838155555555553}}
(实在不想画图了,就用dict表示吧,spInd表示当前分割特征,spVal表示当前分割值,left表示坐子节点,right表示右子节点)
从dict中也明显可以看到,它将数据分成5段,但这个前提是ops=(1,4)选的好,对树进行预剪枝了。
如果ops=(0.1,0.4)会发生什么呢?
{'spInd': 0, 'spVal': 0.39434999999999998, 'left': {'spInd': 0, 'spVal': 0.58200200000000002, 'left': {'spInd': 0, 'spVal': 0.79758300000000004, 'left': {'spInd': 0, 'spVal': 0.81900600000000001, 'left': {'spInd': 0, 'spVal': 0.83269300000000002, 'left': 3.9814298333333347, 'right': {'spInd': 0, 'spVal': 0.81913599999999998, 'left': 4.5692899999999996, 'right': 4.048082}}, 'right': 3.7688410000000001}, 'right': {'spInd': 0, 'spVal': 0.62039299999999997, 'left': {'spInd': 0, 'spVal': 0.62261599999999995, 'left': 2.9787170277777779, 'right': 2.6702779999999997}, 'right': {'spInd': 0, 'spVal': 0.61605100000000002, 'left': 3.5225040000000001, 'right': 3.0497069999999997}}}, 'right': {'spInd': 0, 'spVal': 0.48669800000000002, 'left': {'spInd': 0, 'spVal': 0.53324099999999997, 'left': {'spInd': 0, 'spVal': 0.55900899999999998, 'left': 2.0720909999999999, 'right': 1.8145387500000001}, 'right': 2.0843065555555551}, 'right': 1.8810897500000001}}, 'right': {'spInd': 0, 'spVal': 0.19783400000000001, 'left': {'spInd': 0, 'spVal': 0.21054200000000001, 'left': {'spInd': 0, 'spVal': 0.37526999999999999, 'left': 1.2040690000000001, 'right': {'spInd': 0, 'spVal': 0.316465, 'left': 0.86561450000000006, 'right': {'spInd': 0, 'spVal': 0.23417499999999999, 'left': 1.1113766363636364, 'right': 0.90613224999999997}}}, 'right': 1.3753635000000002}, 'right': {'spInd': 0, 'spVal': 0.14865400000000001, 'left': 0.071894545454545447, 'right': {'spInd': 0, 'spVal': 0.14314299999999999, 'left': -0.27792149999999999, 'right': -0.040866062499999994}}}}
显然,过拟合了。生成了很多不必要的节点。在实际应用中,根本不能控制数据值得大小,所以ops也很难选好,而ops的选择对结果的影响很大。所以仅仅预剪枝是远远不够的。
于是需要后剪枝。简单来说,就是选择ops,使得构建出的树足够大,接下来从上而下找到叶节点,用测试集的数据来判断这些叶节点是否能降低测试误差,如果能,就合并,伪代码如下:
基于已有的树切分测试数据:
如果存在任一子集是一棵树,则在该子集递归剪枝过程
计算当前两个叶节点合并后的误差
计算合并前的误差
如果合并后的误差小于合并前的误差:
将两个叶节点合并
对上述决策树进行剪枝,由于没有测试数据,便拿前150当作训练数据,后50当作测试数据,图如下:

同样,ops=(0.1,0.4),剪枝后的树为:
{'spInd': 0, 'spVal': 0.39434999999999998, 'left': {'spInd': 0, 'spVal': 0.58028299999999999, 'left': {'spInd': 0, 'spVal': 0.79758300000000004, 'left': 3.9739993000000005, 'right': 3.0065657575757574}, 'right': 1.9667640539772728}, 'right': {'spInd': 0, 'spVal': 0.19783400000000001, 'left': 1.0753531944444445, 'right': -0.028014558823529413}}
由那么复杂的树剪枝剪成只有五个类别。效果不错
实现代码如下:
treePlotter.py
'''
Created on 2017年7月30日
@author: fujianfei
'''
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#解约matplotlib画图,中文乱码问题
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstSides = list(myTree.keys())
firstStr = firstSides[0]#找到输入的第一个元素
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstSides = list(myTree.keys())
firstStr = firstSides[0]#找到输入的第一个元素
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
#depth = getTreeDepth(myTree)
firstSides = list(myTree.keys())
firstStr = firstSides[0]#找到输入的第一个元素
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
#def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show()
# def retrieveTree(i):
# listOfTrees =[{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
# {'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
# ]
# return listOfTrees[i]
#createPlot(thisTree)
CARTTree.py
'''
Created on 2017年8月2日
@author: Administrator
'''
import operator
class TreeNode(object):
'''
.树节点的定义:
'''
def __init__(self, feat=None, val=None, left=None, right=None):
'''
featureToSpliton:该节点对应的特征,比如'年龄'
ValToSplit:由特征分类后的值,比如'青年','中年','老年'
leftBranch:左分支
rightBranch:右分支
'''
self.feat = feat
self.val = val
self.left = left
self.right = right
def calcGini(dataSet):
'''
.计算训练数据的预测误差,在这里用基尼指数
'''
num = len(dataSet)#数据集的行数,即有几个样本点
labelCounts = {}#提取总共有多少标签并计数
for featVec in dataSet:#遍历数据集
label = featVec[-1]#提取标签
if label not in labelCounts.keys():#如果标签不再labelCount里
labelCounts[label] = 0#那么在字典labelCount里建一对字典 key=label,value=0
labelCounts[label] += 1#对key=label的字典 的 value加1,计数
gini = 0.0 #定义1-基尼指数
for key in labelCounts.keys():
prop = float(labelCounts[key])/num #计算每个类别的概率
gini += prop ** 2 #每个类别概率的平方相加,赋值给gini
return 1-gini#1-概率平方之和,即为基尼指数
def splitDataSet(dataSet, featAndVal):
'''
.分割数据集,根据特征feat(比如年龄)和特征对应的某个值val(比如青年)
.将数据dataSet分割为两部分:青年的数据集sub_dateSet1,非青年的数据集sub_dateSet2,并返回两个子数据集
.返回的子数据集可用来计算条件基尼指数,Gini(D,A)
'''
sub_dateSet1 = []
sub_dateSet2 = []
for featVec in dataSet:
if featVec[featAndVal[0]] == featAndVal[1]:
reduceDataSet = featVec[:featAndVal[0]]
reduceDataSet.extend(featVec[featAndVal[0]+1:])
sub_dateSet1.append(reduceDataSet)
else:
reduceDataSet = featVec[:featAndVal[0]]
reduceDataSet.extend(featVec[featAndVal[0]+1:])
sub_dateSet2.append(reduceDataSet)
return sub_dateSet1,sub_dateSet2
def chooseBestFeatAndCuttingpoint(dataSet):
'''
.遍历数据集找到最小的基尼指数,选择最优特征与最优切分点
'''
bestFeatAndCuttingpoint = [-1,-1]#定义优特征和最优切分点
min_gini = float("inf")#定义最小基尼指数
numFeat = len(dataSet[0]) - 1#特征数
numData = len(dataSet)#样本数
for i in range(numFeat):#遍历所有特征
featList = [example[i] for example in dataSet]
uniqueFeat = set(featList)
for value in uniqueFeat:#遍历所有可能的切分点
#把样本集合D根据特征A是否取某一可能值a被分割成D1和D2两部分
subdata1,subdata2 = splitDataSet(dataSet, [i,value])
#计算在特征A,切分点a的条件下,集合D的基尼指数
tmp_gini = (float(len(subdata1))/numData) * calcGini(subdata1) + (float(len(subdata2))/numData) * calcGini(subdata2)
if tmp_gini < min_gini:
min_gini = tmp_gini
bestFeatAndCuttingpoint = [i,value]
return bestFeatAndCuttingpoint
def majorityCnt(classList):
'''
.多数投票表决,有时候会遇到数据集已经处理了所有的属性
.但是类标签还不是唯一的,这个时候便用该方法确定该叶子节点的分类
'''
classCount = {}
for vote in classList:
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reserve=True)
return sortedClassCount[0][0]
def creatCART(dataSet, labels):
'''
.用数据字典结构存储树
.后续的CART树剪枝就用这种结构
'''
classList = [example[-1] for example in dataSet]#dataSet的最后一列,类别列
#结束递归的条件:
#1.类别完全相同
if classList.count(classList[0]) == len(classList):
return classList[0]
#2.分类到了最后一个节点,用多数投票决定类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
#选择最优特征和最优切分点
bestFeatAndCuttingpoint = chooseBestFeatAndCuttingpoint(dataSet)
bestFeatLabel = labels[bestFeatAndCuttingpoint[0]]#特征对应的标签
mytree = {bestFeatLabel:{}}#定义树,用字典类型的结构就足以表示决策树全部的信息
del(labels[bestFeatAndCuttingpoint[0]])#将用过的标签删除
sub_dataSet1,sub_dataSet2 = splitDataSet(dataSet, bestFeatAndCuttingpoint)#分割成D1和D2
subLabels = labels[:]#去掉用过后的标签
mytree[bestFeatLabel]['是'] = creatCART(sub_dataSet1, subLabels)#符合val的Branch,即D1
mytree[bestFeatLabel]['否'] = creatCART(sub_dataSet2, subLabels)#不符合val的Branch,即D2
return mytree
class CART(object):
'''
.用特殊类型结构存储树,自己建的TreeNode,树节点形式的结构
.这种结构还不完善,没有去调式
'''
def __init__(self,data=None):
def creatNode(dataSet=None, bestFeatAndCuttingpoint=None):
gini = calcGini(dataSet)
#递归停止条件:样本个数小于预定阈值,或样本集的基尼指数小于预定阈值,或这没有更多特征
if len(dataSet) <=0 or gini <=0.0001 or len(dataSet[0]) <=0:
return None
#选择最优特征和最优切分点
sub_dataSet1,sub_dataSet2 = splitDataSet(dataSet, bestFeatAndCuttingpoint)#分割成D1和D2
return TreeNode(bestFeatAndCuttingpoint[0], bestFeatAndCuttingpoint[1], creatNode(sub_dataSet1,chooseBestFeatAndCuttingpoint(sub_dataSet1)), creatNode(sub_dataSet2,chooseBestFeatAndCuttingpoint(sub_dataSet2)))
self.root = creatNode(data, chooseBestFeatAndCuttingpoint(data))
def preOrder(root):
'''
.树的前序遍历
'''
print(root.feat)
if root.left:
preOrder(root.left)
if root.right:
preOrder(root.right)
regTrees.py
'''
Created on 2017年8月5日
@author: fujianfei
'''
import numpy as np
from os.path import os
import matplotlib.pyplot as plt
def loadDataSet(fileName):
'''
.导入数据
'''
data_path = os.getcwd()+'\\data\\'
dataMat = np.loadtxt(data_path+fileName,delimiter='\t')
return dataMat
def binSplitDataSet(dataSet, feature, value):
'''
.将数据根据特征和值分成两部分,一部分为大于value的数据集mat0,一部分为小于等于Value的数据集mat1
'''
# print(np.nonzero((dataSet[:,feature] > value)))
mat0 = dataSet[np.nonzero((dataSet[:,feature] > value)),:][0]
mat1 = dataSet[np.nonzero((dataSet[:,feature] <= value)),:][0]
return mat0,mat1
def regLeaf(dataSet):
return np.mean(dataSet[:,-1])
def regErr(dataSet):
return np.var(dataSet[:,-1]) * len(dataSet)
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
tolS = ops[0];tolN = ops[1]
if len(set(dataSet[:,-1].tolist())) == 1:
return None, leafType(dataSet)
n = len(dataSet[0])
S = errType(dataSet)
bestS = float('inf'); bestIndex = 0; bestValue = 0
for featIndex in range(n-1):#遍历所有特征
for splitVal in set(dataSet[:,featIndex]):#遍历所有确定特征的值
mat0,mat1 = binSplitDataSet(dataSet, featIndex, splitVal)#将数据分成两部分
if(np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN):continue
newS = errType(mat0) + errType(mat1)#计算分成两部分后的数据的方差之和
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
if(S-bestS) < tolS:
return None, leafType(dataSet)
mat0,mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (np.shape(mat0)[0] < tolN) or (np.shape(mat1)[0] < tolN):
return None, leafType(dataSet)
return bestIndex, bestValue
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
if feat == None: return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
def istree(obj):
return (type(obj).__name__ == 'dict');
def getMean(tree):
'''
.计算树的平均值
'''
if istree(tree['left']) : return getMean(tree['left'])
if istree(tree['right']) : return getMean(tree['right'])
return (tree['left']+tree['right'])/2.0
def prune(tree, testDate):
'''
.剪枝
'''
if len(testDate) == 0 : return getMean(tree)
if istree(tree['left']) or istree(tree['right']):
lSet, rSet = binSplitDataSet(testDate, tree['spInd'], tree['spVal'])
if istree(tree['left']) : tree['left'] = prune(tree['left'], lSet)
if istree(tree['right']) : tree['right'] = prune(tree['right'], rSet)
if (not istree(tree['left'])) and (not istree(tree['right'])):
lSet, rSet = binSplitDataSet(testDate, tree['spInd'], tree['spVal'])
#剪枝前的误差
erroNoMerge = np.sum(np.power(lSet[:,-1]-tree['left'],2)) + np.sum(np.power(rSet[:,-1]-tree['right'],2))
#剪枝后的误差
treeMean = (tree['left'] + tree['right'])/2.0
erroMerge = np.sum(np.power(testDate[:,-1]-treeMean,2))
#如果剪枝后的误差小于剪枝前的误差,则进行剪枝
if erroMerge < erroNoMerge:
print('merging')
return treeMean
else : return tree
else : return tree
dataSet = loadDataSet('ex0.txt')
dataSet1 = loadDataSet('ex0test.txt')
plt.subplot(121)
plt.scatter(dataSet[:,0], dataSet[:,1])
plt.subplot(122)
plt.scatter(dataSet1[:,0], dataSet1[:,1])
plt.show()
tree_ = createTree(dataSet,ops=(0.1,0.4))
tree_ = prune(tree_,dataSet1)
print(tree_)
init.py
from DecisionTree import trees,CARTTree,treePlotter,regTrees
from os.path import os
# def createDataSet():
# dataSet = [[1,1,'yes'],
# [1,1,'yes'],
# [1,0,'no'],
# [0,1,'no'],
# [0,1,'no']]
# labels = ['no surfacing','flippers']
# return dataSet,labels
# def createDataSet():
# dataSet = [[1,2,2,3,'no'],
# [1,2,2,2,'no'],
# [1,1,2,2,'yes'],
# [1,1,1,3,'yes'],
# [1,2,2,3,'no'],
# [2,2,2,3,'no'],
# [2,2,2,2,'no'],
# [2,1,1,2,'yes'],
# [2,2,1,1,'yes'],
# [2,2,1,1,'yes'],
# [3,2,1,1,'yes'],
# [3,2,1,2,'yes'],
# [3,1,2,2,'yes'],
# [3,1,2,1,'yes'],
# [3,2,2,3,'no']]
# labels = ['年龄','有工作','有自己房子','信贷情况']
# return dataSet,labels
def loadData(fileName):
dataSet = []
data_path = os.getcwd()+'\\data\\'
fr = open(data_path+fileName)
for line in fr.readlines():
curLine = line.strip().split(',')
dataSet.append(curLine)
return dataSet
dataSet = loadData('watermelon1.txt')
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
# dataSet,labels = createDataSet()
mytree = trees.createTree(dataSet, labels)
# mytree = regTrees.createTree(dataSet)
# mytree = CARTTree.creatCART(dataSet, labels)
print(mytree)
# treePlotter.createPlot(mytree)