Python 爬虫基础教程——BeautifulSoup抓取入门(1)

大家好,上篇推文介绍了爬虫方面需要注意的地方、使用vscode开发环境的时候会遇到的问题以及使用正则表达式的方式爬取页面信息,本篇内容主要是介绍BeautifulSoup模块的使用教程。
一、BeautifulSoup介紹
引用官方的解释:
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
简单来说Beautiful Soup是python的一个库,是一个可以从网页抓取数据的利器。
官方文档:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
二、BeautifulSoup安裝
pip install beautifulsoup4
或
pip install beautifulsoup4
-i http://pypi.douban.com/simple/
--trusted-host http://pypi.douban.com
顺便说一句:我使用的开发工具还是vscode,不清楚的看一下之前的推文。
三、BeautifulSoup解析器
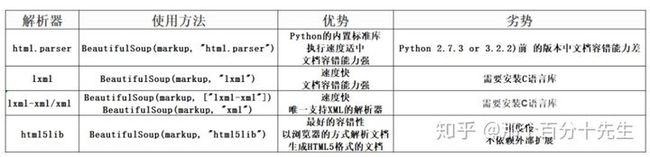
3.1 html.parse
html.parse 是内置的不需要安装的
import requests
from bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())结果
3.2 lxml
lxml 是需要安装 pip install lxml
import requests
from bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
print(soup)结果

3.3 lxml-xml/xml
lxml-xml/Xm是需要安装的 pip install lxml
import requests
from bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'xml')
print(soup)结果
3.4 html5lib
html5lib 是需要安装的 pip install html5lib
import requests
from bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html5lib')
print(soup)结果
大家看到这几个解析器解析出来的记过基本上都是一样,但是如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的。什么叫HTML或XML文档格式不正确,简单的来说就是缺少不必要的标签或者标签没有闭合,比如页面缺少body标签、只有a标签开始的部分缺少a标签结束的部分(这里是一些前端的知识,不明白的可以搜索一下,很简单)。
我们来尝试一下
from bs4 import BeautifulSoup
html=""
soup = BeautifulSoup(html, 'html.parser')
print("html.parser 结果:")
print(soup)
soup1 = BeautifulSoup(html, 'lxml')
print("lxml 结果:")
print(soup1)
soup2 = BeautifulSoup(html, 'xml')
print("xml 结果:")
print(soup2)
soup3 = BeautifulSoup(html, 'html5lib')
print("html5lib 结果:")
print(soup3)
结果
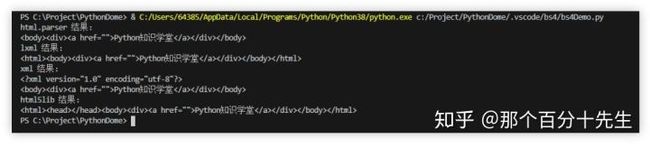
可以看出html.parser与lxml 差不多的 都会给标签补齐,但lxml会把html 标签给补齐,xml也会给标签补齐,而且还会加上xml文档的版本编码方式等信息,但是不会把html标签补齐,html5lib 也会补齐不但补齐了html标签而且给整个页面补齐head 标签。
这就验证了上面表格上的html5lib 的容错性最好,但是html5lib 解析器的速度不快,内容比较少的话是比较不出速度的差别的,所以推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
如果我们不指定解析器会怎么样?
from bs4 import BeautifulSoup
html=""
soup = BeautifulSoup(html)
print("html.parser 结果:")
print(soup)结果

从结果提示可以得出,不指定解析器的话,他会给出系统最好的解析器,我的系统是lxml,如果你在别的环境没有安装lxml的话,可能会是别的解析器,总之系统会给你选择一个默认最好的解析器给你,所以你可以不指定,这还不是比较人性化的吧。
四、BeautifulSoup对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
4.1 tag
tag中最重要的属性: name和attributes
from bs4 import BeautifulSoup
html="Python知识学堂 "
soup = BeautifulSoup(html,'lxml')
tag=soup.a #a标签就相当于一个标签
tag.name
print(tag.name)
tag=soup.test #test 也是算是标签
tag.name
print(tag.name)
结果

上面的代码中的a标签就是表示一个tag,而且test也算是一个标签,test是我随便写的,所以Beautiful Soup中html标签和自定义的标签都是可以当作是tag,是不是很强大!
那么什么是attributes呢?看上面的代码 a 标签中的data-id与class这个就算是标签中的属性;
from bs4 import BeautifulSoup
html="结果:

如果要获取某一个属性,可以使用tag['data-id']或tag.attrs['data-id'] 都是可以的。
这个用处最多的应该是获取a标签的链接地址以及img标签的媒体文件地址等。
如果属于里有多个值的话会返回一个list
from bs4 import BeautifulSoup
html="结果:

4.2 NavigableString
包含在tag内的字符串可以用NavigableString类来直接获取,也叫可以遍历的字符串。
from bs4 import BeautifulSoup
html="结果:

这个比较简单,就不再多说了;
4.3 BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
先大概了解一下,在后面遍历文档、搜索文档会有描述;
4.4 Comment
主要是文档中的注释部分。
Comment 对象是一个特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup
html= ""
soup = BeautifulSoup(html,'lxml')
comment = soup.b.string
print(comment)结果

不过下面这种情况是获取不到的
from bs4 import BeautifulSoup
html= "我是谁?"
soup = BeautifulSoup(html,'lxml')
comment = soup.b.string
print(comment)结果

可以看到返回的结果是None,所以只有在特殊的情况下才能获取到注释的内容;
五、总结
本篇文章讲述了关于BeautifulSoup的一些基础的内容。主要是bs的几种解析器,根据实际的情况选择不同的解析器。