beautifulsoup获取属性_Python 爬虫基础教程——BeautifulSoup抓取入门
点击上方蓝色文字关注我们吧
有你想要的精彩

大家好,上篇推文介绍了爬虫方面需要注意的地方、使用vscode开发环境的时候会遇到的问题以及使用正则表达式的方式爬取页面信息,本篇内容主要是介绍BeautifulSoup模块的使用教程。
BeautifulSoup介紹
引用官方的解释:
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
简单来说Beautiful Soup是python的一个库,是一个可以从网页抓取数据的利器。
官方文档:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup安裝
pip install beautifulsoup4
或
pip install beautifulsoup4
-i http://pypi.douban.com/simple/
--trusted-host pypi.douban.com
顺便说一句:我使用的开发工具还是vscode,不清楚的看一下之前的推文。
BeautifulSoup解析器
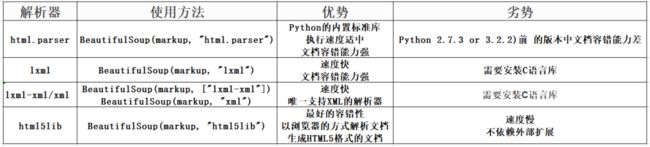
html.parse
html.parse 是内置的不需要安装的
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
结果

lxml
lxml 是需要安装 pip install lxml
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
print(soup)
结果

lxml-xml/xml
lxml-xml/Xm是需要安装的 pip install lxml
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'xml')
print(soup)结果
html5lib
html5lib 是需要安装的 pip install html5lib
import requestsfrom bs4 import BeautifulSoup
url='https://www.baidu.com'
response=requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html5lib')
print(soup)
结果

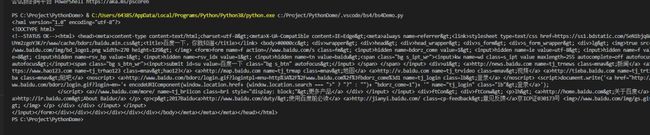
大家看到这几个解析器解析出来的记过基本上都是一样,但是如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的。什么叫HTML或XML文档格式不正确,简单的来说就是缺少不必要的标签或者标签没有闭合,比如页面缺少body标签、只有a标签开始的部分缺少a标签结束的部分(这里是一些前端的知识,不明白的可以搜索一下,很简单)。
我们来尝试一下
from bs4 import BeautifulSoup
html="Python知识学堂
"
soup = BeautifulSoup(html, 'html.parser')
print("html.parser 结果:")
print(soup)
soup1 = BeautifulSoup(html, 'lxml')
print("lxml 结果:")
print(soup1)
soup2 = BeautifulSoup(html, 'xml')
print("xml 结果:")
print(soup2)
soup3 = BeautifulSoup(html, 'html5lib')
print("html5lib 结果:")
print(soup3)
结果

可以看出html.parser与lxml 差不多的 都会给标签补齐,但lxml会把html 标签给补齐,xml也会给标签补齐,而且还会加上xml文档的版本编码方式等信息,但是不会把html标签补齐,html5lib 也会补齐不但补齐了html标签而且给整个页面补齐head 标签。
这就验证了上面表格上的html5lib 的容错性最好,但是html5lib 解析器的速度不快,内容比较少的话是比较不出速度的差别的,所以推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
如果我们不指定解析器会怎么样?
from bs4 import BeautifulSoup
html="Python知识学堂
"
soup = BeautifulSoup(html)
print("html.parser 结果:")
print(soup)
结果

从结果提示可以得出,不指定解析器的话,他会给出系统最好的解析器,我的系统是lxml,如果你在别的环境没有安装lxml的话,可能会是别的解析器,总之系统会给你选择一个默认最好的解析器给你,所以你可以不指定,这还不是比较人性化的吧。
BeautifulSoup对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
tag
tag中最重要的属性: name和attributes
from bs4 import BeautifulSoup
html="Python知识学堂
Python知识学堂"
soup = BeautifulSoup(html,'lxml')
tag=soup.a #a标签就相当于一个标签
tag.name
print(tag.name)
tag=soup.test #test 也是算是标签
tag.name
print(tag.name)
结果

上面的代码中的a标签就是表示一个tag,而且test也算是一个标签,test是我随便写的,所以Beautiful Soup中html标签和自定义的标签都是可以当作是tag,是不是很强大!
那么什么是attributes呢?看上面的代码 a 标签中的data-id与class这个就算是标签中的属性;
from bs4 import BeautifulSoup
html="Python知识学堂
"
soup = BeautifulSoup(html,'lxml')
tag=soup.a
print(tag.attrs)
结果:

如果要获取某一个属性,可以使用tag['data-id']或tag.attrs['data-id'] 都是可以的。
这个用处最多的应该是获取a标签的链接地址以及img标签的媒体文件地址等。
如果属于里有多个值的话会返回一个list
from bs4 import BeautifulSoup
html="Python知识学堂
"
soup = BeautifulSoup(html,'lxml')
print(tag['data-id'])
结果:

NavigableString
包含在tag内的字符串可以用NavigableString类来直接获取,也叫可以遍历的字符串。
from bs4 import BeautifulSoup
html="Python知识学堂,欢迎你!
"
soup = BeautifulSoup(html,'lxml')
tag=soup.a
print(tag.string)
结果:

这个比较简单,就不再多说了;
BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
先大概了解一下,在后面遍历文档、搜索文档会有描述;
Comment
主要是文档中的注释部分。
Comment 对象是一个特殊类型的 NavigableString 对象:
from bs4 import BeautifulSoup
html= ""
soup = BeautifulSoup(html,'lxml')
comment = soup.b.string
print(comment)
结果

不过下面这种情况是获取不到的
from bs4 import BeautifulSoup
html= "我是谁?"
soup = BeautifulSoup(html,'lxml')
comment = soup.b.string
print(comment)结果

可以看到返回的结果是None,所以只有在特殊的情况下才能获取到注释的内容;
遍历文档树
直接看代码吧
from bs4 import BeautifulSoup
html=' python 知识学堂
![]()
Python 知识 学堂 欢迎 您
'#上面是随便写的一个页面代码
soup=BeautifulSoup(html,'lxml')
#print(soup.prettify())
print("-------------------------------------------------分割符----------------------------------------------------")
print(soup.head) # 获取head 标签
print("-------------------------------------------------分割符----------------------------------------------------")
print(soup.a) #获取a 标签 默认是第一个
print("-------------------------------------------------分割符----------------------------------------------------")
print('contents:')
print(soup.a.contents) #tag的 .contents 属性可以将tag的子节点以列表的方式输出
print("-------------------------------------------------分割符----------------------------------------------------")
print('children:')for child in soup.form.children: #获取标签下的一级子标签
print(child)
print("-------------------------------------------------分割符----------------------------------------------------")
print('descendants:')for child in soup.form.descendants: #获取标签下的所有tag子孙节点进行递归循环
print(child)
print("-------------------------------------------------分割符----------------------------------------------------")
print('strings:')for str in soup.strings: #输入标签内的字符串
print(str)
print("-------------------------------------------------分割符----------------------------------------------------")
print('stripped_strings:')for str in soup.stripped_strings: #输入标签内的字符串 去除空字符串
print(str)
结果:
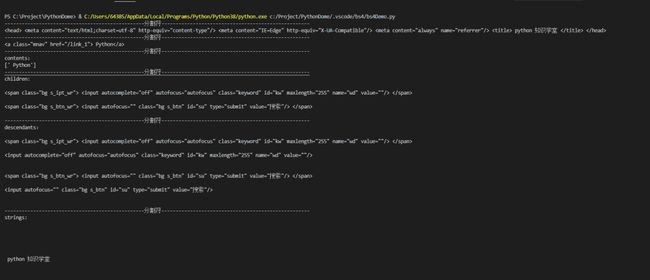

上面知识简单的举了几个获取树的节点的方式,还有很多其他的方式,比如获取父节点,兄弟节点等等。有点与jquery 遍历 DOM的概念类似。
搜索文档树
Beautiful Soup定义了很多搜索方法, 这里主要介绍一下比较常用的到的两个方法:find()和find_all(),其他的可以用法类似,举一反三。
过滤器
字符串
正则表达式
列表
True
方法
from bs4 import BeautifulSoupimport re
html=' python 知识学堂
![]()
Python 知识 学堂 欢迎 您
'#上面是随便写的一个页面代码
soup=BeautifulSoup(html,'lxml')
print("-------------------------------------------------分割符----------------------------------------------------") #最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签
print("字符串:")
print(soup.find_all('a'))
print("-------------------------------------------------分割符----------------------------------------------------") #如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以a开头的标签,这表示所有标签都应该被找到
print("正则表达式:")
print(soup.find_all(re.compile("^a")))
print("-------------------------------------------------分割符----------------------------------------------------") #如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有标签和标签
print("列表:")
print(soup.find_all(['a','head']))
print("-------------------------------------------------分割符----------------------------------------------------") #True 可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
print("Ture:")
print(soup.find_all(True))
结果:

find_all()
Name:可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉;
keyword 参数:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性;
按CSS搜索:按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag;
string 参数:通过 string 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, string 参数接受 字符串 , 正则表达式 , 列表, True .;
limit 参数:find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果;
recursive 参数:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
from bs4 import BeautifulSoup
html=' python 知识学堂
![]()
Python 知识 学堂 欢迎 您
'#上面是随便写的一个页面代码
soup=BeautifulSoup(html,'lxml')
#print(soup.prettify())
print("通过tag的name:")
print(soup.find_all('head')) #获取head 标签
print("通过keyword获取:")
print(soup.find_all(id="head")) #获取Id 为head的所有标签
print("通过css类名获取:")
print(soup.find_all('a',class_='mnav')) #获取所有a标签 并且class属性值为mnavprint("通过string获取:")print(soup.find_all(string="知识")) #获取所有a标签内容为python 的所有标签,全字符匹配
print("limit参数:")
print(soup.find_all("a",limit=2)) #limit表示获取的数量
print("recursive 参数:")
print(soup.find_all("a",recursive=false)) #recursive 默认为true 表示获取当前tag的所有子孙节点,如果为false 只搜索tag直接子节点
结果:
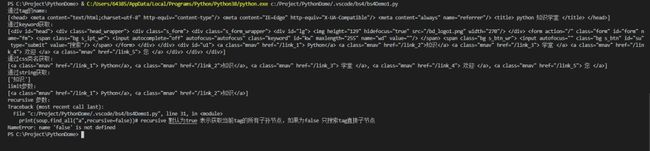
注意只有 find_all() 和 find() 支持 recursive 参数.
find()的方法跟find_all()基本一样,唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果。
输出
格式化输出
压缩输出
输出格式
get_text()
from bs4 import BeautifulSoup
html=' python 知识学堂
![]()
Python 知识 学堂 欢迎 您
'#上面是随便写的一个页面代码
soup = BeautifulSoup(html,'lxml')#prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行
print("格式化输出:")
print(soup.prettify())
print("-------------------------------------------------分割符----------------------------------------------------") #如果只想得到结果字符串,不重视格式,那么可以对一个 BeautifulSoup 对象或 Tag 对象使用Python的 unicode() 或 str() 方法
print("压缩输出:")
print(str(soup))
print("-------------------------------------------------分割符----------------------------------------------------") #Beautiful Soup输出是会将HTML中的特殊字符转换成Unicode,比如“&lquot;”
print("输出格式:")
print(str(BeautifulSoup("&&*&*",'lxml')))
print("-------------------------------------------------分割符----------------------------------------------------") #如果只想得到tag中包含的文本内容,那么可以用 get_text() 方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回
print("get_text():")
print(soup.get_text())
print("-------------------------------------------------分割符----------------------------------------------------")
结果我就不贴出来了,自己执行一下就知道了。
当然还有别的很多方法,在这里就不再赘述了,可以直接参考官方
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Buaautiful soup 的功能还是很强大的,这里只是简单的描述了一下爬虫常用的一些东西。
下面就来实操一下吧,还是一上篇文章获取省市区为例子
实例
我们还是用上篇的获取省市区来举例子。
import requestsfrom bs4 import BeautifulSoupimport timeclass Demo():def __init__(self):try:base_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
trlist = self.get_data(base_url, "provincetable",'provincetr') #查看页面,就知道所有的省所在的tr上都有唯一的class='provincetr'for tr in trlist:for td in tr:if td.a is None:continue
p_name = td.a.get_text()
c_url = base_url + td.a.get('href') #获取下级城市的地址
print("省:" + p_name) #获取每个省
# time.sleep(0.5)
trs = self.get_data(c_url, "citytable","citytr")for tr in trs: #循环每个市if tr.find_all('td')[1] is None:continue
#c_code = tr.find_all('td')[0].string #获取城市code
c_name = tr.find_all('td')[1].string #获取城市 name
ct_url = base_url + tr.find_all('td')[1].a.get('href') #获取下级区的地址
print(p_name+"-"+c_name)
time.sleep(0.5)
trs1 = self.get_courtydata(ct_url)if trs1 is None:continuefor tr1 in trs1: #循环每个区if tr1.find_all('td')[1] is None:continue
#ct_code = tr.find_all('td')[0].string #获取区code
ct_name = tr1.find_all('td')[1].string #获取区name
print(p_name+"-"+c_name+"-"+ct_name)
except:
print("出错了")
def get_data(self, url, table_attr,attr):
response = requests.get(url)
response.encoding = 'gb2312' #编码转换
soup = BeautifulSoup(response.text, 'lxml') #使用lxml的解析器
table = soup.find('table',class_=table_attr) #查看页面元素就知道数据都在第二个 tbody
trlist = table.find_all('tr',class_=attr)return trlist
def get_courtydata(self, url):
response = requests.get(url)
response.encoding = 'gb2312' #编码转换
soup = BeautifulSoup(response.text, 'lxml') #使用lxml的解析器
towntr=soup.find('table',class_='towntable')if towntr is not None:
table = soup.find('table',class_='towntable')
trlist = table.find_all('tr',class_='towntr')else:
table = soup.find('table',class_='countytable')
trlist = table.find_all('tr',class_='countytr')return trlistif __name__ == '__main__':
Demo()
结果
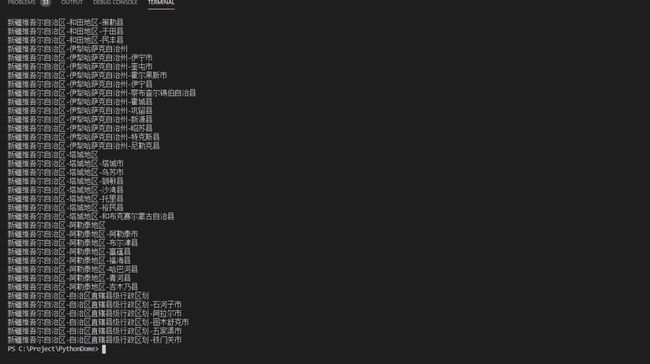
直接给大家看一下获取到的最后一个省市区的结果了,大家注意每次获取的页面信息时的时间间隔;
总结
本篇文章讲述了关于BeautifulSoup的一些基础的内容,主要是与爬虫相关的,关于BeautifulSoup其他功能还有很多,大家可以区官网上自行学习。
再贴一下 官网地址:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
下期预告
下次的推文是关于lxml的模块的相关基础内容,不过下周的的推文是关于深度学习的内容,爬虫的可能要等到下下周了,感谢大家的支持!

往期精选(?猛戳可查看)
Python爬虫基础教程——正则表达式抓取入门
2020-08-30

Python实用教程系列——VSCode Python 开发环境搭建
2020-08-01
Python实用教程系列——异常处理
2020-07-05

点赞和在看一下吧
