Python之Scrapy爬虫(热门网站数据爬取)
第一关:猫眼电影排行TOP100信息爬取
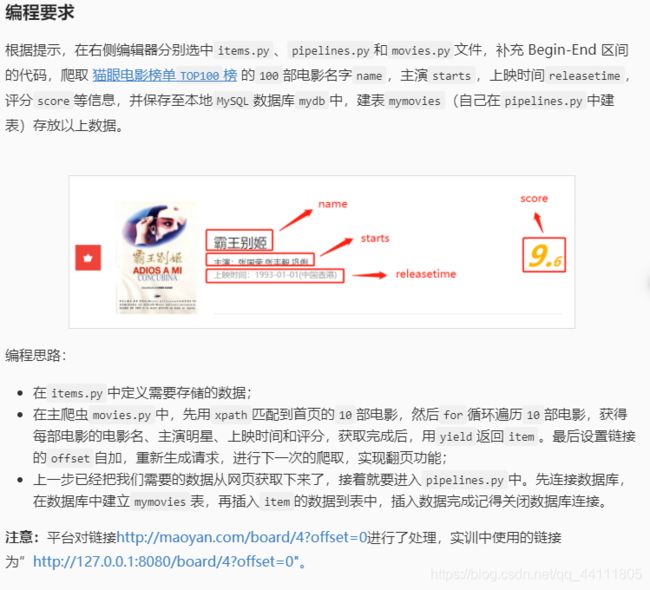

代码:
item.py文件
import scrapy
class MaoyanItem(scrapy.Item):
#********** Begin **********#
name = scrapy.Field()
starts = scrapy.Field()
releasetime = scrapy.Field()
score = scrapy.Field()
#********** End **********#
pipeline.py文件
import pymysql
class MaoyanPipeline(object):
def process_item(self, item, spider):
#********** Begin **********#
#1.连接数据库
connection = pymysql.connect(
host='localhost', # 连接的是本地数据库
port=3306, #数据库端口名
user='root', # 自己的mysql用户名
passwd='123123', # 自己的密码
db='mydb', # 数据库的名字
charset='utf8', # 默认的编码方式
)
#2.建表、给表插入数据,完成后关闭数据库连接,return返回item
name = item['name']
starts = item['starts']
releasetime = item['releasetime']
score = item['score']
try:
with connection.cursor() as cursor:
sql1 = 'Create Table If Not Exists mymovies(name varchar(50) CHARACTER SET utf8 NOT NULL,starts text CHARACTER SET utf8 NOT NULL,releasetime varchar(50) CHARACTER SET utf8 DEFAULT NULL,score varchar(20) CHARACTER SET utf8 NOT NULL,PRIMARY KEY(name))'
# 单章小说的写入
sql2 = 'Insert into mymovies values (\'%s\',\'%s\',\'%s\',\'%s\')' % (
name, starts, releasetime, score)
cursor.execute(sql1)
cursor.execute(sql2)
# 提交本次插入的记录
connection.commit()
finally:
# 关闭连接
connection.close()
return item
#********** End **********#
movies.py文件
import scrapy
from maoyan.items import MaoyanItem
class MoviesSpider(scrapy.Spider):
name = 'movies'
allowed_domains = ['127.0.0.1']
offset = 0
url = "http://127.0.0.1:8080/board/4?offset="
#********** Begin **********#
#1.对url进行定制,为翻页做准备
start_urls = [url + str(offset)]
#2.定义爬虫函数parse()
def parse(self, response):
item = MaoyanItem()
movies = response.xpath("//div[ @class ='board-item-content']")
for each in movies:
#电影名
name = each.xpath(".//div/p/a/text()").extract()[0]
#主演明星
starts = each.xpath(".//div[1]/p/text()").extract()[0]
#上映时间
releasetime = each.xpath(".//div[1]/p[3]/text()").extract()[0]
score1 = each.xpath(".//div[2]/p/i[1]/text()").extract()[0]
score2 = each.xpath(".//div[2]/p/i[2]/text()").extract()[0]
#评分
score = score1 + score2
item['name'] = name
item['starts'] = starts
item['releasetime'] = releasetime
item['score'] = score
yield item
#3.在函数的最后offset自加10,然后重新发出请求实现翻页功能
if self.offset < 90:
self.offset += 10
yield scrapy.Request(self.url+str(self.offset), callback=self.parse)
#********** End **********#
第二关:小说网站玄幻分类第一页小说爬取

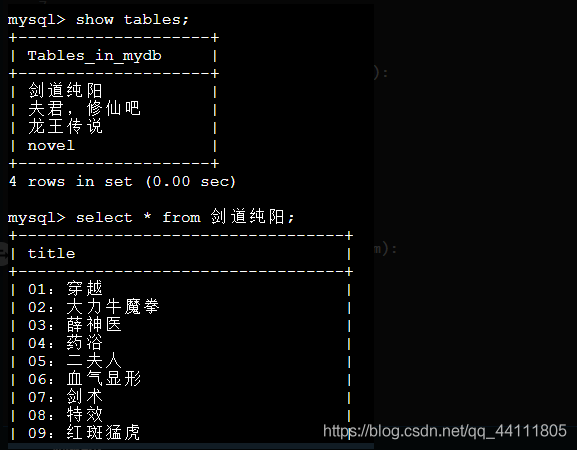

代码:
items.py文件
import scrapy
#存放全部小说信息
class NovelprojectItem(scrapy.Item):
#********** Begin **********#
name = scrapy.Field()
author = scrapy.Field()
state = scrapy.Field()
description = scrapy.Field()
#********** End **********#
#单独存放小说章节
class NovelprojectItem2(scrapy.Item):
#********** Begin **********#
tablename = scrapy.Field()
title = scrapy.Field()
#********** End **********#
pipeline.py文件
import pymysql
from NovelProject.items import NovelprojectItem,NovelprojectItem2
class NovelprojectPipeline(object):
def process_item(self, item, spider):
#********** Begin **********#
#1.和本地的数据库mydb建立连接
connection = pymysql.connect(
host='localhost', # 连接的是本地数据库
port = 3306, # 端口号
user='root', # 自己的mysql用户名
passwd='123123', # 自己的密码
db='mydb', # 数据库的名字
charset='utf8', # 默认的编码方式:
)
#2.处理来自NovelprojectItem的item(处理完成后return返回item)
if isinstance(item, NovelprojectItem):
# 从items里取出数据
name = item['name']
author = item['author']
state = item['state']
description = item['description']
try:
with connection.cursor() as cursor:
# 小说信息写入
sql1 = 'Create Table If Not Exists novel(name varchar(20) CHARACTER SET utf8 NOT NULL,author varchar(10) CHARACTER SET utf8,state varchar(20) CHARACTER SET utf8,description text CHARACTER SET utf8,PRIMARY KEY (name))'
sql2 = 'Insert into novel values (\'%s\',\'%s\',\'%s\',\'%s\')' % (name, author, state, description)
cursor.execute(sql1)
cursor.execute(sql2)
# 提交本次插入的记录
connection.commit()
finally:
# 关闭连接
connection.close()
return item
#3.处理来自NovelprojectItem2的item(处理完成后return返回item)
elif isinstance(item, NovelprojectItem2):
tablename = item['tablename']
title = item['title']
try:
with connection.cursor() as cursor:
# 小说章节的写入
sql3 = 'Create Table If Not Exists %s(title varchar(20) CHARACTER SET utf8 NOT NULL,PRIMARY KEY (title))' % tablename
sql4 = 'Insert into %s values (\'%s\')' % (tablename, title)
cursor.execute(sql3)
cursor.execute(sql4)
connection.commit()
finally:
connection.close()
return item
#********** End **********#
novel.py文件
import scrapy
import re
from scrapy.http import Request
from NovelProject.items import NovelprojectItem
from NovelProject.items import NovelprojectItem2
class NovelSpider(scrapy.Spider):
name = 'novel'
allowed_domains = ['127.0.0.1']
start_urls = ['http://127.0.0.1:8000/list/1_1.html'] #全书网玄幻魔法类第一页
#********** Begin **********#
#1.定义函数,通过'马上阅读'获取每一本书的 URL
def parse(self, response):
book_urls = response.xpath('//li/a[@class="l mr10"]/@href').extract()
three_book_urls = book_urls[0:3] #只取3本
for book_url in three_book_urls:
yield Request(book_url, callback=self.parse_read)
#2.定义函数,进入小说简介页面,获取信息,得到后yield返回给pipelines处理,并获取'开始阅读'的url,进入章节目录
def parse_read(self, response):
item = NovelprojectItem()
# 小说名字
name = response.xpath('//div[@class="b-info"]/h1/text()').extract_first()
#小说简介
description = response.xpath('//div[@class="infoDetail"]/div/text()').extract_first()
# 小说连载状态
state = response.xpath('//div[@class="bookDetail"]/dl[1]/dd/text()').extract_first()
# 作者名字
author = response.xpath('//div[@class="bookDetail"]/dl[2]/dd/text()').extract_first()
item['name'] = name
item['description'] = description
item['state'] = state
item['author'] = author
yield item
# 获取开始阅读按钮的URL,进入章节目录
read_url = response.xpath('//a[@class="reader"]/@href').extract()[0]
yield Request(read_url, callback=self.parse_info)
#3.定义函数,进入章节目录,获取小说章节名并yield返回
def parse_info(self, response):
item = NovelprojectItem2()
tablename = response.xpath('//div[@class="main-index"]/a[3]/text()').extract_first()
titles = response.xpath('//div[@class="clearfix dirconone"]/li')
for each in titles:
title = each.xpath('.//a/text()').extract_first()
item['tablename'] = tablename
item['title'] = title
yield item
#********** End **********#
第三关:模拟登陆拉勾网爬取招聘信息


代码:
items.py文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AjaxprojectItem(scrapy.Item):
#********** Begin **********#
jobName = scrapy.Field()
jobMoney = scrapy.Field()
jobNeed = scrapy.Field()
jobCompany = scrapy.Field()
jobType = scrapy.Field()
jobSpesk = scrapy.Field()
#********** End **********#
middlewares.py文件
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import scrapy
#********** Begin **********#
from scrapy import signals
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
import random
#********** End **********#
class AjaxprojectSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class AjaxprojectDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
#********** Begin **********#
#别忘了在开头导入依赖
class MyUserAgentMiddleware(UserAgentMiddleware):
#设置User-agent
def __init__(self, user_agent):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
return cls(
user_agent = crawler.settings.get('MY_USER_AGENT')
)
def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent
class CookieMiddleware(CookiesMiddleware):
def __init__(self, cookie):
self.cookie = cookie
@classmethod
def from_crawler(cls, crawler):
return cls(
cookie = crawler.settings.get('COOKIE')
)
def process_request(self, request, spider):
request.cookies = self.cookie
#********** End **********#
pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class AjaxprojectPipeline(object):
def process_item(self, item, spider):
#********** Begin **********#
#1.连接数据库
connection = pymysql.connect(
host='localhost', # 连接的是本地数据库
port=3306, #数据库端口名
user='root', # 自己的mysql用户名
passwd='123123', # 自己的密码
db='mydb', # 数据库的名字
charset='utf8', # 默认的编码方式
)
#2.建表,插入数据,完毕后关闭数据库连接,并return item
jobName = item['jobName']
jobMoney = item['jobMoney']
jobNeed = item['jobNeed']
jobCompany = item['jobCompany']
jobType = item['jobType']
jobSpesk = item['jobSpesk']
try:
with connection.cursor() as cursor:
sql1 = 'Create Table If Not Exists lgjobs(jobName varchar(20) CHARACTER SET utf8 NOT NULL,jobMoney varchar(10),jobNeed varchar(20) CHARACTER SET utf8 ,jobCompany varchar(20) CHARACTER SET utf8 ,jobType varchar(20) CHARACTER SET utf8 ,jobSpesk varchar(20) CHARACTER SET utf8 ,PRIMARY KEY(jobName))'
sql2 = 'Insert into lgjobs values (\'%s\',\'%s\',\'%s\',\'%s\',\'%s\',\'%s\')' % (jobName, jobMoney, jobNeed, jobCompany,jobType,jobSpesk)
cursor.execute(sql1)
cursor.execute(sql2)
# 提交本次插入的记录
connection.commit()
finally:
# 关闭连接
connection.close()
return item
#********** End **********#
settings.py文件
# -*- coding: utf-8 -*-
# Scrapy settings for AjaxProject project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'AjaxProject'
SPIDER_MODULES = ['AjaxProject.spiders']
NEWSPIDER_MODULE = 'AjaxProject.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'AjaxProject.middlewares.AjaxprojectSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#********** Begin **********#
#MY_USER_AGENT
MY_USER_AGENT = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
]
#DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,#这里要设置系统的useragent为None,否者会被覆盖掉
'AjaxProject.middlewares.MyUserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700,
}
#ITEM_PIPELINES
ITEM_PIPELINES = {
'AjaxProject.pipelines.AjaxprojectPipeline': 300,
}
#DOWNLOAD_DELAY
DOWNLOAD_DELAY = 1.5
#COOKIE
COOKIE = {
"user_trace_token": "20171109093921 - c87e4dd6 - 6116 - 4060 - a976 - 38df4f6dfc1c",
"_ga = GA1": ".2.1308939382.1510191563",
"LGUID": "20171109093922 - cff5ddb7 - c4ee - 11e7 - 985f - 5254005c3644",
"JSESSIONID": "ABAAABAAAGGABCBAE8E3FCEFC061F7CF2860681B1BF3D98",
"X_HTTP_TOKEN": "0f2396abe975f6a09df1c0b8a0a3a258",
"showExpriedIndex": "1",
"showExpriedCompanyHome": "1",
"showExpriedMyPublish": "1",
"hasDeliver": "12",
"index_location_city": "% E6 % B7 % B1 % E5 % 9C % B3",
"TG - TRACK - CODE": "index_user",
"login": "false",
"unick": "",
"_putrc": "",
"LG_LOGIN_USER_ID": "",
"_gat": "1",
"LGSID": "20180720141029 - 99fde5eb - 8be3 - 11e8 - 9e4d - 5254005c3644",
"PRE_UTM": "",
"PRE_HOST": "",
"PRE_SITE": "",
"PRE_LAND": "https % 3A % 2F % 2Fwww.lagou.com % 2Fzhaopin % 2F",
"SEARCH_ID": "5ddd3d52f1d94b45820534b397ef21e6",
"LGRID": "20180720141849 - c455d124 - 8be4 - 11e8 - 9e4d - 5254005c3644",
}
#********** End **********#
ajax.py文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import requests
from AjaxProject.items import AjaxprojectItem
class AjaxSpider(scrapy.Spider):
name = 'ajax'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/zhaopin/%d/' %n for n in range(1,6)] #爬取招聘信息1-5页
#********** Begin **********#
#定义爬虫处理函数parse()
def parse(self, response):
Jobs = response.xpath('//ul[@class="item_con_list"]/li')
for Job in Jobs:
jobName = Job.xpath('div/div/div/a/h3/text()').extract_first()
jobMoney = Job.xpath('div/div/div/div/span/text()').extract_first()
jobNeed = Job.xpath('div/div/div/div/text()').extract()
jobNeed = jobNeed[2].strip()
jobCompany = Job.xpath('div/div/div/a/text()').extract()
jobCompany = jobCompany[3].strip()
jobType = Job.xpath('div/div/div/text()').extract()
jobType = jobType[7].strip()
jobSpesk = Job.xpath('div[@class="list_item_bot"]/div/text()').extract()
jobSpesk = jobSpesk[-1].strip()
item = AjaxprojectItem()
item['jobName'] = jobName
item['jobMoney'] = jobMoney
item['jobNeed'] = jobNeed
item['jobCompany'] = jobCompany
item['jobType'] = jobType
item['jobSpesk'] = jobSpesk
yield item
#********** End **********#