本文主要记录利用爬虫爬取豆瓣对电影《西虹市首富》的短评,使用word分词器分词,并使用Spark计算出磁盘取Top20,使用echats展示。
效果图如下:

相关文章:
1.Spark之PI本地
2.Spark之WordCount集群
3.SparkStreaming之读取Kafka数据
4.SparkStreaming之使用redis保存Kafka的Offset
5.SparkStreaming之优雅停止
6.SparkStreaming之写数据到Kafka
7.Spark计算《西虹市首富》短评词云
1.爬取数据
参考:使用爬虫爬取豆瓣电影影评数据Java版
其中略微修改:
PageParser.java
public Data parse(String url, String html) {
Document doc = Jsoup.parse(html, url);
// 获取链接列表
List links =
doc.select("#paginator > a.next")
.stream()
.map(a -> a.attr("abs:href"))
.collect(Collectors.toList());
// 获取数据列表
List> results = doc.select("#comments > div.comment-item")
.stream()
.map(div -> {
Map data = new HashMap<>();
String author = div.selectFirst("h3 > span.comment-info > a").text();
String date = div.selectFirst("h3 > span.comment-info > span.comment-time").text();
Element rating = div.selectFirst("h3 > span.comment-info > span.rating");
String star = "0";
if (rating != null) {
// allstar40 rating
star = rating.attr("class");
star = star.substring(7, 9);
}
String vote = div.selectFirst("h3 > span.comment-vote > span.votes").text();
String comment = div.selectFirst("div.comment > p").text();
data.put("author", author);
data.put("date", date);
if (star != null)
data.put("star", star);
data.put("vote", vote);
data.put("comment", comment);
return data;
})
.collect(Collectors.toList());
return new Data(links, results);
}
DataProcessor.java
public void process(List results) {
if (results == null || results.isEmpty()) {
return;
}
try {
// 数据
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File("C:\\xhs_json.txt"), true)));
Gson gson = new Gson();
for (T result : results) {
bw.write(gson.toJson(result));
bw.write("\r\n");
}
bw.flush();
bw.close();
// 分词结果
PrintWriter pw = new PrintWriter(new OutputStreamWriter(new FileOutputStream(new File("C:\\xhs_word.txt"), true)));
for (T result : results) {
if (result instanceof Map) {
List words = WordSegmenter.seg(((Map) result).get("comment").toString());
pw.println(words.stream().map(word -> word.getText()).collect(Collectors.joining(" ")));
}
}
pw.flush();
pw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
大概540条数据,保存两份文件,xhs_json.txt是完整的短评json文件,xhs_word.txt是使用word对短评内容分词的文件

xhs_json.txt

xhs_word.txt
爬虫下载地址
xhs_json.txt下载地址
xhs_word.txt下载地址
2.Spark计算
只需要利用xhs_word.txt文件进行wordcount计算即可,然后打印出echat需要显示的格式即可
object YingPing {
def main(args: Array[String]): Unit = {
//创建一个Config
val conf = new SparkConf()
.setAppName("YingPing")
.setMaster("local[1]")
//核心创建SparkContext对象
val sc = new SparkContext(conf)
//WordCount
sc.textFile("C:\\xhs_word.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//.repartition(1)
.sortBy(_._2, false)
.take(20)
.map(x => {
val map = new java.util.HashMap[String, String]()
map.put("name", x._1)
map.put("value", x._2 + "")
map.put("itemStyle", "createRandomItemStyle()")
map
})
.foreach(item => println(new Gson().toJson(item).replace("\"c", "c").replace(")\"", ")") + ","))
// 借助http://echarts.baidu.com/echarts2/doc/example/wordCloud.html#infographic可以显示词云
//停止SparkContext对象
sc.stop()
}
}
结果如下:
{"name":"电影","itemStyle":createRandomItemStyle(),"value":"160"},
{"name":"麻花","itemStyle":createRandomItemStyle(),"value":"112"},
{"name":"喜剧","itemStyle":createRandomItemStyle(),"value":"100"},
{"name":"开心","itemStyle":createRandomItemStyle(),"value":"96"},
{"name":"沈腾","itemStyle":createRandomItemStyle(),"value":"92"},
{"name":"笑点","itemStyle":createRandomItemStyle(),"value":"92"},
{"name":"笑","itemStyle":createRandomItemStyle(),"value":"79"},
{"name":"真的","itemStyle":createRandomItemStyle(),"value":"50"},
{"name":"好笑","itemStyle":createRandomItemStyle(),"value":"49"},
{"name":"一部","itemStyle":createRandomItemStyle(),"value":"47"},
{"name":"故事","itemStyle":createRandomItemStyle(),"value":"47"},
{"name":"讽刺","itemStyle":createRandomItemStyle(),"value":"45"},
{"name":"太","itemStyle":createRandomItemStyle(),"value":"44"},
{"name":"尴尬","itemStyle":createRandomItemStyle(),"value":"40"},
{"name":"星","itemStyle":createRandomItemStyle(),"value":"39"},
{"name":"尬","itemStyle":createRandomItemStyle(),"value":"37"},
{"name":"夏洛特","itemStyle":createRandomItemStyle(),"value":"34"},
{"name":"观众","itemStyle":createRandomItemStyle(),"value":"33"},
{"name":"金钱","itemStyle":createRandomItemStyle(),"value":"33"},
{"name":"挺","itemStyle":createRandomItemStyle(),"value":"33"},
将结果复制到echats的在线页面显示即可
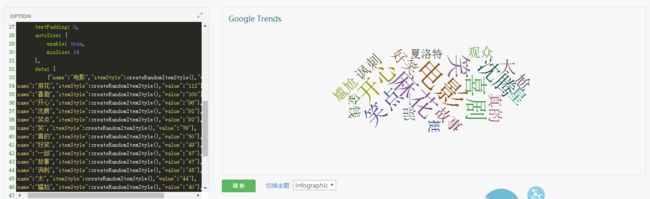
image.png