Pytorch学习记录-torchtext和Pytorch的实例2
0. PyTorch Seq2Seq项目介绍
在完成基本的torchtext之后,找到了这个教程,《基于Pytorch和torchtext来理解和实现seq2seq模型》。
这个项目主要包括了6个子项目
使用神经网络训练Seq2Seq- 使用RNN encoder-decoder训练短语表示用于统计机器翻译
- 使用共同学习完成NMT的堆砌和翻译
- 打包填充序列、掩码和推理
- 卷积Seq2Seq
- Transformer
2. 使用RNN encoder-decoder训练短语表示用于统计机器翻译
现在我们已经涵盖了基本的工作流程,这节教程将重点关注改进我们的结果。基于我们从前一个教程中获得的PyTorch和TorchText的知识,我们将介绍第二个第二个模型,它有助于Encoder-Decoder模型面临的信息压缩问题。该模型将基于使用用于统计机器翻译的RNN Encoder-Decoder的学习短语表示的实现,其使用GRU。
本节教程源自《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
2.1 介绍
这里回顾了上一节的通用Encoder-Decoder模型。
2.2 处理数据
数据处理和上次一样,同样适用torchtext和spacy
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import time
SEED=1234
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic=True
spacy_de=spacy.load('de')
spacy_en=spacy.load('en')
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC=Field(tokenize=tokenize_de,init_token='',eos_token='',lower=True)
TRG=Field(tokenize=tokenize_en,init_token='',eos_token='',lower=True)
train_data,valid_data,test_data=Multi30k.splits(exts=('.de','.en'),fields=(SRC,TRG))
print(vars(train_data.examples[11]))
{'src': ['vier', 'typen', ',', 'von', 'denen', 'drei', 'hüte', 'tragen', 'und', 'einer', 'nicht', ',', 'springen', 'oben', 'in', 'einem', 'treppenhaus', '.'], 'trg': ['four', 'guys', 'three', 'wearing', 'hats', 'one', 'not', 'are', 'jumping', 'at', 'the', 'top', 'of', 'a', 'staircase', '.']}
SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = torch.device('cpu')
BATCH_SIZE=128
train_iterator,valid_iterator,test_iterator=BucketIterator.splits(
(train_data,valid_data,test_data),
batch_size=BATCH_SIZE,
device=device
)
2.3 构建Seq2Seq模型
2.3.1 Encoder
Encoder与之前的模型类似,只是将LSTM换成了单层GRU,同时dropout也不在作为参数传入GRU中,因为在多层RNN的每一层之间使用了dropout。由于我们只有一个图层,如果我们尝试使用传入dropout值,PyTorch将显示一个警告。
另外,GRU要求的返回值只有隐藏状态,而不像LSTM那样还要求有单元状态。
接下来的部分和上一个模型很类似,使用卷积计算序列X的隐藏状态H,返回上下文向量z,。
这与一般seq2seq模型的Encoder相同,所有“魔法”都发生在GRU内(绿色方块)。
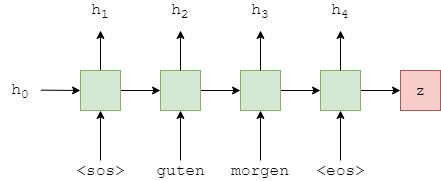
我们看一下实现的代码
class Encoder(nn.Module):
def __init__(self, input_dim,emb_dim,hid_dim,dropout):
super(Encoder,self).__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.hid_dim=hid_dim
self.dropout=dropout
self.embedding=nn.Embedding(input_dim,emb_dim)
self.rnn=nn.GRU(emb_dim, hid_dim)
self.dropout=nn.Dropout(dropout)
def forward(self, src):
#src = [src sent len, batch size]
embedded=self.dropout(self.embedding(src))
outputs, hidden=self.rnn(embedded)
#outputs = [src sent len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
return hidden
2.3.2 Decoder
Decoder与上一个模型有很大不同,减少了信息的压缩,GRU不仅获取目标token 、上一个隐藏状态 ,同时还有上下文向量z
注意这个z是没有t下标的,说明我们是在复用Encoder同一层返回的上下文状态(隐藏状态)。
预测使用linear处理当前token、、上下文向量z。
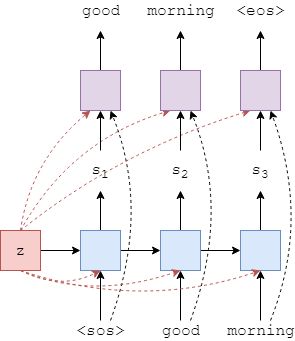
可以看到,本次的Decoder和之前的是有区别的。初始隐藏状态仍然是上下文向量,因此在生成第一个token时,我们实际上是在GRU中输入两个相同的上下文向量。
- 在实现的时候,通过将和串联传入GRU,所以输入的维度应该是emb_dim+ hid_dim
- linear层输入的是 和 串联,而隐藏状态和上下文向量都是维度相同,所以输入的维度是emb_dim+hid_dim*2
- forward现在需要一个上下文参数。在forward过程中,我们将和连接成emb_con,然后输入GRU,我们将,和连接在一起作为输出,然后通过线性层提供它以接收我们的预测, 。
这里使用torch.cat进行tensor拼接。
torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起。
class Decoder(nn.Module):
def __init__(self, output_dim,emb_dim,hid_dim,dropout):
super(Decoder,self).__init__()
self.output_dim=output_dim
self.emb_dim=emb_dim
self.hid_dim=hid_dim
self.dropout=dropout
self.embedding=nn.Embedding(output_dim,emb_dim)
self.rnn=nn.GRU(emb_dim+ hid_dim,hid_dim)
self.out=nn.Linear(emb_dim+hid_dim*2, output_dim)
self.dropout=nn.Dropout(dropout)
def forward(self, input, hidden, context):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#context = [n layers * n directions, batch size, hid dim]
#n layers and n directions in the decoder will both always be 1, therefore:
#hidden = [1, batch size, hid dim]
#context = [1, batch size, hid dim]
input =input.unsqueeze(0)
embedded=self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
emb_con = torch.cat((embedded, context), dim = 2)
#emb_con = [1, batch size, emb dim + hid dim]
output,hidden=self.rnn(emb_con,hidden)
output=torch.cat((embedded.squeeze(0), hidden.squeeze(0), context.squeeze(0)), dim = 1)
prediction=self.out(output)
return prediction,hidden
2.3.3 Seq2Seq
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq,self).__init__()
self.encoder=encoder
self.decoder=decoder
self.device=device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
def forward(self,src,trg,teacher_forcing_ratio=0.5):
#src = [src sent len, batch size]
#trg = [trg sent len, batch size]
batch_size=trg.shape[1]
max_len=trg.shape[0]
trg_vocab_size=self.decoder.output_dim
outputs=torch.zeros(max_len,batch_size,trg_vocab_size).to(self.device)
context=self.encoder(src)
hidden=context
input=trg[0,:]
for t in range(1,max_len):
output,hidden=self.decoder(input,hidden,context)
outputs[t]=output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.max(1)[1]
input = (trg[t] if teacher_force else top1)
return outputs
2.4 训练模型
和之前的训练一样
INPUT_DIM=len(SRC.vocab)
OUTPUT_DIM=len(TRG.vocab)
ENC_EMB_DIM=256
DEC_EMB_DIM=256
HID_DIM=512
ENC_DROPOUT=0.5
DEC_DROPOUT=0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, DEC_DROPOUT)
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = torch.device('cpu')
model=Seq2Seq(enc,dec,device).to(device)
def init_weights(m):
for name,param in m.named_parameters():
nn.init.normal_(param.data,mean=0,std=0.01)
model.apply(init_weights)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(7855, 256)
(rnn): GRU(256, 512)
(dropout): Dropout(p=0.5)
)
(decoder): Decoder(
(embedding): Embedding(5893, 256)
(rnn): GRU(768, 512)
(out): Linear(in_features=1280, out_features=5893, bias=True)
(dropout): Dropout(p=0.5)
)
)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 14,220,293 trainable parameters
optimizer=optim.Adam(model.parameters())
PAD_IDX=TRG.vocab.stoi['']
criterion=nn.CrossEntropyLoss(ignore_index=PAD_IDX)
# 构建训练循环和验证循环
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg sent len, batch size]
#output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
#trg = [(trg sent len - 1) * batch size]
#output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
print(loss.item())
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg sent len, batch size]
#output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
#trg = [(trg sent len - 1) * batch size]
#output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 1
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
很奇怪,昨天CUDA又好了,但是现在再用还是不行,怀疑是没有归零或是其他问题,现在换回CPU处理,奇慢无比。日了。
对pytorch做了版本降级,现在应该可以了,使用GPU跑了全程,每个epoch耗时在6分钟左右,而使用CPU的话一个epoch在32分钟左右,还是有明显提升,遇到的另一个问题,似乎显卡没有全功率运行……等会看看怎么设置一下。
这是运行结果
Epoch: 01 | Time: 5m 46s
Train Loss: 5.084 | Train PPL: 161.356
Val. Loss: 5.383 | Val. PPL: 217.769
Epoch: 02 | Time: 5m 44s
Train Loss: 4.439 | Train PPL: 84.671
Val. Loss: 5.256 | Val. PPL: 191.736
Epoch: 03 | Time: 5m 42s
Train Loss: 4.104 | Train PPL: 60.601
Val. Loss: 4.655 | Val. PPL: 105.062
Epoch: 04 | Time: 5m 44s
Train Loss: 3.749 | Train PPL: 42.493
Val. Loss: 4.265 | Val. PPL: 71.139
Epoch: 05 | Time: 5m 40s
Train Loss: 3.371 | Train PPL: 29.121
Val. Loss: 3.978 | Val. PPL: 53.397
。。。
Epoch: 10 | Time: 5m 42s
Train Loss: 2.118 | Train PPL: 8.312
Val. Loss: 3.552 | Val. PPL: 34.873
进一步加载保存的模型,使用测试集进行评估,差不多哈
model.load_state_dict(torch.load('tut2-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
# | Test Loss: 3.475 | Test PPL: 32.305 |