
Kaggle上发布过各种类型的数据科学比赛中,以forecast类型的比赛占比最大、单场参赛人数最多,是kaggle的金牌大户,其内容包括像预测某公司/产品未来几月的收入/销量、预测商品的目标人群、根据大数据评估预测用户的还贷风险等。
以今年的热门赛事为例,不管是创下单场参赛人数之最的Home Credit Default Risk,还是依旧进行中的Google Analytics Customer Revenue Prediction,去逛逛它们的kernels和discussion就会发现,参赛者使用的清一色都是gradient boost模型,如xgboost、GBM、lightGBM等,个别清新脱俗的会用Random Forest。大家拼的主要是DEA(Exploratory Data Analysis)和feature engineering而非模型。
这不禁让我疑惑,难道forecast类型问题只有机器学习一条路么?神经网络真的没有用武之地了么?
不是这样的。Cheng Guo和Felix Berkhahny在paper--Entity Embeddings of Categorical Variables中提到他们用一个identity embedding神经网络模型在kaggle Rossmann Store Sales比赛中取得第三名的成绩,Jeremy Howard的source code复现了这篇paper。我这篇博文就是要给你介绍这款神经网络,它只做了少量的feature engineering,就获得了惊人的效果。
Predict Future Sales / Notebook
Predict Future Sales,是kaggle上的playground比赛,是coursera上相关课程的最终大作业,如果你有兴趣也可以在项目介绍页面找到该课程。主办方提供俄罗斯1C玩具公司的销售数据,要求参赛者预测未来一个月商品的销售量。
我选择这个数据集的主要原因:
- 它是真实的数据集,训练样本数目庞大但信息量少,可以说是简约却不简单。
- 不需要做太多的feature engineering。
在开始分析神经网络之前,请你先到kaggle上熟悉比赛的data。
Setup
from fastai.structured import *
from fastai.column_data import *
我是用fastai library来构建训练模型的,所以需要import它们的libraries。
Data Cleaning
# https://www.kaggle.com/dlarionov/feature-engineering-xgboost
train = pd.read_csv(PATH/'sales_train.csv', low_memory=False)
test = pd.read_csv(PATH/'test.csv', low_memory=False).set_index('ID')
shops = pd.read_csv(PATH/'shops.csv', low_memory=False)
items = pd.read_csv(PATH/'items.csv', low_memory=False)
cats = pd.read_csv(PATH/'item_categories.csv', low_memory=False)
median = train[(train.shop_id==32)&(train.item_id==2973)&
(train.date_block_num==4)&(train.item_price>0)].item_price.median()
train.loc[train.item_price<0, 'item_price'] = median
# Якутск Орджоникидзе, 56
train.loc[train.shop_id == 0, 'shop_id'] = 57
test.loc[test.shop_id == 0, 'shop_id'] = 57
# Якутск ТЦ "Центральный"
train.loc[train.shop_id == 1, 'shop_id'] = 58
test.loc[test.shop_id == 1, 'shop_id'] = 58
# Жуковский ул. Чкалова 39м²
train.loc[train.shop_id == 10, 'shop_id'] = 11
test.loc[test.shop_id == 10, 'shop_id'] = 11
原始数据有些训练样本的数据有拼写错误、填写错误、某项数值远超平均值等问题,准备数据集的第一步就是修正这些错误、剔除某些噪声样本,这个过程称为data cleaning。对于此类structured data(图像、声音则是unstructured data),data cleaning尤为重要。
Feature Engineering
对于structure data类型的数据集,Feature engineering的重要程度甚至胜过机器学习模型,虽然我们的神经网络相比xgboost这类模型并不需要做太多feature engineering,但巧妇难为无米之炊,原始数据特征少的可怜,基本的特征处理还是必要的。这部分的代码量很大,不会全部贴出来,完整代码请查看notebook。

如Figure 1所示,有价值的只有item_price和item_cnt_day这两个feature,这里我主要用mean encoding方法,其基本思想是,围绕某个feature来创建新feature,例如:
recipies = [
(['date_block_num'], [('item_cnt_month', 'mean')]),
......
]
col_names = [
'date_avg_item_cnt', ......
]
matrix, _ = join_df_agg(matrix, matrix, recipies, col_names)
这部分代码就是对item_cnt_month做mean encoding:以date_block_num来分类,求每一类的所有item_cnt_month的均值,并将结果命名为date_avg_item_cnt。换句话说,就是根据每家店中每个商品每月的平均销量,计算出每个月份公司所有商品的平均销量。
mean encoding是一种简单实用甚至被滥用的技术,gradient boost模型往往会一上来就创建出几百甚至上千个feature,再通过feature的importance指标筛选出有价值的feature。好消息是,我们的神经网络模型并不需要做这么多:)。
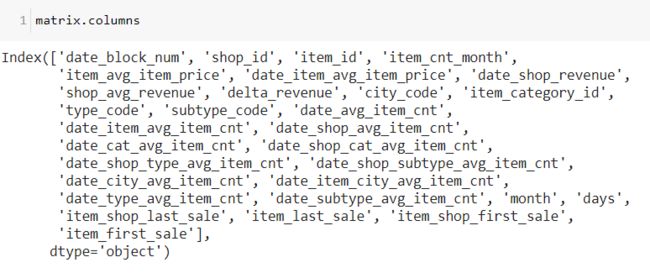
matrix.columns是feature engineering的结果。
cont_cols = list(trn_df.columns)
cat_cols = ['date_block_num', 'shop_id', 'item_id', 'city_code',
'item_category_id', 'type_code', 'subtype_code', 'month', 'days']
y_col = 'item_cnt_month'
skip_cols = []
for o in cat_cols + [y_col] + skip_cols:
cont_cols.remove(o)
Structured data分为:
- categorical data,如等级(低、中、高)、省/州、星期、月份等可分类的数据。
- continuous data,如销售量、客户数、单价金额等数值数据。
continuous data的数据类型是float或integer,而categorical data则通常被定义为one-hot encoding。殊不知one-hot encoding有两个弊端:
- one-hot encoding是稀疏编码,浪费内存。
- 更糟糕的是,one-hot code之间无法建立关联,例如星期六和星期日关联度比较高,但[0,0,0,0,0,1,0]和[0,0,0,0,0,0,1]却很难建立关联。
Embedding
Embedding可以完美地解决one-hot encoding的两个弊端。最典型的Embedding应用就是大名鼎鼎的word2vec,它是很经典NLP模型,它把单词(token)定义为长度为200~600的特征向量,向量的长度就是特征数,两个词如果词义相近的话,它们的向量也会相近,反之依然。

假设word2vec创建的词典如Figure 2所示,每个单词定义为一个长度为300的特征向量,向量的特征可能是gender、age、food等,可以看到的是man和woman两向量的值相近,apple和orange的值相近,在food这个维度,man/woman和apple/orange相差很大。
如果把word2vec的特征向量应用到categorical data,categorical data不再用没有关联的identity matrix表示,而是定义成embedding matrix,就可以根据向量间的亲疏远近找到categorical data的内在关联。
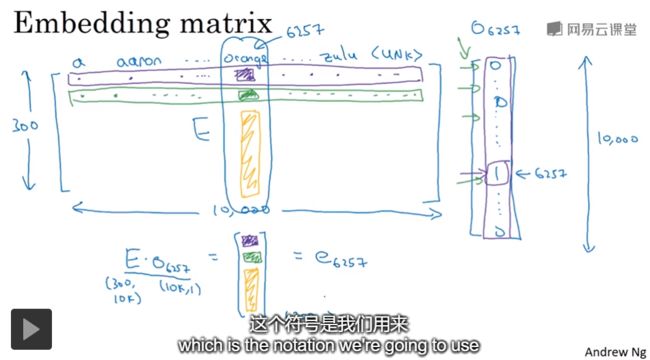
图Figure 3表示,如何从embedding matrix中取出一个向量,方法是将其乘以one-hot向量。前文已经分析了,one-hot code的稀疏性会造成内存浪费。其实从编程角度上看,只要给定一个index(Figure 3中index是6257),就可以取出相应index列的向量,并不需要将矩阵乘以一个长度10000的向量,造成无谓的计算和存储浪费。
实际上,embedding模型就是这样做的,将矩阵运算问题转化为根据下标直接提取向量,只保留one-hot向量的小标,将一个matrix转换成一个vector。

对于回归模型来说,一个mini-batch就是一个input向量,Figure 5就是continuous data和categorical data在向量中的结构,黄色和绿色框定的是continuous data,它们直接从dataset赋值到input向量。蓝色框中是categorical data,是Figure 4所示的index向量,向量每个元素指向embeddding matrix中的一个column,也就是相应的特征向量。

Model
Pytorch已经帮我们定义了实现了embedding matrix模型, 即nn.Embedding()。 md.get_learner()会调用MixedInputModel()创建continuous和categorical data混合的神经网络。nn.Embedding(c, s)中的c代表row size,s表示feature size。
class MixedInputModel(nn.Module):
......
self.embs = nn.ModuleList([nn.Embedding(c, s) for c,s in emb_szs])
......
emb_drop = 0.04 * 2
szs = [1000, 500]
ps = np.array([0.25, 0.5])
learn = md.get_learner(emb_szs, len(cont_cols), emb_drop, 1, szs=szs, drops=ps, y_range=(0, 20))
emb_szs定义了所有embedding matrix的shape,它的rows当然就是data的个数,例如表示week的matrix,rows == 7。然而feature的长度又有什么决定的呢?Figure 3中, 特征向量的长度是300,因为文字是非常复杂的,必须为它的学习提供大量的神经元,但在本例中,我们并不需要创造如此庞大的matrix,因为这很容易发生过拟合,这里我的设定是, features = rows // 2 && features <= 80,这是实战有效的经验,如果模型大量underfitting,可以适时增加feature size。
cat_sz = [(o, len(trn_df[o].cat.categories) + 1) for o in cat_cols]
emb_szs = [(o, min(50, o // 2)) for _, o in cat_sz]
emb_szs
[(35, 17),
(58, 29),
(21807, 80),
(32, 16),
(85, 42),
(21, 10),
(66, 33),
(13, 6),
(4, 2)]
Training
df_trn, y, nas, mapper = proc_df(trn_df, 'item_cnt_month', skip_flds=skip_cols, do_scale=True)
proc_df()的主要作用是对dataset做normalization,这对神经网络来说非常重要。mapper是normalize用到的均值、标准差等系数,如果有test_df,需要使用与train_set一致的normalization系数,即mapper。本例并没有创建test_df。
train_ratio = 0.75
train_size = int(n * train_ratio)
val_idxs = list(range(train_size, n))
len(val_idxs), np.array(val_idxs)
因为是要预测未来,time series forecast项目对validation set的选择不能选取任意训练样本,这里我选取25%最新时间的数据作为validation set。
bs = 256
md = ColumnarModelData.from_data_frame(PATH, val_idxs, df_trn, y.astype('float32'), cat_cols, bs=bs)
learn = md.get_learner(emb_szs, len(cont_cols), emb_drop, 1, szs=szs, drops=ps, y_range=(0, 20))
lr = 1e-3
learn.fit(lr, 1)
epoch trn_loss val_loss
0 0.723625 0.677875
learn.fit(lr / 3, 3)
epoch trn_loss val_loss
0 0.604653 0.634174
1 0.621239 0.638807
2 0.62528 0.631941
可以看到只需要少量训练,模型就收敛了,模型效果如何呢?
learn.crit
np.sqrt(0.631941)
0.79494716805584
神经网络的loss function就是MSE,本项目的metrics是RMSE,所以,对loss值求根就是metrics,即np.sqrt(0.631941) == 0.7949。0.7949能得到个什么成绩呢,我们来看kaggle的LB。
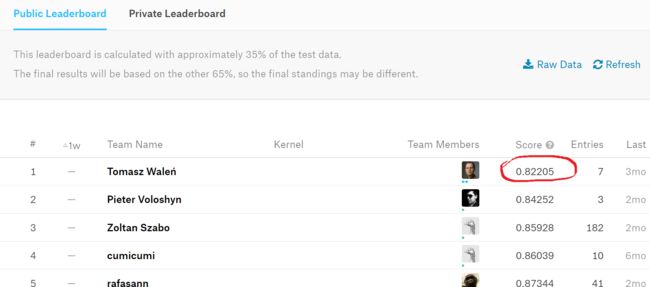
可以看到,public LB的第一名的score也不过是0.82205!
如果看到这里你开始跃跃欲试准备要拿这个模型去冲级冠军的话,那你先等等。还记得test.csv的样子吗,它和其他比赛最大的不同是:需要你自己创建一个未来的test_set,难点也在于此。你要构建下一个月的test_set,但下一个月的数据从哪里来?我们做feature engineering的基础的是item_price和item_cnt_day,这两个值怎么模拟?是最近三个月的均值?最近半年的均值?要不要考虑sale trend? 我们要预测的是下一个月的数据,如果test_set不像它该有的数据分布,那public LB socre就会比我们本地的score低。
LB Score Vs Native Score
参加kaggle比赛过程中会不断地提交结果得到public LB的score反馈,很多时候public LB score和我们自己验证的score差距还不小,那是不是说kaggle public LB比我们自己的validation set更可靠呢? 答案是否定的。

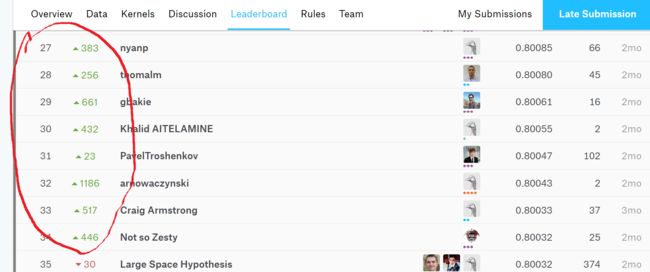
以 Home Credit Default Risk为例,kaggle的LB分为public LB和private LB两种,一般情况下public LB只验证test set中一小部分,大部分的test set在private LB,它是比赛结束时最终的test set。可以看到上图红色圈定的几个名次,最左侧的数字的是他们的最终排名,旁边绿色上升箭头的数字代表他们从public LB切换到private LB上升的排名,他们都提升了几百名,尤其是32名,他提升1186名!
为什么会这样?! 因为Home Credit Default Risk的public LB只含有20%的test set,其他80%的test set都在private LB。那个排名32位的哥们,如果他相信public LB socre,那他就是1000多名,而实际上它自己的validation set告诉他他应该是32名!
回到Predict Future Sales,它的public LB也只占test set的35%,这个比赛因为是教学作业,是不会结束的,也就是永远不会有用到private LB的那天,这也是我在本例不涉及test set的原因。而我在本例为validation set划分了高达25%的训练数据集,相比public LB,我更相信validation set的评估能力。
总结
利用embedding matrix构建的神经网络模型在structured dataset也有很好的表现,相比gradient boost模型,它只需要做少量的feature engineering。embedding完美解决了one-hot encoding的两个弊端,其最经典的应用就是word2vec模型。在kaggle比赛中,public LB并不能代替自己validation set。
References
- Entity Embeddings of Categorical Variables
- Feature engineering, xgboost
- https://github.com/alexshuang/predict_future_sales/blob/master/Predict_Future_Sale.ipynb
- https://github.com/fastai/fastai/blob/master/courses/dl1/lesson3-rossman.ipynb