【语义分割文献阅读】Segmentation from Natural Language Expressions
【语义分割文献阅读】Segmentation from Natural Language Expressions
文章目录
- 【语义分割文献阅读】Segmentation from Natural Language Expressions
-
- Abstract
- 1 Introduction
- 2 Related work
-
-
- Localizing objects with natural language
- Fully convolutional network for segmentation
- Attention and visual question answering
-
- 3 Our model
-
- 3.1 Spatial feature map extraction
- 3.2 Encoding expressions with LSTM network
- 3.3 Spatial classification and upsampling 空间分类和上采样
- 4 Experiments
-
- 4.1 Baseline methods
-
- Combination of per-word segmentation
- Foreground segmentation from bounding boxes.
- Classification over segmentation proposals
- Whole image
- 4.2 Evaluation on ReferIt dataset
-
- Results
- Speed
- Conclusion
- Acknowledgments
Abstract
本文探讨了一个基于自然语言表达的图像分割新问题。这不同于在一组预定义的语义类别上的传统语义分割,例如,短语“坐在右边长凳上的两个人”需要只分割坐在右边长凳上的两个人,而没有人站在或坐在另一个长凳上。以前适用于此任务的方法仅限于一组固定的类别和/或矩形区域。为了对语言表达进行像素化分割,我们提出了一个端到端的可训练递归和卷积网络模型,该模型可以联合学习处理视觉和语言信息。在我们的模型中,递归LSTM网络用于将参考表达式编码为矢量表示,而完全卷积网络用于从图像中提取空间特征图并输出目标对象的空间响应图。在一个基准数据集上,我们证明了我们的模型可以从自然语言表达式中产生高质量的分割输出,并且在很大程度上优于基线方法。
1 Introduction
语义图像分割是计算机视觉中的一个核心问题,基于卷积神经网络[1,2,3,4,5,6]的大规模视觉数据集和丰富的表示方法已经取得了重大进展。虽然这些现有的分割方法可以为“train”或“cat”等查询类别预测精确的像素级掩码,但它们不能为更复杂的查询预测分割,例如自然语言表达式“汽车右侧穿着黑色衬衫的两个人”。在本文中,我们解决了以下问题:给定一幅图像和一个描述图像某一部分的自然语言表达式,我们希望分割覆盖该表达式所描述的视觉实体的相应区域。 例如,如图1 (d)所示,对于短语“穿蓝色外套的人”,我们希望预测一个包括中间穿着蓝色外套的两个人,但不包括其他两个人的分割。这个问题与语义分割的核心计算机视觉问题相关但不同(例如PASCAL VOC对20个对象类的分割挑战[7]),其涉及预测预定义的一组对象或素材类别的像素化标签(图1,b),以及实例分割(例如[8]),其另外区分对象类的不同实例(图1,c)。它也不同于与语言无关的前景分割(例如[9]),后者的目标是在前景(或最显著的)对象上生成遮罩。本文的目标不是像在语义图像分割中那样为图像中的每个像素分配语义标签,而是基于给定的表达式为感兴趣的视觉实体产生分割掩模。自然语言描述不是固定在一组对象和材料类别上,还可能涉及诸如“黑色”和“平滑”等属性、诸如“奔跑”等动作、诸如“右边”等空间关系以及诸如“骑马的人”等不同视觉实体之间的交互。

从自然语言表达式中分割图像的任务有着广泛的应用,例如建立基于语言的人机界面,向机器人发出“拿起苹果旁边桌子上的罐子”等指令。在这里,能够使用多词引用表达式来区分不同的对象实例是很重要的,但与仅使用边界框相比,获得精确的分割也很重要,尤其是对于非网格对齐的对象(例如,参见图2)。这对于交互式照片编辑来说也很有意思,在交互式照片编辑中,人们可以用自然语言来指代要处理的图像的某些部分或对象,例如“模糊穿红色衬衫的人”,或者参考你的一餐的某些部分来估计他们的营养,“两大块培根”,以更好地决定是否应该吃它,而不是像[10]中那样吃一顿饱饭。
如第2节中更详细的描述,适用于此任务的现有方法被限制为仅解析图像中的边界框[11,12,13],和/或被限制为先验确定的固定类别集[1,3,4,6]。在本文中,我们提出了一个端到端的可训练递归卷积网络模型,该模型联合学习处理视觉和语言信息,并为自然语言表达式描述的目标图像区域产生分割输出,如图2所示。我们通过递归LSTM网络将表达式编码成固定长度的向量表示,并使用卷积网络从图像中提取空间特征图。编码的表达式和特征图然后由多层分类器网络以完全卷积的方式进行处理,以产生粗响应图,该粗响应图用反卷积[1,5]进行上采样,以获得目标图像区域的像素级分割掩模。在基准数据集上的实验结果表明,我们的模型能够从自然语言表达式中生成高质量的分割预测,并且显著优于基线方法。我们的模型是使用标准反向传播进行训练的,并且在测试时比以前依赖于对每个边界框进行评分的方法更有效。

2 Related work
我们的工作涉及以下几个方面。
Localizing objects with natural language
用自然语言定位对象。我们的工作与最近关于自然语言的对象定位的工作有关,其中的任务是根据自然语言描述定位场景中的目标对象(通过在其上画一个边界框)。在[11]和[13]中报道的方法建立在图像字幕框架如LRCN [14]或mRNN [15]的基础上,并且通过选择表达式具有最高概率的边界框来定位对象。 我们的模型不同于[11]和[13],因为我们不必学习从图像区域生成表达式。在[12]中,作者提出了一个模型,通过关注短语能够被最好地重构的区域来定位文本短语。在[16]中,利用典型相关分析(CCA)学习视觉特征和单词的联合嵌入空间,给定一个自然语言查询,通过在联合嵌入空间中寻找与文本序列最近的区域来定位对应的目标对象。
据我们所知,所有这些先前的定位方法只能返回目标对象的边界框,并且先前的工作没有学会直接输出给定自然语言描述的对象的分割掩码作为查询。 作为比较,在第4.1节中,我们还评估了在[11]和[12]的边界框预测上使用前景分割。
Fully convolutional network for segmentation
语义分割的全卷积网络。完全卷积网络是仅由卷积(和汇集)层组成的卷积神经网络,是在一组预定义的语义类别[1,3,4,6]上进行语义分割的最新方法。完全卷积网络的一个很好的特性是空间信息保留在输出中,这使得这些网络适合需要空间网格输出的分割任务。 在我们的模型中,特征提取和分割输出都是通过完全卷积网络实现的。在第4.1节中,我们还使用全卷积网络作为每字切分的基线。
Attention and visual question answering
注意力和视觉问答。最近,注意力模型已经被用于包括图像识别、图像字幕和视觉问题回答在内的几个领域。在[17]中,通过聚焦于每个单词的特定图像区域来生成图像标题。在最近的视觉问题回答模型[18,19]中,通过关注一个或多个图像区域来确定答案。[20]的作者提出了一种可视化的问答方法,通过对句子进行解析,为“黑”和“猫”生成注意图,可以学会回答“黑猫在哪里”等对象参考问题。
这些注意力模型与我们的工作相关,因为它们也学习生成空间网格“注意力地图”,这些地图通常覆盖感兴趣的对象。然而,这些注意力模型不同于我们的工作,因为它们只学习生成粗略的空间输出,并且注意力图的目的是促进其他任务,例如图像字幕,而不是精确地分割出对象。
3 Our model
给定一个图像和一个自然语言表达式作为查询,目标是为表达式描述的视觉实体输出一个分割掩码。 这个问题需要对图像和表达的视觉和语言理解。为了实现这一目标,我们提出了一个具有三个主要组成部分的模型:基于递归LSTM网络的自然语言表达式编码器,提取局部图像描述符并生成空间特征图的全卷积网络,以及将编码表达式和空间特征图作为输入并输出像素级分割掩码的全卷积分类和上采样网络。 图3显示了我们的方法的概要;我们在第3.1、3.2和3.3节中介绍了这些组件的细节。用于特征图提取和分类的网络体系结构类似于FCN模型[1],该模型已被证明对于语义图像分割是有效的。
与相关工作[11,13]相比,我们没有明确地产生对应于给定视觉表示的对象描述的单词序列,因为我们感兴趣的是从表达预测图像分割,而不是预测表达。这样,与[11,13]相比,我们的模型具有更少的参数,因为它不必学习预测下一个单词,这可能是一项艰巨的任务。
3.1 Spatial feature map extraction
给定场景的图像,我们希望获得它的区别特征表示,同时保留表示中的空间信息,以便更容易预测空间分割掩模。这是通过类似于FCN-32s [1]的完全卷积网络模型实现的,其中图像通过一系列卷积(和汇集)层馈送,以获得作为特征表示的空间地图输出。给定大小为W × H的输入图像,我们在图像上使用卷积网络来获得w × h的空间特征图,特征图上的每个位置包含 D i m D_{im} Dim通道(Dimcdimensional local descriptor)。
对于特征地图上的每个空间位置,我们对该位置的二维局部描述符应用L2归一化,以便获得更鲁棒的特征表示。这样,我们可以提取一个 w × h × D i m w × h × D_{im} w×h×Dim的空间特征图作为每幅图像的表示。
此外,为了允许模型推理空间关系,例如图3中的“合适的女人”,向特征地图添加了两个额外的通道:每个空间位置的x和y坐标。我们使用相对坐标,其中要素地图的左上角和右下角分别表示为(1,1)和(+1,+1)。这样,我们获得了包含局部图像描述符和空间坐标的 w × h × ( D i m + 2 ) w × h × (D_{im}+2) w×h×(Dim+2)表示。
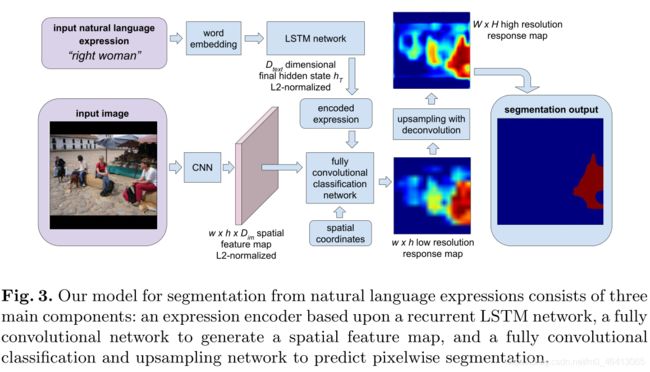
在我们的实现中,我们采用VGG-16体系结构[21]作为我们的完全卷积网络,将fc6、fc7和fc8视为卷积层,输出 D i m D_{im} Dim= 1000维局部描述符。生成的要素图大小为w = W/s,h = H/s,其中s = 32是fc8图层输出上的像素跨度。空间特征地图上的单元具有384像素的非常大的感受野,因此我们的方法具有聚集来自附近区域的上下文信息的潜力,这可以帮助推断视觉实体之间的交互 ,例如“桌子旁边的人”。
3.2 Encoding expressions with LSTM network
对于描述图像区域的输入自然语言表达式,我们希望将文本序列表示为向量,因为处理固定长度的向量比处理可变长度的序列更容易。为了实现这一目标,我们采用了编码器的方法,依次对学习方法进行排序[22,23]。在我们的自然语言表达编码器中,我们首先通过一个单词嵌入矩阵将每个单词嵌入到一个向量中,然后使用一个具有离散隐藏状态的递归长短期记忆(LSTM) [24]网络来扫描嵌入的单词序列。对于文本序列S = (w1,…wn)在每个时间步长T,LSTM网络将来自单词嵌入矩阵的嵌入单词向量作为输入。在LSTM网络已经看到整个文本序列之后的最后时间步t = T,我们使用LSTM网络中的隐藏状态作为表达式的编码向量表示。 类似于第3.1节,我们还对hT中的数据维度进行了L2归一化。在我们的实现中,我们使用了一个LSTM网络,它的隐态为1000维。
3.3 Spatial classification and upsampling 空间分类和上采样
在从第3.1节中的图像和第3.2节中的编码表达式提取空间特征图之后,我们想要确定特征图上的每个空间位置是否属于前景(由自然语言表达式描述的视觉实体)。在我们的模型中,这是由局部图像描述符和编码表达式上的完全卷积分类器完成的。我们首先平铺并连接空间网格中每个空间位置的本地描述符,以获得包含视觉和语言特征的 w × h × D ∑ ( 其 中 D ∑ = D i m + D t e x t + 2 ) w×h×D∑(其中D∑= D_{im}+D_{text}+2) w×h×D∑(其中D∑=Dim+Dtext+2)空间地图。然后,我们训练一个两层分类网络,其中有一个二维隐藏层,该隐藏层在输入时采用D∫维表示,并输出一个分数来指示一个空间位置是否属于目标图像区域。 我们在实现中使用 D c l s D_{cls} Dcls= 500。
该分类网络以完全卷积的方式应用于底层w×h特征映射,作为两个1×1卷积层(它们之间的ReLU不呈线性)。全卷积分类网络输出一个包含分类分数的w ×h粗低分辨率响应图,可以看作是参考表达式的低分辨率分段,如图3所示。
为了获得更高分辨率的分割掩模,我们通过反卷积(交换卷积运算的前向和后向过程)[1,5]进一步执行上采样。这里我们使用一个2s × 2s反卷积滤波器,其步长为s(其中s = 32,适用于我们使用的VGG-16网络架构),类似于FCN-32s模型[1]。反卷积操作产生与输入图像具有相同大小的W ×H高分辨率响应图,并且高分辨率响应图上的值表示像素是否属于目标对象的置信度。我们使用像素分类结果(即响应图上的值是否大于0)作为最终的分割预测
在训练时,我们训练集中的每个训练实例都是一个元组(I,S,M),其中I是一个图像,S是描述该图像中一个区域的自然语言表达式,M是该区域的二进制分割掩码。训练期间的损失函数定义为像素级损失的平均值

其中,W和H是图像宽度和高度,vijis是高分辨率响应图上的响应值(分数),Mijis是像素(I,j)处的二进制地面真实标签。l是每像素加权逻辑回归损失,如下所示
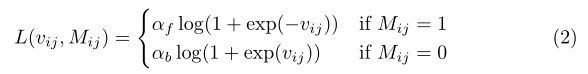
其中αf和α表示前景和背景像素的损失权重。在实践中,我们发现对前景像素使用更高的损失权重训练收敛得更快,并且我们在 L ( v i j , M i j ) L(v_{ij},M_{ij}) L(vij,Mij)中使用 α f = 3 和 α b = 1 α_f= 3和α_b= 1 αf=3和αb=1。特征图提取网络中的参数从1000级ILSVRC分类任务[25]中预处理的VGG-16网络[21]初始化,用于上采样的反卷积滤波器从双线性插值初始化。我们模型中的所有其他参数,包括单词嵌入矩阵、LSTM参数和分类器参数,都是随机初始化的。整个网络使用带动量的SGD进行标准反向传播训练。
4 Experiments
与PASCAL VOC [7]等图像分割中广泛使用的数据集相比,只有少数公开可用的数据集在分割后的图像区域上带有自然语言注释。在我们的实验中,我们在参考数据集[26]上用视觉实体的自然语言描述和它们的分割掩码来训练和测试我们的方法。参考数据集[26]建立在IAPR TC-12数据集[27]的基础上,有20,000幅图像。在96,654个分割的图像区域上注释有130,525个表达式(一些区域用多个表达式注释)。在这个数据集中,地面真实分割来自SAIPR-12数据集[28]。参考数据集中的表达式对区域是有区别的,因为它们是在一个两人游戏中收集的,该游戏的目标是通过表达式使目标区域容易与图像的其余部分区分开来。在撰写本文时,参考数据集[26]是最大的公开可用的数据集,它包含在分割图像区域上注释的自然语言表达式。
在这个数据集上,我们使用与[11,12]中相同的训练值和测试分割。有10000张图片用于训练和验证,10000张图片用于测试。引用数据集中带注释的区域既包含“对象”区域,如汽车、人和瓶子,也包含“素材”区域,如天空、河流和山脉。
虽然[13]还收集了一个单独的Google-RefExp数据集,该数据集包含带有可从MS COCO数据集注释获得的分段区域的自然语言表达式[29],但该数据集仅包含来自COCO中80个对象类别的对象注释,并且不包含“填充”区域,如雪。
因为据我们所知,还没有直接学习基于自然语言表达式预测分割的前期工作,为了评估我们的方法,我们构建了几个强基线方法,如第4.1节所述,并将我们的方法与这些方法进行比较。
4.1 Baseline methods
Combination of per-word segmentation
在该基线方法中,不是首先用递归LSTM网络编码整个表达式,而是单独分割表达式中的每个单词,然后组合每个单词的分割结果以获得最终的预测。 这种方法可以看作是用一个“词袋”来表示表达式。我们在参考数据集中选取N个最常出现的单词(在手动删除一些停止词如“the”和“towards”)并训练一个FCN模型[1]来分割每个单词。类似于PASCAL VOC分词挑战[7],在这种方法中,每个单词都被视为一个独立的语义类别。然而,与PASCAL VOC分割不同,这里一个像素可以同时属于多个类别(单词),因此具有多个标签。在训练过程中,我们为训练集中的每个训练样本(一个图像和一个表达式)生成一个每个单词的像素化标签图。对于一个给定的表达式,相应的前景像素用一个N维二进制向量l来标记,其中li= 1当且仅当单词I出现在表达式中,背景像素用等于全零的l来标记。在我们的实验中,我们使用N = 500,并从PASCAL VOC 2011分段任务[1]中预处理的FCN-32s网络初始化网络,并用单词上的多标签逻辑回归损失训练整个网络。
在测试时,给定图像和自然语言表达式作为输入,网络输出N个单词的像素级分数图,并且进一步组合每个单词的分数以获得输入表达式的分段。在我们的实现中,我们实验了三种不同的方法来组合每个单词的分割:对于那些出现在表达式中的单词(在N个单词列表中),我们
a)取它们的分数的平均值
b)取它们预测的交集
c)取它们预测的并集。
在一些罕见的情况下(2.83%的测试样本),表达式中没有一个单词在N最常见的词,我们不输出该表达式的任何分割,即所有像素都被预测为背景。
Foreground segmentation from bounding boxes.
在这种基线方法中,我们首先使用基于自然语言输入的定位方法[11,12]来获得给定表达式的包围盒定位,然后使用GrabCut [9]从包围盒中提取前景分割。给定图像和自然语言表达式,我们使用最近提出的两种方法SCRC [11]和基勒[12]从图像和表达式获得包围盒预测。在SCRC [11]中,作者使用了一个改编自图像字幕的模型,并通过找到表达式接收概率最高的候选包围盒来定位参考表达式。在GroundeR [12]中,候选包围盒上的注意力模型被用于以无监督的方式通过找到能够最好地重建表达式的区域来对参考表达式进行基础(定位),或者以有监督的方式直接训练模型来关注最佳包围盒。在[11,12]之后,我们使用100个得分最高的边界框[30]作为每个图像的一组候选边界框。在测试时,给定一个输入表达式,我们使用SCRC [11]或基勒[12]计算100个边界框建议的得分,并评估两种方法:要么使用得分最高的边界框的整个矩形区域,要么使用GrabCut [9]从中分割前景。我们在实验中使用了[12]的监督版本。
Classification over segmentation proposals
在这种基线方法中,我们首先使用MCG [31]提取一组候选分割建议,然后训练二进制分类器来确定候选分割建议是否与表达式匹配。在这个基线中,我们使用了与监督版本[12]相似的管道。首先,从每个建议中提取视觉特征,并与编码句子连接。然后,在级联特征上训练分类网络,以将分割建议分类为前景或背景。我们使用来自MCG的100个得分最高的分割建议,并通过首先将其大小调整到224 × 224(分割区域之外的那些像素用通道平均值填充)来从每个分割中提取视觉特征,然后使用在ILSVRC分类任务上预处理的VGG-16网络从调整后的分割中提取视觉特征。然后对整个网络进行端到端的培训。该基线和我们的方法之间的主要区别在于,我们的方法通过完全卷积网络执行像素分类,而该基线需要另一种建议方法来获得候选区域。
Whole image
作为一个额外的琐碎基线,我们还评估使用整个图像作为每个表达式的分割。
4.2 Evaluation on ReferIt dataset
我们在参考数据集[26]中的10,000个训练图像上训练我们的模型和第4.1节中的基线方法(留出一小部分用于验证),遵循与[11]中相同的分割。在我们的实现中,我们将所有图像和地面真实分割调整大小并填充到固定大小W × H(其中我们设置W = H = 512),保持它们的纵横比并用零填充外部区域,并将分割输出映射回原始图像大小以获得最终分割。
在我们的实验中,我们使用两阶段训练策略:我们首先训练我们模型的低分辨率版本,然后从中微调以获得最终的高分辨率模型(即图3中的完整模型)。在我们的低分辨率版本中,我们没有在第3.3节中添加反卷积滤波器,因此该模型仅输出图3中的w×h = 16×16粗响应图。我们还将地面真值标签下采样到w × h,并直接在粗响应图上训练以匹配下采样的标签。在训练低分辨率模型后,我们通过添加一个步长为s = 32的2s × 2s反卷积滤波器来构建最终的高分辨率模型,如第3.3节所述,并通过双线性插值来初始化滤波器权重(所有其他参数都从低分辨率模型初始化)。然后,在训练集上使用W × H地面真实分割掩码标签对高分辨率模型进行微调。我们根据经验发现,这两个阶段的训练比直接训练我们的完整模型来预测高分辨率分割更快收敛。
我们在测试集中的10,000幅图像上评估了我们的模型和第4.1节中的基线方法的性能。以下两个指标用于评估:整体交-并(IoU)指标和精度指标。总IoU是总相交面积除以总并集面积,其中相交面积和并集面积都是在所有测试样本上累积的(每个测试样本是一个图像和一个参考表达式)。虽然整体IoU指标是PASCAL VOC分割[11]中使用的标准指标,但我们的评估略有不同,因为我们希望衡量模型在背景下分割输入表达式描述的前景区域的准确性,而整体IoU指标有利于天空和地面等大区域。因此,我们还用精度指标从易到难对5个不同的IoU阈值进行评估:0.5、0.6、0.7、0.8、0.9。精度指标是预测值和地面真实值之间的IoU超过阈值的测试样本的百分比。例如,[email protected]是预测分割与基础真实区域重叠至少50% IoU的表达式的百分比。
Results
表1总结了我们评估的主要结果。只需返回整个图像,就已经获得了15%的整体IoU。这部分是由于ReferIt数据集包含一些大区域,如“天空”和“城市”,并且整体IoU指标对大区域赋予了更多权重。但是不出所料,整个图像基线的精度最低。

从表1可以看出,通过对每个单词的分割并结合每个单词的结果,可以得到一个合理的整体IoU。在第4.1节中三种不同的组合每个单词结果的方法中,平均每个单词的分数效果最好。使用来自SCRC[11] (“SCRC bbox” ) 或接地器[12] (“接地器bbox”)的整个包围盒预测获得了与平均每个单词分割相当的精度,而它们在整体IoU方面更差,并且使用来自MCG的分割建议的分类(“MCG分类”)导致比这两种方法稍高的精度。此外,可以看到,与使用整个边界框区域相比,使用GrabCut [9]从边界框中分割前景(“SCRC grabcut”和“地滚球GrabCut”)对SCRC和地滚球都产生了更高的精度。我们认为精度度量更能反映自然语言表达式分割方法的性能,因为在实际应用中,人们通常更关心参考表达式被正确分割的频率。
在精度度量和整体IoU度量下,我们的模型在很大程度上优于所有基线方法。在表1中,倒数第二行(“低分辨率”)对应于在来自我们的低分辨率模型的粗略响应图上直接使用双线性上采样,而最后一行(“高分辨率”)显示了我们的完整模型的性能。可以看出,与基线方法相比,我们的最终模型获得了显著更高的精度和整体IoU。图4显示了使用我们的模型和基线方法的一些分割例子。

引用数据集包含对象区域和填充区域。对象是那些具有明确定义的结构和封闭边界的实体,如人、狗和飞机,而东西是那些没有固定结构的实体,如天空、河流、道路和雪。尽管存在这种差异,但对象区域和填充区域都可以通过我们的模型使用相同的方法进行分割。图5显示了我们模型中对象区域的一些分割例子
图6显示了填充区域的例子。
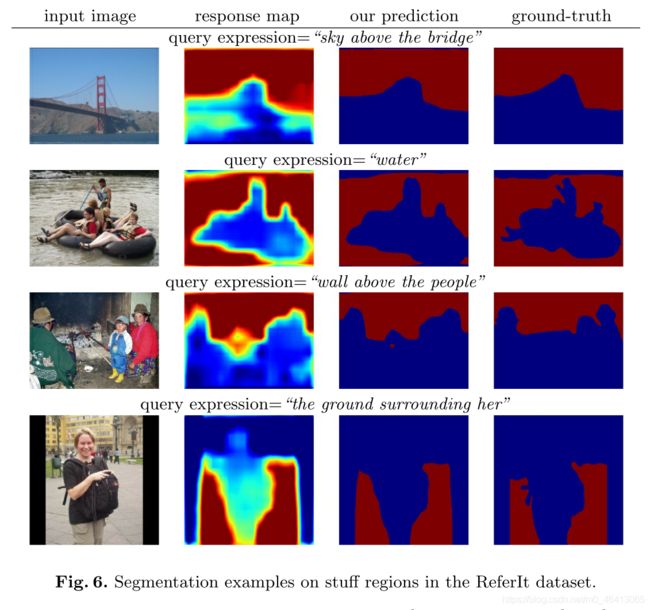
可以看出,我们的模型可以为“左边的鸟”这样的对象表达式和“桥上的天空”这样的填充表达式预测合理的分割。
图8显示了同一张图片上不同引用表达式的一些例子。
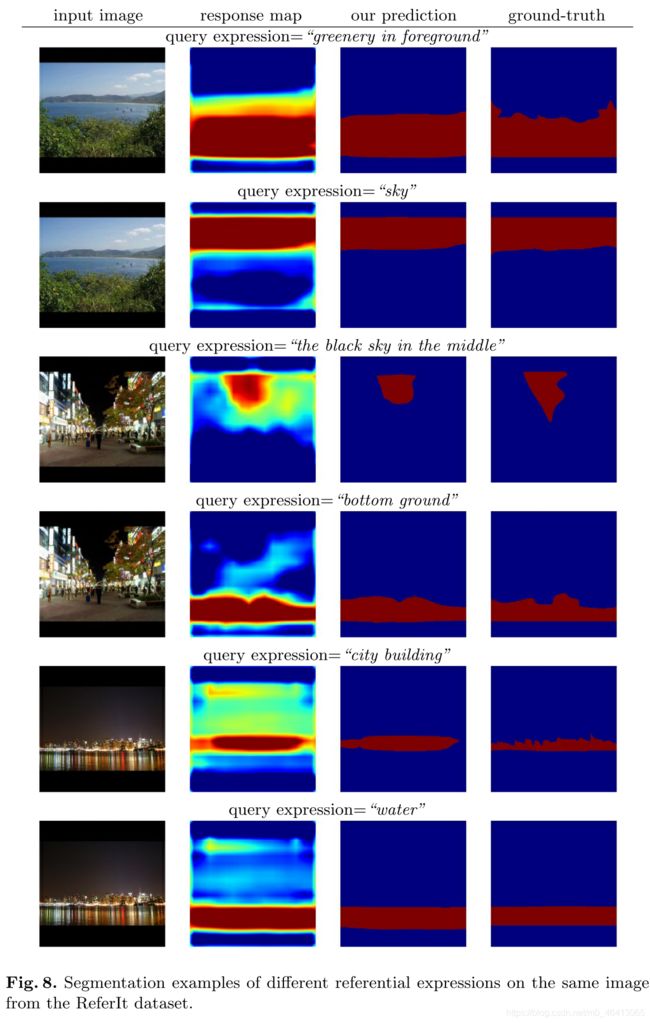
图9和图10显示了更多关于对象和填充区域的分割示例。
图7显示了参考数据集上的一些失败案例,其中预测和基础事实分割之间的IoU小于50%。在一些失败的情况下(例如图7,中间),我们的模型产生了合理的响应图,覆盖了自然语言引用表达式的目标区域,但是不能精确地分割出对象或事物的边界。
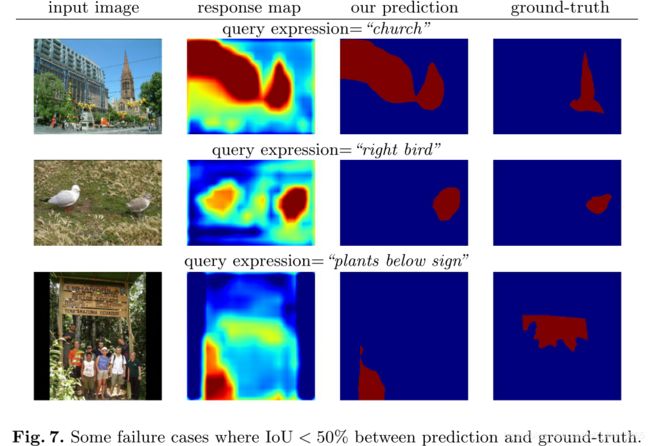
图11显示了更多的失败案例。

Speed
我们还比较了我们的方法和基线方法的速度。表2显示了在一台带有NVIDIA特斯拉K40 GPU的机器上,不同模型在测试时预测分段的平均时间消耗。可以看出,虽然我们的方法比每个词的切分基线慢,但它比基于建议的方法(如“SCRC grabcut”或“MCG分类”)快得多。

Conclusion
在本文中,我们解决了分割自然语言表达式的挑战性问题,以生成参考表达式所描述的图像区域的像素化分割输出。为了解决这个问题,我们提出了一个端到端的可训练递归卷积神经网络模型,将表达式编码为向量表示,从图像中提取空间特征映射表示,并基于完全卷积分类器和上采样输出像素化分割。 我们的模型可以有效地预测描述单个或多个对象或事物的引用表达式的分割输出。在基准数据集上的实验结果表明,我们的模型比基线方法有很大的优势。
Acknowledgments
作者感谢丽莎·亨德里克斯和马塞尔·西蒙对草稿的反馈。这项工作得到了美国国防高级研究计划局、AFRL、美国国防部MURI奖第000141110688号、美国国家科学基金会奖第1427425号和第1212798号以及伯克利视觉和学习中心的支持。马库斯·罗尔巴赫获得了德国学术交流服务(DAAD)惠誉国际项目的奖学金。