JumpServer单节点Prometheus监控并告警
JumpServer单节点Prometheus监控并告警
一、基本环境
| 名称 | IP | 组件 |
|---|---|---|
| JumpServer单节点(MySQL,Redis分离) | 192.168.0.11 | node-exporter,blackbox,prometheus-server,alertmanager |
| Prometheus | 192.168.0.200 | node-exporter,mysql-exporter,redis-exporter |
注:如果JumpServer的MySQL,Redis分布在不同节点,分开安装prometheus组件即可
二、JumpServer部署
三、docker部署
Prometheus节点docker部署
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum -y install docker-ce docker-compose
配置docker加速
cat <<EOF>/etc/docker/daemon.json
{
"registry-mirrors": ["https://ornb7jit.mirror.aliyuncs.com"]
}
EOF
四、prometheus部署
prometheus拉取镜像
docker pull grafana/grafana
docker pull prom/prometheus
docker pull prom/node-exporter
docker pull prom/blackbox-exporter
docker pull prom/alertmanager
JumpServer拉取镜像
docker pull prom/node-exporter
docker pull prom/mysqld-exporter
docker pull oliver006/redis_exporter
prometheus部署
cd /opt
mkdir alertmanager
mkdir grafana
mkdir prometheus
touch /opt/alermanager/alertmanager.yml
touch /opt/prometheus/prometheus.yml
touch /opt/prometheus/rules.yml
chmod 777 /opt
docker-compose
version: "3.0"
services:
grafana:
container_name: server-grafana
image: grafana/grafana
ports:
- "3000:3000"
volumes:
- "/opt/grafana:/var/lib/grafana"
restart: "on-failure"
networks:
- net
depends_on:
- promethues
promethues:
container_name: server-prom
image: prom/prometheus
hostname: server-prom
ports:
- "9090:9090"
volumes:
- "/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml"
- "/opt/prometheus/rules.yml:/etc/prometheus/rules.yml"
- "/opt/prometheus/data:/prometheus"
- "/etc/localtime:/etc/localtime:ro"
networks:
- net
restart: "no"
depends_on:
- node-exporter
- alertmanager
node-exporter:
container_name: server-node-exporter
image: prom/node-exporter
hostname: server-node-exporter
pid: "host"
ports:
- "9100:9100"
volumes:
- "/proc:/host/proc:ro"
- "/sys:/host/sys:ro"
- "/:/rootfs:ro"
command: "--web.listen-address=:9100 --path.procfs=/host/proc --path.rootfs=/rootfs --path.sysfs=/host/sys --collector.bonding"
network_mode: "host" #这里设置为bridge有bug,端口连接不上
restart: "on-failure"
blackbox-exporter:
container_name: server-blackbox-exporter
image: prom/blackbox-exporter
hostname: server-blackbox-exporter
ports:
- "9115:9115"
# volumes:
# - "/opt/blackbox/backbox.yml:/config/blackbox.yml"
networks:
- net
restart: "on-failure"
alertmanager:
container_name: server-alertmanager
image: prom/alertmanager
hostname: server-alertmanager
ports:
- "9093:9093"
volumes:
- "/opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml"
restart: "on-failure"
networks:
- net
networks:
net:
driver: bridge
ipam:
driver: default
config:
- subnet: 192.168.250.0/24
prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 30s
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.200:9093
scrape_configs:
- job_name: server-prom
static_configs:
- targets: ['192.168.0.200:9090']
labels:
instance: server-prom
- job_name: server-node-exporter
static_configs:
- targets: ['192.168.0.200:9100']
labels:
instance: server-node-exporter
- job_name: server-alertmanager
static_configs:
- targets: ['192.168.0.200:9093']
labels:
instance: server-alertmanager
- job_name: server-blackbox-exporter
static_configs:
- targets: ['192.168.0.200:9115']
labels:
instance: server-blackbox-exporter
- job_name: jms-mysql-exporter
static_configs:
- targets: ['192.168.0.11:9104']
labels:
instance: jms-mysql-exporter
- job_name: jms-redis-exporter
static_configs:
- targets: ['192.168.0.11:9121']
labels:
instance: jms-redis-exporter
- job_name: jms-node-exporter
static_configs:
- targets: ['192.168.0.11:9100']
labels:
instance: jms-node-exporter
- job_name: jms-http
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http://192.168.0.11:8080
- https://192.168.0.11:8443
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.0.200:9115
- job_name: jms-port
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets: ['192.168.0.11:3306','192.168.0.11:6379','192.168.0.11:8080','192.168.0.11:8443']
#labels:
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.0.200:9115
rules.yml
groups:
- name: mysql_rule
rules:
- alert: MySQL is Down
expr: mysql_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} MySQL is down"
description: "MySQL database is down. This requires immediate action!"
- alert: MysqlTooManyConnections(>80%)
expr: avg by (instance) (rate(mysql_global_status_threads_connected[1m])) / avg by (instance) (mysql_global_variables_max_connections) * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "MySQL too many connections (> 80%) (instance {
{ $labels.instance }})"
description: "More than 80% of MySQL connections are in use on {
{ $labels.instance }}\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: MysqlHighThreadsRunning
expr: avg by (instance) (rate(mysql_global_status_threads_running[1m])) / avg by (instance) (mysql_global_variables_max_connections) * 100 > 60
for: 2m
labels:
severity: warning
annotations:
summary: "MySQL high threads running (instance {
{ $labels.instance }})"
description: "More than 60% of MySQL connections are in running state on {
{ $labels.instance }}\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: MysqlSlowQueries
expr: increase(mysql_global_status_slow_queries[1m]) > 0
for: 2m
labels:
severity: warning
annotations:
summary: "MySQL slow queries (instance {
{ $labels.instance }})"
description: "MySQL server mysql has some new slow query.\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: open files high
expr: mysql_global_status_innodb_num_open_files > (mysql_global_variables_open_files_limit) * 0.75
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} open files high"
description: "Open files is high. Please consider increasing open_files_limit."
- alert: Read buffer size is bigger than max. allowed packet size
expr: mysql_global_variables_read_buffer_size > mysql_global_variables_slave_max_allowed_packet
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Read buffer size is bigger than max. allowed packet size"
description: "Read buffer size (read_buffer_size) is bigger than max. allowed packet size (max_allowed_packet).This can break your replication."
- alert: Thread stack size is too small
expr: mysql_global_variables_thread_stack <196608
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Thread stack size is too small"
description: "Thread stack size is too small. This can cause problems when you use Stored Language constructs for example. A typical is 256k for thread_stack_size."
- alert: InnoDB Log File size is too small
expr: mysql_global_variables_innodb_log_file_size < 16777216
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Log File size is too small"
description: "The InnoDB Log File size is possibly too small. Choosing a small InnoDB Log File size can have significant performance impacts."
- alert: Binary Log is disabled
expr: mysql_global_variables_log_bin != 1
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Binary Log is disabled"
description: "Binary Log is disabled. This prohibits you to do Point in Time Recovery (PiTR)."
- alert: Binlog Cache size too small
expr: mysql_global_variables_binlog_cache_size < 1048576
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Cache size too small"
description: "Binlog Cache size is possibly to small. A value of 1 Mbyte or higher is OK."
- alert: Binlog Statement Cache size too small
expr: mysql_global_variables_binlog_stmt_cache_size <1048576 and mysql_global_variables_binlog_stmt_cache_size > 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Statement Cache size too small"
description: "Binlog Statement Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK."
- alert: Binlog Transaction Cache size too small
expr: mysql_global_variables_binlog_cache_size <1048576
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Transaction Cache size too small"
description: "Binlog Transaction Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK."
- alert: Sync Binlog is enabled
expr: mysql_global_variables_sync_binlog == 1
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Sync Binlog is enabled"
description: "Sync Binlog is enabled. This leads to higher data security but on the cost of write performance."
- name: redis_rule
rules:
- alert: RedisDown
expr: redis_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Redis down (instance {
{ $labels.instance }})"
description: "Redis instance is down\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: RedisTooManyMasters
expr: count(redis_instance_info{
role="master"}) > 1
for: 0m
labels:
severity: critical
annotations:
summary: "Redis too many masters (instance {
{ $labels.instance }})"
description: "Redis cluster has too many nodes marked as master.\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: RedisOutOfSystemMemory
expr: redis_memory_used_bytes / redis_total_system_memory_bytes * 100 > 90
for: 2m
labels:
severity: warning
annotations:
summary: "Redis out of system memory (instance {
{ $labels.instance }})"
description: "Redis is running out of system memory (> 90%)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- name: node_exporter
rules:
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: "Host out of memory (instance {
{ $labels.instance }})"
description: "Node memory is filling up (< 10% left)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: HostIsDown
expr: up == 0
for: 2m
labels:
serverity: critical
annotations:
summary: "HOST:{
{$labels.instance}} is down"
description: "HOST:{
{$labels.instance}} is down"
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: "Host out of disk space (instance {
{ $labels.instance }})"
description: "Disk is almost full (< 10% left)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: HostOutOfInodes
expr: node_filesystem_files_free{
mountpoint ="/rootfs"} / node_filesystem_files{
mountpoint="/rootfs"} * 100 < 10 and ON (instance, device, mountpoint) node_filesystem_readonly{
mountpoint="/rootfs"} == 0
for: 2m
labels:
severity: warning
annotations:
summary: "Host out of inodes (instance {
{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{
mode="idle"}[2m])) * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Host high CPU load (instance {
{ $labels.instance }})"
description: "CPU load is > 80%\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: HostCpuStealNoisyNeighbor
expr: avg by(instance) (rate(node_cpu_seconds_total{
mode="steal"}[5m])) * 100 > 10
for: 1m
labels:
severity: warning
annotations:
summary: "Host CPU steal noisy neighbor (instance {
{ $labels.instance }})"
description: "CPU steal is > 10%. A noisy neighbor is killing VM performances or a spot instance may be out of credit.\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- name: blackbox_probe
rules:
- alert: blackboxStatus
expr: probe_success == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} is down"
description: "This requires immediate action!"
alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: ""
smtp_from: ""
smtp_auth_username: ""
smtp_auth_password: ""
smtp_require_tls: false
route:
group_by: ['mysql_rule','redis_rule','node_exporter','blackbox_probe']
group_wait: 60s
group_interval: 60s
repeat_interval: 1h
receiver: 'email'
routes:
- match_re:
job: "server-prom|server-node-exporter|server-alertmanager|server-blackbox-exporter|jms-mysql-exporter|jms-redis-exporter|jms-node-exporter|jms-http|jms-port"
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: ''
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname','instance','severity']
JumpServer部署
docker-compose
version: "3.0"
services:
mysql-exporter:
container_name: jms-mysql-exporter
image: prom/mysqld-exporter
hostname: jms-mysql-exporter
ports:
- "9104:9104"
environment:
DATA_SOURCE_NAME: "exporter:password@(192.168.0.11:3306)/"
restart: "on-failure"
networks:
- net
redis-exporter:
container_name: jms-redis-exporter
image: oliver006/redis_exporter
hostname: jms-redis-exporter
ports:
- "9121:9121"
command: "-redis.addr 192.168.0.11:6379 -redis.password password"
restart: "on-failure"
networks:
- net
node-exporter:
container_name: jms-node-exporter
image: prom/node-exporter
hostname: jms-node-exporter
pid: 'host'
ports:
- "9100:9100"
volumes:
- "/proc:/host/proc:ro"
- "/sys:/host/sys:ro"
- "/:/rootfs:ro"
command: "--web.listen-address=:9100 --path.procfs=/host/proc --path.rootfs=/rootfs --path.sysfs=/host/sys --collector.bonding"
network_mode: "host" #这里设置为bridge有bug,端口连接不上
restart: "on-failure"
networks:
net:
driver: bridge
ipam:
driver: default
config:
- subnet: 192.168.250.0/24
mysql-exporter授权
# 在mysql上配置监控使用的用户
CREATE USER 'exporter'@'192.168.250.0/24' IDENTIFIED BY 'password';
GRANT PROCESS,REPLICATION CLIENT,SELECT ON *.* TO 'exporter'@'192.168.250.0/24';
五、测试
组件测试


告警测试



收到邮件
六、对接grafana
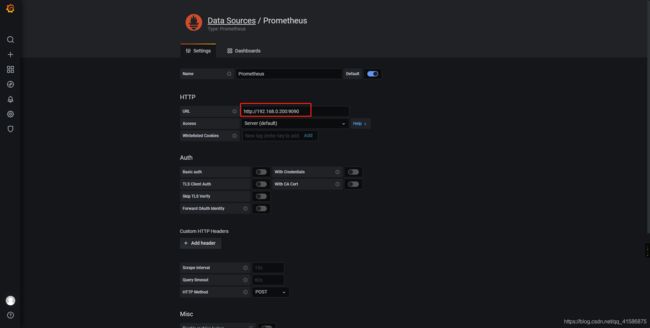
导入dashboard
# node_exporter: 8919
# mysql-exporter:11329
# redis-exporter: 2751
# blackbox-exporter: 9965
# alertmanager: 9578

alertmanager

blackbox

mysql-exporter

node-exporter

redis
