基础阶段(五)——有限MDP问题及其策略迭代法总结
提示:转载请注明出处,若文章无意侵犯到您的合法权益,请及时与作者联系。
基础阶段(五)——有限MDP问题及其策略迭代法代码分析
前言
1.1 强化学习的问题定义
1.2 方格世界的经典MDP问题
1.3 环境与Agent对象
二、策略迭代分析
2.1 策略评估
2.2 策略改进
2.3 策略迭代
2.4 值迭代
前言
在之前的学习中我们学习了有限MDP问题的基于模型的DP解法,也就是策略迭代法,但是很多东西不与实践代码相结合,总会觉得没有成就感,那么我们就将之前介绍的算法通过举例并进行代码分析,注意本文并不会给出全部的可实现的代码,只会根据需要截取相应的部分进行讲解,但是本文会将自己参考的原文链接及代码挂出,供有需要的同学学习。
本文参考的资料文章主要来源:强化学习基础篇: 策略迭代 (Policy Iteration)
一、典型的方格世界问题说明
1.1 强化学习的问题定义
一个Agent与环境不断进行交互,在每一个时间步长t中,环境提供当前状态
给Agent,Agent根据这个当前状态做出决策,这时Agent可能存在多个动作可选,Agent按照一定的策略采取动作
,之后会得到环境反馈的立即回报
,环境此时按照状态转移的概率分布进入了下一个时刻的后继状态,这个后继状态可能是自身也可能是其他状态。
在以上过程中注意存在2个概率分布:
一个是当前状态下要采取哪个动作,即以什么样的策略来决策,随机选择还是统一固定的,本质是一个概率分布问题。
一个是转移到的后继状态将会是什么,即当前状态可以转移到哪些状态,转移到每个状态的概率是多少,本质上就是状态转移的概率分布。
注意:有时还会提到初始状态分布,即初始时刻选择哪一个初始状态的问题。
1.2 方格世界的经典MDP问题
接下来我们给出一个标准的马尔科夫决策过程(MDP)问题来进行研究。假设我们有一个3 x 3的方格世界(GridWorld)作为环境,
存在一个单元格叫做超级玛丽,它每个时间步长只可以往上、下、左、右四个方向移动,在方格世界中存在一个固定的单元格是宝藏,当超级玛丽找到宝藏则游戏结束,我们的目标是让超级玛丽以最快的速度找到宝藏。

我们将上面的描述进行马尔科夫决策过程(MDP)的描述:
- 状态空间State:超级玛丽当前的单元格序号,按照从左到右、从上到下分别是0-8的9个离散值。
- 动作空间Action: 上、下、左、右共计4个离散值
- 动作概率
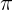 :默认初始策略为在任何状态下都选择向下的动作
:默认初始策略为在任何状态下都选择向下的动作 - 状态转移概率P:默认采取某个动作后一定百分百转移到该方向的相邻单元格,如果相邻单元格不存在则转移到自身。
- 折扣因子
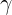 :默认为0.9。
:默认为0.9。 - 立即回报Reward:本文认为该关系是已知的
- 超级玛丽每移动一步,Reward = -1
- 超级玛丽得到宝箱,Reward = 0并且游戏终止
1.3 环境与Agent对象
通过分析以上强化学习的基本定义,我们可以归纳出环境和Agent所具备的基本特点:
环境的特点:
- 环境要确定Agent的观测空间和动作空间。Agent采取的动作和观测到的状态都是离散的,这里我们可以使用一个两个数组来表示,一个是0-8,一个是0-3.
- 环境要根据状态转移概率分布确定后继状态。Agent采取动作后环境可以自己根据状态概率分布切换到相应的后继状态。这里的概率分布比较简单,例如只要Agent当前状态不是在最上层采取向上动作,则状态序号-3即可,依次类推。
- 环境要确定Agent获得的立即回报Reward。Agent采取某个动作进入后继状态后环境可以给出相应的立即回报Reward
- 环境要确定Agent终止交互的终止条件。Agent什么时候停止与环境的交互,这里只要判断Agent的后继状态是不是宝藏所在单元格即可。
Agent的特点:
- Agent应当具备观测有限状态的能力。Agent并不一定掌握全部的环境状态信息,它只能通过观测掌握可以获得的有限的观测信息,能观测到的信息的程度取决于强化学习问题的难度。这里我们是研究一个已知模型问题,所以Agent可以观察到的状态的观测空间就是状态空间。
- Agent应当具备采取有限动作的能力。Agent只能采取有限的动作与环境进行交互且具备采取这些动作的能力,这些动作由环境决定。这里Agent采取动作后仅仅影响环境的后继状态,可以交给环境去完成,
- Agent应当具备进行自主决策的能力。它可以决定在当前状态下来判断下一时刻应该采取什么样的动作,采取有限的动作与环境进行交互。Agent选择每个动作的概率分布是会变化的,只有这样我们才能找到最佳策略,这里我们默认初始都采取向下的动作。这种让动作概率分布发生变化的过程就是我们通过策略迭代来完成的。
- Agent应当具备获取环境反馈的能力。Agent采取动作后应当可以获取环境响应的反馈,从而自己更新策略来学习新的知识。Agent进入下一个状态可以获取的环境反馈有状态转移概率,后继状态,立即回报和是否终止等信息。这些都是由环境决定的,Agent只需要访问环境的接口来获取这个信息即可。
二、策略迭代分析
在本文中我们将会把主要精力集中在研究Agent对象上,特别是它的策略迭代法,其他更多深入研究可参考来源资料中的讲解或者我的实践阶段的代码分析。
2.1 策略评估
直接给出之前的策略评估算法流程:

上述评估算法输入一个策略policy,输出一个存储状态价值的数组v,算法中包含大循环来保证每个状态价值可以不断迭代到响应的精确度,在大循环里面存在一个遍历所有状态的循环、一个遍历所有动作的循环和一个遍历所有后继状态的循环,一共是一个四层嵌套循环结构。
下面是其Python代码实现,这个方法是Agent类中的一个方法,env是其内部的环境类对象的映射。
def policy_evaluation(self, policy):
"""策略评估"""
V = np.zeros(self.env.nS) # 使用一个含有9个0.的数组来存储9个状态的价值
THETA = 0.0001 # 策略评估的精度
delta = float("inf") # 当前迭代的差距量,初始化为正无穷
while delta > THETA:
delta = 0 # 当前迭代的差距量初始化为0
for s in range(self.env.nS):# 遍历环境给出的所有的状态(即0-8)
expected_value = 0 #初始化当前状态价值为0
for action, action_prob in enumerate(policy[s]): # 获取当前状态可采取的所有动作(上下左右)及其采取对应动作的概率
# 遍历采取动作后的所有可能转移的后继状态
# 在当前状态采取当前动作后得到环境反馈的后继状态转移概率,后继状态,立即回报,是否终止
for prob, next_state, reward, done in self.env.P[s][action]:
expected_value += action_prob * prob * (reward + DISCOUNT_FACTOR * V[next_state])#贝尔曼期望方程
delta = max(delta, np.abs(V[s] - expected_value)) # 本次迭代后价值变化的差异
V[s] = expected_value #保存当前状态的价值
return V以上需要特别说明的是输入的policy是一个9行4列的状态*动作的矩阵,这个矩阵初始状态中第2列都为1,其余都为0,表示向下的动作概率为1,其余动作的概率为0。
另外其中调用的self.env.P[s][a]是一个二维列表,它可以返回指定状态和动作对应的所有后继状态及其被选中的概率、立即回报和是否终结等信息,这个功能由环境类实现,我们这里不做分析。
2.2 策略改进
策略改进这里就是根据状态价值计算出当前动作价值最大的动作:
def next_best_action(self, s, V):
"""下一个最好的动作"""
action_values = np.zeros(env.nA)# 动作价值
for a in range(env.nA):
for prob, next_state, reward, done in self.env.P[s][a]:
action_values[a] += prob * (reward + DISCOUNT_FACTOR * V[next_state])
return np.argmax(action_values), np.max(action_values) #返回最大动作状态的动作索引及其动作价值2.3 策略迭代
下面直接给出策略迭代的算法流程:

相应的代码实现如下:
def optimize(self):
"""策略优化"""
policy = np.tile(np.eye(self.env.nA)[1], (self.env.nS, 1)) #9行4列的矩阵,状态*动作,向下的动作都为1,其余为0
is_stable = False
round_num = 0 #循环次数
while not is_stable:
is_stable = True
print("\nRound Number:" + str(round_num))
round_num += 1
print("Current Policy")
print(np.reshape([env.get_action_name(entry) for entry in [np.argmax(policy[s]) for s in range(self.env.nS)]], self.env.shape))
# 进行策略评估
V = self.policy_evaluation(policy)
print("Expected Value accoridng to Policy Evaluation")
print(np.reshape(V, self.env.shape))
# 遍历所有的状态
for s in range(self.env.nS):
action_by_policy = np.argmax(policy[s]) #获取动作概率最大的动作序号
best_action, best_action_value = self.next_best_action(s, V) # 获取当前状态中动作价值最大的动作序号及其动作价值
# print("\nstate=" + str(s) + " action=" + str(best_action))
policy[s] = np.eye(self.env.nA)[best_action] #替换原先的动作选取策略
if action_by_policy != best_action: #如果当前动作不是最优的就继续迭代
is_stable = False
policy = [np.argmax(policy[s]) for s in range(self.env.nS)] #返回最优策略:含有9个表示最优动作序号的数组
return policy在上述代码中可以看到,在每一轮策略迭代中都分为策略评估和策略改进两部分。
策略评估计算出每个状态的价值后,策略改进部分再遍历所有的状态,计算每个状态下,动作价值最好的动作,然后按照贪婪的策略,将当前最好的策略替换掉原先的动作策略,指导所有状态的动作策略不再变化时,策略迭代就结束了。
2.4 值迭代
下面直接给出值迭代的算法流程:

相应的代码实现如下:
def optimize(self):
THETA = 0.0001
delta = float("inf")
round_num = 0
while delta > THETA:
delta = 0
print("\nValue Iteration: Round " + str(round_num))
print(np.reshape(self.V, env.shape))
for s in range(env.nS):
best_action, best_action_value = self.next_best_action(s, self.V)
delta = max(delta, np.abs(best_action_value - self.V[s]))
self.V[s] = best_action_value
round_num += 1
policy = np.zeros(env.nS)
for s in range(env.nS):
best_action, best_action_value = self.next_best_action(s, self.V)
policy[s] = best_action
return policy上述代码中直接使用当前状态下的动作价值最大的动作来代替状态价值,这样子的好处就是可以减少遍历状态空间的次数,但是相应的收敛速度就会变慢。