centos7下cdh集群报错总结,环境CDH6.3.2+cm6.1,持续更新
之前我的虚拟机用的都是ambari搭建的HDP,由于看到网上讲的和朋友讲的企业中用的一般是CDH,且CDH的稳定性和效率也会比较高。所以就在虚拟机上搭建了CDH。(只不过我搭建的不是集群,只是单机搭建)
具体搭建过程,我总结好了,可以私信我直接获取 cdh搭建的有道云笔记,有空再写上来。
以下是相关的一些注意事项和错误总结!
1.httpd无法进入,重启也不行的解决方法
如果已经用启动命令了但是无法进入网页或者报错的话,排除端口开放问题和防火墙问题之后。那么先用yum卸载httpd和mod_wsgi,
卸载命令:
yum remove httpd mod_wsgi
然后在重新安装:
yum -y install httpd mod_wsgi
然后重启服务:service httpd restart
2.关于http的一些事项
制作cm yum源的时候不要写https,而是写http!除非你本机配置好了https,包括后面安装部署cdh的时候填写也要填的是http。
[CM]
name=cm6
#下面一行要注意是http
baseurl=http://cdh/cm6/
gpgcheck=0
EOF
3.cm的server节点无法启动
/usr/local/java/jdk1.8.0_211/是我的jdk的绝路路径。
mkdir -p /usr/java
ln -s /usr/local/java/jdk1.8.0_211/ /usr/java/default
4.cm的agent节点无法启动
(1)server和agent的id标识不一致导致
rm -rf /var/lib/cloudera-scm-agent/cm_guid
systemctl restart cloudera-scm-agent
(2) error: [Errno 111] Connection refused
ps -ef | grep supervisord
kill -9 该进程ID
5.centos修改配置时的重要事项
(1)环境变量问题
建议把python3、java、scala2.11的环境变量都配置在/etc/profile中,也就是作为全局变量。
这里可以顺便去学习回顾一下关于linux环境变量的知识:
-
centos环境变量_Centos7:Linux环境变量配置文件
-
CentOS中环境变量与配置文件的深入讲解
(2)永久关闭THP
Centos6开始引入THP,Centos7时默认启用,用来提升内存性能。但是对一些数据库来说,要求关闭此功能。
centos系统重启导致Transparent Hugepages(THP,页面内存透明化)开启,为提升hadoop性能和满足组件邀请,hadoop环境上要求关闭Transparent Hugepages(THP,页面内存透明化),但是操作系统重启后会自动开启Transparent Hugepages(THP,页面内存透明化)。
所以,需要永久关闭THP,或者去调整它!当然这里是直接关闭。
永久关闭的方法:
vim /etc/rc.d/rc.local
内容如下:
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
然后赋予执行权限:
chmod 755 /etc/rc.d/rc.local
重启之后,验证是否成功:
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/defrag
#都是always madvise [never]才可以
6.安装部署cdh6之前的事项
(1) 拍摄快照
在安装完cm之后,能够进入web UI的登陆窗口后。先别着急往下做,先做一下server节点 (虚拟机/服务器) 的快照。【我这里是单台机器,所以就只用拍摄一台的快照,如果你搭建的是集群,当然也建议拍摄快照,毕竟从头再来的勇气虽然还在,但是既费时间、效率又低】
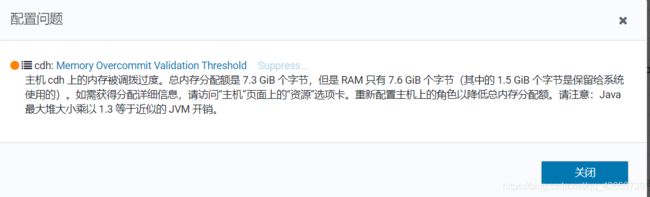
7.内存大小事项
如下图,我给我这个虚拟机的内存是8G左右的内存都不够,因为7G左右的内存已经产生了交换空间了。所以尽量给虚拟机分配高一点的内存!网上说至少16G左右吧,才能正常,具体的去看一下CDH官网。

8.安装cdh6过程中hdfs进入安全模式(safe mode)的解决方法
我试过了,在root用户下的hdfs的强制退出命令hdfs dfsadmin -safemode leave也是无法解除的。网上说要切换到hdfs的角色下在镜像强制退出,试过了也不行。
原因的引起可能是:【这些是瞎猜的,可能有点偏】
- 写入写出的时候timeout了。
- SWAP交换空间导致的
- THP没有关闭,影响了hdfs的安装和测试。
我这里是THP没有成功关闭导致的,因为之前用的是命令操作关闭,而不是直接修改启动文件,所以重启过后没能达到永久关闭的目的,经过恢复快照的推演,也证实了这个想法。
解决方法是当然是永久关闭THP了,在上面有。
9.UI界面显示的警告
如下图,其实就是内存不足导致的!当然还有其它可以调整的。更当然的是,可以添加更多节点,我这里只有一个节点,所以提示我要添加更多主机。【注意,以下所有图中,我都还没启动cdh】
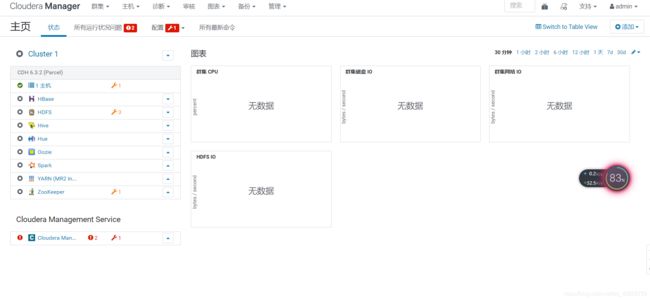

值得注意的是警告并非错误!如果你电脑配置足够强悍,这些警告是不会出现的。

10.UI界面部署cdh过程中的重要事项
(1) 进行角色分配的时候,一定不要留空!能填的都要填上。
(2) 进行数据库设置的时候,User JDBC可以不填,默认就行,因为前面已经配置好了默认的。还有 Hive Metastore Server 一定要配置上主节点。
(3) 进行审核更改的时候默认就好。
(4) 关于hdfs的块大小的设计策略:
从2.7.3版本开始block size的默认大小为128M,之前版本的默认值是64M.
首先,要弄明白:
- 文件块越大,分割数越少,寻址时间越短,但磁盘传输时间越长;
- 文件块越小,分割数越多,寻址时间越长,但磁盘传输时间越短;
- 寻址时间含义:HDFS中找到目标文件block块所花费的时间。
本质上来说,hdfs块大小,会影响程序启动的mapper数量,mapper数量启动的太多,对程序不好,浪费了很多时间在启动mapper上。
但是,块大小并不是越大越好,因为块太大而恰好万一这个task失败了,就要重启一个task,把刚刚task的任务从头开始再运行一遍。你细品,当你觉得就要完成这个task的时候突然失败然后从头来一次,效率低下。
这个没有一个统一的标准,一般默认的128m就已经满足要求了!当然如果是大数据系统的话,可以调高。
11.最后
我想知道如何找到shell的历史屏显信息,但我找到的结果是这样。所以上面的步骤很多是无法还原场景的。以后遇到问题一定先存储问题下来再解决问题,方便总结和分享。
2021.05.01