pytorch实现:对预训练好的卷积网络微调
pytorch实现:对预训练好的卷积网络微调
- 一、导入所需的包
- 二、微调预训练的VGG16网络
- 三、准备新网络需要的数据
- 四、微调网络的训练和预测
由于卷积神经网络层数多,训练参数较多,导致从0开始训练很深的卷积网络非常困难,所以我们可以对预训练好的模型参数进行微调,快速实现自己的任务。pytorch提供ImageNet数据集与预训练好的流行的深度学习网络。
本文使用VGG16网络,对网络结构和参数进行微调。数据集来自kaggle:https://www.kaggle.com/slothkong/10-monkey-species
一、导入所需的包
from torchvision.datasets import ImageFolder
from torchvision import models, transforms
from torch.optim import SGD, Adam
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import torch.utils.data as Data
import torch.nn as nn
import torch
import seaborn as sns
import hiddenlayer as hl #训练过程中此库,可以可视化网络在训练集和验证集上的表现
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore') # 忽略warning
二、微调预训练的VGG16网络
# 进入预训练VGG16网络
vgg16 = models.vgg16(pretrained=True) # 导入的网络是使用ImageNet数据集预训练好的网络
vgg = vgg16.features # 获取VGG16的特征提取层:包括卷积层和池化层,不包含全连接层
for param in vgg16.parameters():
param.requires_grad_(False) # 为了提高速度,只使用VGG16提取图像的特征,需要将特征提取层参数冻结,不更新权重
# vgg16特征提取层处理结束后,在提取层后添加新的全连接层,用于图像分类
class MyVggModel(nn.Module):
def __init__(self):
super(MyVggModel, self).__init__()
# 预训练vgg16的特征提取层
self.vgg = vgg
# 添加新的全连接层
self.classifier = nn.Sequential(
nn.Linear(25088, 512),
nn.ReLU(),
nn.Dropout(p=0.5), #防止过拟合
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256, 10),
nn.Softmax(dim=1)
)
# 定义前向传播路径
def forward(self, x):
x = self.vgg(x)
x = x.view(x.size(0), -1)
output = self.classifier(x)
return output
#输出网络结构
Myvggc=MyVggModel()
print(Myvggc)

三、准备新网络需要的数据
#数据增强
# 使用10类猴子的数据集
# 对训练集进行预处理
train_data_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机长宽比裁剪为224*224
transforms.RandomHorizontalFlip(p=0.5), # 依概率p=0.5水平翻转
transforms.ToTensor(), # 转化为张量,并归一化至[0-1]
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #图像标准化
]) # torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;transforms.Compose函数的主要作用是串联多个图片变换的操作
#对验证集进行预处理
val_data_transforms = transforms.Compose([
transforms.Resize(256), #重置图像分辨率吧
transforms.CenterCrop(224), #依据给定的size从中心处裁剪
transforms.RandomHorizontalFlip(p=0.5), # 依概率p=0.5水平翻转
transforms.ToTensor(), #转化为张量,并归一化至[0-1]
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #图像标准化
])
# 读取训练数据集
train_data_dir = './archive/training/'
# ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名
train_data = ImageFolder(root=train_data_dir, transform=train_data_transforms)
train_data_loader = Data.DataLoader(
train_data, batch_size=32, shuffle=True, num_workers=2)
# 读取验证数据集
val_data_dir = './archive/validation/'
# ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名
val_data = ImageFolder(root=val_data_dir, transform=val_data_transforms)
val_data_loader = Data.DataLoader(
val_data, batch_size=32, shuffle=True, num_workers=2)
print('训练数据集样本数为:', len(train_data.targets))
print('验证数据集样本数为:', len(val_data.targets))
#结果
训练数据集样本数为: 1097
验证数据集样本数为: 272
# 读取一个batch数据
for step, (b_x, b_y) in enumerate(train_data_loader):
if step > 0:
break
# 可视化一个batch数据
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
plt.figure(figsize=(12, 6))
for i in range(len(b_y)):
plt.subplot(4, 8, i+1)
image = b_x[i, :, :, :].numpy().transpose(
(1, 2, 0)) # transpose转置的意思,轴变换
image = std*image+mean
# clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min。
image = np.clip(image, 0, 1)
plt.imshow(image)
plt.title(b_y[i].data.numpy())
plt.axis('off')
plt.subplots_adjust(hspace=0.3)

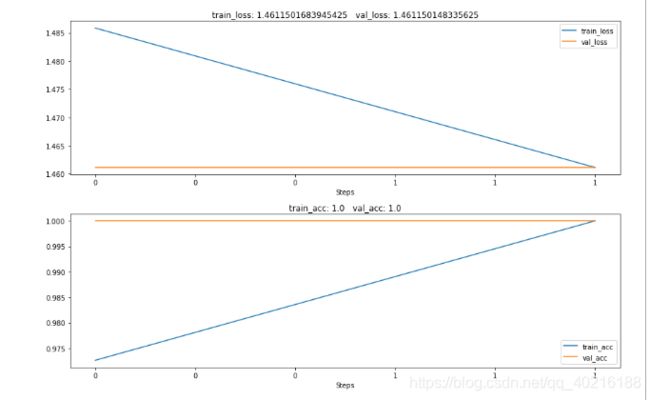
四、微调网络的训练和预测
optimizer = Adam(Myvggc.parameters(), lr=0.003) # 定义优化器
loss_func = nn.CrossEntropyLoss() # 定义损失函数
# 记录训练过程的指标
history1 = hl.History()
# 使用Canvas可视化
canvas1 = hl.Canvas()
# 对模型进行迭代训练
for epoch in range(10):
train_loss_epoch = 0
val_loss_epoch = 0
train_corrects = 0
val_corrects = 0
# 进行训练
Myvggc.train()
for step, (b_x, b_y) in enumerate(train_data_loader):
output = Myvggc(b_x)
loss = loss_func(output, b_y)
pre_lab = torch.argmax(output, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_epoch += loss.item()*b_x.size(0)
train_corrects += torch.sum(pre_lab == b_y.data)
# 计算一个epoch的损失和精度
train_loss = train_loss_epoch/len(train_data.targets)
train_acc = train_corrects.double()/len(train_data.targets)
# 进行验证
Myvggc.eval()
for step, (val_x, val_y) in enumerate(val_data_loader):
output = Myvggc(val_x)
loss = loss_func(output, val_y)
pre_lab = torch.argmax(output, 1)
val_loss_epoch += loss.item()*val_x.size(0)
val_corrects += torch.sum(pre_lab == val_y.data)
# 计算一个epoch的损失和精度
val_loss = val_loss_epoch/len(val_data.targets)
val_acc = val_corrects.double()/len(val_data.targets)
# 保存每个epoch上的输出loss和acc
history1.log(epoch, train_loss=train_loss, val_loss=val_loss,
train_acc=train_acc.item(), val_acc=val_acc.item())
# 可视化训练过程
with canvas1:
canvas1.draw_plot([history1['train_loss'], history1['val_loss']])
canvas1.draw_plot([history1['train_acc'], history1['val_acc']])