Flink实战(110):flink-sql使用(十八)connector(十九)Flink 与 hive 结合使用(七) Flink Hive Connector 使用
声明:本系列博客是根据SGG的视频整理而成,非常适合大家入门学习。
《2021年最新版大数据面试题全面开启更新》
Flink 1.12 版本
1. Hive 建表

//1、创建 Hive 数据库 create database zhisheng; //2、查看创建的数据库 show databases; //3、使用创建的数据库 use zhisheng; //4、在该库下创建 Hive 表 CREATE TABLE IF NOT EXISTS flink ( appid int, message String ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE; //5、往该表插入一条数据 insert into flink values(11111, '233sadadadwqqdq');
2.Flink 读取 Hive 已经存在的表数据
//1、创建 Hive CATALOG,Flink 通过 catalog 不仅可以将自己的表写入 Hive 的 metastore,也能读写 Hive 的表
CREATE CATALOG flinkHiveCatalog WITH (
'type' = 'hive',
'default-database' = 'zhisheng',
'hive-conf-dir' = '/app/apache-hive-2.1.1-bin/conf'
);
//2、使用该 Catalog
USE CATALOG flinkHiveCatalog;
//3、因为刚才已经写入了一条数据到 Hive 表(flink)
select * from flink;

3.Flink 往 Hive 中已经存在的表写数据
//1、创建 Source 表 CREATE TABLE yarn_log_datagen_test_hive_sink ( appid INT, message STRING ) WITH ( 'connector' = 'datagen', 'rows-per-second'='10', 'fields.appid.kind'='random', 'fields.appid.min'='1', 'fields.appid.max'='1000', 'fields.message.length'='100' ); //2、将数据写入到 Hive 表 insert into flink select * from yarn_log_datagen_test_hive_sink;
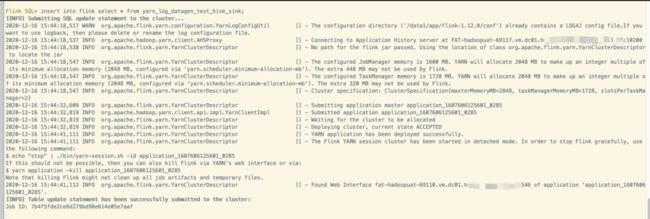
//再次查询 Hive 表里面的数据 select * from flink;

直接在 Hive 利用命令查询:

4 .完整 Example
CREATE CATALOG flinkHiveCatalog WITH ( 'type' = 'hive', 'default-database' = 'zhisheng', 'hive-conf-dir' = '/app/apache-hive-2.1.1-bin/conf' ); USE CATALOG flinkHiveCatalog; SET table.sql-dialect=hive; -- 创建 Hive 表要指定 sql-dialect 为 Hive,否则创建的时候识别不了下面的 DDL 语句 CREATE TABLE yarn_logs ( appid INT, message STRING ) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00', 'sink.partition-commit.trigger'='partition-time', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.policy.kind'='metastore,success-file', 'sink.parallelism'='2' -- 该参数内部才支持设置并行度 ); SET table.sql-dialect=default; -- 创建 Flink 表又要换回默认的 sql-dialect,Flink 支持在同一个 SQL 里面设置多个 sql-dialect CREATE TABLE yarn_log_datagen_test ( appid INT, message STRING, log_ts TIMESTAMP(3), WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.appid.kind' = 'random', 'fields.appid.min' = '1', 'fields.appid.max' = '1000', 'fields.message.length' = '100' ); -- streaming sql, insert into hive table INSERT INTO yarn_logs SELECT appid, message, DATE_FORMAT(log_ts, 'yyyy-MM-dd'), DATE_FORMAT(log_ts, 'HH') FROM yarn_log_datagen_test; -- batch sql, select with partition pruning SELECT * FROM yarn_logs WHERE dt='2020-12-16' and hr='12';
查看 table 的存储路径
show create table yarn_logs;