机器学习-第三方库(工具包)-scikit-learn【特征工程】
Python语言的机器学习工具
Scikit-learn包括许多知名的机器学习算法的实现(算法原理一定要懂)
Scikit-learn文档完善,容易上手,封装的好,丰富的API,建立模型简单,预测简单,使其在学术界颇受欢迎。
Scikit-learn缺点:算法过程无法看到,有些参数都在算法Api内部优化,无法手动调参。(相对比的,tensorflow的Api有的封装的高,有的封装的低,可以手动调参。比如Scikit-learn的线性回归梯度下降法无法手动调α学习率大小,而tensorflow可以手动调节)
一、scikit-learn数据集
1、scikit-learn获取数据集
sklearn.datasets是scikit-learn获取数据集的api,加载获取流行数据集
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples * n_features] 的二维numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名,回归数据集没有
1.1 sklearn.datasets.load_*()
获取小规模数据集,数据在\sklearn\datasets\data目录里,下载scikit-learn时同时下载下来了;
1.1.1 sklearn分类数据集(目标值是离散型的)
1.1.1.1 “鸢尾花分类” 数据集
sklearn.datasets.load_iris()

from sklearn.datasets import load_iris
li = load_iris()
print("特征值---->li.feature_names = \n", li.feature_names)
print("签名值---->li.target_names = \n", li.target_names)
print("目标值---->li.target = \n", li.target)
print("特征数据数组---->li.data = \n", li.data)
print('数据描述---->li.DESCR = \n', li.DESCR)
打印结果
特征值---->li.feature_names =
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
签名值---->li.target_names =
['setosa' 'versicolor' 'virginica']
目标值---->li.target =
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
特征数据数组---->li.data =
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5. 3.2 1.2 0.2]
[5.5 3.5 1.3 0.2]
[4.9 3.1 1.5 0.1]
[4.4 3. 1.3 0.2]
[5.1 3.4 1.5 0.2]
[5. 3.5 1.3 0.3]
[4.5 2.3 1.3 0.3]
[4.4 3.2 1.3 0.2]
[5. 3.5 1.6 0.6]
[5.1 3.8 1.9 0.4]
[4.8 3. 1.4 0.3]
[5.1 3.8 1.6 0.2]
[4.6 3.2 1.4 0.2]
[5.3 3.7 1.5 0.2]
[5. 3.3 1.4 0.2]
[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]
[5. 2. 3.5 1. ]
[5.9 3. 4.2 1.5]
[6. 2.2 4. 1. ]
[6.1 2.9 4.7 1.4]
[5.6 2.9 3.6 1.3]
[6.7 3.1 4.4 1.4]
[5.6 3. 4.5 1.5]
[5.8 2.7 4.1 1. ]
[6.2 2.2 4.5 1.5]
[5.6 2.5 3.9 1.1]
[5.9 3.2 4.8 1.8]
[6.1 2.8 4. 1.3]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[6.4 2.9 4.3 1.3]
[6.6 3. 4.4 1.4]
[6.8 2.8 4.8 1.4]
[6.7 3. 5. 1.7]
[6. 2.9 4.5 1.5]
[5.7 2.6 3.5 1. ]
[5.5 2.4 3.8 1.1]
[5.5 2.4 3.7 1. ]
[5.8 2.7 3.9 1.2]
[6. 2.7 5.1 1.6]
[5.4 3. 4.5 1.5]
[6. 3.4 4.5 1.6]
[6.7 3.1 4.7 1.5]
[6.3 2.3 4.4 1.3]
[5.6 3. 4.1 1.3]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[6.1 3. 4.6 1.4]
[5.8 2.6 4. 1.2]
[5. 2.3 3.3 1. ]
[5.6 2.7 4.2 1.3]
[5.7 3. 4.2 1.2]
[5.7 2.9 4.2 1.3]
[6.2 2.9 4.3 1.3]
[5.1 2.5 3. 1.1]
[5.7 2.8 4.1 1.3]
[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]
[6.5 3.2 5.1 2. ]
[6.4 2.7 5.3 1.9]
[6.8 3. 5.5 2.1]
[5.7 2.5 5. 2. ]
[5.8 2.8 5.1 2.4]
[6.4 3.2 5.3 2.3]
[6.5 3. 5.5 1.8]
[7.7 3.8 6.7 2.2]
[7.7 2.6 6.9 2.3]
[6. 2.2 5. 1.5]
[6.9 3.2 5.7 2.3]
[5.6 2.8 4.9 2. ]
[7.7 2.8 6.7 2. ]
[6.3 2.7 4.9 1.8]
[6.7 3.3 5.7 2.1]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[6.1 3. 4.9 1.8]
[6.4 2.8 5.6 2.1]
[7.2 3. 5.8 1.6]
[7.4 2.8 6.1 1.9]
[7.9 3.8 6.4 2. ]
[6.4 2.8 5.6 2.2]
[6.3 2.8 5.1 1.5]
[6.1 2.6 5.6 1.4]
[7.7 3. 6.1 2.3]
[6.3 3.4 5.6 2.4]
[6.4 3.1 5.5 1.8]
[6. 3. 4.8 1.8]
[6.9 3.1 5.4 2.1]
[6.7 3.1 5.6 2.4]
[6.9 3.1 5.1 2.3]
[5.8 2.7 5.1 1.9]
[6.8 3.2 5.9 2.3]
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
数据描述---->li.DESCR =
Iris Plants Database
====================
Notes
-----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
This is a copy of UCI ML iris datasets.
http://archive.ics.uci.edu/ml/datasets/Iris
The famous Iris database, first used by Sir R.A Fisher
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
References
----------
- Fisher,R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda,R.O., & Hart,P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
1.1.1.2 “数字分类” 数据集
sklearn.datasets.load_digits()

from sklearn.datasets import load_digits
li = load_digits()
print("签名值---->li.target_names = \n", li.target_names)
print("目标值---->li.target = \n", li.target)
print("特征数据数组---->li.data = \n", li.data)
print('数据描述---->li.DESCR = \n', li.DESCR)
打印结果:
签名值---->li.target_names =
[0 1 2 3 4 5 6 7 8 9]
目标值---->li.target =
[0 1 2 ... 8 9 8]
特征数据数组---->li.data =
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
数据描述---->li.DESCR =
Optical Recognition of Handwritten Digits Data Set
===================================================
Notes
-----
Data Set Characteristics:
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.
T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.
L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,
1994.
References
----------
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their
Applications to Handwritten Digit Recognition, MSc Thesis, Institute of
Graduate Studies in Science and Engineering, Bogazici University.
- E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.
Linear dimensionalityreduction using relevance weighted LDA. School of
Electrical and Electronic Engineering Nanyang Technological University.
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
1.1.1.3 “20Newsgroups” 数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
用于分类的大数据集
subset: ‘train’或者’test’,‘all’,可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”,一般选择’all’,然后手动用split来划分训练集与测试集。
datasets.clear_data_home(data_home=None):清除目录下的数据
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
print("特征数据值数组中的第一个---->news.data[0] = \n", news.data[0])
print("签名值---->news.target_names = \n", news.target_names)
print("目标值---->news.target = ", news.target)
print('数据描述---->news.description = ', news.description)
打印结果:
特征数据值数组中的第一个---->news.data[0] =
From: Mamatha Devineni Ratnam <mr47+@andrew.cmu.edu>
Subject: Pens fans reactions
Organization: Post Office, Carnegie Mellon, Pittsburgh, PA
Lines: 12
NNTP-Posting-Host: po4.andrew.cmu.edu
I am sure some bashers of Pens fans are pretty confused about the lack
of any kind of posts about the recent Pens massacre of the Devils. Actually,
I am bit puzzled too and a bit relieved. However, I am going to put an end
to non-PIttsburghers' relief with a bit of praise for the Pens. Man, they
are killing those Devils worse than I thought. Jagr just showed you why
he is much better than his regular season stats. He is also a lot
fo fun to watch in the playoffs. Bowman should let JAgr have a lot of
fun in the next couple of games since the Pens are going to beat the pulp out of Jersey anyway. I was very disappointed not to see the Islanders lose the final
regular season game. PENS RULE!!!
签名值---->news.target_names =
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
目标值---->news.target = [10 3 17 ... 3 1 7]
数据描述---->news.description = the 20 newsgroups by date dataset
1.1.2 sklearn回归数据集(目标值是连续型的)
1.1.2.1 :“波士顿房价” 数据集
sklearn.datasets.load_boston()

from sklearn.datasets import load_boston
lb = load_boston()
print("获取特征数据值 lb.data = \n", lb.data)
print("目标值 lb.target = \n", lb.target)
print('lb.DESCR = \n', lb.DESCR)
打印结果:
获取特征数据值 lb.data =
[[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00]
[2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00]
[2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00]
...
[6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00]
[1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00]
[4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]]
目标值 lb.target =
[24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4
18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8
18.4 21. 12.7 14.5 13.2 13.1 13.5 18.9 20. 21. 24.7 30.8 34.9 26.6
25.3 24.7 21.2 19.3 20. 16.6 14.4 19.4 19.7 20.5 25. 23.4 18.9 35.4
24.7 31.6 23.3 19.6 18.7 16. 22.2 25. 33. 23.5 19.4 22. 17.4 20.9
24.2 21.7 22.8 23.4 24.1 21.4 20. 20.8 21.2 20.3 28. 23.9 24.8 22.9
23.9 26.6 22.5 22.2 23.6 28.7 22.6 22. 22.9 25. 20.6 28.4 21.4 38.7
43.8 33.2 27.5 26.5 18.6 19.3 20.1 19.5 19.5 20.4 19.8 19.4 21.7 22.8
18.8 18.7 18.5 18.3 21.2 19.2 20.4 19.3 22. 20.3 20.5 17.3 18.8 21.4
15.7 16.2 18. 14.3 19.2 19.6 23. 18.4 15.6 18.1 17.4 17.1 13.3 17.8
14. 14.4 13.4 15.6 11.8 13.8 15.6 14.6 17.8 15.4 21.5 19.6 15.3 19.4
17. 15.6 13.1 41.3 24.3 23.3 27. 50. 50. 50. 22.7 25. 50. 23.8
23.8 22.3 17.4 19.1 23.1 23.6 22.6 29.4 23.2 24.6 29.9 37.2 39.8 36.2
37.9 32.5 26.4 29.6 50. 32. 29.8 34.9 37. 30.5 36.4 31.1 29.1 50.
33.3 30.3 34.6 34.9 32.9 24.1 42.3 48.5 50. 22.6 24.4 22.5 24.4 20.
21.7 19.3 22.4 28.1 23.7 25. 23.3 28.7 21.5 23. 26.7 21.7 27.5 30.1
44.8 50. 37.6 31.6 46.7 31.5 24.3 31.7 41.7 48.3 29. 24. 25.1 31.5
23.7 23.3 22. 20.1 22.2 23.7 17.6 18.5 24.3 20.5 24.5 26.2 24.4 24.8
29.6 42.8 21.9 20.9 44. 50. 36. 30.1 33.8 43.1 48.8 31. 36.5 22.8
30.7 50. 43.5 20.7 21.1 25.2 24.4 35.2 32.4 32. 33.2 33.1 29.1 35.1
45.4 35.4 46. 50. 32.2 22. 20.1 23.2 22.3 24.8 28.5 37.3 27.9 23.9
21.7 28.6 27.1 20.3 22.5 29. 24.8 22. 26.4 33.1 36.1 28.4 33.4 28.2
22.8 20.3 16.1 22.1 19.4 21.6 23.8 16.2 17.8 19.8 23.1 21. 23.8 23.1
20.4 18.5 25. 24.6 23. 22.2 19.3 22.6 19.8 17.1 19.4 22.2 20.7 21.1
19.5 18.5 20.6 19. 18.7 32.7 16.5 23.9 31.2 17.5 17.2 23.1 24.5 26.6
22.9 24.1 18.6 30.1 18.2 20.6 17.8 21.7 22.7 22.6 25. 19.9 20.8 16.8
21.9 27.5 21.9 23.1 50. 50. 50. 50. 50. 13.8 13.8 15. 13.9 13.3
13.1 10.2 10.4 10.9 11.3 12.3 8.8 7.2 10.5 7.4 10.2 11.5 15.1 23.2
9.7 13.8 12.7 13.1 12.5 8.5 5. 6.3 5.6 7.2 12.1 8.3 8.5 5.
11.9 27.9 17.2 27.5 15. 17.2 17.9 16.3 7. 7.2 7.5 10.4 8.8 8.4
16.7 14.2 20.8 13.4 11.7 8.3 10.2 10.9 11. 9.5 14.5 14.1 16.1 14.3
11.7 13.4 9.6 8.7 8.4 12.8 10.5 17.1 18.4 15.4 10.8 11.8 14.9 12.6
14.1 13. 13.4 15.2 16.1 17.8 14.9 14.1 12.7 13.5 14.9 20. 16.4 17.7
19.5 20.2 21.4 19.9 19. 19.1 19.1 20.1 19.9 19.6 23.2 29.8 13.8 13.3
16.7 12. 14.6 21.4 23. 23.7 25. 21.8 20.6 21.2 19.1 20.6 15.2 7.
8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9
22. 11.9]
lb.DESCR =
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
1.1.2.2 :“糖尿病” 数据集
sklearn.datasets.load_diabetes()
from sklearn.datasets import load_diabetes
ld = load_diabetes()
print("获取特征数据值 ld.data = \n", ld.data)
print("目标值 ld.target = \n", ld.target)
print('ld.DESCR = \n', ld.DESCR)
打印结果:
获取特征数据值 ld.data =
[[ 0.03807591 0.05068012 0.06169621 ... -0.00259226 0.01990842
-0.01764613]
[-0.00188202 -0.04464164 -0.05147406 ... -0.03949338 -0.06832974
-0.09220405]
[ 0.08529891 0.05068012 0.04445121 ... -0.00259226 0.00286377
-0.02593034]
...
[ 0.04170844 0.05068012 -0.01590626 ... -0.01107952 -0.04687948
0.01549073]
[-0.04547248 -0.04464164 0.03906215 ... 0.02655962 0.04452837
-0.02593034]
[-0.04547248 -0.04464164 -0.0730303 ... -0.03949338 -0.00421986
0.00306441]]
目标值 ld.target =
[151. 75. 141. 206. 135. 97. 138. 63. 110. 310. 101. 69. 179. 185.
118. 171. 166. 144. 97. 168. 68. 49. 68. 245. 184. 202. 137. 85.
131. 283. 129. 59. 341. 87. 65. 102. 265. 276. 252. 90. 100. 55.
61. 92. 259. 53. 190. 142. 75. 142. 155. 225. 59. 104. 182. 128.
52. 37. 170. 170. 61. 144. 52. 128. 71. 163. 150. 97. 160. 178.
48. 270. 202. 111. 85. 42. 170. 200. 252. 113. 143. 51. 52. 210.
65. 141. 55. 134. 42. 111. 98. 164. 48. 96. 90. 162. 150. 279.
92. 83. 128. 102. 302. 198. 95. 53. 134. 144. 232. 81. 104. 59.
246. 297. 258. 229. 275. 281. 179. 200. 200. 173. 180. 84. 121. 161.
99. 109. 115. 268. 274. 158. 107. 83. 103. 272. 85. 280. 336. 281.
118. 317. 235. 60. 174. 259. 178. 128. 96. 126. 288. 88. 292. 71.
197. 186. 25. 84. 96. 195. 53. 217. 172. 131. 214. 59. 70. 220.
268. 152. 47. 74. 295. 101. 151. 127. 237. 225. 81. 151. 107. 64.
138. 185. 265. 101. 137. 143. 141. 79. 292. 178. 91. 116. 86. 122.
72. 129. 142. 90. 158. 39. 196. 222. 277. 99. 196. 202. 155. 77.
191. 70. 73. 49. 65. 263. 248. 296. 214. 185. 78. 93. 252. 150.
77. 208. 77. 108. 160. 53. 220. 154. 259. 90. 246. 124. 67. 72.
257. 262. 275. 177. 71. 47. 187. 125. 78. 51. 258. 215. 303. 243.
91. 150. 310. 153. 346. 63. 89. 50. 39. 103. 308. 116. 145. 74.
45. 115. 264. 87. 202. 127. 182. 241. 66. 94. 283. 64. 102. 200.
265. 94. 230. 181. 156. 233. 60. 219. 80. 68. 332. 248. 84. 200.
55. 85. 89. 31. 129. 83. 275. 65. 198. 236. 253. 124. 44. 172.
114. 142. 109. 180. 144. 163. 147. 97. 220. 190. 109. 191. 122. 230.
242. 248. 249. 192. 131. 237. 78. 135. 244. 199. 270. 164. 72. 96.
306. 91. 214. 95. 216. 263. 178. 113. 200. 139. 139. 88. 148. 88.
243. 71. 77. 109. 272. 60. 54. 221. 90. 311. 281. 182. 321. 58.
262. 206. 233. 242. 123. 167. 63. 197. 71. 168. 140. 217. 121. 235.
245. 40. 52. 104. 132. 88. 69. 219. 72. 201. 110. 51. 277. 63.
118. 69. 273. 258. 43. 198. 242. 232. 175. 93. 168. 275. 293. 281.
72. 140. 189. 181. 209. 136. 261. 113. 131. 174. 257. 55. 84. 42.
146. 212. 233. 91. 111. 152. 120. 67. 310. 94. 183. 66. 173. 72.
49. 64. 48. 178. 104. 132. 220. 57.]
ld.DESCR =
Diabetes dataset
================
Notes
-----
Ten baseline variables, age, sex, body mass index, average blood
pressure, and six blood serum measurements were obtained for each of n =
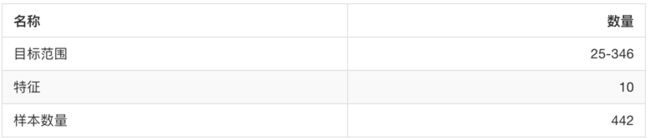
442 diabetes patients, as well as the response of interest, a
quantitative measure of disease progression one year after baseline.
Data Set Characteristics:
:Number of Instances: 442
:Number of Attributes: First 10 columns are numeric predictive values
:Target: Column 11 is a quantitative measure of disease progression one year after baseline
:Attributes:
:Age:
:Sex:
:Body mass index:
:Average blood pressure:
:S1:
:S2:
:S3:
:S4:
:S5:
:S6:
Note: Each of these 10 feature variables have been mean centered and scaled by the standard deviation times `n_samples` (i.e. the sum of squares of each column totals 1).
Source URL:
http://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
For more information see:
Bradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) "Least Angle Regression," Annals of Statistics (with discussion), 407-499.
(http://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf)
1.2 sklearn.datasets.fetch_*(data_home=None)
获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/;windows系统默认保存位置为C:\Users\Admin\scikit_learn_data
2、scikit-learn分割数据集
2.1 数据集划分原则
机器学习一般的数据集会划分为两个部分:
- 训练数据(75%):用于训练,构建模型;
- 测试数据(25%):在模型检验时使用,用于评估模型是否有效;
2.2 scikit-learn数据集分割API
sklearn.model_selection.train_test_split(arrays, options)
arrays表示可以传入多个array参数
- x 数据集的特征数据值
- y 数据集的目标值(标签值)
options 表示可以传入多个参数
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 返回值顺序
- 特征数据值of训练集, 特征数据值of测试集,目标值of训练集 , 目标值of测试集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
li = load_iris()
# 注意返回值顺序: eigenvalues_train(特征数据值-训练集), eigenvalues_test(特征数据值-测试集),target_value_train(目标值-训练集) , target_value_test(目标值-测试集)
eigenValuesOfTrainDataFrame, eigenValuesOfTestDataFrame, targetValuesOfTrainSeries, targetValuesOfTestSeries = train_test_split(li.data, li.target, test_size=0.25)
print('\n特征数据值of训练集 eigenValuesOfTrainDataFrame:\n', eigenValuesOfTrainDataFrame)
print('\n特征数据值of测试集 eigenValuesOfTestDataFrame:\n', eigenValuesOfTestDataFrame)
print('\n目标值of训练集 targetValuesOfTrainSeries:\n', targetValuesOfTrainSeries)
print('\n目标值of测试集 targetValuesOfTestSeries:\n', targetValuesOfTestSeries)
打印结果:
特征数据值of训练集 eigenValuesOfTrainDataFrame:
[[5.7 4.4 1.5 0.4]
[6.1 3. 4.6 1.4]
[7.3 2.9 6.3 1.8]
[7.7 2.8 6.7 2. ]
[6.4 3.1 5.5 1.8]
[5.5 2.5 4. 1.3]
[5.6 3. 4.1 1.3]
[5.6 2.9 3.6 1.3]
[4.8 3.1 1.6 0.2]
[5. 2.3 3.3 1. ]
[5. 3.5 1.3 0.3]
[4.7 3.2 1.6 0.2]
[6. 2.7 5.1 1.6]
[5. 3.4 1.6 0.4]
[6.3 3.3 6. 2.5]
[6. 2.2 4. 1. ]
[5. 3.3 1.4 0.2]
[6.1 2.9 4.7 1.4]
[5.4 3.4 1.5 0.4]
[7.2 3. 5.8 1.6]
[6.7 3.3 5.7 2.5]
[6.1 2.6 5.6 1.4]
[4.8 3.4 1.6 0.2]
[4.6 3.6 1. 0.2]
[6.7 3.1 5.6 2.4]
[6.4 3.2 5.3 2.3]
[4.4 3. 1.3 0.2]
[4.9 2.5 4.5 1.7]
[6.1 3. 4.9 1.8]
[6.8 2.8 4.8 1.4]
[7.7 2.6 6.9 2.3]
[6.3 2.5 4.9 1.5]
[5.1 3.3 1.7 0.5]
[6.9 3.2 5.7 2.3]
[4.5 2.3 1.3 0.3]
[7.4 2.8 6.1 1.9]
[5.5 2.4 3.7 1. ]
[5. 3.5 1.6 0.6]
[7.9 3.8 6.4 2. ]
[5.6 3. 4.5 1.5]
[5.1 3.8 1.6 0.2]
[6.5 3. 5.5 1.8]
[6.7 2.5 5.8 1.8]
[6.5 3.2 5.1 2. ]
[4.3 3. 1.1 0.1]
[5.7 2.9 4.2 1.3]
[5.1 2.5 3. 1.1]
[5.1 3.7 1.5 0.4]
[5.5 2.3 4. 1.3]
[5.5 3.5 1.3 0.2]
[6.9 3.1 5.4 2.1]
[5.4 3. 4.5 1.5]
[5.4 3.4 1.7 0.2]
[7.2 3.2 6. 1.8]
[6.4 2.9 4.3 1.3]
[7.6 3. 6.6 2.1]
[5. 3.6 1.4 0.2]
[5.4 3.7 1.5 0.2]
[5.9 3.2 4.8 1.8]
[6.2 2.9 4.3 1.3]
[4.9 3. 1.4 0.2]
[5.2 4.1 1.5 0.1]
[5.8 2.7 3.9 1.2]
[6.4 3.2 4.5 1.5]
[6.6 2.9 4.6 1.3]
[7. 3.2 4.7 1.4]
[6.9 3.1 4.9 1.5]
[4.9 3.1 1.5 0.1]
[6.5 3. 5.2 2. ]
[4.8 3. 1.4 0.3]
[6.3 3.3 4.7 1.6]
[6.2 2.2 4.5 1.5]
[6.7 3. 5. 1.7]
[5.6 2.5 3.9 1.1]
[5.9 3. 4.2 1.5]
[6. 3. 4.8 1.8]
[6.3 2.7 4.9 1.8]
[5.3 3.7 1.5 0.2]
[4.4 2.9 1.4 0.2]
[6.4 2.7 5.3 1.9]
[6.3 2.3 4.4 1.3]
[6.2 2.8 4.8 1.8]
[5.8 2.6 4. 1.2]
[5. 3. 1.6 0.2]
[5.9 3. 5.1 1.8]
[5.8 4. 1.2 0.2]
[5.6 2.8 4.9 2. ]
[4.9 3.1 1.5 0.1]
[4.6 3.2 1.4 0.2]
[6.7 3.3 5.7 2.1]
[6.4 2.8 5.6 2.2]
[5.2 3.5 1.5 0.2]
[6.5 2.8 4.6 1.5]
[5. 3.2 1.2 0.2]
[5.1 3.4 1.5 0.2]
[5.4 3.9 1.3 0.4]
[5.2 2.7 3.9 1.4]
[4.9 3.1 1.5 0.1]
[5.7 3. 4.2 1.2]
[6.3 3.4 5.6 2.4]
[6.1 2.8 4.7 1.2]
[5.8 2.7 5.1 1.9]
[4.6 3.4 1.4 0.3]
[6.8 3.2 5.9 2.3]
[6. 3.4 4.5 1.6]
[4.7 3.2 1.3 0.2]
[6. 2.9 4.5 1.5]
[5.5 2.6 4.4 1.2]
[6.2 3.4 5.4 2.3]
[5.5 4.2 1.4 0.2]
[6.3 2.8 5.1 1.5]
[5.6 2.7 4.2 1.3]]
特征数据值of测试集 eigenValuesOfTestDataFrame:
[[7.2 3.6 6.1 2.5]
[6.1 2.8 4. 1.3]
[5. 2. 3.5 1. ]
[5.1 3.8 1.5 0.3]
[4.8 3.4 1.9 0.2]
[7.1 3. 5.9 2.1]
[5.7 2.5 5. 2. ]
[6.5 3. 5.8 2.2]
[7.7 3. 6.1 2.3]
[5. 3.4 1.5 0.2]
[5.8 2.7 4.1 1. ]
[6.8 3. 5.5 2.1]
[6.3 2.9 5.6 1.8]
[5.2 3.4 1.4 0.2]
[5.8 2.7 5.1 1.9]
[5.7 2.8 4.5 1.3]
[5.7 3.8 1.7 0.3]
[6.4 2.8 5.6 2.1]
[6.7 3. 5.2 2.3]
[5.5 2.4 3.8 1.1]
[5.1 3.8 1.9 0.4]
[6.6 3. 4.4 1.4]
[6.9 3.1 5.1 2.3]
[4.9 2.4 3.3 1. ]
[5.8 2.8 5.1 2.4]
[5.4 3.9 1.7 0.4]
[4.6 3.1 1.5 0.2]
[6.3 2.5 5. 1.9]
[6.7 3.1 4.7 1.5]
[7.7 3.8 6.7 2.2]
[4.8 3. 1.4 0.1]
[5.7 2.6 3.5 1. ]
[5.1 3.5 1.4 0.2]
[6. 2.2 5. 1.5]
[4.4 3.2 1.3 0.2]
[5.7 2.8 4.1 1.3]
[5.1 3.5 1.4 0.3]
[6.7 3.1 4.4 1.4]]
目标值of训练集 targetValuesOfTrainSeries:
[0 1 2 2 2 1 1 1 0 1 0 0 1 0 2 1 0 1 0 2 2 2 0 0 2 2 0 2 2 1 2 1 0 2 0 2 1
0 2 1 0 2 2 2 0 1 1 0 1 0 2 1 0 2 1 2 0 0 1 1 0 0 1 1 1 1 1 0 2 0 1 1 1 1
1 2 2 0 0 2 1 2 1 0 2 0 2 0 0 2 2 0 1 0 0 0 1 0 1 2 1 2 0 2 1 0 1 1 2 0 2
1]
目标值of测试集 targetValuesOfTestSeries:
[2 1 1 0 0 2 2 2 2 0 1 2 2 0 2 1 0 2 2 1 0 1 2 1 2 0 0 2 1 2 0 1 0 2 0 1 0 1]
二、特征抽取 (使用scikit-learn进行数据的特征抽取)
1、字典类型数据----特征抽取
使用类:sklearn.feature_extraction.DictVectorizer
sklearn.feature_extraction.DictVectorizer的作用:对字典数据进行特征值化。即:把字典里的一些非数值型的数据分别转换为特征,然后用特征值(0或1)来表示该特征是否存在。待输入的数据要求为字典类型,如果原始数据不是字典类型,而是数组形式,需要将有类别的这些特征先要转换为字典数据,如果某些特征用不到,则不用提取(比如下图中的name,如果用不到,就不用提取出来)。

DictVectorizer语法:
- DictVectorizer(sparse=True,…),实例化
- DictVectorizer.fit_transform(X) ,X:字典或者包含字典的迭代器;返回值:返回sparse矩阵
- DictVectorizer.inverse_transform(X),X:array数组或者sparse矩阵;返回值:转换之前数据格式
- DictVectorizer.get_feature_names(),返回类别名称
- DictVectorizer.transform(X),按照原先的标准转换
字典特征抽取流程:
- 实例化类DictVectorizer
- 调用fit_transform方法输入数据并转换 (注意返回格式)
[{
'city': '北京','temperature':100}
{
'city': '上海','temperature':60}
{
'city': '深圳','temperature':30}]
# 字典特征抽取
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""字典数据抽取"""
# 实例化
my_dict00 = DictVectorizer() # 默认值为sparse=True,返回sparse矩阵
# 调用fit_transform对字典格式的原始数据进行转换,默认返回sparse矩阵
my_data00 = my_dict00.fit_transform([{
'city': '北京', 'temperature': 100}, {
'city': '上海', 'temperature': 60}, {
'city': '深圳', 'temperature': 30}])
print('转换后的特征值(sparse矩阵类型):my_data00=\n', my_data00)
my_dict = DictVectorizer(sparse=False) # sparse=False 返回矩阵
# 调用fit_transform对字典格式的原始数据进行转换,通过DictVectorizer(sparse=False)设置返回类型为矩阵(ndarray类型),而不是默认的sparse矩阵
my_data01 = my_dict.fit_transform([{
'city': '北京', 'temperature': 100}, {
'city': '上海', 'temperature': 60}, {
'city': '深圳', 'temperature': 30}])
# 获取类别名称
feature_names = my_dict.get_feature_names()
# 调用inverse_transform,返回转换之前数据格式
my_data02 = my_dict.inverse_transform(my_data01)
print('特征值列名:feature_names = my_dict.get_feature_names()=\n', feature_names)
print('转换后的特征值(ndarray矩阵类型):my_data01=\n', my_data01)
print('my_data01.shape=', my_data01.shape)
print('my_data02 = my_dict.inverse_transform(my_data01)=\n', my_data02)
return None
if __name__ == "__main__":
dictvec()
打印结果:
转换后的特征值(sparse矩阵类型):my_data00=
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
特征值列名:feature_names = my_dict.get_feature_names()=
['city=上海', 'city=北京', 'city=深圳', 'temperature']
转换后的特征值(ndarray矩阵类型):my_data01=
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
my_data01.shape= (3, 4)
my_data02 = my_dict.inverse_transform(my_data01)=
[{
'city=北京': 1.0, 'temperature': 100.0}, {
'city=上海': 1.0, 'temperature': 60.0}, {
'city=深圳': 1.0, 'temperature': 30.0}]
2、文本类型数据----特征抽取
2.1 方式一(抽取词频):sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.CountVectorizer的作用:对文本数据进行特征值化。首先将所有文章里的所有的词统计出来,重复的只统计一次。然后对每篇文章,在词的列表里面进行统计每个词出现的次数。注意:单个字母不统计(因为单个单词没有单词分类依据)。

DictVectorizer语法:
- CountVectorizer(max_df=1.0,min_df=1,…)----实例化,返回词频矩阵
- CountVectorizer.fit_transform(X,y)----X:文本或者包含文本字符串的可迭代对象;返回值:返回sparse矩阵
- CountVectorizer.inverse_transform(X)----X:array数组或者sparse矩阵;返回值:转换之前数据格式
- CountVectorizer.get_feature_names()----返回值:单词列表
文本特征抽取流程:
- 实例化类CountVectorizer
- 调用fit_transform方法输入数据并转换(注意返回格式,利用toarray()进行sparse矩阵转换array数组)
- 中文需要先进行分词,然后再进行特征抽取。
2.1.1 不带有中文的文本特征抽取
["life is short,i like python","life is too long,i dislike python"]
# 文本特征抽取
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""对文本进行特征值化"""
cv = CountVectorizer()
data = cv.fit_transform(["Python: life is short,i like python. it is python.", "life is too long,i dislike python. it is not python."]) # 列表里表示第一篇文章,第二篇文章
print('cv.get_feature_names() = \n', cv.get_feature_names())
print('data = \n', data)
print('data.toarray() = \n', data.toarray())
return None
if __name__ == "__main__":
countvec()
打印结果:
cv.get_feature_names() =
['dislike', 'is', 'it', 'life', 'like', 'long', 'not', 'python', 'short', 'too']
data =
(0, 2) 1
(0, 4) 1
(0, 8) 1
(0, 1) 2
(0, 3) 1
(0, 7) 3
(1, 6) 1
(1, 0) 1
(1, 5) 1
(1, 9) 1
(1, 2) 1
(1, 1) 2
(1, 3) 1
(1, 7) 2
data.toarray() =
[[0 2 1 1 1 0 0 3 1 0]
[1 2 1 1 0 1 1 2 0 1]]
2.1.2 带有中文的文本特征抽取(不进行分词)
有中文的文本特征抽取,如果不先进行中文分词,则将一段话当做一个词
["你们感觉人生苦短,你 喜欢python java javascript", "人生 漫长,我们 不喜欢python,react"]
# 文本特征抽取
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""对文本进行特征值化"""
cv = CountVectorizer()
data = cv.fit_transform(["你们感觉人生苦短,你 喜欢python java javascript", "人生 漫长,我们 不喜欢python,react"]) # 列表里表示第一篇文章,第二篇文章
print('cv.get_feature_names() = \n', cv.get_feature_names())
print('data = \n', data)
print('data.toarray() = \n', data.toarray())
return None
if __name__ == "__main__":
countvec()
打印结果:
cv.get_feature_names() =
['java', 'javascript', 'react', '不喜欢python', '人生', '你们感觉人生苦短', '喜欢python', '我们', '漫长']
data =
(0, 1) 1
(0, 0) 1
(0, 6) 1
(0, 5) 1
(1, 2) 1
(1, 3) 1
(1, 7) 1
(1, 8) 1
(1, 4) 1
data.toarray() =
[[1 1 0 0 0 1 1 0 0]
[0 0 1 1 1 0 0 1 1]]
2.1.3 使用“jieba”库进行中文分词的文本特征抽取
安装:pip3 install jieba
使用:jieba.cut("我是一个好程序员")
返回值:词语生成器
# 文本特征抽取
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
"""中文分词"""
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""中文特征值化"""
c1, c2, c3 = cutword()
print('c1 = \n', c1)
print('c2 = \n', c2)
print('c3 = \n', c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print('cv.get_feature_names() = \n', cv.get_feature_names()) # 单个词不统计
print('data.toarray() = \n', data.toarray())
return None
if __name__ == "__main__":
hanzivec()
打印结果:
c1 =
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。
c2 =
我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。
c3 =
如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
cv.get_feature_names() =
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '这样']
data.toarray() =
[[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0]
[0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1]
[1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
2.2 方式二(tf-idf抽取词语的重要性)
API:sklearn.feature_extraction.text.TfidfVectorizer
tf:term frequency---->词频
idf:inverse document frequency---->逆文档频率=log( 总 文 档 数 量 该 词 出 现 的 文 档 数 量 \frac{总文档数量}{该词出现的文档数量} 该词出现的文档数量总文档数量)
tf × idf---->该词在该篇文档中的重要性程度
tf-idf的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
tf-idf作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
tf-idf是分类机器学习算法的重要依据。
tf-idf方法比count方法更好一些,但是在自然语言处理过程中会使用比tf-idf更好的方法【使用单字,使用n-garm,使用BM25,使用word2vec等,让其结果更加准确】。
2.2.1 tf-idf算法代码实现
import numpy as np
import pandas as pd
import math
### 1. 定义数据和预处理
docA = "The cat sat on my bed"
docB = "The dog sat on my knees"
bowA = docA.split(" ")
bowB = docB.split(" ")
print('bowA = {0}'.format(bowA))
print('bowB = {0}'.format(bowB))
# 构建词库
wordSet = set(bowA).union(set(bowB))
print('wordSet = {0}'.format(wordSet))
### 2. 进行词数统计
# 用统计字典来保存词出现的次数
wordDictA = dict.fromkeys(wordSet, 0)
wordDictB = dict.fromkeys(wordSet, 0)
# 遍历文档,统计词数
for word in bowA:
wordDictA[word] += 1
for word in bowB:
wordDictB[word] += 1
print('\nwordDataFrame = \n{0}'.format(pd.DataFrame([wordDictA, wordDictB])))
### 3. 计算词频tf=该词在文章A中的词频
def computeTF(wordDict, bow):
# 用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来
tfDict = {
}
nbowCount = len(bow)
for word, count in wordDict.items():
tfDict[word] = count / nbowCount
return tfDict
### 4. 计算逆文档频率idf=log(总文档数量/该词出现的文档数量)
def computeIDF(wordDictList):
# 用一个字典对象保存idf结果,每个词作为key,初始值为0
idfDict = dict.fromkeys(wordDictList[0], 0)
N = len(wordDictList)
for wordDict in wordDictList:
# 遍历字典中的每个词汇,统计Ni
for word, count in wordDict.items():
if count > 0:
# 先把Ni增加1,存入到idfDict
idfDict[word] += 1
# 已经得到所有词汇i对应的Ni,现在根据公式把它替换成为idf值
for word, ni in idfDict.items():
idfDict[word] = math.log10((N + 1) / (ni + 1))
return idfDict
### 5. 计算TF-IDF
def computeTFIDF(tf, idfs):
tfidf = {
}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
if __name__ == '__main__':
tfA = computeTF(wordDictA, bowA)
tfB = computeTF(wordDictB, bowB)
print('\ntfA = {0}'.format(tfA))
print('tfB = {0}'.format(tfB))
idfs = computeIDF([wordDictA, wordDictB])
print('\nidfs = {0}'.format(idfs))
tfidfA = computeTFIDF(tfA, idfs)
tfidfB = computeTFIDF(tfB, idfs)
print('\ntfidfDataFrame = \n{0}'.format(pd.DataFrame([tfidfA, tfidfB])))
打印结果:
bowA = ['The', 'cat', 'sat', 'on', 'my', 'bed']
bowB = ['The', 'dog', 'sat', 'on', 'my', 'knees']
wordSet = {
'The', 'my', 'sat', 'knees', 'cat', 'on', 'bed', 'dog'}
wordDataFrame =
The bed cat dog knees my on sat
0 1 1 1 0 0 1 1 1
1 1 0 0 1 1 1 1 1
tfA = {
'The': 0.16666666666666666, 'my': 0.16666666666666666, 'sat': 0.16666666666666666, 'knees': 0.0, 'cat': 0.16666666666666666, 'on': 0.16666666666666666, 'bed': 0.16666666666666666, 'dog': 0.0}
tfB = {
'The': 0.16666666666666666, 'my': 0.16666666666666666, 'sat': 0.16666666666666666, 'knees': 0.16666666666666666, 'cat': 0.0, 'on': 0.16666666666666666, 'bed': 0.0, 'dog': 0.16666666666666666}
idfs = {
'The': 0.0, 'my': 0.0, 'sat': 0.0, 'knees': 0.17609125905568124, 'cat': 0.17609125905568124, 'on': 0.0, 'bed': 0.17609125905568124, 'dog': 0.17609125905568124}
tfidfDataFrame =
The bed cat dog knees my on sat
0 0.0 0.029349 0.029349 0.000000 0.000000 0.0 0.0 0.0
1 0.0 0.000000 0.000000 0.029349 0.029349 0.0 0.0 0.0
2.2.2 tf-idf算法案例
# 文本特征抽取(tf-idf方式)
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutword():
"""中文分词"""
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def tfidfvec():
"""中文特征值化"""
c1, c2, c3 = cutword()
print('c1 = \n', c1)
print('c2 = \n', c2)
print('c3 = \n', c3)
tfidf = TfidfVectorizer()
data = tfidf.fit_transform([c1, c2, c3])
print('tfidf.get_feature_names() = \n', tfidf.get_feature_names())
print('data.toarray() = \n', data.toarray())
return None
if __name__ == "__main__":
tfidfvec()
打印结果:
c1 =
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。
c2 =
我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。
c3 =
如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。
tfidf.get_feature_names() =
['一种', '不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '这样']
data.toarray() =
[[0. 0. 0.21821789 0. 0. 0.
0.43643578 0. 0. 0. 0. 0.
0.21821789 0. 0.21821789 0. 0. 0.
0. 0.21821789 0.21821789 0. 0.43643578 0.
0.21821789 0. 0.43643578 0.21821789 0. 0.
0. 0.21821789 0.21821789 0. 0. 0. ]
[0. 0. 0. 0.2410822 0. 0.
0. 0.2410822 0.2410822 0.2410822 0. 0.
0. 0. 0. 0. 0. 0.2410822
0.55004769 0. 0. 0. 0. 0.2410822
0. 0. 0. 0. 0.48216441 0.
0. 0. 0. 0. 0.2410822 0.2410822 ]
[0.15698297 0.15698297 0. 0. 0.62793188 0.47094891
0. 0. 0. 0. 0.15698297 0.15698297
0. 0.15698297 0. 0.15698297 0.15698297 0.
0.1193896 0. 0. 0.15698297 0. 0.
0. 0.15698297 0. 0. 0. 0.31396594
0.15698297 0. 0. 0.15698297 0. 0. ]]
三、特征的预处理(对数据进行处理)
特征的预处理:通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
数值型数据预处理方法(缩放):1、归一化;2、标准化;3、缺失值;并不是每个算法都需要缩放处理。
类别(String)型数据预处理方法:LabelEncode(Series)、OrdinalEncode(DataFrame)、OneHotEncode(one-hot编码可消除数值大小对算法的影响);
时间型数据预处理方法:时间的切分;
scikit-learn所有的预处理方法都在sklearn. preprocessing类下
1、归一化方法(不常用)
1.1 归一化的目的
使得某一特征不会对最终结果造成比其他特征更大的影响。
1.2 特点
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
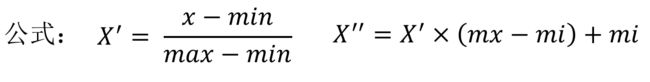
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0。

1.3 sklearn归一化API: sklearn.preprocessing.MinMaxScaler
MinMaxScaler语法:
- MinMaxScalar(feature_range=(0,1)…),实例化,每个特征缩放到给定范围(默认[0,1])
- MinMaxScalar.fit_transform(X),X:numpy array格式的数据[n_samples,n_features],返回值:转换后的形状相同的array
from sklearn.preprocessing import MinMaxScaler
def min_max():
"""归一化处理"""
mm = MinMaxScaler() # 默认:MinMaxScaler(feature_range=(0, 1))
data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
return None
if __name__ == "__main__":
min_max()
打印结果:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
1.4 如果数据中异常点较多,会有什么影响?
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,归一化方法只适合传统精确小数据场景。一般传统精确小数据场景不多,所以在实际应用中不太用归一化方法。
2、标准化方法(常用)
2.1 标准化的目的
使得某一特征不会对最终结果造成比其他特征更大的影响。
2.2 特点
通过对原始数据进行变换把数据变换到均值为0,方差为1 范围内。

2.3 sklearn标准化API: scikit-learn.preprocessing.StandardScaler
StandardScaler语法:
- StandardScaler(…),实例化,处理之后每列来说所有数据都聚集在均值0附近方差为1。
- StandardScaler.fit_transform(X,y),X:numpy array格式的数据[n_samples,n_features],返回值:转换后的形状相同的array。
- StandardScaler.mean_,原始数据中每列特征的平均值。
- StandardScaler.std_,原始数据每列特征的方差。
from sklearn.preprocessing import StandardScaler
def stand():
"""标准化缩放"""
std = StandardScaler()
data = std.fit_transform([[1., -1., 3.], [2., 4., 2.], [4., 6., -1.]])
print('data = \n', data)
return None
if __name__ == "__main__":
stand()
打印结果:
data =
[[-1.06904497 -1.35873244 0.98058068]
[-0.26726124 0.33968311 0.39223227]
[ 1.33630621 1.01904933 -1.37281295]]
2.4 标准化方法 V.S. 归一化方法
归一化:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变。
标准化:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
3、数值型数据离散化

4、时间型特征数据处理

5、统计型特征数据处理

6、缺失值的处理方法
注意:虽然scikit-learn也提供了缺失值的处理api,但是缺失值一般使用pandas来处理
6.1 缺失值的处理方法
- 删除----如果每列或者行数据缺失值达到一定的比例,建议放弃整行或者整列
- 插补(常用)----可以通过缺失值每行或者每列(比按行填补靠谱)的平均值、中位数来填充
6.2 sklearn缺失值API: sklearn.preprocessing.Imputer
Imputer语法:
- Imputer(missing_values=‘NaN’, strategy=‘mean’, axis=0),完成缺失值插补
- Imputer.fit_transform(X,y) ,X:numpy array格式的数据[n_samples,n_features],返回值:转换后的形状相同的array
Imputer流程:
- 初始化Imputer,指定”缺失值”,指定填补策略,指定行或列(缺失值也可以是别的指定要替换的值);
- 调用fit_transform方法输入数据并转换;
from sklearn.preprocessing import Imputer
import numpy as np
def im():
"""缺失值处理"""
# NaN, nan 两种写法都可以
im = Imputer(missing_values='NaN', strategy='mean', axis=0) # axis=0 表示按列求平均值
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print('data = \n', data)
return None
if __name__ == "__main__":
im()
打印结果:
data =
[[1. 2.]
[4. 3.]
[7. 6.]]
4.3 关于np.nan(np.NaN)
- numpy的数组中可以使用np.nan/np.NaN来代替缺失值,属于float类型
- 如果是文件中的一些缺失值,可以替换成nan,通过np.array转化成float型的数组即可
四、数据降维(维度:特征的数量)
数据降维不是指数据矩阵的维度,而是指特征数量的减少。
数据降维方法:特征选择、主成分分析。
1、数据降维方式一:特征选择
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
特征选择原因----冗余:部分特征的相关度高,容易消耗计算性能;噪声:部分特征对预测结果有负影响
特征选择主要方法(三大武器):
- Filter(过滤式):VarianceThreshold
- Embedded(嵌入式):正则化、决策树
- 神经网络
- Wrapper(包裹式):基本用不到
1.1 Filter(过滤式):VarianceThreshold
原则:把特征值差不多的特征删除掉,该特征对预测的作用不大。
用到的类:sklearn.feature_selection.VarianceThreshold,利用方差(Variance)进行过滤。
VarianceThreshold语法:
- VarianceThreshold(threshold = 0.0),删除所有低方差特征
- Variance.fit_transform(X,y),X:numpy array格式的数据[n_samples,n_features],返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
VarianceThreshold流程
- 初始化VarianceThreshold,指定阀值方差。阀值方差根据实际情况来选择。阀值方差可以选0~9范围内的所有数,没有一个最好值,得根据实际效果来选择。
- 调用fit_transform
from sklearn.feature_selection import VarianceThreshold
def var():
"""特征选择-删除低方差的特征"""
var = VarianceThreshold() # 默认:threshold=0.0
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print('data = \n', data)
return None
if __name__ == "__main__":
var()
打印结果:
data =
[[2 0]
[1 4]
[1 1]]
1.2 Embedded(嵌入式):正则化、决策树
1.3 神经网络
2、数据降维方式二:主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA):是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。
设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。
本质:PCA是一种分析、简化数据集的技术(当特征数量达到上百的时候,考虑数据的简化)。
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。在降低维度时,尽可能减少损失。
作用:可以削减回归分析或者聚类分析中特征的数量。
用到的类:sklearn.decomposition

高维度数据容易出现的问题:特征之间通常是线性相关的或近似线性相关。
2.1 PCA理论基础:正交变换
正交向量:指点乘积(数量积)为零的两个或多个向量,若向量 α ⃗ \vec{α} α 与 β ⃗ \vec{β} β 正交,则 α ⃗ \vec{α} α· β ⃗ \vec{β} β=0,记为 α ⃗ \vec{α} α⊥ β ⃗ \vec{β} β。
正交矩阵(orthogonal matrix):是一个方块矩阵(方阵),其元素为实数,而且行(列)向量两两正交且是单位向量,使得该矩阵的转置矩阵为其逆矩阵: Q T Q^T QT = Q−1 ⇔ Q T Q^T QTQ = Q Q T Q^T QT = E。
正交矩阵的行列式值必定为 + 1或 − 1。
作为一个线性映射(变换矩阵),正交矩阵保持距离不变,所以它是一个保距映射,具体例子为旋转与镜射。
行列式值为+1的正交矩阵,称为特殊正交矩阵,它是一个旋转矩阵。
行列式值为-1的正交矩阵,称为瑕旋转矩阵。瑕旋转是旋转加上镜射。镜射也是一种瑕旋转。
正交变换:是线性变换的一种,它从实内积空间V映射到V自身,且保证变换前后内积不变。因为向量的模长与向量间的夹角都是用内积定义的,所以正交变换前后一对向量各自的模长和它们的夹角都不变。
正交变换: Y’ = P * X = [ 1 2 − 1 2 1 2 1 2 ] \left[ \begin{matrix} {1\over \sqrt{2}} & -{1\over \sqrt{2}} \\ {1\over \sqrt{2}} & {1\over \sqrt{2}} \end{matrix} \right] [2121−2121] * [ − 1 − 1 0 2 0 − 2 0 0 1 1 ] \left[ \begin{matrix} -1 & -1 & 0 & 2 & 0\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right] [−1−2−10002101] = [ 1 2 − 1 2 0 1 2 − 1 2 − 3 2 − 1 2 0 3 2 1 2 ] \left[ \begin{matrix} {1\over \sqrt{2}} & -{1\over \sqrt{2}} & 0 & {1\over \sqrt{2}} & -{1\over \sqrt{2}} \\ -{3\over \sqrt{2}} & -{1\over \sqrt{2}} & 0 & {3\over \sqrt{2}} & {1\over \sqrt{2}} \end{matrix} \right] [21−23−21−21002123−2121]
旋转矩阵(Rotation matrix):是在乘以一个向量的时候有改变向量的方向但不改变大小的效果并保持了手性的矩阵。
通过旋转矩阵(属于正交矩阵,满足正交矩阵的一切性质)将原矩阵旋转到各个点的x分量(x1, x2, x3, x4 …)之间,或者y分量(y1, y2, y3, y4 …)之间,或者z分量(z1, z2, z3, z4 …)之间尽可能不相等。
二维旋转矩阵: P P P = [ s i n θ − s i n θ c o s θ c o s θ ] \left[ \begin{matrix} sinθ & -sinθ \\ cosθ & cosθ \end{matrix} \right] [sinθcosθ−sinθcosθ] = = = θ=45° \overset{\text{θ=45°}}{===} ===θ=45° [ 1 2 − 1 2 1 2 1 2 ] \left[ \begin{matrix} {1\over \sqrt{2}} & -{1\over \sqrt{2}} \\ {1\over \sqrt{2}} & {1\over \sqrt{2}} \end{matrix} \right] [2121−2121]
三维旋转矩阵: P x P_x Px = [ 1 0 0 0 c o s θ x − s i n θ x 0 s i n θ x c o s θ x ] \left[ \begin{matrix} 1 & 0 & 0 \\ 0 & cosθ_x & -sinθ_x \\ 0 & sinθ_x & cosθ_x \end{matrix} \right] ⎣⎡1000cosθxsinθx0−sinθxcosθx⎦⎤; P y P_y Py = [ c o s θ y 0 s i n θ y 0 1 0 − s i n θ y 0 c o s θ y ] \left[ \begin{matrix} cosθ_y & 0 & sinθ_y \\ 0 & 1 &0 \\ -sinθ_y & 0 & cosθ_y \end{matrix} \right] ⎣⎡cosθy0−sinθy010sinθy0cosθy⎦⎤; P z P_z Pz = [ c o s θ z − s i n θ z 0 s i n θ z c o s θ z 0 0 0 1 ] \left[ \begin{matrix} cosθ_z & -sinθ_z & 0 \\ sinθ_z & cosθ_z &0 \\ 0& 0 & 1\end{matrix} \right] ⎣⎡cosθzsinθz0−sinθzcosθz0001⎦⎤
Y’矩阵的第2行数据(y数据)各不相同,可以用来做降维处理。选取旋转矩阵P的第二行作为变换矩阵,左乘矩阵X得到一个线性变换后的行矩阵(行向量)。由原来的特征x、特征y(2个)减少为特征y(1个),而且该保留下来的特征y包含了原数据的大部分信息。
Y’ = P * X = [ 1 2 1 2 ] \left[ \begin{matrix} {1\over \sqrt{2}} & {1\over \sqrt{2}} \end{matrix} \right] [2121] * [ − 1 − 1 0 2 0 − 2 0 0 1 1 ] \left[ \begin{matrix} -1 & -1 & 0 & 2 & 0\\ -2 & 0 & 0 & 1 & 1 \end{matrix} \right] [−1−2−10002101] = [ − 3 2 − 1 2 0 3 2 1 2 ] \left[ \begin{matrix} -{3\over \sqrt{2}} & -{1\over \sqrt{2}} & 0 & {3\over \sqrt{2}} & {1\over \sqrt{2}} \end{matrix} \right] [−23−2102321]

PCA有两种通俗易懂的解释:(1)最大方差理论;(2)最小化降维造成的损失。这两个思路都能推导出同样的结果。
最大方差理论:最好的 k k k 维特征是将 n n n 维样本点转换为 k k k 维后,每一个维度上的样本方差都很大,数据更加发散。将这些更加发散的数据提供给算法进行训练时,更有利于得出更好的模型。
- 样本 X m × n \textbf{X}_{m×n} Xm×n (其中 m m m 为样品数量, n n n 为特征数量)在 u n × 1 \textbf{u}_{n×1} un×1 向量方向上的投影为 X m × n ⋅ u \textbf{X}_{m×n}·\textbf{u} Xm×n⋅u,其方差 v a r = ( X m × n ⋅ u − E ) 2 = ( X m × n ⋅ u − E ) T ⋅ ( X m × n ⋅ u − E ) var=(\textbf{X}_{m×n}·\textbf{u}-\textbf{E})^2=(\textbf{X}_{m×n}·\textbf{u}-\textbf{E})^T·(\textbf{X}_{m×n}·\textbf{u}-\textbf{E}) var=(Xm×n⋅u−E)2=(Xm×n⋅u−E)T⋅(Xm×n⋅u−E)
- 令数据中心化,则 E = 0 \textbf{E}=\textbf{0} E=0
- 方差 v a r = ( X m × n ⋅ u ) T ⋅ ( X m × n ⋅ u ) = u T ( X T X ) n × n u var=(\textbf{X}_{m×n}·\textbf{u})^T·(\textbf{X}_{m×n}·\textbf{u})=\textbf{u}^T(\textbf{X}^T\textbf{X})_{n×n}\textbf{u} var=(Xm×n⋅u)T⋅(Xm×n⋅u)=uT(XTX)n×nu,此方差 v a r var var 是关于 u \textbf{u} u 的一个函数,问题转为:就 v a r ( u ) var(u) var(u) 的极大值。
- 令 u \textbf{u} u 是单位向量,则 ∣ u ∣ = 1 ⟹ u T ⋅ u = 1 |\textbf{u}|=1\implies\textbf{u}^T·\textbf{u}=1 ∣u∣=1⟹uT⋅u=1;
- 问题转为求在约束条件 u T ⋅ u = 1 \textbf{u}^T·\textbf{u}=1 uT⋅u=1 下,求 v a r = u T ( X T X ) n × n u var=\textbf{u}^T(\textbf{X}^T\textbf{X})_{n×n}\textbf{u} var=uT(XTX)n×nu 的极大值;
- 构造朗格朗日函数: J ( u ) = u T ( X T X ) n × n u + λ ( 1 − u T ⋅ u ) J(\textbf{u}) = \textbf{u}^T(\textbf{X}^T\textbf{X})_{n×n}\textbf{u} + λ(1-\textbf{u}^T·\textbf{u}) J(u)=uT(XTX)n×nu+λ(1−uT⋅u);
- 求朗格朗日函数 J ( u ) J(\textbf{u}) J(u)对 u \textbf{u} u的偏导,并令其为0,此时所求的 u \textbf{u} u 即是约束条件 u T ⋅ u = 1 \textbf{u}^T·\textbf{u}=1 uT⋅u=1 下函数 v a r = u T ( X T X ) n × n u var=\textbf{u}^T(\textbf{X}^T\textbf{X})_{n×n}\textbf{u} var=uT(XTX)n×nu 的极大值处的 u \textbf{u} u;
- ∂ J ( u ) ∂ u = ∂ [ u T ( X T X ) n × n u + λ ( 1 − u T ⋅ u ) ] ∂ u = 2 ( X T X ) n × n u − 2 λ u = 0 \begin{aligned}\frac{\partial{J(\textbf{u})}}{\partial{\textbf{u}}}=\frac{\partial{[ \textbf{u}^T(\textbf{X}^T\textbf{X})_{n×n}\textbf{u} + λ(1-\textbf{u}^T·\textbf{u})]}}{\partial{\textbf{u}}}=2(\textbf{X}^T\textbf{X})_{n×n}\textbf{u}-2λ\textbf{u}=0\end{aligned} ∂u∂J(u)=∂u∂[uT(XTX)n×nu+λ(1−uT⋅u)]=2(XTX)n×nu−2λu=0;
- ∴ \textbf{∴} ∴ [ ( X T X ) n × n ] u = λ u \begin{aligned}[(\textbf{X}^T\textbf{X})_{n×n}]\textbf{u}=λ\textbf{u}\end{aligned} [(XTX)n×n]u=λu;
- ∴ \textbf{∴} ∴ { [ ( X T X ) n × n ] − λ E } u = 0 \begin{aligned}\{[(\textbf{X}^T\textbf{X})_{n×n}]-λ\textbf{E}\}\textbf{u}=0\end{aligned} { [(XTX)n×n]−λE}u=0
- { [ ( X T X ) n × n ] − λ E } u = 0 \begin{aligned}\{[(\textbf{X}^T\textbf{X})_{n×n}]-λ\textbf{E}\}\textbf{u}=0\end{aligned} { [(XTX)n×n]−λE}u=0 是一个 n n n 个未知数 n n n 个方程的齐次线性方程组,(参考:《线性代数》同济大学第六版 p 120 p_{120} p120)它有非零解的充分必要条件是系数行列式
∣ [ ( X T X ) n × n ] − λ E ∣ = 0 \begin{aligned}\left|[(\textbf{X}^T\textbf{X})_{n×n}]-λ\textbf{E}\right|=0\end{aligned} ∣∣∣[(XTX)n×n]−λE∣∣∣=0 - ∴ \textbf{∴} ∴ 求解未知数为 u \textbf{u} u 的方程 [ ( X T X ) n × n ] u = λ u \begin{aligned}[(\textbf{X}^T\textbf{X})_{n×n}]\textbf{u}=λ\textbf{u}\end{aligned} [(XTX)n×n]u=λu 的解,就是求 方阵 ( X T X ) n × n (\textbf{X}^T\textbf{X})_{n×n} (XTX)n×n 的特征值 λ λ λ 以及 各个特征值分别对应的 特征向量 u \textbf{u} u,其中 特征值 λ λ λ 及其对应的特征向量 u \textbf{u} u 的数量为 n n n;
- 由于 方阵 ( X T X ) n × n (\textbf{X}^T\textbf{X})_{n×n} (XTX)n×n 是一个对称矩阵,所以求得的不同的特征值 λ λ λ 对应的 特征向量 u \textbf{u} u 之间两两正交(方向垂直);
- ∴ \textbf{∴} ∴ PCA方法找方差 v a r var var 最大时的方向向量 u \textbf{u} u,就是找第一主成分;PCA方法找方差 v a r var var 第二大时的方向向量 u \textbf{u} u,就是找第二主成分;方阵 ( X T X ) n × n (\textbf{X}^T\textbf{X})_{n×n} (XTX)n×n 特征向量 的数量为 n n n 个,求出的主成分的数量为 n n n 个。
- PCA主成分分析降维,就是从 n n n 个相互垂直的方向向量 u n × 1 \textbf{u}_{n×1} un×1 中选取 ( n − k ) (n-k) (n−k) 个方向向量 u n × 1 \textbf{u}_{n×1} un×1 ,然后将 X m × n \textbf{X}_{m×n} Xm×n 通过 X m × n × u n × 1 i \textbf{X}_{m×n}×\textbf{u}_{n×1}^i Xm×n×un×1i投影到各个 u n × 1 i \textbf{u}_{n×1}^i un×1i方向上,得到各个方向向量 u n × 1 i \textbf{u}_{n×1}^i un×1i (特征 i i i)上的 数据 X m × 1 i \textbf{X}_{m×1}^i Xm×1i,或者通过将 n n n 个相互垂直的方向向量 u n × 1 \textbf{u}_{n×1} un×1 通过加权平均得到 ( n − k ) (n-k) (n−k) 个方向向量 u n × 1 i \textbf{u}_{n×1}^i un×1i (特征 i i i)上的 数据 X m × 1 i \textbf{X}_{m×1}^i Xm×1i。
2.2 PCA语法
2.2.1 PCA(n_components=None)
- 实例化,将数据分解为较低维数空间。
- n_components可以为0~1的小数或整数。
- n_components取小数时,表示PCA主成分分析之后信息保留量的百分比。经验表明一般填写0.9~0.95之间的小数。
- n_components取整数时,表示PCA主成分分析之后所保留的特征的数量。一般不用此参数。
2.2.2 PCA.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features],返回值:转换后指定维度的array
2.3 PCA降维案例
2.3.1 PCA降维案例01
from sklearn.decomposition import PCA
def pca():
"""主成分分析进行特征降维"""
pca070 = PCA(n_components=0.70)
data070 = pca070.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print('data070 = \n', data070)
pca080 = PCA(n_components=0.80)
data080 = pca080.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print('data080 = \n', data080)
pca099 = PCA(n_components=0.99)
data099 = pca099.fit_transform([[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]])
print('data099 = \n', data099)
return None
if __name__ == "__main__":
pca()
打印结果:
data070 =
[[ 1.28620952e-15]
[ 5.74456265e+00]
[-5.74456265e+00]]
data080 =
[[ 1.28620952e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]
data099 =
[[ 1.28620952e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]
结果表明:
- 当n_components=0.70时,由原来的4个特征,最后保留了1个特征;
- 当n_components=0.80 时,由原来的4个特征,最后保留了2个特征;保留了原始数据的近80%的信息量。
- 当n_components=0.99 时,由原来的4个特征,最后保留了2个特征;保留了原始数据的近99%的信息量。
3、降维方法“特征选择”与“主成分分析”的选择
如果特征数量特别多(比如上百个),则选择主成分分析的方法来降维;
五、scikit-learn转换器与估计器
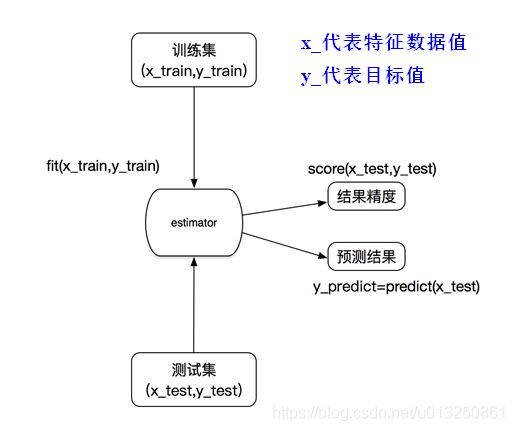
1、scikit-learn转换器:实现特征工程的Api
1.1 fit(X)
对输入的数据X进行各种属性(平均值、方差…)的计算,但不输出任何数据。
1.2 transformer(Y)
根据上一步fit(X)函数计算的各种属性值(平均值、方差…)来计算输入的数据Y的各种结果,并输出转换后的数据。所以transformer(Y)的输出结果直接依赖于最紧邻的上一步fit(X)中计算出来的各种属性值(平均值、方差…)。
1.3 fit-transformer() = fit() + transformer()
输入数据后立刻计算各种属性值(平均值、方差…)然后输出转换后的数据。
2、scikit-learn估计器:实现算法的Api
2.1 用于分类的估计器
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
2.2 用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归