搜索技术 淘气三千问(三万字长文)
如果你也对以下问题有好奇心,那么这篇文章适合读一读:
搜索引擎的基本工作原理是什么?
四代搜索技术发展的历史进程是什么?
什么是大搜?什么是垂搜?
什么是query?什么是index?什么是term?什么是doc?
query分析包括哪些方面?
什么是查询策略?
什么是搜索SUG?
什么是摘要索引?
什么是相关搜索?
什么是搜索引擎cache缓存机制?
什么是正排索引?什么是倒排索引?
什么是内容农场?
针对搜索爬虫,常见的内容作弊方式有哪些?
针对链接引擎中的链接分析技术,常见的链接作弊方法有哪些?
什么是页面隐藏作弊?
什么是网页去重算法?
百度搜索引擎的缓存机制是什么?
什么是淘宝搜索引擎的缓存机制?
什么是搜索引擎的缓存对象?
什么是搜索引擎的缓存结构?
什么是搜索引擎的缓存淘汰策略?
什么是搜索引擎的缓存更新策略(Refresh Policy)?
什么是谷歌三架马车?
什么是谷歌三架马车之一的GFS?
什么是谷歌三架马车之一的MapReduce?
什么是谷歌三架马车之一的Bigtable?
什么是FST数据结构?
什么是SkipList的数据结构?
什么是BKD Tree的数据结构?
什么是搜索召回?
什么是搜索小流量?
什么是互联网毒瘤内容农场?
什么是暗网?
什么是深度网络搜索?
搜索引擎怎样爬取暗网?
什么是暗网?
搜索引擎为什么一定要抓取暗网?
常用的搜索技巧有哪些?
参考
搜索引擎的基本工作原理是什么?
用户发起请求后,大致的搜索流程如下:
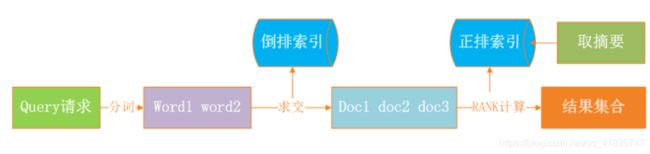
首先用切词组件做分词,把query分成多个word,然后多个word会从我们的倒排索引里面获取倒排拉链,在倒排拉链的基础上,会做求交计算来拿到所有命中的doc list。拿到doc list之后,我们希望能够把优质的网页反馈给用户,这时候我们还需要做rank计算。rank计算就是拿倒排里面的一些位置索引信息,包括在正排里面拿一些rank的属性特征信息做打分,最终会把分数比较高的Top N结果反馈用户。当然在前端web页面展示的时候,需要从正排中提取摘要信息,展示给用户。这就是整个的检索过程。
四代搜索技术发展的历史进程是什么?
将搜索引擎技术的发展分为4个时代:分类目录、文本检索、连接分析和用户中心。
史前一代:分类目录的一代
这个时代也可以成为“导航时代”,Yahoo和hao123是这个时代的代表。通过人工收集整理,把各类别的高质量网站或者网页分门别类罗列,用户可以根据分级目录来查找高质量的网站。这种方式是纯人工的方式,并未采取什么高深的技术手段。
采取分类目录的方式,一般被收录的网站质量都较高,但是这种方式可扩展性不强,绝大部分网站不能被收录。
第一代:文本检索的一代
文本检索的一代采用经典的信息检索模型,比如布尔模型、向量空间模型或者概率模型,来计算用户查询关键词和网页文本内容的相关程度。网页之间有丰富的链接关系,而这一代搜索引擎并未使用这些信息。早期的很多搜索引擎比如Alta Vista、Excite等大都采取这种模式。
相比分类目录,这种方式可以收录大部分网页,并能够按照网页内容和用户查询的匹配程度进行排序。但是总体而言,搜索结果质量不是很好。
第二代:连接分析的一代
这一代的搜索引擎充分利用了网页之间的链接关系,并深入挖掘和利用了网页链接所代表的含义。通常而言,网页链接代表的一种推荐关系,所以通过链接分析可以在海量内容中找出重要的网页。这种重要性本质上是对网页流行程度的一种衡量,因为被推荐次数多的网页其实代表了其具有流行性。搜索引擎通过结合网页流行性和内容相似性来改善搜索质量。
Google率先提出并使用PageRank链接分析技术,并大获成功,这同时也引进了学术界和其他商业搜索引擎的关注。后来学术界陆续推出了很多改进的链接分析算法。目前几乎所有的商业搜索引擎都采取了链接分析技术。
采用链接分析能够有效改善搜索质量,但是这种搜索引擎并未考虑用户的个性化要求,所以只要输入的查询请求相同,所有用户都会获得相同的搜索结果。另外,很多网站拥有者为了获得更高的搜索排名,针对链接分析算法提出了不少链接作弊方案,这样导致搜索结果质量变差。
第三代:用户中心的一代
目前的搜索引擎大都可以归为第三代,即以理解用户需求为核心。不同用户即使输入同一个查询关键词,但其目的也有可能不一样。比如同样输入“苹果”作为查询词,一个追捧iPhone的时尚青年和一个果农的目的会有相当大的差距。即使是同一个用户,输入相同的查询词,也会因为所在的时间和场合不同,需求有所变化。而目前搜索引擎大都致力于解决如下问题,如何能够理解用户发出的某个很短小的查询词背后包含的真正需求,所以这一代搜索引擎称之为以用户为中心的一代。
为了能够获取用户的真实需求,目前搜索引擎大都做了很多技术方面的尝试。比如利用用户发送查询词时的时间和地理位置信息,利用用户过去发出的查询词及相应的点击记录、历史信息等技术手段,来试图理解用户此时此刻的真正需求。
例如举一个很简单的例子,现在的搜索引擎都有SUG系统,即suggestion建议,我们输入一个query,搜索引擎会预测出我们想要搜索的单词: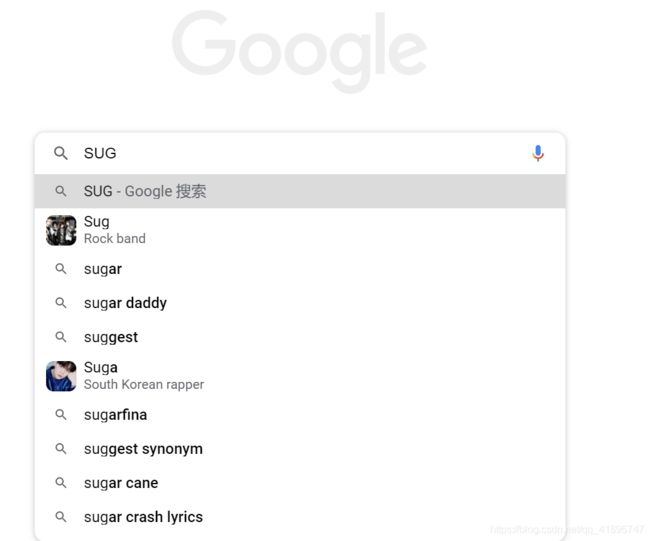
这个搜索建议极大提升了我们的搜索体验,是以用户为中心设计思想的典范。
什么是大搜?什么是垂搜?
大家有没有发现,现在的搜索习惯和十年前的搜索习惯完全不一样了。现在我们想要搜一个要去的地点/景区,会去高德/去哪儿/携程;想要买衣服,一般去淘宝搜索;想要听音乐,会去QQ音乐/网易云音乐;想要看某部电影,一般去爱奇艺/腾讯视频等等。而十年前,无论我们想要干啥,都会去百度一下/谷歌一下。现在互联网各大寡头圈地为王,每个公司都有自己擅长的领域,我们想去搜索某一类特定的知识,会打开特定的APP/网站,这就是垂类搜索(垂搜)。
- 综合领域:像百度、google、搜狗、360等,搜索全网内容,一般叫大搜。一般搜索的内容是互联网上的网页,多数是通过爬虫获取到,通过网页的标题和正文来搜索。
- 垂直领域:像视频、音乐、电商、小说等,只搜索特定领域的内容,一般叫垂搜或小搜。垂域搜索的数据,往往是非常结构化的,比如淘宝里的商品,优酷里的影片信息等,与网页相比,文本偏短。
什么是query?什么是index?什么是term?什么是doc?
-
query:搜索关键字,也叫keyword
-
doc:被搜索的内容,比如一个网页,一部影响,一件商品,在索引里是一条记录,都叫一个doc
-
QU:query understanding,查询理解,即对query进行分析,得到一些用户意图相关的信息,辅助检索
-
index:索引
-
term:query分词后,每个词,称为一个term
query分析包括哪些方面?
这是一个经典的NLP问题。query分析基本包涵三点:确定检索的粒度、Term属性分析、Query需求分析。
确定检索的粒度
所谓确定检索粒度,就是分词的粒度。我们会提供标准的分词,以及短语、组合词。针对不同的分词粒度返回的网页集合是不一样的。标准分词粒度越小,返回的结果越多,从中拿到优质结果的能力就越低。而短语和组合词本身就是一个精准的检索组合,相对的拿到的网页集合的质量就会高一些。
Term属性分析
这一块主要是涉及到两个点。
第一个点就是query中每一个词的term weight(权重)。权重是用来做什么的?每一个用户的query它本身都有侧重点。举个例子,比如“北京长城”这个query,用户输入这个词搜索的时候其实他想搜的是长城,北京只是长城的一个限定词而已,所以说在term weight计算的时候,长城是作为一个主词来推荐的。即使query只搜长城也会返回一个符合用户预期的结果,但是如果只搜北京的话,是不可能返回用户预期的结果的。
第二个就是term本身的一些紧密性。紧密性代表用户输入的query的一些关联关系。举个明显的例子,有些query是具有方向性的,比如说北京到上海的机票怎么买?多少钱?这本身是有方向性的语义。
Query需求分析
针对query本身我们要分析用户的意图是什么?当然也包括一些时效性的特征。举个例子,比如说“非诚勿扰”这个词,它有电影也有综艺节目。
如果说能够分析出用户本身他是想看电影还是看综艺节目,我们就会给用户反馈一个更优质的结果,来满足用户的需求。
什么是查询策略?
查询策略覆盖的工具就是我们整个引擎架构所要做的工作。查询策略主要包括四个方面的工作:检索资源、确定相关网页集合、结果相关性计算、重查策略。
检索资源
所谓检索资源就是我们从互联网上拿到的网页。从互联网上能拿到的网页,大概是万亿规模,如果说我们把所有网页拿过来,然后做建库做索引,在用户层面检索,从量级上来说是不太现实的。因为它需要很多的机器资源,包括一些服务资源,另外我们从这么大一个集合里面来选取符合用户需求的数据,代价也是很大的。所以说我们会对整个检索资源做一个缩减,也就是说我们会针对互联网上所有的抓取过的网页,做一个质量筛选。
质量筛选出结果之后,我们还会对网页做一个分类。我们拿到陌生的网页,会根据它本身的站点的权威性,网站本身的内容质量做打分。然后我们会对网页分类,标记高质量的网页,普通网页,时效性的一个网页,这样的话在用户检索的时候我们会优先选择高质量的网页返回给用户。当然从另外一个维度来讲,我们也会从内容上进行分类,就是说每个网页的title和qanchor信息,也就是锚文本信息,是对整篇文章的一个描述信息,也代表文章的主体。如果我们优先拿title和anchor信息作为用户的召回的一个相关url集合,那它准确性要比从正文拿到的结果质量要高。当然我们也会保留这种信息来提升它的召回的量。这是检索要准备的检索资源这一块。
确定相关网页集合
这一块的话基本上可以分为两点。
一个是整个query切分后的 term命中,能够命中query当然非常好,因为它能够反应相关数据,正常情况下,网站和用户query相关性是非常高的。
但是也会存在这样问题,所有的query全命中有可能返回网站数量不够,我们这时候就需要做一些term部分命中的一些策略。前面query分析中讲到了term weight的概念,我们可能会选择一些term weight比较重要的term来作为这次召回结果的一个term。整个确定相关网页集合的过程,就是一个求交计算的过程,后面我会再详细介绍。
结果相关性计算
我们拿到了相关的网页之后,会做一个打分,打分就是所说的结果相关性计算。我这里列举了两个最基础的计算。第一个是基础权值的计算,针对每个term和文章本身的相关性的信息。第二个就是term紧密度计算,也就是整个query里面的term在文章中的分布情况。
重查策略
为什么有重查策略,就是因为在用户检索过程中有可能返回的结果比较少,也有可能返回给用户的结果质量比较低,最差的就是结果不符合用户的真正意图。我们可能通过以下三个方式来解决这个问题,一是增加检索资源来拿到更多的结果;而是通过更小粒度的term,减掉一些不重要的term来拿到的结果,还有我们可能也会做一些query的改写以及query的扩展,来满足用户的意图。
从整个检索模型可以看到,我们要做的工作首先是query分析;第二我们需要把检索资源提前准备好,那就是所谓的索引;第三点是在一个query过来之后,我们通过求交计算确定相关的网页集合,然后通过相关性计算,把优质的集合返回给用户,最后如果结果不满足用户要求的话,我们可以做一个重查。
什么是搜索SUG?
绝大部分搜索都有SUG,就是suggestion的简称。具体效果如下:
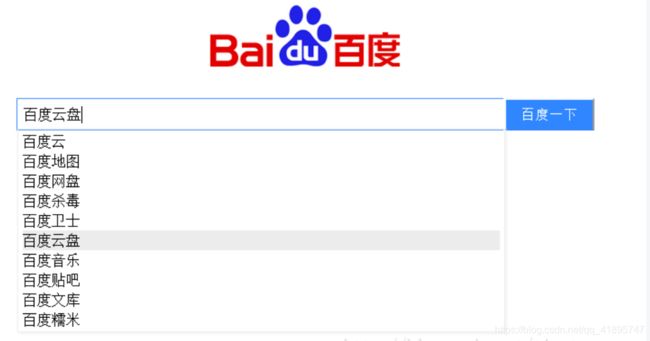
简单来说就是搜索会有联想功能,但是sug也会有缺点,因为现在JS响应速度远大于鼠标点击的速度,所以会有多次的请求对后端造成压力。
一般会根据IP、query ID等这些要素进行签名,一次搜索只请求一次后端,降低后端的压力。
感兴趣的可以看看这篇文章:https://blog.csdn.net/tim_tsang/article/details/39268189
什么是摘要索引?
摘要索引用于部分场景的搜索效率提升,摘要索引将文档所需返回展示的对应信息存储在一起,通过Doc_id可以定位该文档的存储位置,并获取对应的摘要信息,为用户提供摘要获取服务。摘要索引的结构和正排索引类似,但其功能不同。
什么是相关搜索?
相关搜索(related searches):google和百度搜索结果页的底部,都有展示相关搜索,即搜索query_a的用户,也喜欢搜索query_b, query_c等。

什么是搜索引擎cache缓存机制?
其实对于任意的后端来说,增加cache机制都是最有效优化手段。
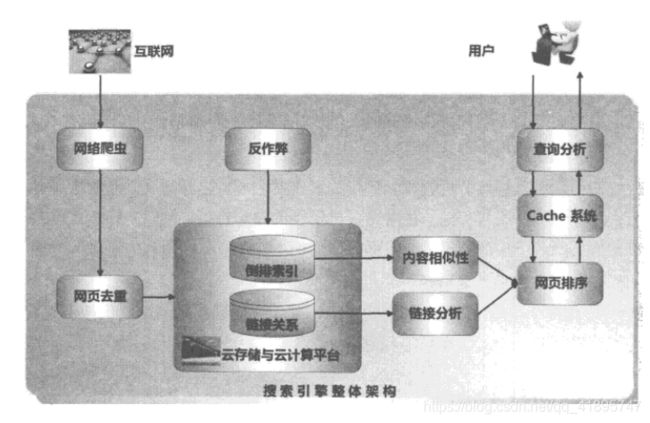
任何领域都有2-8定律,搜索引擎也不例外,80%的搜索都集中在20%的内容上。我们只要增加有效的cache,兜得住这80%的搜索量,就能极大程度上优化搜索体验。但是,什么样的query命中cache?cache在什么地方触发?cache的失效时间是怎样?cache什么时候更新?如何更新?等等,这些问题就是搜索架构设计的时候需要考虑到的。事实上,对于现在的搜索引擎来说,cache的命中率已经是很高很高,极大程度上优化了用户体验。
如下图所示,这个搜索架构在query分析后就加上了cache,如果命中cache,后面的操作就可以省略,归并广告等结果后就可以光速召回了。
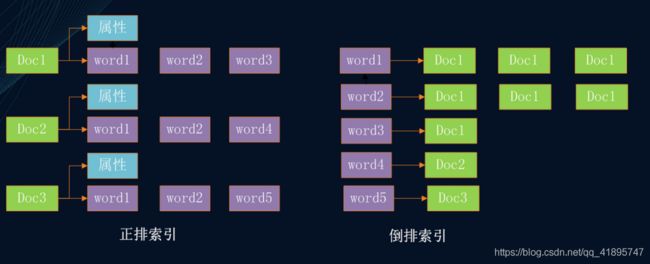
什么是正排索引?什么是倒排索引?
-
正排索引:以doc作为key,以这个doc包含的term或属性信息作为value,就是常规的数据库存储结构。便于通过docId,查询这个doc的属性信息。想像一下,如果要检索出所有包含“apple”的网页,需要将索引里所有doc遍历一遍。
-
倒排索引:与正排相反,以term作为key,以包含这个term的所有doc的ID作为value,构建出的KV结构。如果要检索出包含“apple”的网页,只需要以apple作为key,一把就能取出所有包含apple这个词的网页。
什么是内容农场?
随着搜索引擎的诞生而诞生。其本质是产生大量低质量内容的网站,内容来源可能是爬虫,也可能由写手产生。经营内容农场的人大多都擅长SEO,因此在搜索引擎中搜索对应关键字或者文章时,内容农场的网站往往排名在原创网站之上。
如果你是互联网从业者,那么使用搜索引擎去查找技术问题时,肯定会遇到一些排名靠前的回答,似是而非,排版混乱,那一般是复制粘贴型的内容产生者,这在中文搜索时更为常见。
内容农场无孔不入。在PC时代污染了搜索引擎,在移动互联网时代就污染启动页推送;即便是在微信这样封闭的生态圈中,他们也稳稳地生根发芽。公众号、小程序、视频号,都潜伏着内容农场的身影。
都说互联网时代是“信息爆炸”的时代,这点我不否认。互联网中存在着大量优质的内容,天文地理、古今中外,无所不包。但是,你可能永远都找不到。 内容农场看似人畜无害,但实际上却是种潜移默化的污染。一个高产的内容农厂,一个月可以产出一百万份文章,这个数字相当于四个英文版维基百科一年的出版数。
针对搜索爬虫,常见的内容作弊方式有哪些?
比较常见的内容作弊方式包括:
1. 关键词重复
对于作弊者关心的目标关键词,大量重复设置在页面内容中。因为词频是搜索引擎相似度计算中必然会考虑的因子,关键词重复本质上是通过增高目标关键词的词频来影响搜索引擎内容相似性排名。
2. 无关查询词作弊
为了能够尽可能多吸引搜索流量,作弊者在页面内容中增加很多和页面主题无关的关键词,这本质上也是一种词频作弊,即将原先为0的单词词频增加到非0词频,以此吸引更多搜索引擎流量。
比如有的作弊者在网页的末端以不可见的方式加入一堆单词词表。也有作弊者在正文内容插入某些热门查询词。甚至有些页面内容是靠机器完全随机生成或者利用其他网页的页面内容片段随机拼凑而成的。
3. 图片alt标签文本作弊
alt标签原本是作为图片描述信息来使用的,一般不会在HTML页面显示,除非用户将鼠标放在图片上,但是搜索引擎会利用这个信息,所以有些作弊者将alt的内容以作弊词汇来填充,达到吸引更多搜索流量的目的。
4. 网页标题作弊
网页标题作为描述网页内容的综述性信息,对于判断一个网页所讲述的主题是非常重要的启发因素。所以搜索引擎在计算相似性得分时,往往会增加标题词汇的得分权重。作弊者利用这一点,将与网页主题无关的目标词重复放置在标题位置来获得好的排名。
5. 网页重要标签作弊
网页不像普通格式的文本,是带有HTML标签的,而有些HTML标签代表了强调内容重要性的含义,比如加粗标记 ,段落标题
搜索引擎一般会利用这些信息进行排序,因为这些标记因素能够更好的体现网页的内容所表现的主题信息。作弊者通过在这些重要位置插入作弊关键词也能影响搜索引擎排名结果。
6. 网页元信息作弊
网页元信息比如网页内容描述区(meta description)和网页内容关键词区(meta keyword)是供制作网页的人对网页主题信息进行简短描述的,同以上情况类似,作弊者往往也会通过在其中插入作弊关键词来影响网页排名。
通过以上几种常见作弊手段的描述,我们可以看出,作弊者的作弊意图主要有以下几类:
1. 增加目标作弊词词频来影响排名;
2. 增加主题无关内容或者热门查询吸引流量;
3. 关键位置插入目标作弊词影响排名;
针对链接引擎中的链接分析技术,常见的链接作弊方法有哪些?
所谓“链接作弊”,是网站拥有者考虑到搜索引擎排名中利用了“链接分析”技术,所以通过操纵页面之间的链接关系,或者操纵页面之间的链接锚文字,以此来增加链接排序因子的得分,并影响搜索结果排名的作弊方法。常见的链接作弊方法众多,此节简述几种比较流行的作弊方法。
1.链接农场(Link Farm)
为了提高网页的搜索引擎链接排名,“链接农场”构建了大量互相紧密链接的网页集合,期望能够利用搜索引擎链接算法的机制,通过大量相互链接来提高网页排名。“链接农场”内的页面链接密度极高,任意两个页面都可能存在互相指向链接。图8-2展示了一个精心构建的链接农场。
2.Goolge 轰炸(Google Bombing)
“锚文字”是指向某个网页的链接描述文字,这些描述信息往往体现了被指向网页的内容主题,所以搜索引擎往往会在排序算法中利用这一点。
作弊者通过精心设置锚文字内容来诱导搜索引擎给予目标网页较高排名,一般作弊者设置的锚文字和目标网页内容没有什么关系。
几年前曾经有个著名例子,采用“Google轰炸”来操控搜索结果排名。当时如果用Google搜索“miserable failure”,会发现排在第二位的搜索结果是美国时任总统小布什的白宫页面,这就是通过构建很多其它网页,在页面中包含链接指向目标页面,其链接锚文字包含 “miserable failure”(参考图8-3和图8-4)。通过这种方式就导致了人们看到的搜索结果。
3.交换友情链接
作弊者通过和其它网站交换链接,相互指向对方的网页页面,以此来增加网页排名。很多作弊者过分地使用此种手段,但是并不意味这使用这个手段的都是作弊网站,交换友情链接的做法也是正常网站的常规措施。
4.购买链接
有些作弊者会通过购买链接的方法,即花钱让一些排名较高的网站的链接指向自己的网页,以此提高网站排名。
5.购买过期域名
有些作弊者会购买刚刚过期的域名,因为有些过期域名本身的PageRank排名是很高的,通过购买域名可以获得高价值的外链。
6.“门页”作弊(Doorway Pages)
“门页”本身不包含正文内容,而是由大量链接构成,而这些链接往往会指向同一网站内的页面,作弊者通过制造大量的“门页”来提升网站排名。
什么是页面隐藏作弊?
“页面隐藏作弊”通过一些手段瞒骗搜索引擎爬虫,使得搜索引擎抓取的页面内容和用户点击查看到的页面内容不同,以这种方式来影响搜索引擎的搜索结果。常见的页面隐藏作弊方式有:
1. IP地址隐形作弊(IP Cloaking)
网页拥有者在服务器端记载搜索引擎爬虫的IP地址列表,如果发现是搜索引擎在请求页面,则会推送给爬虫一个伪造的网页内容,而如果是其它IP地址,则会推送另外的网页内容,这个页面往往是有商业目的的营销页面。
2. HTTP请求隐形作弊(User agent Cloaking)
客户端和服务器在获取网页页面的时候遵循HTTP协议,协议中有一项叫做“用户代理项”(user agent)。搜索引擎爬虫往往会在这一项有明显的特征(比如Google爬虫此项可能是:Googlebot/2.1),服务器如果判断是搜索引擎爬虫则会推送和用户看到的不同的页面内容。
图8-5是一个HTTP请求隐藏作弊的例子,作弊网站服务器推送给搜索引擎爬虫的页面是讲述减肥食品的内容,而推送给页面访问者的则是减肥产品销售推广页面。这样当用户在搜索减肥知识的时候就会直接访问减肥产品页面,从而达到作弊者的商业目的。
3. 网页重定向
作弊者使得搜索引擎索引某个页面内容,但是如果是用户访问则将页面重定向到一个新的页面。
4.页面内容隐藏
通过一些特殊的HTML标签设置,将一部分内容显示为用户不可见,但是对于搜索引擎来说是可见的。比如设置网页字体前景色和背景色相同,或者在CSS中加入不可见层来隐藏页面内容。将隐藏的内容设置成一些与网页主题无关的热门搜索词,以此增加被用户访问到的概率。
什么是网页去重算法?
网页去重算法-怎么和搜索引擎算法做斗争
不知道大家有没有仔细去研究过搜索引擎爬虫抓取的一个过程,这里可以简单的说一下:
一、定(要知道你准备在哪个范围或者网站去搜索);百度提交,合作DNS,已有爬虫入口
二、爬(将所有的网站的内容全部爬下来)
三、取(分析数据,去掉对我们没用处的数据); 去重:Shingle算法》SuperShinge算法》I-Match算法》SimHash算法
四、存(按照我们想要的方式存储和使用)
五、表(可以根据数据的类型通过一些图标展示)
搜索引擎简单的看就是抓取到页面到数据库,然后存储页面到数据库,到数据库取出页面进行展现,所以这里面是有很多算法的,到现在搜索引擎为了防止作弊,更好的满足用户需求对很多算法已经进行改进,具体的有哪些基础算法大家可以自己去了解(点击: SEO算法 -进行了解 )。今天主要讲的是源码去重,也就是第三部取。
通过上面几个步骤可以了解到,搜索引擎不可能把互联网上的所有页面都存储到数据库,在把你的页面存到数据库之前是要对你的页面进行检查的,检查你的页面是否跟已经存储的页面重复了,这也是很多seoer要去做伪原创增加收录几率的原因。
根据去重的基础算法可以了解到页面去重它是分代码去重和内容去重的,如果我把别人网站的模板程序原封不动的拿过来做网站,那我需要怎么做代码去重呢?今天分享一下怎么做代码去重。

如图,可以看到在每个模板的class后面加上自己的特征字符,这样是既不不影响css样式,又可以做到代码去重的效果,欺骗搜索引擎,告诉它我这是你没有见过的代码程序。
很多东西说出来简单,都是经过很多实操总结出来的,大家需要多去操作,那给大家提一下发散的问题。
如果去重算法有效的话,互联网上面这么多相同程序的网站他们的代码几乎相同(很多程序用相同的模板:织梦,帝国等),他们的权重排名为什么都可以做的很好?
去重算法他有一个发展升级的,简单的说就是最开始的Shingle算法,到后面的SuperShinge算法再升级到I-Match算法之后到SimHash算法,现在每个搜索引擎的算法都是在这些基础的算法上面进行升级改进,我们可以了解大致的原理。
简单点说就是搜索引擎给每个页面一个指纹,每个页面分层很多个小模块,由很多个小模块组成一个页面,就像指纹一样由很多条线组成。
知道这个原理的话我们就知道现在大家所做的伪原创是没有用的,打乱段落顺序,改一些词,是不会影响页面指纹的。
真正的可以做到抄别人内容,还不被判定为重复内容要怎么去做呢?
首先了解一个机制,搜索引擎存储的页面数据他是分层级的,简单点说就是你输入一个搜索词的时候它优先排名的是优质层的数据,其次再是普通层,劣质层。平时看到的很多高权重平台他的内页的排名也可以超过很多网站首页有这里面的原因。
当2个网站程序代码几乎相同,内容也几乎相同的时候,搜索引擎怎么去发现他们是重复的呢?
因为搜索引擎存储的数据量很大,不可能每存储一个新页面就把之前所有存储的页面拿出来对比,那他只能是通过算法判断拿出与新页面标题描述相关的优质层的页面,来与新页面进行重复度对比。如果重复度达到某个值那么他就会被判断为重复内容,就被去重算法给去掉不被收录,如果没有被判定为重复内容则被收录到劣质层。当你想对这个新页面做优化让他的排名有所提,进入到优质层,那它相应的要求也会提升,它会调取更多的页面数据出来,与其进行对比,而不仅仅是通过调取相关标题描述的数据。这样的话就会被搜索引擎发现,它不是原创的,通过综合的一个评估不给予它进入到优质层。
这也是我们看到的一个现象,为什么很多抄的内容可以收录,但是没办法获得好的排名。
如果我们抄了一篇文章,但是我们用了不同的标题,那对于搜索引擎来说,他在劣质层里面没办法发现他是重复的。这也是解释很多奇怪的现象,比如图中:
一个克隆的网站,因为标题的不同,搜索引擎在抓取去重过程中没有发现它,但是之后如果这个页面想要进去到优质层数据库,它就会被发现是重复的,不会给予好的排名展现。
总结:市面上面的伪原创工具是没有用的,没有影响要页面的指纹,如果非要抄别人的修改标题即可,但是不会获得好的排名。在新站初期可以用改标题的方法增加收录,增加网站蜘蛛,中期开始要自己做内容,为获得好的排名展现做铺垫。
百度搜索引擎的缓存机制是什么?
缓存就是临时文件互换区,是可以开展高速数据交换的存储器,它先于内存与CPU互换统计数据,因而速度很快。如今以便加速客户查询的响应速度,缓存基本上变成百度搜索引擎的标准配置。搜索引擎会把一些客户常常检索的关键词的搜索放进到缓存中,那样当该关键词再度被搜索时,就可以立即从内存中读取搜索结果,而无须再从索引库中开展再次查找和排行。缓存体制的导入,不但加速了搜索引擎对用户搜索的反应速度,也降低了搜索引擎对数据的反复测算。
用户的搜索请求中,少数查询词占了查询总数量的相当大的占比,而大部分查询词单独出现的频次都很少,类似长尾理论。因而搜索引擎把用户常常查寻的“少量”关键词的搜索结果储放于缓存中,就可以解决大部分用户的搜索请求了。整个搜索引擎的缓存体制中还会涉及到缓存淘汰和缓存更新体制。
由于搜索引擎的缓存也并不是无限的,毫无疑问也有载满的时候,这时就必须有效的淘汰体制,把应用频率小的搜索去除,填补进来应用频率大的搜索结果,来确保缓存文件中的內容可以响应及命中当下尽量多的用户搜索请求。同时网页和索引库中的文档內容随之时间的转变也会进而变化,以便促使缓存中的结果和网页同步,这时就必须有效的缓存更新体制。
这解释一下缓存更换体制:百度搜索引擎以便节约资源,并不是对缓存中的內容开展实时更新,只是会挑选在深夜等搜索请求较为少的时间范围开展更新缓存,因此用户在不一样时间搜索相同关键词获得的结果将会是不一样的,可是通常在较短期内的反复搜索会获得同样的搜索。如今的搜素引擎会分析搜索关键词的特性,并依据搜索关键词的特性调节缓存的更新频率,例如,如今百度搜索的“最新基本信息”“最新有关微博”等实用性搜索的缓存更新频率和一般词缓存更新的频率毫无疑问是不一样的。必须表明的是,如今大型搜索引擎的缓存并不是简单地直接缓存文件关键词的搜索结果,而是有着很繁杂的缓存结构和统计数据,通常是多级结构的,一起提高百度搜索引擎的响应速度和缓存数据的命中率范畴。
什么是淘宝搜索引擎的缓存机制?
当淘宝搜索引擎接收到用户查询的时候,会首先在缓存系统查找,看缓存内是否包含用户查询的搜索结果,如果发现缓存已经存储了相同查询的搜索结果,则从缓存内读出结果展现给用户;如果缓存内没有找到相同的用户查询,则将用户查询按照常规处理方式交由淘宝搜索引擎返回结果,并将这条用户查询的搜索结果及中间数据根据一定策略调入缓存中,这样下次遇到同样的查询可以直接在缓存中读取,以加快用户响应速度并减少淘宝搜索引擎系统的计算负载。
淘宝缓存系统包含两个部分,即缓存存储区及缓存管理策略。缓存存储区是高速内存中的一种数据结构,可以存放某个查询对应的搜索结果,也可以存放搜索中间结果,比如一个查询单词的倒排列表。
缓存管理策略又包含两个子系统,即缓存淘汰策略和缓存更新策略。
之所以需要缓存淘汰策略,是因为不论给缓存分配多大空间,当系统运行到一定程度,很可能缓存已经满了,当有新的需要缓存的内容要进入缓存时,需要根据一定的策略,从缓存中剔除一部分优先级别较低的缓存内容,以腾出空间供后续内容放入缓存存储区,如何选择替换项目是缓存淘汰策略需要考虑的问题。
另外,使用缓存系统是有一定风险存在的,即缓存内容和索引内容不一致问题。如果淘宝搜索引擎索引的文档集合是静态文档,这个问题是不存在的,因为既然文档集合没有发生任何变化,只要搜索引擎的排序算法不更改,那么针对固定的用户查询,其对应的搜索结果是固定不变的,所以缓存里面的内容永不过期。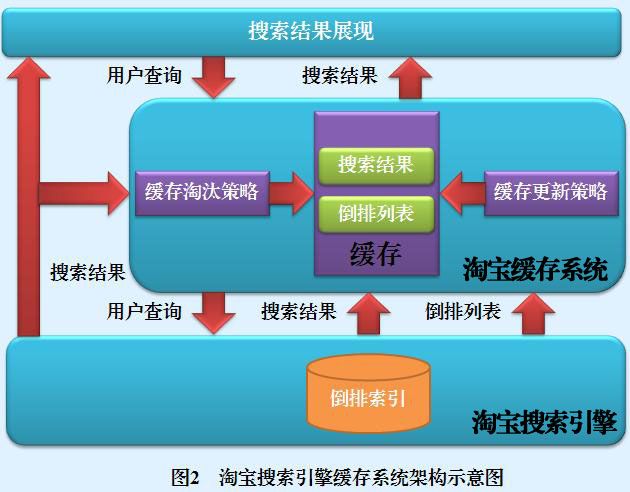
但是在一般应用场景中,淘宝搜索引擎要处理的文档集合是动态变化的,可能会面临新加入的文档,也可能会删除旧的文档或者旧的文档内容发生了变化。当索引己经反映了这种变化,而缓存数据没有随着索引做出相应的变化,那么就会发生缓存内容和索引内容不一致的问题。缓存更新策略就是用来维持两者一致性的。
对淘宝搜索引缓存系统来说,一个优秀的缓存系统,希望能够在以下儿个方面表现出色。
1、最大化缓存命中率
所谓缓存的命中率,就是说一段时间内所有用户发出的查询中,有多大比例的查询对应的搜索结果是从缓存中获得的。这个比例越高,说明缓存管理策略越成功,就有效地节省了淘宝搜索引擎的计算成本。具体而言,不同的缓存淘汰策略就是采用不同算法来获得尽可能高的命中率。
2、缓存内容与索引内容保持一致性
好的缓存管理策略应该避免出现缓存内容与索引内容不一致的状况,因为这种不一致会影响用户的搜索体验,所以缓存系统需要有优秀的缓存更新策略来达到这个目的。
什么是搜索引擎的缓存对象?
对于搜索引擎缓存,在存储区内存放的数据对象并不是唯一的,可以是搜索结果,也可以是某个查询词汇对应的倒排列表,或者是一些搜索的中间结果。
最常见的缓存对象类型是用户查询请求所对应的搜索结果信息,比如宝贝的标题、宝贝URL等。图3给出了将搜索结果作为缓存内容的示例,缓存里保存了“连衣裙" ,“运动鞋”等用户查询,以及其对应的搜索结果。如果此时有另外一个用户愉入“连衣裙”作为查询,则淘宝搜索引擎首先在缓存里面查找,发现己经存在这个用户查询项,则直接提取原先的搜索结果作为输出返回给用户。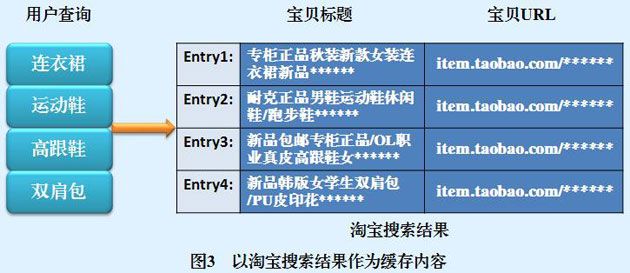
另外一种比较常见的存储对象类型是查询词汇对应的倒排列表(Posting List)。图4是以单词倒排列表作为缓存内容的一个示例图,从图中可以看出,以搜索结果作为缓存内容的情况下,用户查询即使包含多个单词,也是作为一个整体存储在缓存槽里的;而以单词倒排列表作为缓存内容的方式,其存储粒度相对会小些,是以用户查询的分词结果存储在缓存槽里的。比如“夏季 连衣裙”这个用户查询,在搜索结果作为缓存内容情形下占用一项缓存槽,而在缓存倒排列表方式下会占用两个缓存槽,“夏季”和“连衣裙”各自占用一个存储位置。
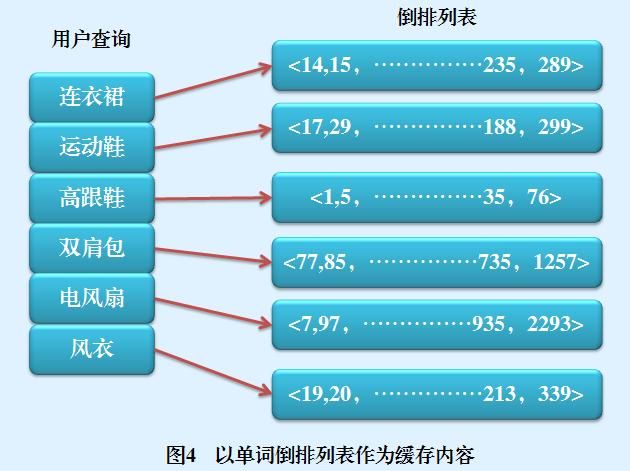
这两种不同的缓存存储内容各自有其优缺点,对于搜索结果型缓存来说,其用户查询响应速度非常快,因为只需要进行查找运算即可返回结果,但是其粒度比较粗,比如在如图3所示的例子中,如果此时用户输入查询“连衣裙 韩版”,则淘宝搜索引擎会发现缓存里面并不存在这个查询,只能按照正常搜索流程,去调用索引数据并进行网页排序等运算。但是倒排列表型缓存因为粒度较小,会发现“连衣裙”这个查询词汇已经在缓存中了,此时只需要从存储在硬盘的倒排索引中读取“韩版”这个词汇的倒排列表数据,然后进行排序运算即可返回结果。由这个例子可以看出,倒排列表型缓存粒度小,所以命中率高,但是因为保存的只是倒排列表这种中间数据,所以仍然需要进行后续的计算才能返回最终结果,在用户响应效率方面慢于搜索结果型缓存。而搜索结果型缓存粒度大,如果在缓存内命中用户查询,则很快给出最终结果,但是命中率要低于倒排列表型缓存。
另外,搜索结果型缓存因为征个搜索结果的大小是可以预估的(一般取前列的K个搜索结果),所以管理起来比较简单,而倒排列表型缓存需要缓存某个单词的倒排列表,而不同单词的倒排列表大小差异很大,如果遇到一个非常大的倒排列表,可能会对目前的缓存空间造成较大影响,甚至被迫移出经常使用的用户查询缓存项,所以如何管理倒排列表型缓存存储区相对而言比较复杂。
以上两种缓存对象是比较常见的缓存类型,还有一种不太经常使用的方式,即保留两个经常搭配出现单词的倒排列表的交集,以这种中间结果形式作为缓存内容。因为用户查询有很大比例是由2个或者3个单词组成的,对于多词构成的用户查询,搜索引擎在从硬盘读出每个词汇的倒排列表后,需要进行文档队列的交集运算。而如果能够事先将这些交集运算的计算结果缓存起来,则可以避免后续的交集运算,提高搜索系统返回结果的速度。但是这种词汇组合的数据量非常大,都放置到内存中往往很困难,所以一般这种中间结果会存储在磁盘上。这种类型的缓存不能单独使用,但是可以作为多级缓存中的一个缓存级别存在,对其他类型的缓存起到补充作用。
什么是搜索引擎的缓存结构?
搜索引擎缓存的结构设计可以有多种选择,最常见的是单级缓存,也可以设计为二级甚至是三级缓存结构。
单级缓存是一种最常见也最简单直接的缓存结构,缓存系统中只包含一个单一缓存,配以缓存管理策略构成了整个缓存系统。图5左方和右方分别是搜索结果型和倒排列表型单级缓存示意图。
尽管单级缓存只包含一级缓存,但是对于不同缓存对象类型来说,其内部处理流程有一定差异。搜索结果型缓存首先在缓存中查找是否包含用户查询,如果存在则直接将搜索结果返回,否则对用户查询进行处理,由搜索系统返回搜索结果并加入缓存中,之后将搜索结果返回给用户。对于倒排列表型缓存,其处理步骤正好相反,查询处理阶段首先将用户查询分词,之后在缓存中查找这些单词对应的倒排列表,如果所有单词的倒排列表都在缓存中,则由查询处理模块根据单词倒排列表对搜索结果进行排序,并将搜索结果返回给用户。如果发现某些单词的倒排列表不在缓存中,会首先从磁盘读入单词对应的倒排列表,将其放入缓存,之后讲行查询处理步骤。
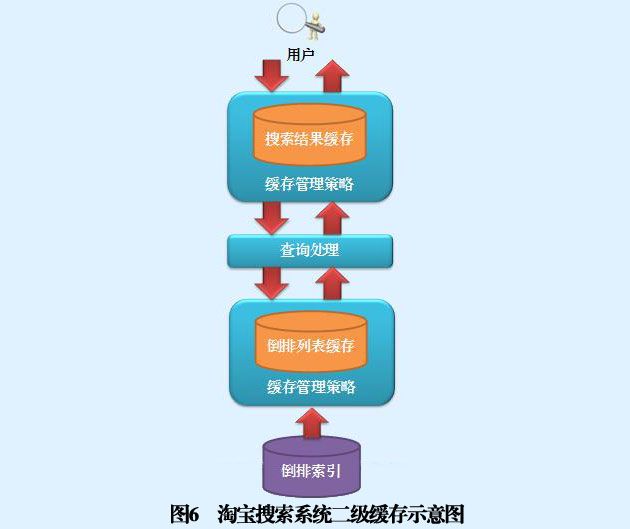
二级缓存结构由两级缓存串联构成,第1级缓存是搜索结果型缓存,第2级缓存是倒排列表型缓存,图6是二级缓存示意图。当系统接收到用户查询时,首先在一级缓存查找,如果找到相同查询请求,则返回搜索结果;如果在一级缓存没有找到完全相同的查询,则转向二级缓存查找构成查询的各个单词的倒排列表,如果某些单词的倒排列表没有在二级缓存中找到,则从磁盘读取对应的倒排列表,进入二级缓存;之后,对所有单词的倒排列表进行求交集运算并根据排序算法排序输出最相关的搜索结果,将相应的用户查询和搜索结果放入一级缓存进行存储,并返回最终结果给用户。采用两级缓存结构的出发点在于能够融合搜索结果型缓存的用户快速响应速度和倒排列表型缓存的命中率高这两个优点。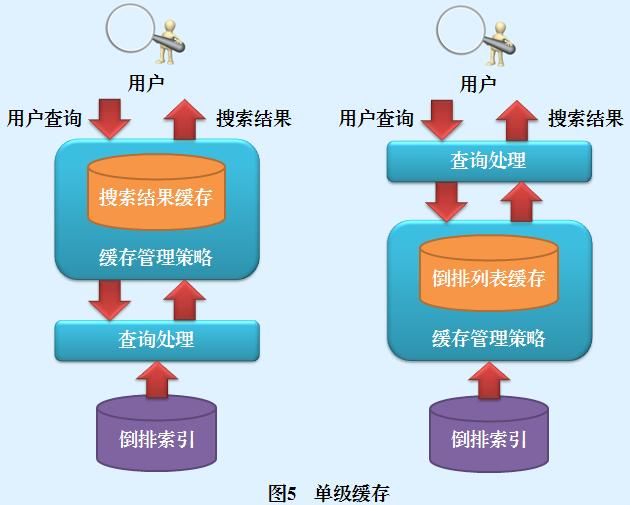
什么是搜索引擎的缓存淘汰策略?
缓存淘汰策略是任何缓存必须配备的管理策略。因为缓存的大小总是有限的,当缓存已满的时候,如果有新的缓存项需要加入,那么必须从已有的缓存项中剔除相对最不重要的项目,而不同的缓存淘汰策略就是根据不同的算法来衡量项目的重要性,并剔除掉最不重要项目占用的内存空间。缓存淘汰策略方法众多,从宏观角度,可以将其分为动态策略和静态动态混合策略。
动态策略
动态策略的缓存数据完全来自于在线用户查询请求,这种缓存策略的基本思路是:对缓存项保留一个权重值,这个权重值根据查询命中情况动态调整,当缓存已满的情况出现时,优先淘汰权重值最低的那个缓存项,通过这种方式来腾出空间。比较常见的动态策略包括:LRU策略、LandLord策略及SLRU等改进策略。
LRU策略:最近最少使用策略(Least Recently Used)
LRU淘汰策略是计算机领域使用非常广泛的缓存替换算法,在操作系统内存管理和Web页面缓存等领域也发挥着重要作用。LRU策略的基本思想是:当缓存已满时,将在设定的时间范围内使用次数最少的项目剔除出缓存,也就是将在设定时间段范围内最少访问的用户查询剔除掉。
在实际系统中,往往为每个缓存项设置一个计数器,将命中查询的计数器清零,与此同时,其他查询计数器加1。如果缓存己满,则将计数器数值最大的项目剔除出缓存。LandLord策略
LandLord策略是一种加权缓存策略(Weighted Cache)。其基本计算流程如下:当一个缓存项插入缓存的时候,会根据缓存项能够获得收益和缓存项所占内存大小的比率设定一个过期值 (Deadline),可以将这个比率理解为系统缓存这个项目的性价比。如果缓存已满,需要剔除项目的时候,选择过期值最小的项目进行淘汰,即淘汰性价比 最低的项目。同时,其他未被淘汰的项目对应的过期值都减去被淘汰项目的过期值,如果一个查询请求在缓存中命中时,会相应地将其过期值根据一定策略调大。
SLRU策略:大小自适应LRU (Size-adjusted LRU)
SLRU策略是对LRU方法的改进。缓存被分为两个部分:非保护区域和保护区域。每个区域的缓存项都按照最近使用频度由高到低排序,频率高端叫做MRU,低端的叫做LRU。如果某个查询没有在缓存中找到,那么将这个查询放入非保护区域的MRU端;如果某个查询在缓存中命中,则把这个查询记录放到保护区的MRU端;如果保护区已满,则把记录从保护区放入非保护区的MRU,这样保护区的记录最少要被访问两次。淘汰机制是将非保护区的LRU端缓存项淘汰。
混合策略
动态策略的缓存数据完全来自于在线用户查询请求,混合策略与此不同,其缓存数据一方面来自于在线用户查询,一方面来自于搜索日志等历史数据。目前效果较好的混合策略包括SDC策略和AC策略。图7是这种策略的示意图。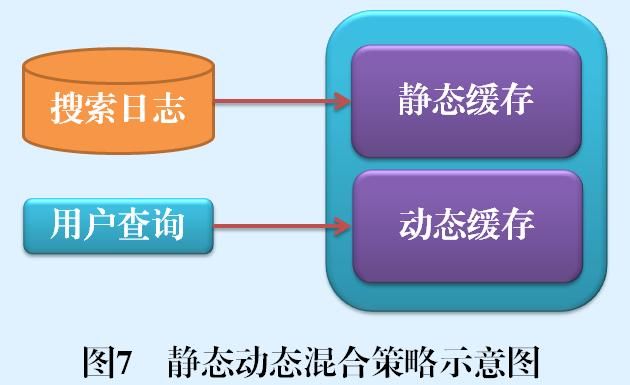
SDC策略:静态动态混合缓存策略(Static and Dynamic Caching)
SDC策略是一种混合缓存策略,SDC将缓存切割为两个部分,一个静态缓存与一个动态缓存。所谓静态缓存,即缓存内容是事先根据搜索日志统计出的最高频的那部分查询请求,在一定时间范围里是相对不变的;而动态缓存则可以配合使用LRU等其他缓存管理策略,根据用户查询请求不断更换内容。通过同时使用静态缓存和动态缓存,可以有效增加缓存请求命中率。SDC是目前效果最好的缓存策略之一。
AC策略:准入策略(Admission Control)
准入策略是类似于SDC策略的一种方法。该方法也将缓存分为两个部分,分别存储高频出现的历史用户查询和动态出现的用户查询及其对应的搜索结果。与SDC不同之处在于:SDC的静态缓存所存储的高频用户查询是完全从过去的搜索日志统计得来的静态内容,而AC策略则综合了搜索日志的统计数据、查询长度等多个判断因素,以此来预测某个查询是否会在未来被多次访问,如果判断是,则放入高频用户查询缓存。
什么是搜索引擎的缓存更新策略(Refresh Policy)?
如果搜索引擎的索引内容不发生变化,缓存的内容就总是和索引系统保持一致。但是淘宝搜索引擎索引经常更新,如果索引内容发生变化,而缓存内容不随着索引变动,会导致缓存内容和索引内容的不一致,这种不一致对于用户的搜索体验会造成负面影响。缓存更新策略就是通过一定的技术手段尽可能保持缓存内容和索引内容的一致性。
目前很多搜索引擎使用简单的更新策略,即在搜索引擎比较繁忙的时候不考虑缓存更新问题,而等到搜索引擎请求很少的时候,比如午夜等时间段,将缓存内的内容批量进行更新,使缓存内容保持和索引内容的一致。这种简单策略适合索引更新不是非常频繁的应用场景,对于索引更新频繁的场景,需要相对复杂些的缓存更新策略。
根据缓存内容和索引内容联系的密切程度,目前的缓存更新策略可以分为两种:缓存——索引密切耦合策略和缓存——索引非耦合策略。
缓存——索引密切耦合策略在索引和缓存之间增加一种直接的变化通知机制,一旦索引内容发生变化则通知缓存系统,缓存系统根据一定的方法判断哪些缓存的内容发生了改变,然后将改变的缓存内容进行更新,或者设定缓存项为过期,这样就可以紧密跟踪并反映索引变化内容。这种密切耦合策略在实际实现时是非常复杂的,因为频繁的索引更新导致频繁的缓存更新,对系统效率及缓存命中率都会有直接影响。图8是一个缓存——索引密切耦合策略的示意图。当有新的索引文档进入淘宝搜索引擎时,系统会对文档内容进行分析,抽取出文档中得分较高的索引词汇,并将这些词汇及其得分传递给失效通知模块,因为如果缓存中的查询包含这些索引词汇的话,很可能该文档将会使得缓存内容失效,失效通知模块会评估哪些缓存项需要进行内容更新,如果某项缓存项需要更新,则提取最新的缓存内容更新旧缓存项。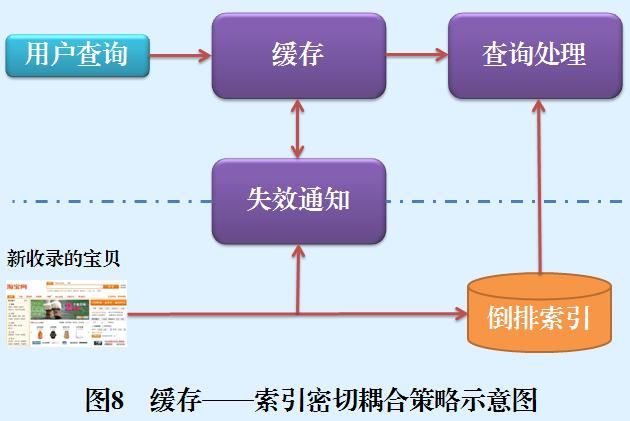
缓存——索引非耦合策略则使用相对简单的策略,当索引变化时并不随时通知缓存系统进行内容更新,而是给每个缓存项设定一个过期值(Time To Live),随着时间流逝,项会逐步过期。通过这种方式可以将缓存项和索引的不一致尽可能减小。淘宝搜索引擎就是采用了用了缓存——索引非祸合策略来维护缓存内容的更新,这就是淘宝搜索系统中下架时间的最根本的来源。
什么是谷歌三架马车?
GFS(Google File System)、MapReduce、Bigtable
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车。
这是谷歌搜索安身立命的根本,三驾马车横空出世,奠定了谷歌搜索的霸主地位,这里面的历史故事可以去看看吴军博士的《数学之美》。
时至今日,如果我们拉长时间轴到20年为一个周期来看呢,这三驾马车到今天的影响力其实已然不同。MapReduce作为一个有很多优点又有很多缺点的东西来说,很大程度上影响力已经释微了。BigTable以及以此为代表的各种KeyValue Store还有着它的市场,但是在Google内部Spanner作为下一代的产品,也在很大程度上开始取代各种各样的的BigTable的应用。而作为这一切的基础的Google File System,不但没有任何倒台的迹象,还在不断的演化,事实上支撑着Google这个庞大的互联网公司的一切计算。
什么是谷歌三架马车之一的GFS?
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
Bigtable
Bigtable实现在Google File System的基础上,它关心数据的内容,根据的数据的内容建立数据模型,对外提供读写数据的接口。
数据模型
Bigtable基本的数据结构和关系型数据库类似,都是以行列构成的表,但是,它还另外增加了新的维度——时间。也就是说,在行列确定的情况下,一个单元格(Cell)中有多个以事件为版本的数据。Bigtable用(row:string, column:string, time:int64) → string表示映射关系。下图为论文中给出的一个例子。
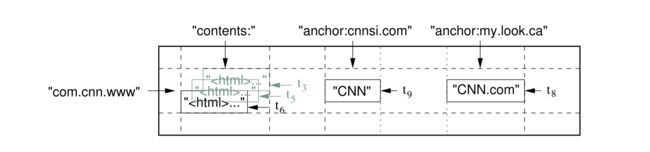
如果想要在表中查询指定版本的内容,我们需要指出行,列,及版本。比如(“com.cnn.www”,“anchor:cnnsi.com”,t9)→ "CNN"。我个人猜想,增加时间这个维度是因为“三驾马车”被设计出来的时候主要是为了支持搜索引擎,搜索引擎可能需要保留多个时间段的网页数据,而GFS也使用追加(Append)作为数据的主要修改方式,所以增加时间戳作为版本既充分利用了GFS的特性,也能满足业务的需求。
另外,Bigtable还把多个Column Keys并入到被称为Column Family的集合中,并将Column Family作为访问控制的基础单元。我认为,这种方案其实是一种事务(Transaction)的实现方案。传统的事务以行为基本操作单位,在读写时对行上锁以实现隔离,而Bigtable则是以Column Family为单位,这里的访问控制其实就是锁的思想。
相关组件
在介绍系统的整体架构之前,我们要对Bigtable用到的两个重要组件有一些了解。由于Bigtable是分布式的数据库,在节点之间的协调上需要额外的处理,这里,Bigtable使用了Google内部的Chubby。我们可以把Chubby看做是Zookeeper,因为Zookeeper本质也就是Chubby的开源版本。另一方面,为了加快数据的查找和存储效率,Bigtable在存储数据之前都进行了排序,而此处用到的存储文件文论称之为SSTable(Sorted String Table)。
在Bigtable中,由于单个表(Table)存储的数据可能相当地多,那么读写的效率就会十分低下,于是Bigtable将Table分割为固定大小的Tablet,将其作为数据存储和查找的基本单位。每当Table增加了这里要说明的是,tablet是数据存储的基本单元,是用户感知不到的。而Column Family则是访问的基本单元,是编程时指定的,两者一前一后,不是一个概念。
Tablet 定位
因为是在分布式系统中,那么每个Tablet所在的机器不同,需要记录相关信息(METADATA)对其进行管理。而存储这些METADATA又需要分布式的系统,所以Bigtable又将这些METADATA的METADATA记录在一个文件中,并将这个文件的位置保存在Chubby中。总结一下,Bigtable有以下三层结构:
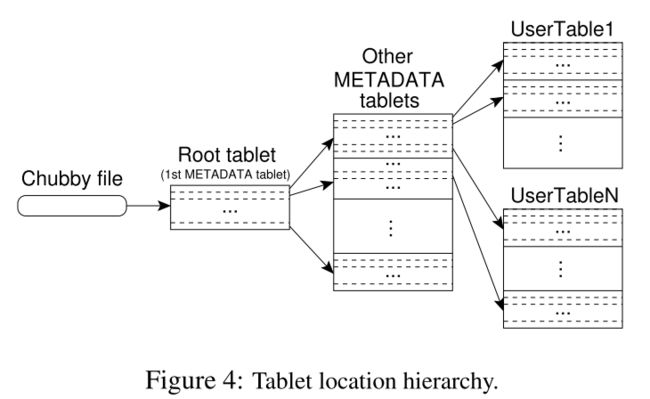
- 在Chubby中保存着Root Tablet的位置
- Root Tablet中保存着METADATA Table中所有 Tablet 的位置
- METADATA Table中保存着所有存储数据的Tablet的位置
这其中有几点值得注意。由于Root Tablet的特殊性,哪怕它的数据量再大,它也不允许被分割。METADATA tables被读取到内存中以加快速度,其中存储的是以开始和结尾的Row Key作为键,tablet位置作为值的映射。
如果客户端希望读取特定的数据,那么它会以此读取Chubby中的文件,Root Tablet,METADATA Tablet,最后读取存储改数据的Tablet。同时,为了加快读取的速度,它会将这些信息缓存到本地,直到信息失效。
Tablet分配
在谈Table分配之前,论文先讨论了怎么处理成员变更的问题。类似于GFS,Bigtable使用Master节点来管理这些相关的事情。
首先,Bigtable使用Chubby来检测Tablet Server的变化。这里的操作和Zookeeper的用法类似,当有新节点加入时,它需要在Chubby中新建一个对应的文件,并获取该文件的锁。由于所有的节点在Chubby中都有对应的文件,那么Master可以通过监听Chubby来获取所有Tablet Server的信息。这里有两种节点失效的情况,一种是仅仅回收了锁但是文件还在,这种情况很可能是节点崩溃了。由于节点不能自己退出,所以在Master节点得到该文件的锁后,它会将文件删除,以此表示节点退出。另一种情况是,文件已经被删除,这种情况说明节点是主动退出系统,那么可以直接重新分配Tablet给其他节点即可。
在正常的情况下,系统中会有大量数据写入,Master需要负责将这些数据分配到合适的Tablet Server。Bigtable并没有明确指出分配所使用的的算法,但是它提出了一个要求。为了保证数据的一致性,同一时间,一个 Tablet只能被分配给一个Tablet Server。Master通过向 Tablet Server 发送载入请求来分配 Tablet。如果该载入请求被Tablet Server接收到前Master仍是有效的,那么就可以认为此次 Tablet 分配操作已成功。
在这里,我们还要考虑Master崩溃的情况,论文中描述了Master恢复的步骤如下:
- 在 Chubby 上获取 Master 独有的锁,确保不会有另一个 Master 同时启动
- 从 Chubby 了解在工作的 Tablet Server
- 从各个 Tablet Server 处获取其所负责的 Tablet 列表,并向其表明自己作为新 Master 的身份,确保 Tablet Server 的后续通信能发往这个新 Master
- Master 确保 Root Tablet 及
METADATA表的 Tablet 已完成分配 - Master 扫描
METADATA表获取集群中的所有 Tablet,并对未分配的 Tablet 重新进行分配
其中,第四步是为了第五步的正确执行。
读写Tablet
上面我们谈了Bigtable的数据模型,如何寻找和分配Tablet,那么数据是怎么以(row,column,time)的格式被组织成Tablet的呢?论文中给出的流程图如下:
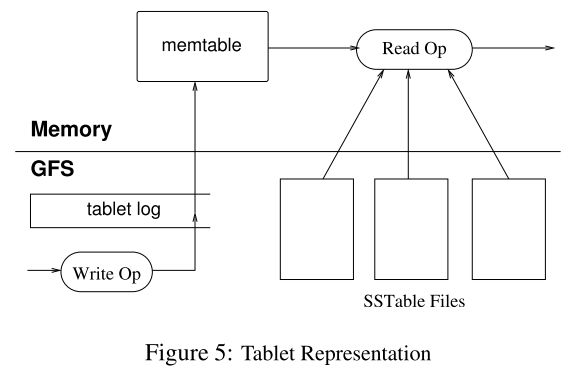
每个Tablet由若干个位于 GFS 上的 SSTable、一个位于内存内的MemTable以及一份Tablet Log组成。
我们来解释一下这张图。为了保证系统可恢复,Google首先使用Table Log(即WAL)将客户端发出的写操作请求记录在磁盘中,那么,一旦系统崩溃,仍然可以从磁盘读取数据,继续执行命令。然后,相关的数据被放入位于内存中的Memtable中,因为内存的速度相当快,那么执行排序等操作就要快得多。当Memtable的大小达到设定的值后,它就会以SSTable的形式被存储到GFS中,这被称为Minor Compaction。
客户端的读操作请求则要综合考虑Memtable和SSTable中的数据,如果Memtable中已经有需要读的数据,就无需读取SSTable。由于Memtable和SSTable都是有序的,所以读取的速度都相当快。
在这里,虽然论文没有明确指出,我认为Memtable和SSTable的大小很可能是64MB。因为GFS将单个Chunk设置为64MB,那么为了最大化地利用磁盘空间,Memtable和SSTable的大小设置为这个值是相当合理的。
由于SSTable中的数据有可能被标记为删除,那么我们需要定期对其进行处理,Bigtable将其称为Major Compaction。在这个过程中,Bigtable会将过期或者被删除的数据删除,并合并多个SSTable。这里似乎和GFS的Garbage Collection有点类似,但是我认为这可能是两个层面的活动。Bigtable清理的是单个Chunk中的数据,而GFS清理的是磁盘中的单个Chunk。
优化
论文中提到,仅靠上述这些方法还不能达到要求的速度,因此,Bigtable还做了一些优化。
第一,为了提高读取的速度,Bigtable使用布隆过滤器判断数据是否在某个SSTable中。
第二,Tablet Server使用Scan Cache缓存SSTable返回的数据,在重复读时提高效率。使用Block Cache缓存从GFS读取的SSTable,这样在读取附近的数据时就无需从磁盘读取。
第三,Bigtable把所有的写入操作都写入到同一个Bigtable Log文件中,而不是每个Server分配一个。同时,因为这个文件相当大,恢复起来很费事。Bigtable会对其进行排序并进行切分,每个Tablet Sever只需读取自己的那部分就可以了。
第四,Bigtable允许针对特定的Column Family生成SSTable,同时进行压缩,以提高读取的效率。
总结
Bigtable重要的贡献是证明了在分布式的系统中,针对超大规模的数据量,使用排序大表的来设计数据库是可行的。这直接带动了LSM Tree的流行,在后来的HBase,LevelDB中都使用了这种方式处理数据。另外,Bigtable系统中Chubby的使用,还告诉工业界分布式协调组件的重要性,这也引导了Zookeeper的设计实现,而其仍然是今天的分布式系统中重要的组件。
什么是谷歌三架马车之一的MapReduce?
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
MapReduce
MapReduce本来是函数式编程中的两个函数,在尝试解决利用大数据进行计算时,Jeff Dean和Sanjay Ghemawat想到了使用这种思想简化计算模型。
基本思想
MapReduce把所有的计算都拆分成两个基本的计算操作,即Map和Reduce。其中Map函数以一系列键值对作为输入,然后输出一个中间文件(Intermediate)。这个中间态是另一种形式的键值对。然后,Reduce函数将这个中间态作为输入,计算得出结果。其中,Map函数和Reduce函数的逻辑都是由开发人员自行定义的。一种经典的逻辑如下图所示。
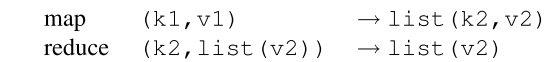
以WordCount为例,准备要统计一本书中所有单词出现的次数。在Map函数中,我们每遇到一个单词W,就往中间文件中写入(W,1)。然后,在Reduce函数中,把所有(W,1)出现的次数相加,就能得到W的出现次数V。
分布式MapReduce流程
上面提到的模型和思想都是单机的,想要在分布式系统中实现,还需要一些改动。在MapReduce中,他们选择将大任务拆分成小任务分配给多台机器,以此充分利用分布式系统的性能。下图是论文中展示的MapReduce的流程图。
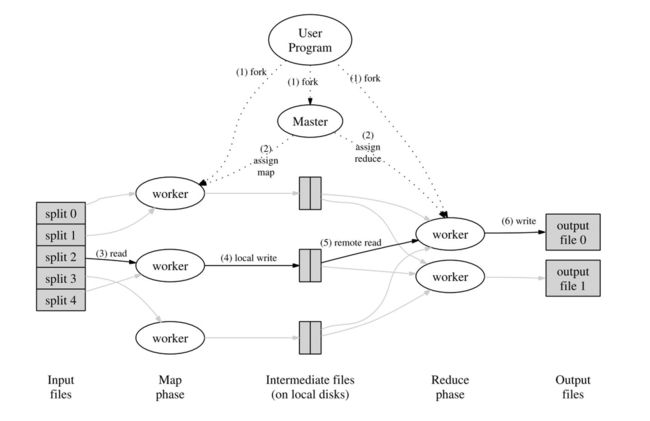
具体的流程如下
- MapReduce客户端会将输入的文件会分为M个片段,每个片段的大小通常在 16~64 MB 之间。然后在多个机器上开始运行MapReduce程序。
- 系统中会有一个机器被选为Master节点,整个 MapReduce 计算包含M个Map 任务和R个 Reduce 任务。Master节点会为空闲的 Worker节点分配Map任务和 Reduce 任务
- 执行Map任务的 Worker开始读入自己对应的片段并将读入的数据解析为输入键值对。然后调用由用户定义的 Map任务。最后,Worker会将Map任务输出的结果存在内存中。
- 在执行Map的同时,Map Worker根据Partition 函数将产生的中间结果分为R个部分,然后定期将内存中的中间文件存入到自己的本地磁盘中。任务完成时,Mapper 便会将中间文件在其本地磁盘上的存放位置报告给 Master。
- Master会将中间文件存放位置通知给Reduce Work。Reduce Worker接收到这些信息后便会通过RPC读取中间文件。在读取完毕后,Reduce Worker会对读取到的数据进行排序,保证拥有相同键的键值对能够连续分布。
- 最后,Reduce Worker会为每个键收集与其关联的值的集合,并调用用户定义的Reduce 函数。Reduce 函数的结果会被放入到对应的结果文件。
- 当所有Map和Reduce都结束后,程序会换新客户端并返回结果。
整个流程非常清晰。首先,将输入文件分割成M个个片段,然后每个Map Worker读取对应的片段并执行Map函数,将结果存入中间文件。Reduce Work则通过Master得知中间文件的位置,然后读取其对应中间文件的内容并运行Reduce函数,最后把结果输出到结果文件中。
这里值得说明的是,无论是输入文件到Map Worker的映射还是中间文件到Reduce Worker的映射都可以通过自定义的哈希函数来确定,论文中默认使用Hash(key) mod R来确定。另外,M和R的值都是由用户指定的,应当比实际的机器数量要多一些,以此实现均衡负载。
Fault-Tolerance
因为使用了分布式系统,所以不可避免地要考虑容错的问题,在MapReduce中,容错也考虑Master和Work两种情况。
Master节点会定期地将当前运行状态存为快照,当Master节点崩溃,就从最近的快照恢复然后重新执行任务。
Master节点会定期地Ping每个Work节点,一旦发现Work节点不可达,针对其当前执行的是Map还是Reduce任务,会有不同的策略。
如果是Map任务,无论任务已完成或是未完成,都会废除当前节点的任务。。之后,Master会将任务重新分配给其他节点,同时由于已经生成的中间文件不可访问,还会通知还未拿到中间文件的Reduce Worker去新的节点拿数据。
如果是Reduce任务,由于结果文件存在GFS中,文件的可用性和一致性由GFS保证,所以Master仅将未完成的任务重新分配。
优化
如果集群中有某个 Worker 花了特别长的时间来完成最后的几个 Map 或 Reduce 任务,整个 MapReduce 计算任务的耗时就会因此被拖长,这样的 Worker 也就成了落后者。MapReduce 在整个计算完成到一定程度时就会将剩余的任务即同时将其分配给其他空闲 Worker 来执行,并在其中一个 Worker 完成后将该任务视作已完成。
这里论文中还提出了其他一些策略,但是我认为不是十分重要也就不再提及。
总结
MapReduce是一个相当简单的计算模型,它尝试将所有的计算任务都拆分成基础的Map和Reduce,以此降低实现的复杂度。但是,这恰恰提高了编程逻辑的复杂度。我看过使用MapReduce实现Join功能的代码,十分地巧妙灵活。但是看似巧妙的背后,是模型过于简单而导致复杂度转移到了代码逻辑的层面。
另一方面,MapReduce的程序类似于批处理程序,需要完整的输入程序才能开始运算,而且每次运算都要至少写入两次磁盘。这就导致每次运算都要等待很长的时间,完全不能实现需要快速响应的业务场景的需求。
以上两个方面,一个引出了支持类SQL的计算工具,另一个引出了支持流式计算的工具,而这两个特性正是今天流行的计算工具的热点。
总得来说,虽然MapReduce在今天几乎抛弃了,但是在当初那个年代以及谷歌的业务需求看来,是相当合适的。
什么是谷歌三架马车之一的Bigtable?
背景介绍
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
Bigtable
Bigtable实现在Google File System的基础上,它关心数据的内容,根据的数据的内容建立数据模型,对外提供读写数据的接口。
数据模型
Bigtable基本的数据结构和关系型数据库类似,都是以行列构成的表,但是,它还另外增加了新的维度——时间。也就是说,在行列确定的情况下,一个单元格(Cell)中有多个以事件为版本的数据。Bigtable用(row:string, column:string, time:int64) → string表示映射关系。下图为论文中给出的一个例子。
如果想要在表中查询指定版本的内容,我们需要指出行,列,及版本。比如(“com.cnn.www”,“anchor:cnnsi.com”,t9)→ "CNN"。我个人猜想,增加时间这个维度是因为“三驾马车”被设计出来的时候主要是为了支持搜索引擎,搜索引擎可能需要保留多个时间段的网页数据,而GFS也使用追加(Append)作为数据的主要修改方式,所以增加时间戳作为版本既充分利用了GFS的特性,也能满足业务的需求。
另外,Bigtable还把多个Column Keys并入到被称为Column Family的集合中,并将Column Family作为访问控制的基础单元。我认为,这种方案其实是一种事务(Transaction)的实现方案。传统的事务以行为基本操作单位,在读写时对行上锁以实现隔离,而Bigtable则是以Column Family为单位,这里的访问控制其实就是锁的思想。
相关组件
在介绍系统的整体架构之前,我们要对Bigtable用到的两个重要组件有一些了解。由于Bigtable是分布式的数据库,在节点之间的协调上需要额外的处理,这里,Bigtable使用了Google内部的Chubby。我们可以把Chubby看做是Zookeeper,因为Zookeeper本质也就是Chubby的开源版本。另一方面,为了加快数据的查找和存储效率,Bigtable在存储数据之前都进行了排序,而此处用到的存储文件文论称之为SSTable(Sorted String Table)。
在Bigtable中,由于单个表(Table)存储的数据可能相当地多,那么读写的效率就会十分低下,于是Bigtable将Table分割为固定大小的Tablet,将其作为数据存储和查找的基本单位。每当Table增加了这里要说明的是,tablet是数据存储的基本单元,是用户感知不到的。而Column Family则是访问的基本单元,是编程时指定的,两者一前一后,不是一个概念。
Tablet 定位
因为是在分布式系统中,那么每个Tablet所在的机器不同,需要记录相关信息(METADATA)对其进行管理。而存储这些METADATA又需要分布式的系统,所以Bigtable又将这些METADATA的METADATA记录在一个文件中,并将这个文件的位置保存在Chubby中。总结一下,Bigtable有以下三层结构:
- 在Chubby中保存着Root Tablet的位置
- Root Tablet中保存着METADATA Table中所有 Tablet 的位置
- METADATA Table中保存着所有存储数据的Tablet的位置
这其中有几点值得注意。由于Root Tablet的特殊性,哪怕它的数据量再大,它也不允许被分割。METADATA tables被读取到内存中以加快速度,其中存储的是以开始和结尾的Row Key作为键,tablet位置作为值的映射。
如果客户端希望读取特定的数据,那么它会以此读取Chubby中的文件,Root Tablet,METADATA Tablet,最后读取存储改数据的Tablet。同时,为了加快读取的速度,它会将这些信息缓存到本地,直到信息失效。
Tablet分配
在谈Table分配之前,论文先讨论了怎么处理成员变更的问题。类似于GFS,Bigtable使用Master节点来管理这些相关的事情。
首先,Bigtable使用Chubby来检测Tablet Server的变化。这里的操作和Zookeeper的用法类似,当有新节点加入时,它需要在Chubby中新建一个对应的文件,并获取该文件的锁。由于所有的节点在Chubby中都有对应的文件,那么Master可以通过监听Chubby来获取所有Tablet Server的信息。这里有两种节点失效的情况,一种是仅仅回收了锁但是文件还在,这种情况很可能是节点崩溃了。由于节点不能自己退出,所以在Master节点得到该文件的锁后,它会将文件删除,以此表示节点退出。另一种情况是,文件已经被删除,这种情况说明节点是主动退出系统,那么可以直接重新分配Tablet给其他节点即可。
在正常的情况下,系统中会有大量数据写入,Master需要负责将这些数据分配到合适的Tablet Server。Bigtable并没有明确指出分配所使用的的算法,但是它提出了一个要求。为了保证数据的一致性,同一时间,一个 Tablet只能被分配给一个Tablet Server。Master通过向 Tablet Server 发送载入请求来分配 Tablet。如果该载入请求被Tablet Server接收到前Master仍是有效的,那么就可以认为此次 Tablet 分配操作已成功。
在这里,我们还要考虑Master崩溃的情况,论文中描述了Master恢复的步骤如下:
- 在 Chubby 上获取 Master 独有的锁,确保不会有另一个 Master 同时启动
- 从 Chubby 了解在工作的 Tablet Server
- 从各个 Tablet Server 处获取其所负责的 Tablet 列表,并向其表明自己作为新 Master 的身份,确保 Tablet Server 的后续通信能发往这个新 Master
- Master 确保 Root Tablet 及
METADATA表的 Tablet 已完成分配 - Master 扫描
METADATA表获取集群中的所有 Tablet,并对未分配的 Tablet 重新进行分配
其中,第四步是为了第五步的正确执行。
读写Tablet
上面我们谈了Bigtable的数据模型,如何寻找和分配Tablet,那么数据是怎么以(row,column,time)的格式被组织成Tablet的呢?论文中给出的流程图如下:
每个Tablet由若干个位于 GFS 上的 SSTable、一个位于内存内的MemTable以及一份Tablet Log组成。
我们来解释一下这张图。为了保证系统可恢复,Google首先使用Table Log(即WAL)将客户端发出的写操作请求记录在磁盘中,那么,一旦系统崩溃,仍然可以从磁盘读取数据,继续执行命令。然后,相关的数据被放入位于内存中的Memtable中,因为内存的速度相当快,那么执行排序等操作就要快得多。当Memtable的大小达到设定的值后,它就会以SSTable的形式被存储到GFS中,这被称为Minor Compaction。
客户端的读操作请求则要综合考虑Memtable和SSTable中的数据,如果Memtable中已经有需要读的数据,就无需读取SSTable。由于Memtable和SSTable都是有序的,所以读取的速度都相当快。
在这里,虽然论文没有明确指出,我认为Memtable和SSTable的大小很可能是64MB。因为GFS将单个Chunk设置为64MB,那么为了最大化地利用磁盘空间,Memtable和SSTable的大小设置为这个值是相当合理的。
由于SSTable中的数据有可能被标记为删除,那么我们需要定期对其进行处理,Bigtable将其称为Major Compaction。在这个过程中,Bigtable会将过期或者被删除的数据删除,并合并多个SSTable。这里似乎和GFS的Garbage Collection有点类似,但是我认为这可能是两个层面的活动。Bigtable清理的是单个Chunk中的数据,而GFS清理的是磁盘中的单个Chunk。
优化
论文中提到,仅靠上述这些方法还不能达到要求的速度,因此,Bigtable还做了一些优化。
第一,为了提高读取的速度,Bigtable使用布隆过滤器判断数据是否在某个SSTable中。
第二,Tablet Server使用Scan Cache缓存SSTable返回的数据,在重复读时提高效率。使用Block Cache缓存从GFS读取的SSTable,这样在读取附近的数据时就无需从磁盘读取。
第三,Bigtable把所有的写入操作都写入到同一个Bigtable Log文件中,而不是每个Server分配一个。同时,因为这个文件相当大,恢复起来很费事。Bigtable会对其进行排序并进行切分,每个Tablet Sever只需读取自己的那部分就可以了。
第四,Bigtable允许针对特定的Column Family生成SSTable,同时进行压缩,以提高读取的效率。
总结
Bigtable重要的贡献是证明了在分布式的系统中,针对超大规模的数据量,使用排序大表的来设计数据库是可行的。这直接带动了LSM Tree的流行,在后来的HBase,LevelDB中都使用了这种方式处理数据。另外,Bigtable系统中Chubby的使用,还告诉工业界分布式协调组件的重要性,这也引导了Zookeeper的设计实现,而其仍然是今天的分布式系统中重要的组件。
什么是FST数据结构?
数据字典 Term Dictionary,通常要从数据字典找到指定的词的方法是,将所有词排序,用二分查找即可。这种方式的时间复杂度是 Log(N),占用空间大小是 O(N*len(term))。缺点是消耗内存,存在完整的term,当 term 数达到上千万时,占用内存非常大。
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:
空间占用小,通过读 term 拆分复用及前缀和后缀的重用,压缩了存储空间;
查询速度快,查询仅有 O(len(term)) 时间复杂度
那么 FST 数据结构是什么原理呢? 先来看看什么是 FSM (Finite State Machine), 有限状态机,从“起始状态”到“终止状态”,可接受一个字符后,自循环或转移到下一个状态。
而FST呢,就是一种特殊的 FSM,在 Lucene 中用来实现字典查找功能(NLP中还可以做转换功能),FST 可以表示成FST的形式
举例:对“cat”、 “deep”、 “do”、 “dog” 、“dogs” 这5个单词构建FST(注:必须已排序),结构如下:
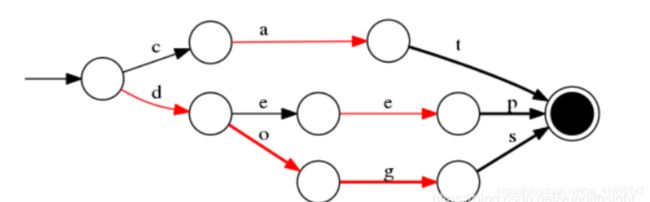
当存在 value 为对应的 docId 时,如 cat/0 deep/1 do/2 dog/3 dogs/4, FST 结构图如下:
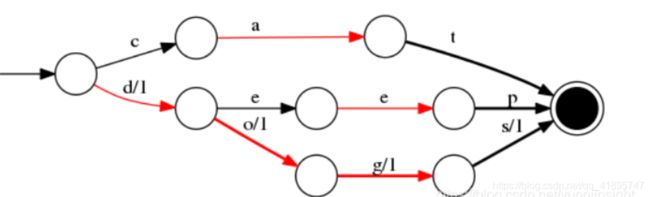
FST 还有一个特点,就是在前缀公用的基础上,还会做一个后缀公用,目标同样是为了压缩存储空间。
什么是SkipList的数据结构?
为了能够快速查找docid,lucene采用了SkipList这一数据结构。SkipList有以下几个特征:
元素排序的,对应到我们的倒排链,lucene是按照docid进行排序,从小到大;
跳跃有一个固定的间隔,这个是需要建立SkipList的时候指定好,例如下图以间隔是;
SkipList的层次,这个是指整个SkipList有几层
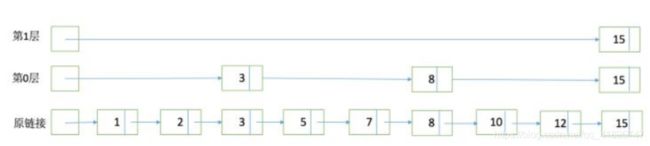
在什么位置设置跳表指针?
• 设置较多的指针,较短的步长, 更多的跳跃机会
• 更多的指针比较次数和更多的存储空间
• 设置较少的指针,较少的指针比较次数,但是需要设置较长的步长较少的连续跳跃
如果倒排表的长度是L,那么在每隔一个步长S处均匀放置跳表指针。
什么是BKD Tree的数据结构?
也叫 Block KD-tree,根据FST思路,如果查询条件非常多,需要对每个条件根据 FST 查出结果,进行求并集操作。如果是数值类型,那么潜在的 Term 可能非常多,查询销量也会很低,为了支持高效的数值类或者多维度查询,引入 BKD Tree。在一维下就是一棵二叉搜索树,在二维下是如果要查询一个区间,logN的复杂度就可以访问到叶子节点对应的倒排链。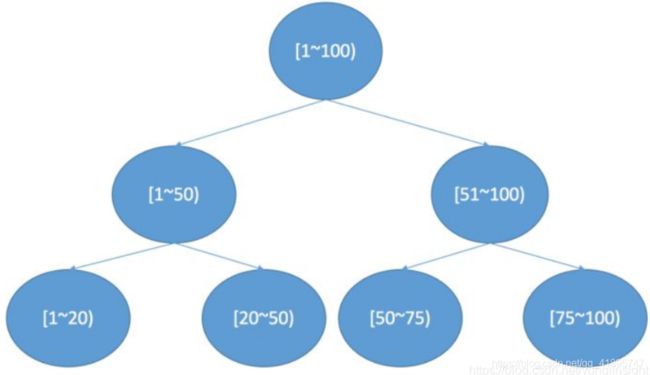
- 确定切分维度,这里维度的选取顺序是数据在这个维度方法最大的维度优先。一个直接的理解就是,数据分散越开的维度,我们优先切分。
- 切分点的选这个维度最中间的点。
- 递归进行步骤1,2,我们可以设置一个阈值,点的数目少于多少后就不再切分,直到所有的点都切分好停止。
什么是搜索召回?
搜索召回是根据输入的query,能够高效的获取query相关的候选doc集合的过程。相关的doc如果不能被被召回,即使后面的粗排、精排做的再好也是徒劳无功。所以召回对于搜索引擎是非常重要的,决定了搜索引擎质量的上限。
什么是搜索小流量?
其实不是搜索架构才有,只要一个系统达到一定的量级,比如百万PV,不做小流量直接上线风险很大,头铁除外。
小流量是让pv总量的一小部分使用到新功能,而其余用户仍然使用原来的功能。
至于怎样抽取小流量、如何抽取更随机更合理,这就不是搜索技术研究的重点了。
什么是互联网毒瘤内容农场?
说起毒瘤一点也不过分,拿我自己举例子,我自己的博客,搜一下:
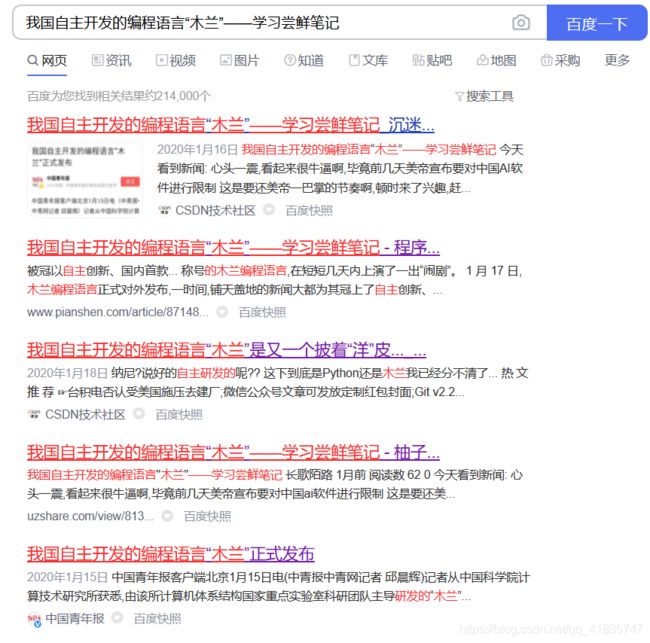
会发现很多和我自己一模一样的博文,有的算有良心表明了转载,有的是洗稿子,有的直接写原创。很多不是人为去抄的,而是爬虫自动爬取,也许你发布博文的后三秒,这一篇blog已经在其他的网站里面出现了!更有趣的事情是,你百度或者谷歌一下,权重排在前面的竟然是转载或者抄袭的文章,辛辛苦苦原创的反而排在后面?!这就是典型的内容农场啦。
引用维基百科对内容农场的描述:
内容农场(英语:content farm)是指图谋网络广告等商业利益,以获取网络流量为主要目标,而以各种合法、非法手段大量、快速生产质量不稳定网络文章的网站或企业。
内容农场通常不会主动管理产出的内容,对侵权或错误内容投诉的处理也很消极,其产出内容有极高比例是盗用、盗译自他人的原创图文,或由非专业写手胡乱拼凑网络文章而来,因而多半缺乏可靠来源、质量低劣、不具参考价值、传播误导讯息,也经常掺杂大量广告或恶意程序。
内容农场的管理者在这些内容上的花费通常都比传统上作家拿到的薪水低。每篇文章公司大约付给作家3.50美元,远低于主流在线媒体的给薪。有些内容农场的内容贡献者每天生产数篇文章,得到的薪水便足以过活。据报导,这些作家通常是受过教育的有小孩的妇女,在家工作赚取额外收入。[1]
至于繁体中文的内容农场,有一部分属于由国外内容农场或博客文章翻译而来,尤其是医学类文章等,较著名的一例便是美国博客Psychology Spot上一篇以"Did you know that intelligence is inherited from mothers?"(你知道智商的遗传是来自于母亲吗?)为题的文章,而此文章发布后便随即出现中文版本,也流传到许多内容农场里,然而讽刺的是,这篇文章被指内容不为所引用的论文支持,“智商基因”的说法也没有任何医师或遗传学权威的支持,此篇文章更曾引来台湾医界人士的强烈质疑,与对其缺乏数据论证的批判。
其实谷歌、百度早在十年前就对内容农场宣战,只是过了十年,这种方式并没有消除,必然永远无法消除,毕竟有人的地方就有江湖,有互联网的地方就有抄袭。最后来看一下常见内容农场的列表:
- apple01(苹果网) - 包括 apple01.cc、apple01.co、apple01.net
- beeper.live(嘟嘟网) - 包括 hknews.pro
- biglife.fun
- bomb01 - 包括 bomb01.asia、bomb01.cc、bomb01.club、bomb01.co、bomb01.com、bomb01.life、bomb01.me、bomb01.media、bomb01.online、bomb01.org、bomb01.party、bomb01.today、bomb01.tw、bomb01.vip、bomb01.xyz
- BuzzHand - 包括 buzzhand.com、buzzhand.net、buzzhand.org、buzzworld.tech
- CMoney
- COCOHK - 包括 cocohk.com, cocohk.net, cocohk.cc, cocohk.me, cocohk.today, cocohk.vip, coco02.com, coco02.net
- COCO01 - 包括 coco01.cc, coco01.today, coco01.me, coco01.net, cocomy.net(COCO大马), peekme.cc
- codertw.com(程序前沿)
- daliulian(大榴梿) - 包括 daliulian.net, daliulian.org
- fafa01.com(看头条) - 包括 fafabest.com、fafa01.com、fale100.com、greatpo.com、post01vicky.com、91post.net、ezreader.life、eeeduuu.com、readdoo.com、readbest.net、lovegamett.com、godayup.com、17no1.com、goupdayday.com、zmjayouzan.com
- gigacircle.com
- hkpeople-local.com
- hot.petonea.com
- hssszn.com(赞新闻)
- itread01.com
- jianshu.com(简书)
- kanwatch - 包括 kanwatch.com、kanwatch.live、kanwatch.site、kanwatch.best
- kknews.cc(每日头条)
- kokomy.net(闪文联盟) - 包括 *.fbs.one、*.orgs.host、*.orgs.life、*.orgs.pub、*.orgs.one、*.orgs.pub、*.orgs.ltd、*.orgs.press、*.ipub.one、*.ipub.pro
- lifeonea.co(壹A新闻)
- lookersideas.com(好点子)
- mission-tw.com(密讯) - 包括 missiback.com, mission-new.com, osometalk.com, tiksomo.com
- moptt.tw
- nooho.net(怒吼)
- presslocal(爱缩兔)- 包括 iso2.cc、iso2.cx、presslocalhk.com、hklocalpress.com、pressyourmum.com
- PTT01(娱乐新闻)- 包括 ptt01.cc、ptt01.tv
- qiqi.news(琦琦看新闻) - 包括 cnba.live、iqiqi.pro、qiqis.net、qiqi.world、iqiqis.com、ipipi.co、ipipi.me、my-love.org、newqiqi.com、twitter-qiqi.com、qiqi.today、allqiqi.com、qiqis.org、defense.rocks
- qiqu.pro(奇趣网) - 包括 qiqu.live、qiqu.world
- read01.com(壹读)
- share001 - 包括 share001.com、share001.net、share001.org
- twgreatdaily(今天头条) - 包括 twgreatdaily.com、twgreatdaily.fun、twgreatdaily.life、twgreatdaily.live
- vivi01.com, 包括 cklive.net,ptttube.com,buzzvideo.pro,cookernote.com,live525.com
- xuehua(雪花新闻) - 包括 xuehua.tw、xuehua.us
- itw01.com 中文技术分享平台
- aboluowang.com 阿波罗新闻网
这篇blog讲的也非常好,推荐一看:https://www.cnblogs.com/pannengzhi/p/12386268.html
什么是暗网?
所谓暗网,是指目前搜索引擎爬虫按照常规方式很难抓取到的互联网页面。搜索引擎爬虫依赖页面内中的链接关系发现新的页面,但是很多网站的内容是以数据库的方式存储的,典型的例子是一些垂直领域网站,比如京东的3C家电数码数据,很难有显性链接指向数据库内的记录,往往是服务网站提供组合查询界面,只有用户按照要求选择查询条件后,才可能获得相关数据,所以常规的爬虫无法索引这些数据内容。
什么是深度网络搜索?
当我们在任何搜索引擎上搜索某项内容时,它只会显示由约10个链接组成的一些结果,并且我们发现至少有一个链接可以满足大多数情况下搜索到的术语。这就是所谓的简单搜索,或者我们可能会在网上冲浪。这样,我们仅使用传统的搜索引擎浏览网页。但是深度网络搜索到底是什么意思?为了解释这一点,我们将使用说明性示例。我们使用Internet,即通过Web探索,学习和发现很多东西。这些内容包括信息收集,照片和视频收集,文档收集等。
搜索引擎怎样爬取暗网?
暗网并不完全是非法的信息,绝大部分还是合法的,比如买火车票的12306官网,那么搜索引擎怎样爬取暗网数据并整合呢?百度谷歌都作了相关技术的探索,百度推出了阿拉丁计划,谷歌的富含信息查询模板技术等,有兴趣的可以搜索一下,比较复杂就不展开了。其实这些已经不仅仅是暗网搜索了,更重要是谷歌百度提供各种垂类搜索,打破信息孤岛,做到真正的大搜。
什么是暗网?
“暗网”是指隐藏的网络,普通网民无法通过常规手段搜索访问,需要使用一些特定的软件、配置或者授权等才能登录。由于“暗网”具有匿名性等特点,容易滋生以网络为勾联工具的各类违法犯罪,一些年轻人深陷其中。记者在中国裁判文书网上搜索显示,涉“暗网”的案件共有21例,涉及贩卖毒品、传播色情恐怖非法信息、侵害公民个人信息等犯罪行为。
互联网是一个多层结构,“表层网”处于互联网的表层,能够通过标准搜索引擎进行访问浏览。藏在“表层网”之下的被称为“深网”。深网中的内容无法通过常规搜索引擎进行访问浏览。“暗网”通常被认为是“深网”的一个子集,显著特点是使用特殊加密技术刻意隐藏相关互联网信息。
暗网是利用加密传输、P2P对等网络、多点中继混淆等,为用户提供匿名的互联网信息访问的一类技术手段,其最突出的特点就是匿名性。
搜索引擎为什么一定要抓取暗网?
因为暗网数据不仅仅是违法信息,杀人放火,奸杀淫掠这些,还有很多有用的信息。
比如小程序信息、微博小程序、地域信息、地图信息等等,特别是在移动互联网时代,不是以URL形式作为唯一展现;这些也是广义上的暗网,所以搜索引擎需要针线这些信息,打破信息孤岛。
常用的搜索技巧有哪些?
摘自:https://zhuanlan.zhihu.com/p/351163107
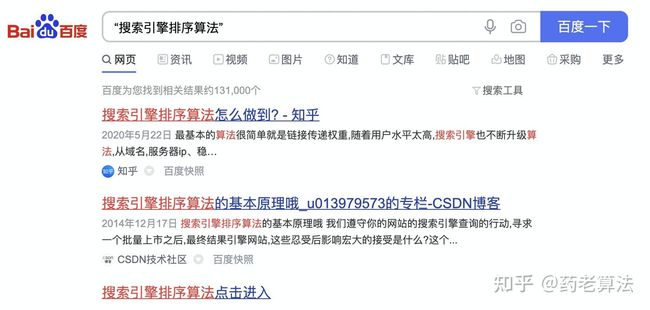
整词查询
众所周知搜索引擎中都会将query进行分词,如果你在搜索的过程中不想分词,则可以在词的首位添加引号,既为整词查询,关键词为:“搜索引擎排序算法”如下:
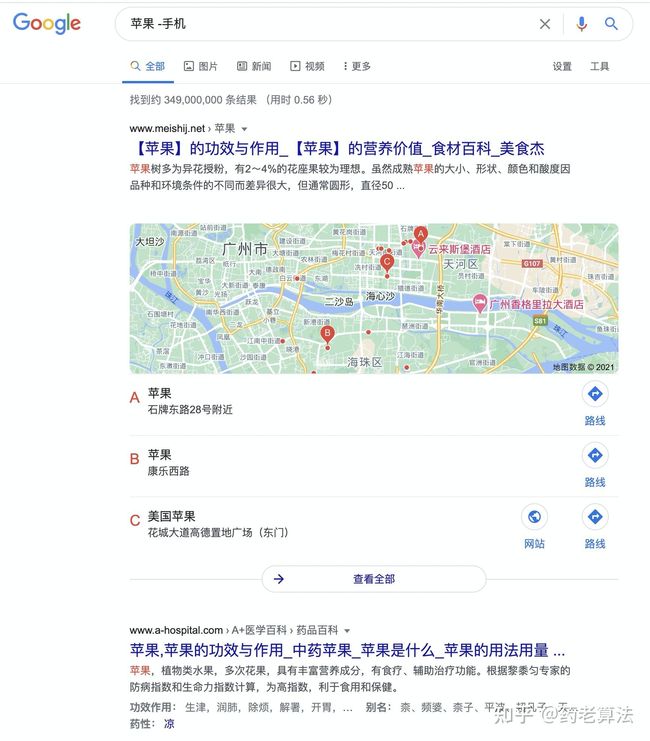
排除关键词 -
在搜索时可能会碰上很多同义词,当你知道某些范围的词我不需要的时候,这个时候可以使用“-”字符进行排除,例如我搜索“苹果”时,只想搜索水果的苹果,而不是苹果手机,则可以使用“苹果 -手机”,如下
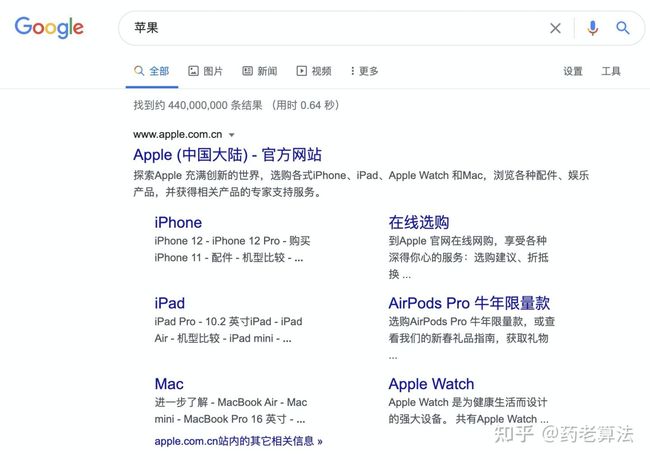
而如果不加范围,可能会出现如下结果:搜索“苹果”
AND / OR
在我们使用多个词进行搜索时,有些需求是只命中一个即可,有些需求则是命中全部,比如我只需搜索“搜索引擎”和“推荐系统”中的一个,则可以使用OR,如下:
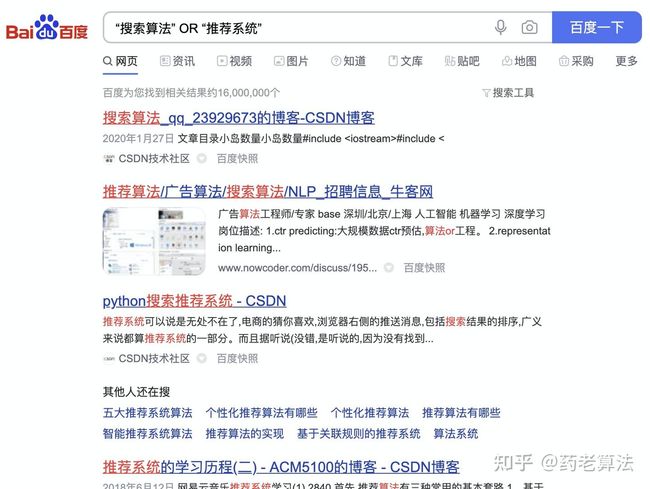
如果需要全命中,则可以使用AND,查找的网页中会同时包含这两个关键词。这个指令,其实我们一直在用,只是没有意识,一般用空格代替,还可以用加号+代替,意思是逻辑“与”,如下:
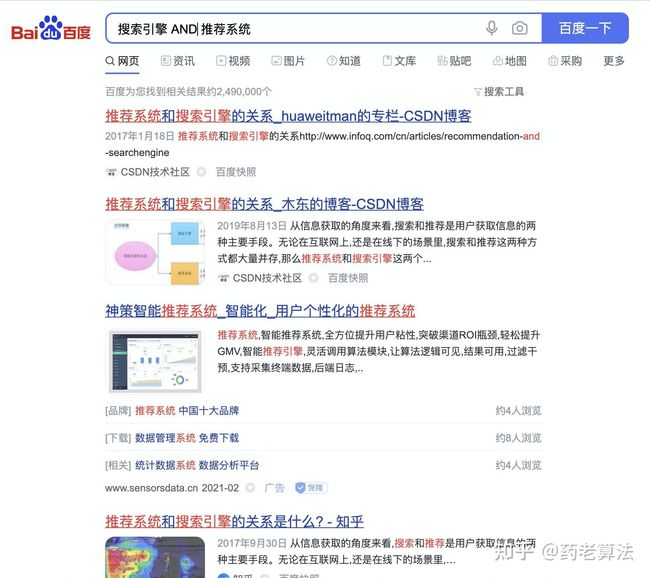
站内搜索
在实际搜索过程中,很多时候我们只想搜索某个站点的结果,比如技术文章我会搜索csdn,想资讯问题我会搜索知乎等,其实有这么一个site指令,让你搜索某个站点的内容,你想查询知乎站点中的“搜索排序算法”,则可以使用“搜索排序算法 site:zhihu.com”,如下:
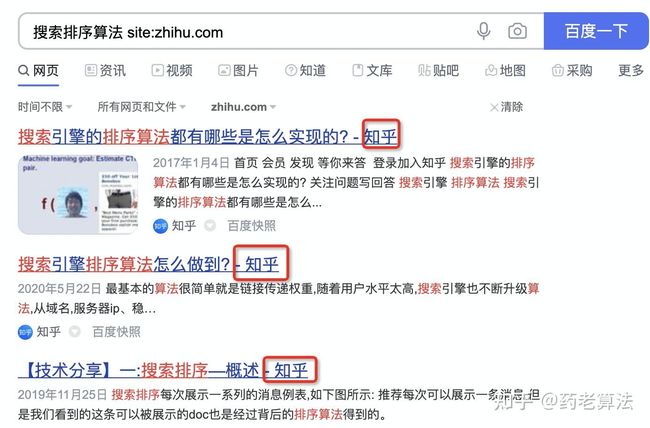
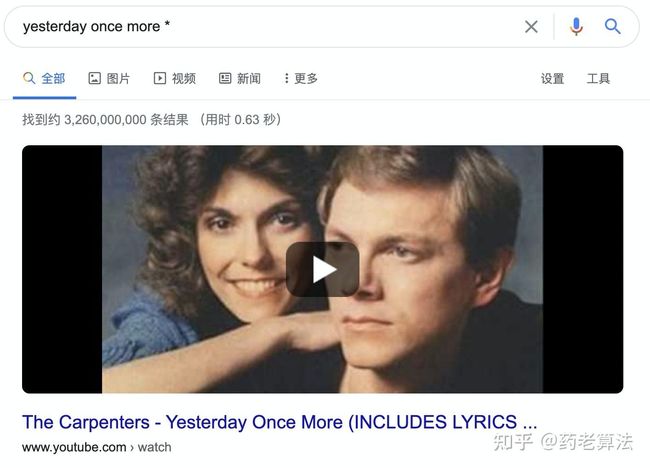
* 星号通配符
有一些场景是我们在搜索过程中,只记得某些文本,但串联不上,无法整句输入,则可以使用 * 通配符,比如一些找歌曲和找诗歌的场景,如下:
字段搜索
此前文章我们有讲过《索引技术》,索引是需要以字段为基础的,而google和百度分别开放了几个字段供用户搜索。本文主要讲解intitle、inurl、allintitle、allinurl以及filetype这几个字段。
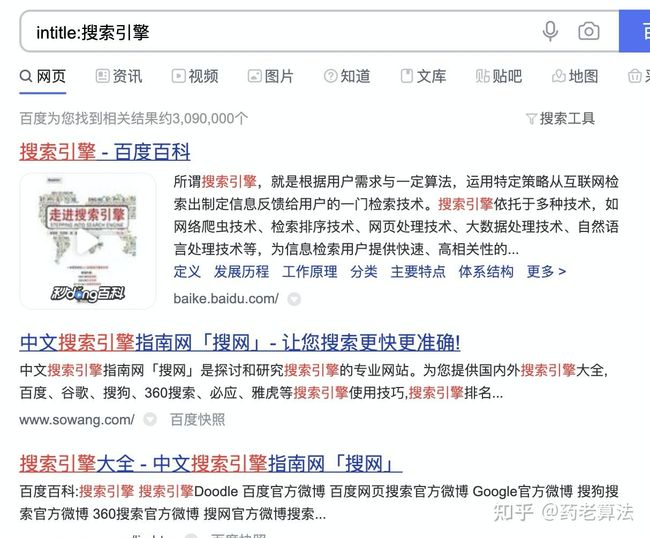
intitle:搜索引擎,指的是标题中命中“搜索引擎”的结果,如下:
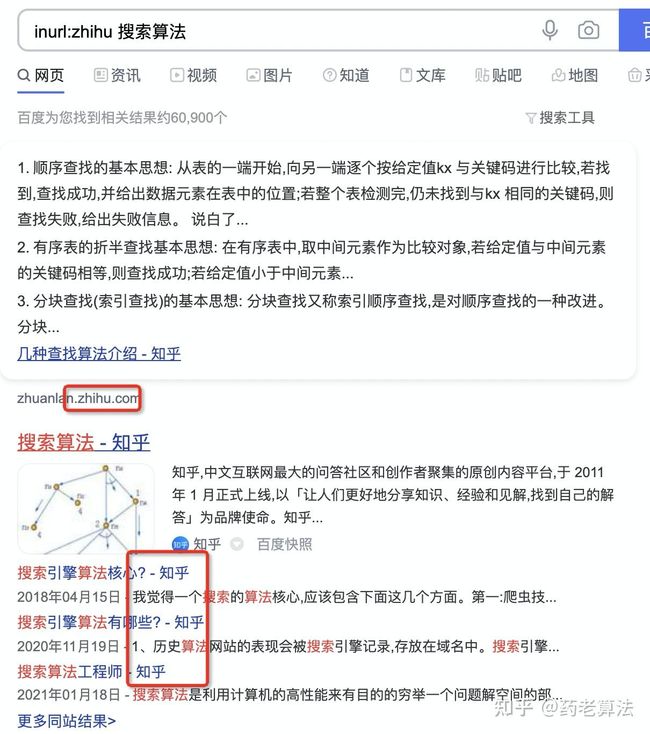
inurl:zhihu,指的是链接中命中zhihu的搜索结果,如下:
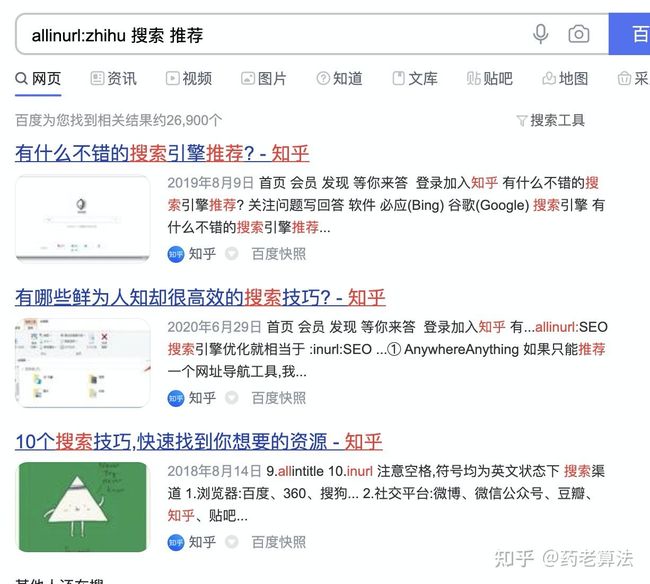
allintitle和allinurl:指令含意和intitle及inurl一样,区别在于intitle和inurl后面只能添加一个关键词。而allintitle和allinurl后面能添加多个关键词或者短语。如下:
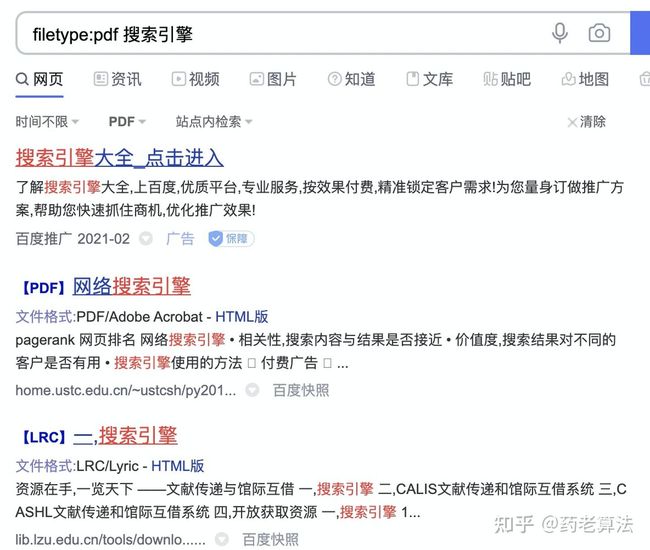
filetype:用于搜索特定文件格式。google和百度都支持filetype指令。
使用“filetype:pdf 搜索引擎”进行搜索,如下:
写在最后:
各位大佬能看到这儿,已经阅读了将近三万字,至少超过95%的人了,先膜一下大佬~
搜索技术是一项集大成的技术,岂能是区区3万字能讲得透彻的呀!这三万字很多都是引用、借鉴各位大佬、前辈的文章,在引用中一一列举出了。
写这篇三千问的初衷也是对这些知识的一次整理,方便自己日后常查阅常学习,继续加油!
参考
- 《这就是搜索引擎——核心技术详解》
- https://www.leiphone.com/news/201511/XD0ZESDzc65GE9me.html
- 《数学之美》
- https://blog.csdn.net/qihoo_tech/article/details/98000090?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control
- https://zhuanlan.zhihu.com/p/24382357
- https://zhuanlan.zhihu.com/p/338566270
- https://zhuanlan.zhihu.com/p/348159133
- https://www.ddosi.com/b240/
- https://blog.csdn.net/yunqiinsight/article/details/90232254?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-4&spm=1001.2101.3001.4242
- https://blog.csdn.net/zhaipengfei1231/article/details/81186798
- https://blog.csdn.net/malefactor/article/details/2032473
- https://blog.csdn.net/malefactor/category_69592.html
- https://blog.csdn.net/malefactor/article/details/7389311
- https://blog.csdn.net/malefactor/article/details/7401022
- https://blog.csdn.net/a345017062/article/details/51447302?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-14.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-14.control