网络协议和Netty——第二章 Java原生网络编程学习笔记
编程中的Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层TCP/IP 协议来建立 TCP 连接。建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个
Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
短连接:
连接->传输数据->关闭连接
HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
也可以这样说:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
长连接:
连接->传输数据->保持连接 -> 传输数据-> ...... ->关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,处理时直接发送数据包就OK了,不用建立TCP连接。
例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好。
总之,长连接和短连接的选择要视情况而定。
一、Linux网络IO模型
1、同步和异步,阻塞和非阻塞
1.1、同步和异步
关注的是结果消息的通信机制
同步:同步的意思就是调用方需要主动等待结果的返回。
异步:异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知,回调函数等。
1.2、阻塞和非阻塞
主要关注的是等待结果返回调用方的状态
阻塞:是指结果返回之前,当前线程被挂起,不做任何事。
非阻塞:是指结果在返回之前,线程可以做一些其他事,不会被挂起。
1.3、两者的组合
1)同步阻塞:同步阻塞基本也是编程中最常见的模型,打个比方你去商店买衣服,你去了之后发现衣服卖完了,那你就在店里面一直等,期间不做任何事(包括看手机),等着商家进货,直到有货为止,这个效率很低。
2)同步非阻塞:同步非阻塞在编程中可以抽象为一个轮询模式,你去了商店之后,发现衣服卖完了,这个时候不需要傻傻的等着,你可以去其他地方比如奶茶店,买杯水,但是你还是需要时不时的去商店问老板新衣服到了没有。
3)异步阻塞:异步阻塞这个编程里面用的较少,有点类似你写了个线程池,submit然后马上future.get(),这样线程其实还是挂起的。有点像你去商店买衣服,这个时候发现衣服没有了,这个时候你就给老板留给电话,说衣服到了就给我打电话,然后你就守着这个电话,一直等着他响什么事也不做。这样感觉的确有点傻,所以这个模式用得比较少。
4)异步非阻塞:异步非阻塞。好比你去商店买衣服,衣服没了,你只需要给老板说这是我的电话,衣服到了就打。然后你就随心所欲的去玩,也不用操心衣服什么时候到,衣服一到,电话一响就可以去买衣服了。
2、五种I/O模型
同步:
- 阻塞I/O(blocking I/O)
- 非阻塞I/O (nonblocking I/O)
- I/O复用(select 、poll和epoll) (I/O multiplexing)
- 信号驱动I/O (signal driven I/O (SIGIO))
异步:
- 异步I/O (asynchronous I/O )
2.1、阻塞I/O模型:
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。

当调用recv()函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从系统缓冲区复制到用户空间,然后该函数返回。在套接应用程序中,当调用recv()函数时,未必用户空间就已经存在数据,那么此时recv()函数就会处于等待状态。
2.2、非阻塞IO模型
我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。上述模型绝不被推荐。

2.3、IO复用模型:
简介:主要是select和epoll两个系统调用;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性,关键是能实现同时对多个IO端口进行监听。
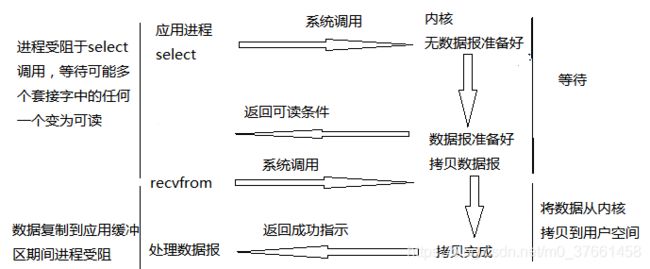
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
当用户进程调用了select,那么整个进程会被block;而同时,kernel会“监视”所有select负责的socket;当任何一个socket中的数据准备好了,select就会返回。这个时候,用户进程再调用read操作,将数据从kernel(内核)拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是用select的优势在于它可以同时处理多个connection。(多说一句:所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接)。
2.4、信号驱动IO
简介:两次调用,两次返回;

首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
2.5、异步IO模型

当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作
3、5个I/O模型的比较
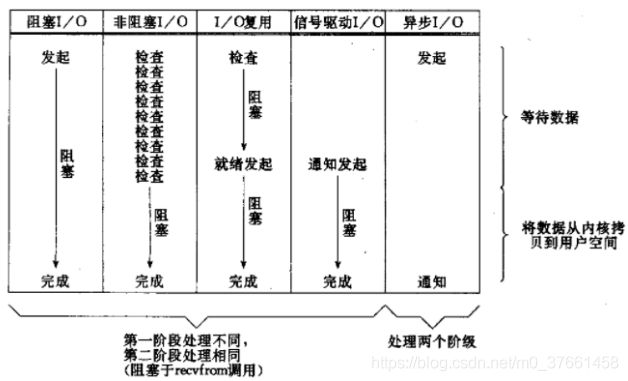
不同I/O模型的区别,其实主要在等待数据和数据复制这两个时间段不同,图形中已经表示得很清楚了。
select、poll、epoll的区别?
1)支持一个进程所能打开的最大连接数
| select |
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响。 |
| poll |
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 |
| epoll |
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接 |
2)FD剧增后带来的IO效率问题
| select |
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 |
| poll |
同上 |
| epoll |
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 |
3)消息传递方式
| select |
内核需要将消息传递到用户空间,都需要内核拷贝动作 |
| poll |
同上 |
| epoll |
epoll通过内核和用户空间共享一块内存来实现的。 |
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1)表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2)select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
补充知识点:
Level_triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率。
Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
select(),poll()模型都是水平触发模式,信号驱动IO是边缘触发模式,epoll()模型既支持水平触发,也支持边缘触发,默认是水平触发。
4、网络编程里通用常识
既然是通信,那么是肯定是有两个对端的,在通信编程里提供服务的叫服务端,连接服务端使用服务的叫客户端。在开发过程中,如果类的名字有Server或者ServerSocket的,表示这个类是给服务端用的,如果类的名字只有Socket的,那么表示这是负责具体的网络读写的。那么对于服务端来说ServerSocket就只是个场所,具体和客户端沟通的还是一个一个的socket,所以在通信编程里,ServerSocket并不负责具体的网络读写,ServerSocket就只是负责接收客户端连接后,新启一个socket来和客户端进行沟通。这一点对所有模式的通信编程都是适用的。
在通信编程里,我们关注的其实也就是三个事情:连接(客户端连接服务器,服务器等待和接收连接)、读网络数据、写网络数据,所有模式的通信编程都是围绕着这三件事情进行的。
5、原生JDK网络编程BIO
服务端提供IP和监听端口,客户端通过连接操作向服务端监听的地址发起连接请求,通过三次握手连接,如果连接成功建立,双方就可以通过套接字进行通信。
传统的同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口;Socket负责发起连接操作。连接成功后,双方通过输入和输出流进行同步阻塞式通信。
传统BIO通信模型:采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成后,通过输出流返回应答给客户端,线程销毁。即典型的一请求一应答模型。
该模型最大的问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端并发访问数呈1:1的正比关系,Java中的线程也是比较宝贵的系统资源,线程数量快速膨胀后,系统的性能将急剧下降,随着访问量的继续增大,系统最终就死掉了。
为了改进这种一连接一线程的模型,我们可以使用线程池来管理这些线程,实现1个或多个线程处理N个客户端的模型(但是底层还是使用的同步阻塞I/O),通常被称为“伪异步I/O模型“。
我们知道,如果使用CachedThreadPool线程池(不限制线程数量,如果不清楚请参考文首提供的文章),其实除了能自动帮我们管理线程(复用),看起来也就像是1:1的客户端:线程数模型,而使用FixedThreadPool我们就有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N:M的伪异步I/O模型。
但是,正因为限制了线程数量,如果发生读取数据较慢时(比如数据量大、网络传输慢等),大量并发的情况下,其他接入的消息,只能一直等待,这就是最大的弊端。
如何使用,参见模块java-bio下的代码:
1)Bio通信的客户端Client代码如下:
public class Client {
public static void main(String[] args) throws IOException {
Socket socket = null;
// 实例化与服务端通信的输入输出流
ObjectOutputStream output = null;
ObjectInputStream input = null;
// 服务器的通信地址
InetSocketAddress address = new InetSocketAddress("127.0.0.1",10086);
try{
// 连接服务器
socket = new Socket();
socket.connect(address);
output = new ObjectOutputStream(socket.getOutputStream());
input = new ObjectInputStream(socket.getInputStream());
// 向服务器输出请求
output.writeUTF("hankin test data...");
output.flush();
// 接收服务器的输出
System.out.println(input.readUTF());
}finally {
if (socket!=null) socket.close();
if (output!=null) output.close();
if (input!=null) input.close();
}
}
}2、Bio通信的服务端
public class Server {
/**
* 每个和客户端的通信都会打包成一个任务,交个一个线程来执行
*/
private static class ServerTask implements Runnable{
private Socket socket = null;
public ServerTask(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
ObjectInputStream inputStream = new ObjectInputStream(socket.getInputStream());
ObjectOutputStream outputStream = new ObjectOutputStream(socket.getOutputStream());
// 接收客户端的输出,也就是服务器的输入
String userName = inputStream.readUTF();
System.out.println("Accept client message from client:"+userName);
// 服务器的输出,也就是客户端的输入
outputStream.writeUTF("hello : "+userName);
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws IOException {
// 服务端启动必备
ServerSocket serverSocket = new ServerSocket();
// 表示服务端在哪个端口上监听
serverSocket.bind(new InetSocketAddress(10086));
System.out.println("Start Server ....");
while(true){
new Thread(new ServerTask(serverSocket.accept())).start();
}
}
}3)Bio通信的服务端(线程池)
public class ServerPool {
// 创建固定数量的线程池
private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* 每个和客户端的通信都会打包成一个任务,交个一个线程来执行
*/
private static class ServerTask implements Runnable{
private Socket socket = null;
public ServerTask(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
ObjectInputStream inputStream = new ObjectInputStream(socket.getInputStream());
ObjectOutputStream outputStream = new ObjectOutputStream(socket.getOutputStream());
// 接收客户端的输出,也就是服务器的输入
String userName = inputStream.readUTF();
System.out.println("Accept client message:"+userName);
// 服务器的输出,也就是客户端的输入
outputStream.writeUTF("hello : "+userName);
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws IOException {
// 服务端启动必备
ServerSocket serverSocket = new ServerSocket();
// 表示服务端在哪个端口上监听
serverSocket.bind(new InetSocketAddress(10086));
System.out.println("Start Server ....");
try{
while(true){
executorService.execute(new ServerTask(serverSocket.accept()));
}
}finally {
serverSocket.close();
}
}
}6、BIO应用-RPC框架
6.1、为什么要用RPC
我们最开始开发的时候,一个应用一台机器,将所有功能都写在一起,比如说比较常见的电商场景;随着我们业务的发展,我们需要提示性能了,我们会怎么做?将不同的业务功能放到线程里来实现异步和提升性能。

但是业务越来越复杂,业务量越来越大,单个应用或者一台机器的资源是肯定背负不起的,这个时候,我们会怎么做?将核心业务抽取出来,作为独立的服务,放到其他服务器上或者形成集群。这个时候就会请出RPC,系统变为分布式的架构。
为什么说千万级流量分布式、微服务架构必备的RPC框架?和LocalCall的代码进行比较,因为引入rpc框架对我们现有的代码影响最小,同时又可以帮我们实现架构上的扩展。
现在的开源rpc框架,有什么?dubbo,grpc等等
当服务越来越多,各种rpc之间的调用会越来越复杂,这个时候我们会引入中间件,比如说MQ、缓存,同时架构上整体往微服务去迁移,引入了各种比如容器技术docker,DevOps等等。最终会变为如图所示来应付千万级流量,但是不管怎样,rpc总是会占有一席之地。

6.2、什么是RPC?
RPC(Remote Procedure Call ——远程过程调用),它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络的技术。
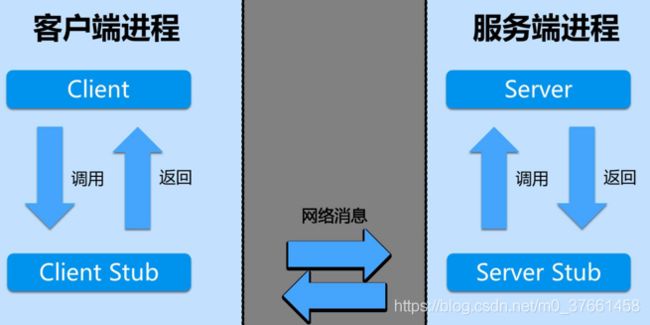
一次完整的RPC同步调用流程:
1)服务消费方(client)以本地调用方式调用客户端存根;
2)什么叫客户端存根?就是远程方法在本地的模拟对象,一样的也有方法名,也有方法参数,client stub接收到调用后负责将方法名、方法的参数等包装,并将包装后的信息通过网络发送到服务端;
3)服务端收到消息后,交给代理存根在服务器的部分后进行解码为实际的方法名和参数
4)server stub根据解码结果调用服务器上本地的实际服务;
5)本地服务执行并将结果返回给server stub;
6)server stub将返回结果打包成消息并发送至消费方;
7)client stub接收到消息,并进行解码;
8)服务消费方得到最终结果。
RPC框架的目标就是要中间步骤都封装起来,让我们进行远程方法调用的时候感觉到就像在本地调用一样。
6.3、RPC和HTTP
RPC字面意思就是远程过程调用,只是对不同应用间相互调用的一种描述,一种思想。具体怎么调用?实现方式可以是最直接的TCP通信,也可以是HTTP方式,在很多的消息中间件的技术书籍里,甚至还有使用消息中间件来实现RPC调用的,我们知道的dubbo是基于TCP通信的,GRPC是Google公布的开源软件,基于最新的HTTP2.0协议,底层使用到了Netty框架的支持。所以总结来说,RPC和HTTP是完全两个不同层级的东西,他们之间并没有什么可比性。
6.4、实现RPC框架
实现RPC框架需要解决的那些问题
1)代理问题
代理本质上是要解决什么问题?要解决的是被调用的服务本质上是远程的服务,但是调用者不知道也不关心,调用者只要结果,具体的事情由代理的那个对象来负责这件事。既然是远程代理,当然是要用代理模式了。
代理(Proxy)是一种设计模式,即通过代理对象访问目标对象;这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。那我们这里额外的功能操作是干什么,通过网络访问远程服务。jdk的代理有两种实现方式:静态代理和动态代理。
2)序列化问题
序列化问题在计算机里具体是什么?我们的方法调用,有方法名,方法参数,这些可能是字符串,可能是我们自己定义的java的类,但是在网络上传输或者保存在硬盘的时候,网络或者硬盘并不认得什么字符串或者javabean,它只认得二进制的01串,怎么办?要进行序列化,网络传输后要进行实际调用,就要把二进制的01串变回我们实际的java的类,这个叫反序列化,java里已经为我们提供了相关的机制Serializable。
3)通信问题
我们在用序列化把东西变成了可以在网络上传输的二进制的01串,但具体如何通过网络传输?使用JDK为我们提供的BIO。
4)登记的服务实例化
登记的服务有可能在我们系统中就是一个名字,怎么变成实际执行的对象实例,当然是使用反射机制。
反射机制是什么?
反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
反射机制能做什么?
反射机制主要提供了以下功能:
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法;
- 在运行时调用任意一个对象的方法;
- 生成动态代理。
最后成型的代码参见模块rpc-client和rpc-server
1) rpc的客户端,调用远端服务RpcClient部分代码:
public class RpcClient {
public static void main(String[] args) {
UserInfo userInfo = new UserInfo("Hankin","15691805634");
SendSms sendSms = RpcClientFrame.getRemoteProxyObj(SendSms.class,"127.0.0.1",9527);
System.out.println("Send mail: "+ sendSms.sendMail(userInfo));
StockService stockService = RpcClientFrame.getRemoteProxyObj(StockService.class,"127.0.0.1",9528);
stockService.addStock("A001",100);
stockService.reduceStock("B002",50);
}
}2)rpc框架的客户端代理部分RpcClientFrame部分代码:
public class RpcClientFrame {
/**
* 远程代理对象
*/
public static T getRemoteProxyObj(final Class serviceInterface,String hostname,int port){
final InetSocketAddress address = new InetSocketAddress(hostname,port);
return (T)Proxy.newProxyInstance(serviceInterface.getClassLoader(),
new Class[]{serviceInterface},new DynProxy(serviceInterface,address));
}
/**
* 动态代理类
*/
private static class DynProxy implements InvocationHandler{
private final Class serviceInterface;
private final InetSocketAddress addr;
public DynProxy(Class serviceInterface, InetSocketAddress addr) {
this.serviceInterface = serviceInterface;
this.addr = addr;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Socket socket = null;
ObjectOutputStream output = null;
ObjectInputStream input = null;
try{
socket = new Socket();
socket.connect(addr);
output = new ObjectOutputStream(socket.getOutputStream());
output.writeUTF(serviceInterface.getName());
output.writeUTF(method.getName());
output.writeObject(method.getParameterTypes());
output.writeObject(args);
output.flush();
input = new ObjectInputStream(socket.getInputStream());
return input.readObject();
}finally {
if (socket!=null) socket.close();
if (output!=null) output.close();
if (input!=null) input.close();
}
}
}
}
rpc-server部分代码:
1)rpc框架的服务端部分RpcServerFrame部分代码:
public class RpcServerFrame {
private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
//服务的注册中心
private static final Map serviceHolder = new HashMap<>();
//服务的端口号
private int port;
public RpcServerFrame(int port) {
this.port = port;
}
// 服务注册
public void registerSerive(String className,Class impl){
serviceHolder.put(className,impl);
}
/**
* 处理服务请求任务
*/
private static class ServerTask implements Runnable{
private Socket client = null;
public ServerTask(Socket client){
this.client = client;
}
@Override
public void run() {
try(ObjectInputStream inputStream = new ObjectInputStream(client.getInputStream());
ObjectOutputStream outputStream = new ObjectOutputStream(client.getOutputStream())){
// 方法所在类名接口名
String serviceName = inputStream.readUTF();
// 方法的名字
String methodName = inputStream.readUTF();
// 方法的入参类型
Class[] paramTypes = (Class[])inputStream.readObject();
// 方法入参的值
Object[] args = (Object[])inputStream.readObject();
Class serviceClass = serviceHolder.get(serviceName);
if (serviceClass == null){
throw new ClassNotFoundException(serviceName+" Not Found");
}
Method method = serviceClass.getMethod(methodName,paramTypes);
Object result = method.invoke(serviceClass.newInstance(),args);
outputStream.writeObject(result);
outputStream.flush();
}catch(Exception e){
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 启动RPC服务
* @throws IOException
*/
public void startService() throws IOException {
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(port));
System.out.println("RPC server on:"+port+":运行");
try{
while(true){
executorService.execute(new ServerTask(serverSocket.accept()));
}
}finally {
serverSocket.close();
}
}
} 2)rpc的服务端,提供短信服务
public class SmsRpcServer {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
try {
RpcServerFrame rpcServer = new RpcServerFrame(9527);
rpcServer.registerSerive(SendSms.class.getName(), SendSmsImpl.class);
rpcServer.startService();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}3)rpc的服务端,提供商品服务
public class StockRpcServer {
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
try{
RpcServerFrame serviceServer = new RpcServerFrame(9528);
serviceServer.registerSerive(StockService.class.getName(), StockServiceImpl.class);
serviceServer.startService();
}catch(Exception e){
e.printStackTrace();
}
}
}).start();
}
}4)本地方法调用的实现
public class LocalCall {
public static void main(String[] args) {
NormalBusi normalBusi = new NormalBusi();
normalBusi.business();
SendSms sendSms = new SendSmsImpl();
UserInfo userInfo = new UserInfo("Hankin","15691805634");
System.out.println("Send mail: "+ sendSms.sendMail(userInfo));
StockService stockService = new StockServiceImpl();
stockService.addStock("A001",100);
stockService.reduceStock("B002",50);
}
}二、原生JDK网络编程- NIO
NIO 库是在JDK 1.4中引入的。NIO弥补了原来的I/O的不足,它在标准Java代码中提供了高速的、面向块的I/O。NIO翻译成no-blocking io或者new io都说得通。
1、和BIO的主要区别
1)面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2)阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read()或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入,该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
2、选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
NIO主要有三个核心部分组成:
buffer缓冲区、Channel管道、Selector选择器
2.1、Selector
Selector的英文含义是“选择器”,也可以称为为“轮询代理器”、“事件订阅器”、“channel容器管理机”都行。应用程序将向Selector对象注册需要它关注的Channel,以及具体的某一个Channel会对哪些IO事件感兴趣。Selector中也会维护一个“已经注册的Channel”的容器。
2.2、Channels
通道,被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据,而且可以同时进行读写。
- 所有被Selector(选择器)注册的通道,只能是继承SelectableChannel类的子类。
- ServerSocketChannel:应用服务器程序的监听通道。只有通过这个通道,应用程序才能向操作系统注册,支持“多路复用IO”的端口监听。同时支持UDP协议和TCP协议。
- ScoketChannel:TCP Socket套接字的监听通道,一个Socket套接字对应了一个客户端IP:端口到服务器IP:端口的通信连接。
- 通道中的数据总是要先读到一个Buffer,或者总是要从一个Buffer中写入。
2.3、buffer缓冲区
后面会讲到
3、操作类型SelectionKey
在向Selector对象注册感兴趣的事件时,JAVA NIO共定义了四种操作:OP_READ、OP_WRITE、OP_CONNECT、OP_ACCEPT(定义在SelectionKey中),分别对应读、写、请求连接、接受连接等网络Socket操作。
ServerSocketChannel和SocketChannel可以注册自己感兴趣的操作类型,当对应操作类型的就绪条件满足时OS会通知channel,下表描述各种Channel允许注册的操作类型,Y表示允许注册,N表示不允许注册,其中服务器SocketChannel指由服务器ServerSocketChannel.accept()返回的对象。
|
|
OP_READ |
OP_WRITE |
OP_CONNECT |
OP_ACCEPT |
| 服务器ServerSocketChannel |
|
|
|
Y |
| 服务器SocketChannel |
Y |
Y |
|
|
| 客户端SocketChannel |
Y |
Y |
Y |
|
服务器启动ServerSocketChannel,关注OP_ACCEPT事件,客户端启动SocketChannel,连接服务器,关注OP_CONNECT事件;服务器接受连接,启动一个服务器的SocketChannel,这个SocketChannel可以关注OP_READ、OP_WRITE事件,一般连接建立后会直接关注OP_READ事件。
客户端这边的客户端SocketChannel发现连接建立后,可以关注OP_READ、OP_WRITE事件,一般是需要客户端需要发送数据了才关注OP_READ事件。连接建立后客户端与服务器端开始相互发送消息(读写),根据实际情况来关注OP_READ、OP_WRITE事件。
我们可以看看每个操作类型的就绪条件:
| 操作类型 |
就绪条件及说明 |
| OP_READ |
当操作系统读缓冲区有数据可读时就绪。并非时刻都有数据可读,所以一般需要注册该操作。 |
| OP_WRITE |
当操作系统写缓冲区有空闲空间时就绪。一般情况下写缓冲区都有空闲空间,小块数据直接写入即可,没必要注册该操作类型,否则该条件不断就绪浪费CPU;但如果是写密集型的任务,比如文件下载等,缓冲区很可能满,注册该操作类型就很有必要,同时注意写完后取消注册。 |
| OP_CONNECT |
当SocketChannel.connect()请求连接成功后就绪。该操作只给客户端使用。 |
| OP_ACCEPT |
当接收到一个客户端连接请求时就绪。该操作只给服务器使用。 |
三、原生JDK网络编程- Buffer
Buffer用于和NIO通道进行交互。数据是从通道读入缓冲区,从缓冲区写入到通道中的。以写为例,应用程序都是将数据写入缓冲,再通过通道把缓冲的数据发送出去,读也是一样,数据总是先从通道读到缓冲,应用程序再读缓冲的数据。
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存( 其实就是数组)。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
1、重要属性
1.1、capacity
作为一个内存块,Buffer有一个固定的大小值,也叫“capacity”。你只能往里写capacity个byte、long,char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续往里写数据。
1.2、position
当你写数据到Buffer中时,position表示当前的位置。初始的position值为0,当一个byte、long等数据写到Buffer后,position会向前移动到下一个可插入数据的Buffer单元,position最大可为capacity – 1。
当读取数据时,也是从某个特定位置读,当将Buffer从写模式切换到读模式,position会被重置为0;当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
1.3、limit
在写模式下Buffer的limit表示你最多能往Buffer里写多少数据,写模式下limit等于Buffer的capacity。
当切换Buffer到读模式时,limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)
2、Buffer的分配
要想获得一个Buffer对象首先要进行分配,每一个Buffer类都有allocate方法(可以在堆上分配,也可以在直接内存上分配)。
分配48字节capacity的ByteBuffer的例子:ByteBuffer buf = ByteBuffer.allocate(48);
分配一个可存储1024个字符的CharBuffer:CharBuffer buf = CharBuffer.allocate(1024);
wrap方法:把一个byte数组或byte数组的一部分包装成ByteBuffer:
ByteBuffer wrap(byte [] array)
ByteBuffer wrap(byte [] array, int offset, int length)
2.1、直接内存
HeapByteBuffer与DirectByteBuffer在原理上,前者可以看出分配的buffer是在heap区域的,其实真正flush到远程的时候会先拷贝到直接内存,再做下一步操作;在NIO的框架下,很多框架会采用DirectByteBuffer来操作,这样分配的内存不再是在java heap上,而是在操作系统的C heap上,经过性能测试,可以得到非常快速的网络交互,在大量的网络交互下,一般速度会比HeapByteBuffer要快速好几倍。
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现。
NIO可以使用Native 函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
2.2、堆外内存的优点和缺点
堆外内存,相比于堆内内存有几个优势:
1)减少了垃圾回收的工作,因为垃圾回收会暂停其他的工作(可能使用多线程或者时间片的方式,根本感觉不到) 。
2)加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后发送;而堆外内存相当于省略掉了这个工作。
而福之祸所依,自然也有不好的一面:
·堆外内存难以控制,如果内存泄漏,那么很难排查。
·堆外内存相对来说,不适合存储很复杂的对象,一般简单的对象或者扁平化的比较适合。
直接内存(堆外内存)与堆内存比较
直接内存申请空间耗费更高的性能,当频繁申请到一定量时尤为明显
直接内存IO读写的性能要优于普通的堆内存,在多次读写操作的情况下差异明显
3、Buffer的读写
3.1、向Buffer中写数据
写数据到Buffer有两种方式:
- 读取Channel写到Buffer。
- 通过Buffer的put()方法写到Buffer里。
从Channel写到Buffer的例子
int bytesRead = inChannel.read(buf); //read into buffer.
通过put方法写Buffer的例子:
buf.put(127);
put方法有很多版本,允许你以不同的方式把数据写入到Buffer中。例如, 写到一个指定的位置,或者把一个字节数组写入到Buffer。 更多Buffer实现的细节参考JavaDoc。
flip()方法
flip方法将Buffer从写模式切换到读模式。调用flip()方法会将position设回0,并将limit设置成之前position的值。
换句话说,position现在用于标记读的位置,limit表示之前写进了多少个byte、char等 —— 现在能读取多少个byte、char等。
3.2、从Buffer中读取数据
从Buffer中读取数据有两种方式:
- 从Buffer读取数据写入到Channel。
- 使用get()方法从Buffer中读取数据。
从Buffer读取数据到Channel的例子:
int bytesWritten = inChannel.write(buf);
使用get()方法从Buffer中读取数据的例子
byte aByte = buf.get();
get方法有很多版本,允许你以不同的方式从Buffer中读取数据。例如,从指定position读取,或者从Buffer中读取数据到字节数组。更多Buffer实现的细节参考JavaDoc。
3.3、使用Buffer读写数据常见步骤:
- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
3.4、其他常用操作
rewind()方法:
Buffer.rewind()将position设回0,所以你可以重读Buffer中的所有数据;limit保持不变,仍然表示能从Buffer中读取多少个元素(byte、char等)。
clear()与compact()方法:
一旦读完Buffer中的数据,需要让Buffer准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设回0,limit被设置成capacity的值,换句话说Buffer被清空了。如果调用compact()方法Buffer中的数据并未清除,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。
如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。
compact()方法将所有未读的数据拷贝到Buffer起始处,然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
mark()与reset()方法:
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position,之后可以通过调用Buffer.reset()方法恢复到这个position。例如:
buffer.mark(); //call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
equals()与compareTo()方法
可以使用equals()和compareTo()方法比较两个Buffer。
equals():
当满足下列条件时,表示两个Buffer相等:
有相同的类型(byte、char、int等)。
Buffer中剩余的byte、char等的个数相等。
Buffer中所有剩余的byte、char等都相同。
如你所见,equals只是比较Buffer的一部分,不是每一个在它里面的元素都比较,实际上它只比较Buffer中的剩余元素。
compareTo()方法:
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素 。
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。
5、Buffer方法总结
| limit(), limit(10)等 |
其中读取和设置这4个属性的方法的命名和jQuery中的val(),val(10)类似,一个负责get,一个负责set |
| reset() |
把position设置成mark的值,相当于之前做过一个标记,现在要退回到之前标记的地方 |
| clear() |
position=0; limit=capacity; mark=-1; 有点初始化的味道,但是并不影响底层byte数组的内容 |
| flip() |
limit=position;position=0;mark=-1; 翻转,也就是让flip之后的position到limit这块区域变成之前的0到position这块,翻转就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的状态 |
| rewind() |
把position设为0,mark设为-1,不改变limit的值 |
| remaining() |
return limit - position; 返回limit和position之间相对位置差 |
| hasRemaining() |
return position < limit返回是否还有未读内容 |
| compact() |
把从position到limit中的内容移到0到limit-position的区域内,position和limit的取值也分别变成limit-position、capacity。如果先将positon设置到limit,再compact,那么相当于clear() |
| get() |
相对读,从position位置读取一个byte,并将position+1,为下次读写作准备 |
| get(int index) |
绝对读,读取byteBuffer底层的bytes中下标为index的byte,不改变position |
| get(byte[] dst, int offset, int length) |
从position位置开始相对读,读length个byte,并写入dst下标从offset到offset+length的区域 |
| put(byte b) |
相对写,向position的位置写入一个byte,并将postion+1,为下次读写作准备 |
| put(int index, byte b) |
绝对写,向byteBuffer底层的bytes中下标为index的位置插入byte b,不改变position |
| put(ByteBuffer src) |
用相对写,把src中可读的部分(也就是position到limit)写入此byteBuffer |
| put(byte[] src, int offset, int length) |
从src数组中的offset到offset+length区域读取数据并使用相对写写入此byteBuffer |
Buffer相关的代码参见模块java-nio下包com.chj.nio.buffer
四、原生JDK网络编程- NIO之Reactor模式
“反应”即“倒置”,“控制逆转”,具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有时间来了,具体事件处理程序通过事件处理器对某个指定的事件发生做出反应;这种控制逆转又称为“好莱坞法则”(不要调用我,让我来调用你)。
例如,路人甲去做男士SPA,前台的接待小姐接待了路人甲,路人甲现在只对10000技师感兴趣,就告诉接待小姐,等10000技师上班了或者是空闲了,通知我。等james接到通知了,做出了反应,把10000技师占住了,然后,路人甲想起上一次的那个10000号房间不错,设备舒适,灯光暧昧,又告诉前台的接待小姐,我对10000号房间很感兴趣,房间空出来了就告诉我,我现在先和10000这个小姐聊下人生,10000号房间空出来了,james接到通知了,路人甲再次做出了反应。路人甲就是具体事件处理程序,前台的接待小姐就是所谓的反应器,10000技师和10000号房间空闲了就是事件,路人甲只对这两个事件感兴趣,其他,比如10001号技师或者10002号房间空闲了也是事件,但是路人甲不感兴趣。
1、单线程Reactor模式流程:
1)服务器端的Reactor是一个线程对象,该线程会启动事件循环,并使用Selector(选择器)来实现IO的多路复用。注册一个Acceptor事件处理器到Reactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样Reactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。
2)客户端向服务器端发起一个连接请求,Reactor监听到了该ACCEPT事件的发生并将该ACCEPT事件派发给相应的Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将该连接所关注的READ事件以及对应的READ事件处理器注册到Reactor中,这样一来Reactor就会监听该连接的READ事件了。
3)当Reactor监听到有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法读取数据,此时read()操作可以直接读取到数据,而不会堵塞与等待可读的数据到来。
4)每当处理完所有就绪的感兴趣的I/O事件后,Reactor线程会再次执行select()阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
注意:Reactor的单线程模式的单线程主要是针对于I/O操作而言,也就是所有的I/O的accept()、read()、write()以及connect()操作都在一个线程上完成的。
但在目前的单线程Reactor模式中,不仅I/O操作在该Reactor线程上,连非I/O的业务操作也在该线
程上进行处理了,这可能会大大延迟I/O请求的响应。所以我们应该将非I/O的业务逻辑操作从Reactor线程上卸载,以此来加速Reactor线程对I/O请求的响应。
2、单线程Reactor—工作者线程池
与单线程Reactor模式不同的是,添加了一个工作者线程池,并将非I/O操作从Reactor线程中移出转交给工作者线程池来执行。这样能够提高Reactor线程的I/O响应,不至于因为一些耗时的业务逻辑而延迟对后面I/O请求的处理。
使用线程池的优势:
① 通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊在线程创建和销毁过程产生的巨大开销。
② 另一个额外的好处是,当请求到达时,工作线程通常已经存在,因此不会由于等待创建线程而延迟任务的执行,从而提高了响应性。
③ 通过适当调整线程池的大小,可以创建足够多的线程以便使处理器保持忙碌状态。同时还可以防止过多线程相互竞争资源而使应用程序耗尽内存或失败。
改进的版本中,所以的I/O操作依旧由一个Reactor来完成,包括I/O的accept()、read()、write()以及connect()操作。对于一些小容量应用场景,可以使用单线程模型。但是对于高负载、大并发或大数据量的应用场景却不合适,主要原因如下:
- 一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的读取和发送;
- 当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,成为系统的性能瓶颈;
3、多Reactor线程模式
Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的事件循环逻辑。
mainReactor可以只有一个,但subReactor一般会有多个。mainReactor线程主要负责接收客户端的连接请求,然后将接收到的SocketChannel传递给subReactor,由subReactor来完成和客户端的通信。
具体流程如下:
1)注册一个Acceptor事件处理器到mainReactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样mainReactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件),启动mainReactor的事件循环。
2)客户端向服务器端发起一个连接请求,mainReactor监听到了该ACCEPT事件并将该ACCEPT事件派发给Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将这个SocketChannel传递给subReactor线程池。
3) subReactor线程池分配一个subReactor线程给这个SocketChannel,即,将SocketChannel关注的READ事件以及对应的READ事件处理器注册到subReactor线程中。当然你也注册WRITE事件以及WRITE事件处理器到subReactor线程中以完成I/O写操作。Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的循环逻辑。
4) 当有I/O事件就绪时,相关的subReactor就将事件派发给响应的处理器处理。注意,这里subReactor线程只负责完成I/O的read()操作,在读取到数据后将业务逻辑的处理放入到线程池中完成,若完成业务逻辑后需要返回数据给客户端,则相关的I/O的write操作还是会被提交回subReactor线程来完成。
注意:所以的I/O操作(包括,I/O的accept()、read()、write()以及connect()操作)依旧还是在Reactor线程(mainReactor线程 或 subReactor线程)中完成的。Thread Pool(线程池)仅用来处理非I/O操作的逻辑。
多Reactor线程模式将“接受客户端的连接请求”和“与该客户端的通信”分在了两个Reactor线程来完成。mainReactor完成接收客户端连接请求的操作,它不负责与客户端的通信,而是将建立好的连接转交给subReactor线程来完成与客户端的通信,这样一来就不会因为read()数据量太大而导致后面的客户端连接请求得不到即时处理的情况。并且多Reactor线程模式在海量的客户端并发请求的情况下,还可以通过实现subReactor线程池来将海量的连接分发给多个subReactor线程,在多核的操作系统中这能大大提升应用的负载和吞吐量。
Netty服务端使用了“多Reactor线程模式”
4、和观察者模式的区别
观察者模式:
也可以称为为 发布-订阅 模式,主要适用于多个对象依赖某一个对象的状态并,当某对象状态发生改变时,要通知其他依赖对象做出更新。是一种一对多的关系。当然,如果依赖的对象只有一个时,也是一种特殊的一对一关系。通常,观察者模式适用于消息事件处理,监听者监听到事件时通知事件处理者对事件进行处理(这一点上面有点像是回调,容易与反应器模式和前摄器模式的回调搞混淆)。
Reactor模式:
reactor模式,即反应器模式,是一种高效的异步IO模式,特征是回调,当IO完成时,回调对应的函数进行处理。这种模式并非是真正的异步,而是运用了异步的思想,当IO事件触发时,通知应用程序作出IO处理。模式本身并不调用系统的异步IO函数。
reactor模式与观察者模式有点像。不过,观察者模式与单个事件源关联,而反应器模式则与多个事件源关联 。当一个主体发生改变时,所有依属体都得到通知。